Tables
This chapter will introduce: what is table and how to manage tables on the platform.
Use tables to manage FAQs
When building a primary agent, developers will mainly create FAQs to build its skills.
It is ideal to do it in this way if the business knowledge consists of unstructured data. For that:
- FAQs are much easier to create and manage.
- The intention recognition model will be more stable.
However, if the business knowledge consists of structured data, building agent skills with FAQs can be defective.
Scenario 1: Object - Attribute - Attribute Value
There is a car sales agent, who needs to learn the price of every model of car.
User may ask:
- How much is 718 Cayman?
- How much is 718 Boxster?
- How much is 718 Spyder?
If we use FAQs to build agent skills in this case, we run into two problems.
- As each model needs to have an FAQ, if there are a large number of models, the developer would need to spend a lot of time creating and managing these FAQs.
- Even if the developer has created all the FAQs needed, highly similar trigger utterances and model names can have a negative impact on the recall results of the algorithmic models. Besides, if the model name also contains confusing information such as letters and numbers, the skills can hardly be triggered correctly.
Apart from product price, the car sales agent also needs to give responses to other questions like:
- Which range does 718 Cayman belong to?
- How many seats does 718 Cayman have?
As you can see, the models and their additional information form a structured two-dimensional table, which is more similar to the original knowledge structure of the business than FAQs.
| Model name | Range | Seat | Price |
|---|---|---|---|
| 718 Cayman | 718 | 2 | 525000 |
| 718 Boxster | 718 | 2 | 565000 |
| 718 Spyder | 718 | 2 | 758000 |
With this table, the developer will not need to create 6 FAQs, but simply set the trigger utterance as:
What is the {attribute} of {model name}?
The agent can then locate the corresponding knowledge in the table and send the answer based on the specific model name and attribute mentioned in the user's message.
In this scenario, building agent skills with a table instead of FAQs not only follows the original business knowledge structure, but also helps the developer manage skills easier and improve the end-user's experience.
Scenario 2: Question - User Attribute - Customized Response
There is an HR agent who works for a large enterprise with offices located in different cities.
Employees based in different cities are likely to ask the same question: "What is the Wi-Fi password?"
