表格
本章节将讲解:什么是表格,以及如何在平台管理表格数据。
使用表格维护知识
最初,在搭建初级的机器人时,训练师会以知识问答(FAQ)类型的技能为主。也就是说,训练师把机器人的知识拆分称一个个互相独立知识点,通过大量问答对来维护机器人的完整知识体系。
如果业务的知识体系本就由一些非结构化的句子组成,那么这样维护非常合适。其优势也显而易见:
- 对训练师来说,创建FAQ操作简单易上手;
- 从对话效果来讲,意图识别模型也相对成熟稳定。
但是,如果业务知识是由结构化的数据组成的,使用知识问答(FAQ)体系的缺陷就会暴露无遗:
场景一: 主体-属性-属性值
有一个保险机器人,记录了所有保险产品的保险期限。
用户可能这么问:
- 莱耶鑫福熙悦两全保险 的保险期限是多久
- 莱耶鑫福熙悦终身寿险 的保险期限是多久
- 莱耶鑫悦满意两全保险 的保险期限是多久
如果使用知识问答来搭建这个场景,会遇到两个问题:
- 每个产品都要单独创建一个知识点。如果业务中产品数量较多,会极大增加训练师的搭建维护成本。
- 即使创建了所有的知识点,大量表述方式冗余的问题和相似度及高的产品名称,也会让算法模型的召回效果面临较大的挑战。如果名称中还包含无意义的字母、数字等易混淆信息,仅靠配置FAQ的意图几乎很难确保准确率。
不光是保险期限,保险机器人也需要解答用户对产品更多方面的信息询问。
用户可能这么问:
- 莱耶鑫福熙悦两全保险的 保险期限 是多久
- 莱耶