If we create a FAQ and set the Wi-Fi passwords of every office as the response, the agent's reply will be like:
The Wi-Fi password for the Beijing office is XXXXXXXXXX. The Wi-Fi password for the Shanghai office is XXXXXXXXXX. The Wi-Fi password for the Changsha office is XXXXXXXXXX. The Wi-Fi password for the Fuzhou office is XXXXXXXXXX.
In this case, the more office this enterpreise has, the harder for the user to find the information needed in such a long response.
Therefore, we can build a dialogue flow:
Step 1: Agent gets the user attribute
located cityStep 2: Go to different routes based on the value.
Step 3: Add an inform block to each route.
Step 4: Set the Wi-Fi password of the corresponding office as the response.
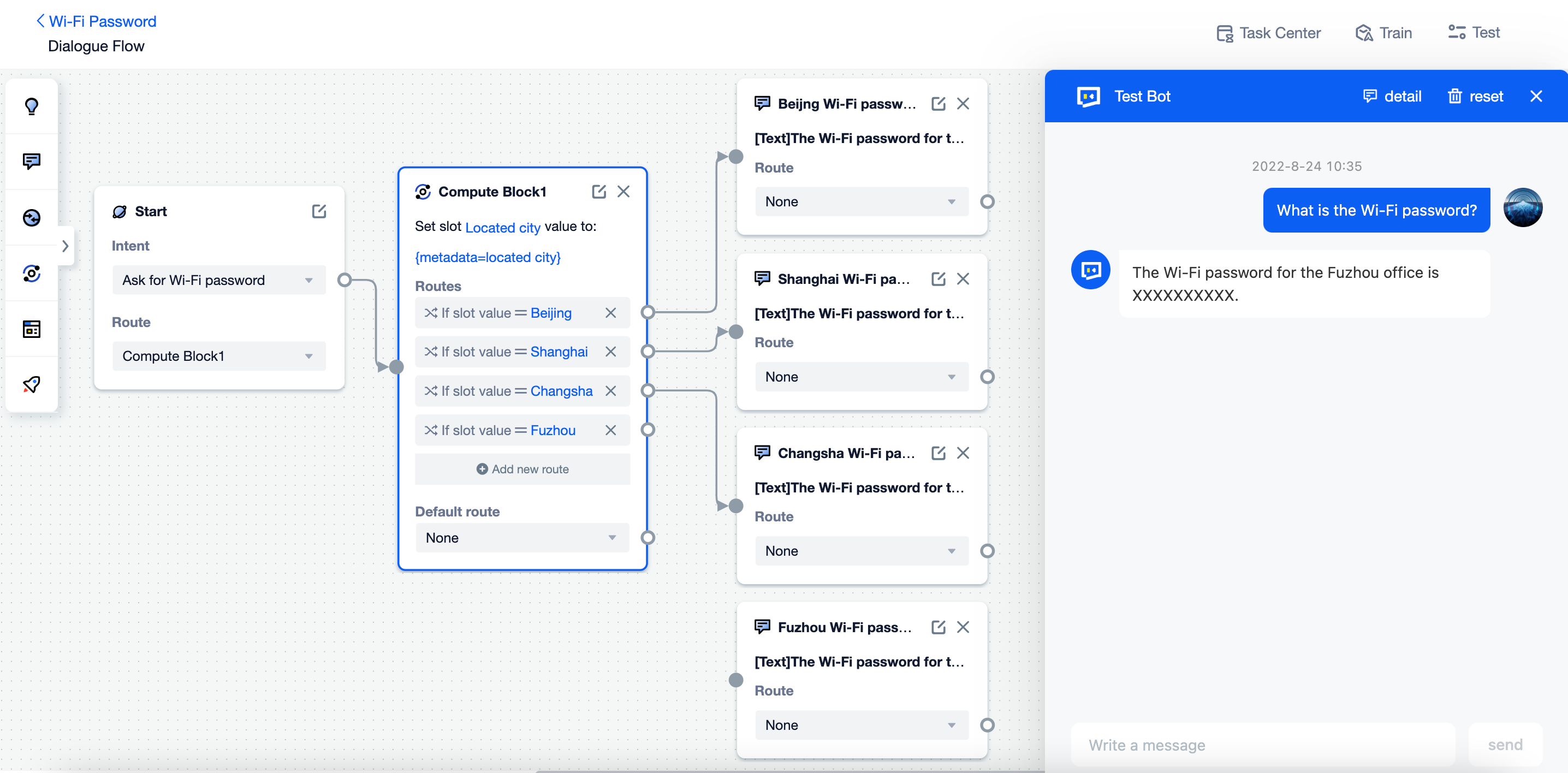
However, if there are dozens of offices, building the skill with dialogue flow can be time-consuming.
In addition to WiFi passwords, many other equipments are also strongly related to the user's locatd city.
Employees based in different offices are likely to ask:
- What is the Wi-Fi password?
- Where is the printer?
- What is the office address in detail?
As the located office and equipments can form a structured two-dimensional table, we can use the table below to build related skills.
| Located city | Wi-Fi password | Printer | Office address |
|---|---|---|---|
| Beijing | XXXXXXXXXX | Next to the finance office on the 19th floor | xx floor, xx Building, xx Street, xx District |
| Shanghai | XXXXXXXXXX | Next to the finance office on the 7th floor | xx floor, xx Building, xx Street, xx District |
| Changsha | XXXXXXXXXX | Next to the finance office on the 2nd floor | xx floor, xx Building, xx Street, xx District |
With this table, the agent can locate the corresponding knowledge in the table and send the answer based on the specific located city of the user attribute.
Advantages of tables
Tables are easier to build and manage. Compared to multidimensional knowledge graphs, two-dimensional tables can already meet most scenes and are more developer-friendly. Table contents can be edited directly on the platform. You can also upload .xlsx files to build tables in a quicker way.
Tables support a variety of data formats including text, associated entity, number, date, time and multimedia response. In addition, each data format has a corresponding judgement logic, making table look-up during conversations more flexible and convenient.
Tables can be used in various scenarios. You can use a table both in the FAQs and dialogue flows.
Management of tables
Click "Build-Rescources-Tables" on the agent menu to enter the page.

Click "+ Create table", enter the table name and select the type to create a new table.
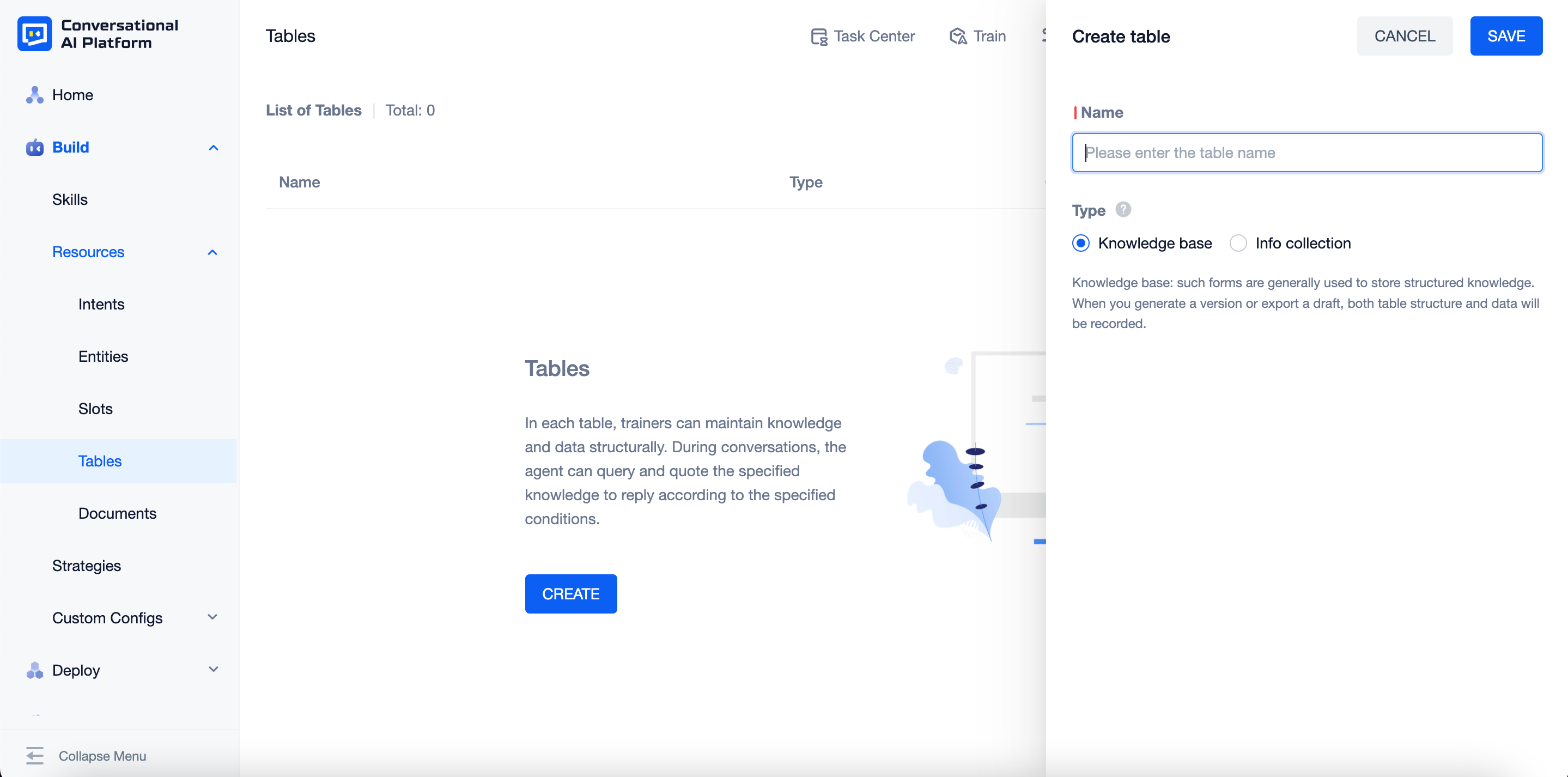
The platform supports two types of tale:
- Knowledge base: Both the data and the structure of the table will be included when creating versions, exporting drafts. Therefore, using this type of table is a better choice to build knowledge extracted from business, so the knowledge can be used in skills.
- Info collection: Only the structure of the table will be included when creating versions or exporting drafts. To achieve the data, you need to export the table on the corresponding table page. Therefore, this type of table is often used to collect the information mentioned in user messages that you want the agent to keep.
warning
Table type cannot be modified once selected.
caution
The amount of table data in information collection scenes will vary with the volume of conversations, which means it is likely to have thousands or millions rows of data on a table.
If use knowledge base tables to collect information, there can be an error when creating versions or exporting drafts.
- After the table is successfully created, it will be displayed on the list in the order of created time. You can check the name, type and created time on the list.
Management of table fields
Clicke "Enter" to enter the table content page.
A newly created table has no field, so you cannot add any content.
Switch to the "Fields" tab to manage fields. Click "+ Create Field", set the name, key and type to create a new field.
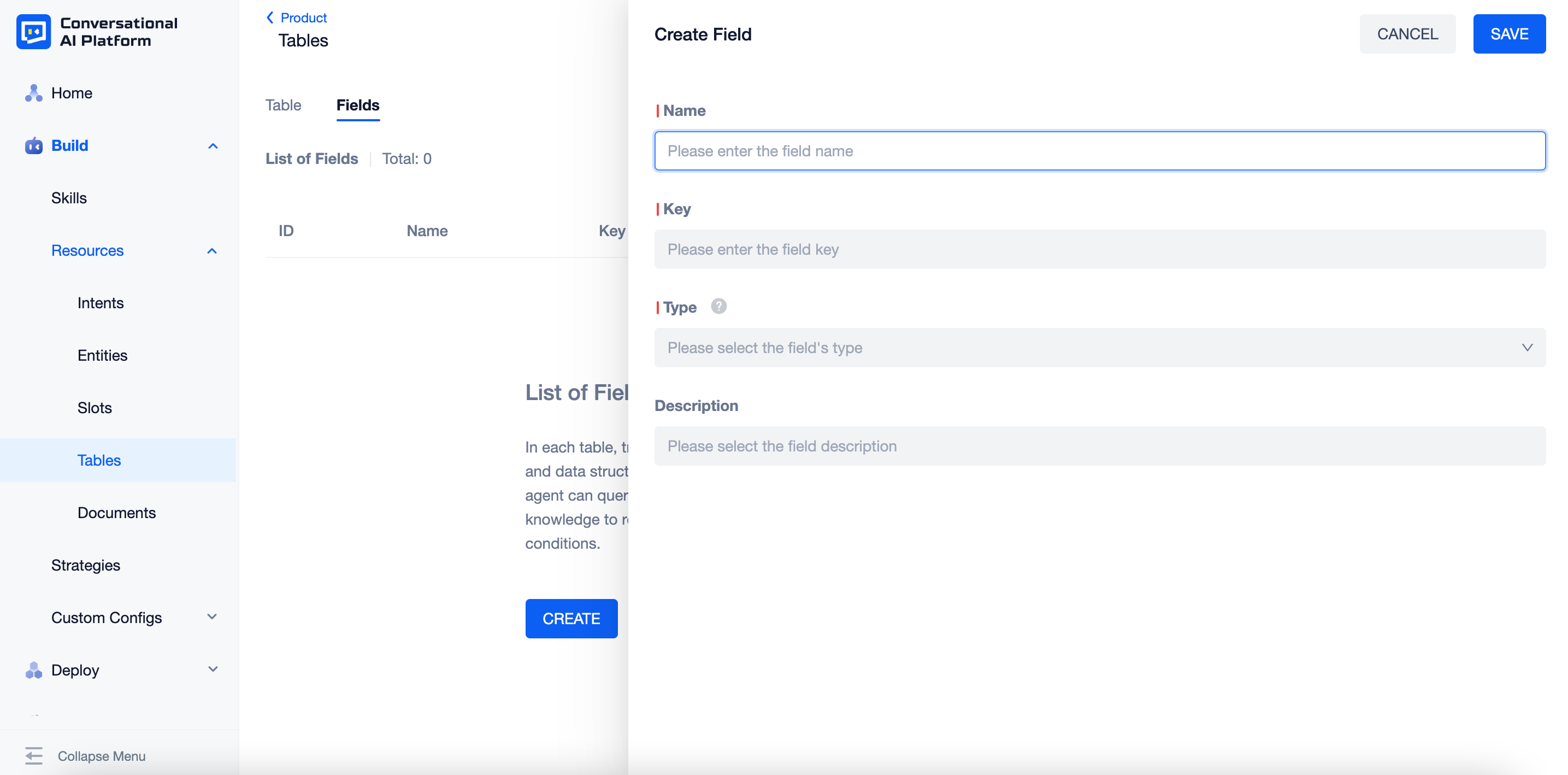
Name: The name of a field will be displayed as the name of a column. It can be modified later, but cannot be repeated within the current table.
Key: The unique identification of the field (for interface processing, only letters, numbers and underscores are allowed), which will be displayed in the header of the exported excel file. It cannot be modified after creation and cannot be repeated within the current table.
Description: The additional description of the field, which will be displayed in the input box prompt when adding a new row of data.
Type: The platform supports 6 commonly used data types: text, number, date, time, date and time, and answer. It cannot be modificated after creation.
Set the type of each field correctly can make it easier to manage the table.
Type Edit box Filter strategies Text Text input box / Drop down selection compoent (with associated entity only) Support comparison by ascll code value
Support fuzzy matching by semanticsDate & Time Date and time selection component Support date and time comparisons Number Number input box, support integers and floating points Support number comparisons Answer Answer edition component, support multimedia content Cannot be used as a filter condition Associated entity: When the type is selected as "text", you can choose to associate it with one or multiple entities. Once the field is associated to an entity, the edit box will change from a input box to a drop down selection component. You can fill it by chosing an entity.
Index config: You need to configure this item if the field is likely to be used as a filter condition. The date & time and number type are configured with this item by default, and answers cannot be used as a filter condition by now, so you only need to configure for the text type. The strategy used cannot be modified after creation.
note
- When "Exact Match" is enabled, fields can be queried to use conditions like equal to, greater than, and less than.
- When "Approximate" is enabled, fields can be queried to use conditions like approximate to. It also supports custom word splitting strategies.
After the field is successfully created, it will be displayed on the list in the order of created time. You can check the ID, name, key, type, description and index config on the list.

Management of table contents
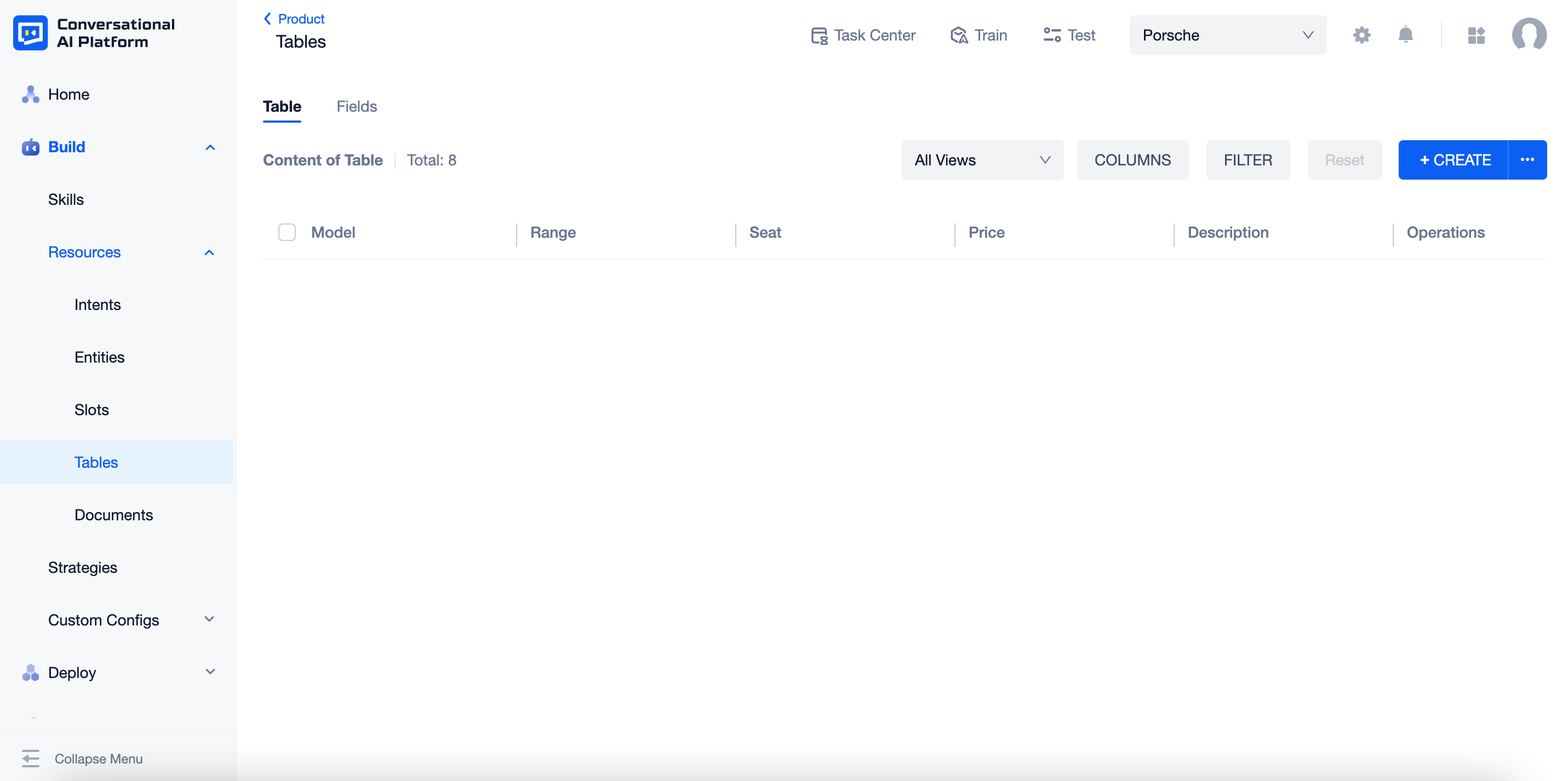
Switch back to the "Table" tab, now you can see the fields created. They are listed from left to right in the order of created time.
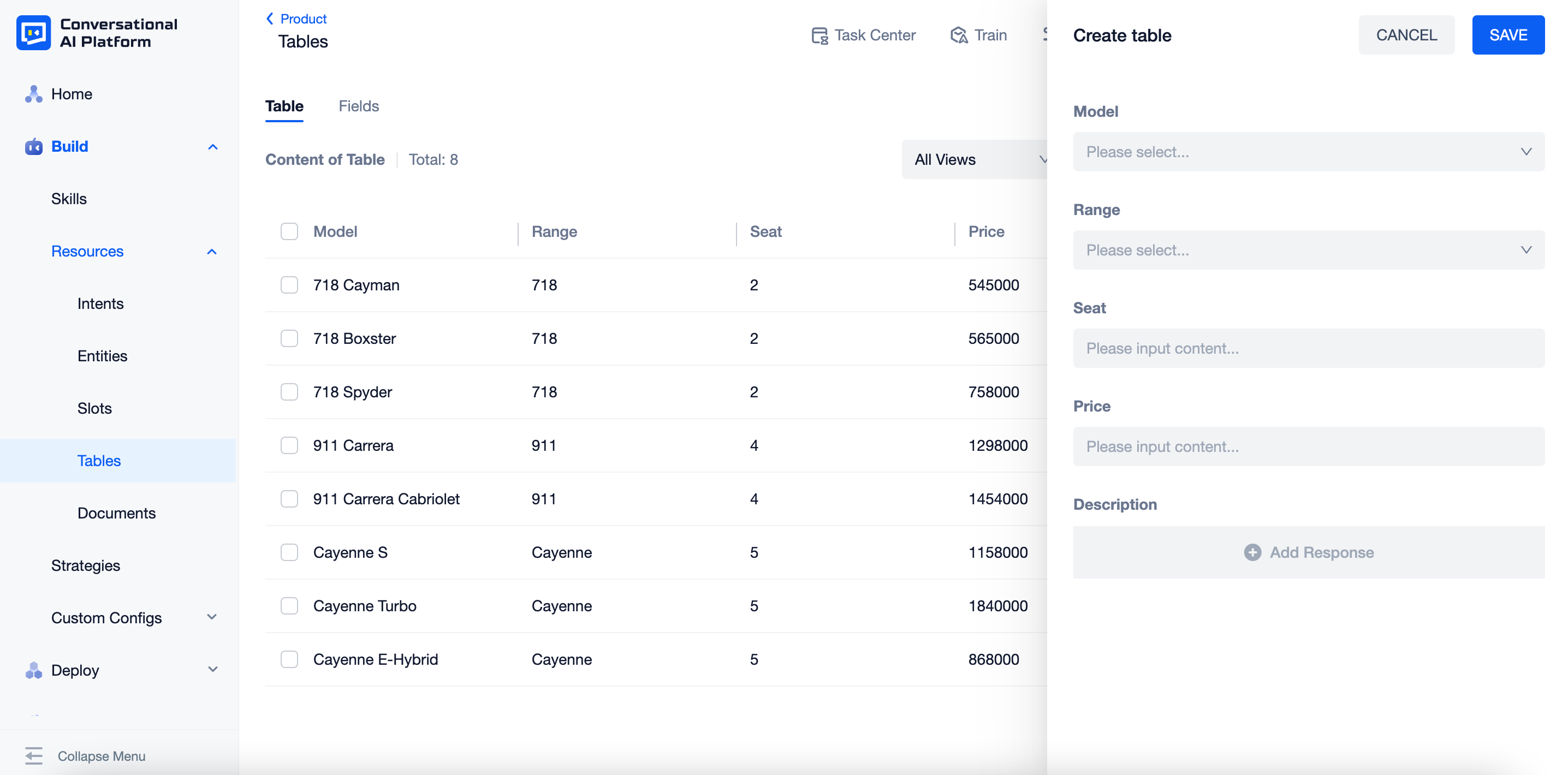
Click "+CREATE" and fill in the items. The platform will set the input box with the most suitable component based on the type of each field.
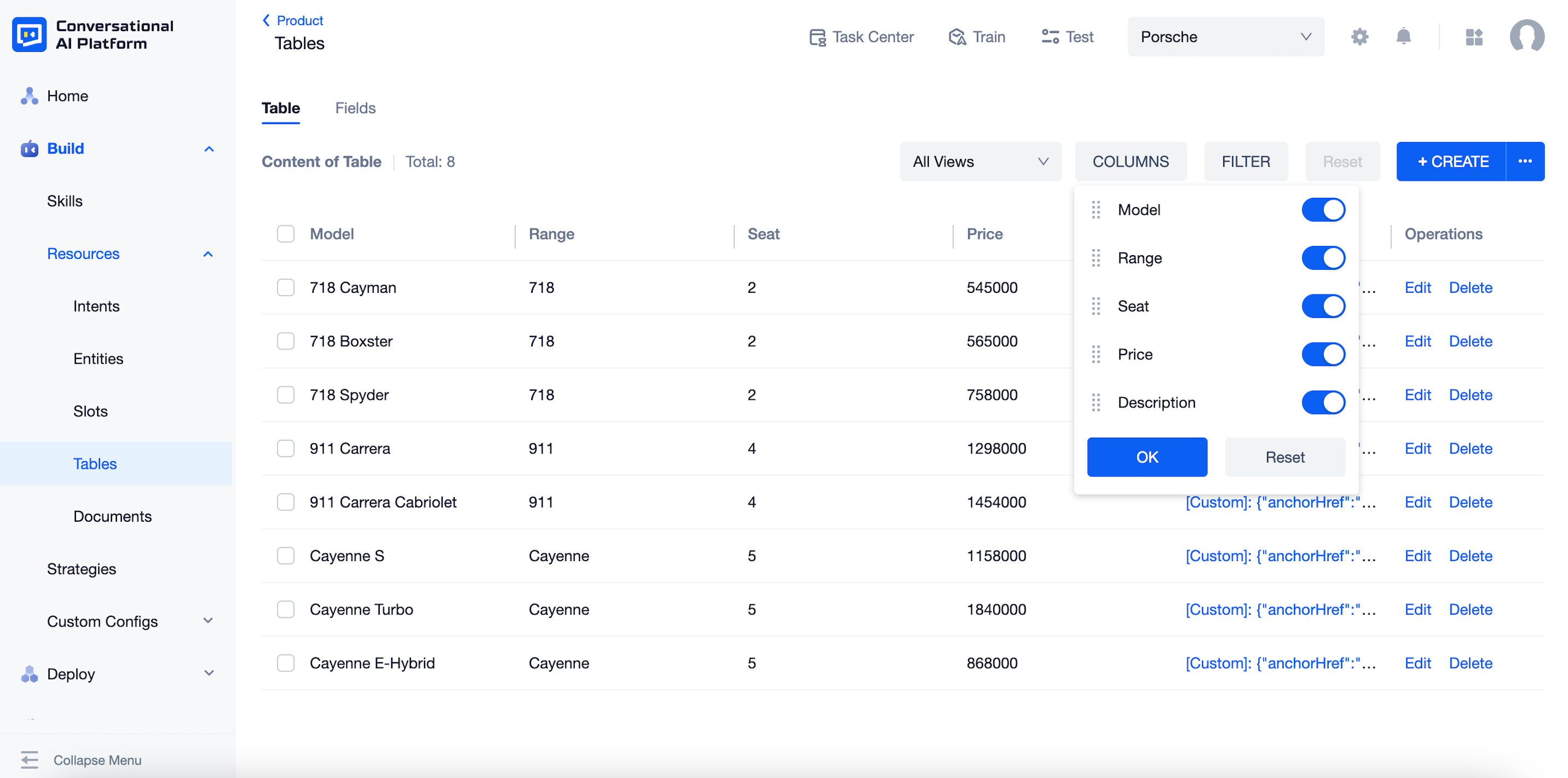
Click "COLUMNS", here you can set the order and the visibility of each field. It will only affect how this page presented, but not the order of each field when creating a new row of data.
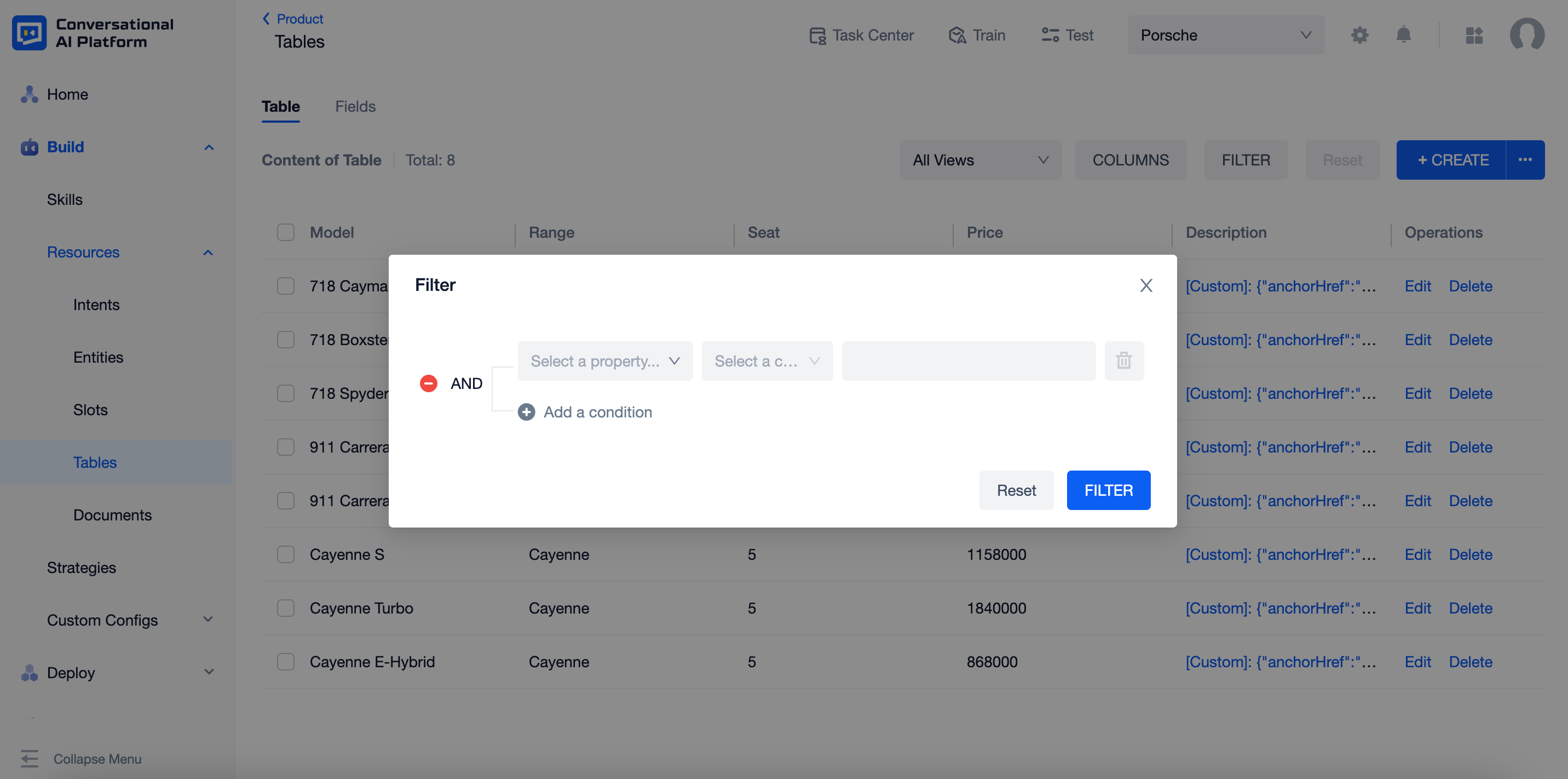
When there are too much data, you can narrow down them by setting the "FILTER". You can set any field except from "answer" as the filter with the "AND" condition. The filter strategies are related to index configs of each field.
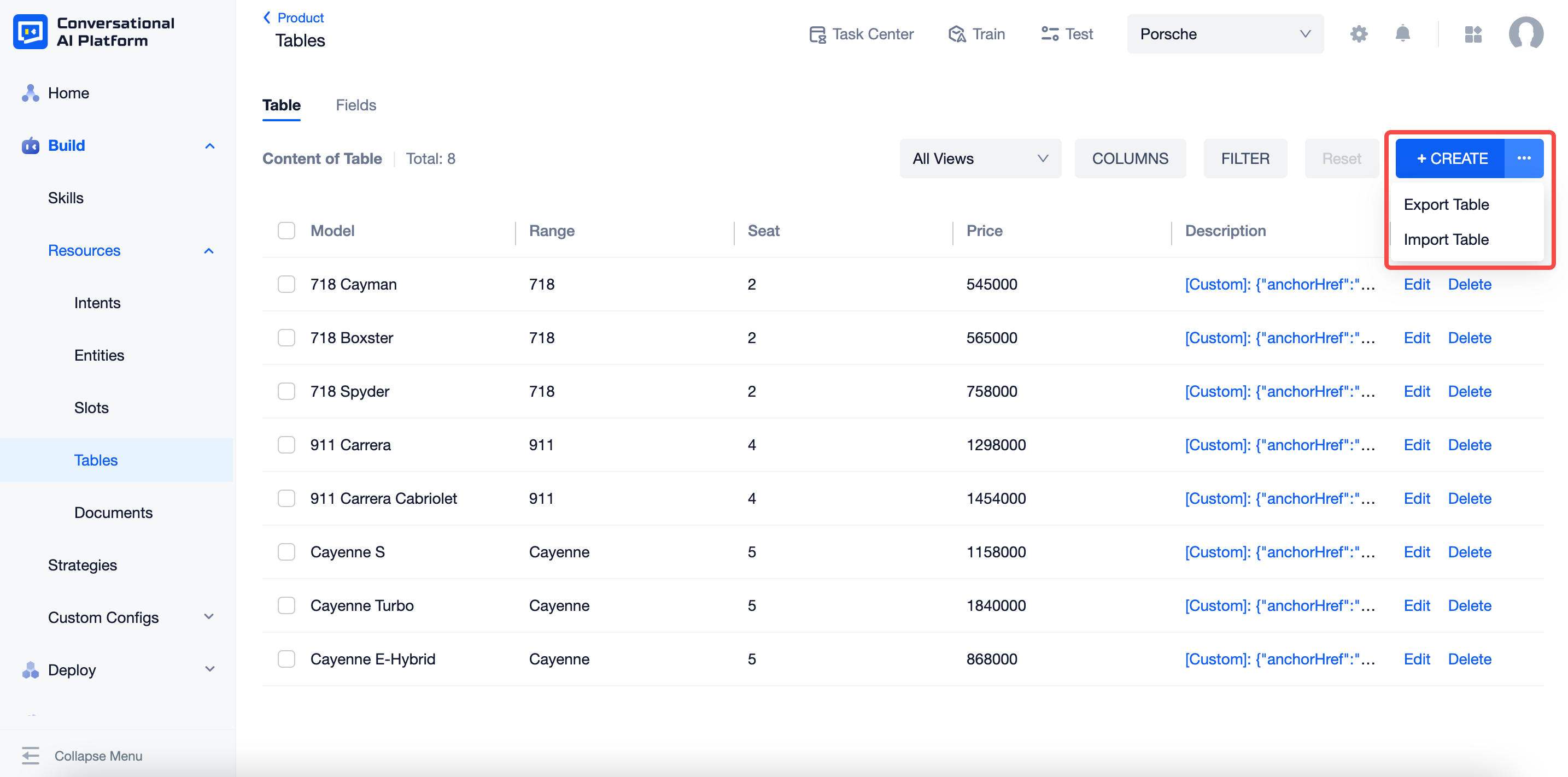
Import & Export
Click "···" beside of "+CREATE", you can import or export tables here. Currently, the platform only supports import and export of the table content, while fields are not included.
Use tables in skills
Tables can be used in both FAQs and dialogue flows. The agent will make table look-up during conversations based on the conditions configured in skills. The results will be sent to the users as responses, or fill the slots configured. For more details, see Personalized Answer and Table Lookup Block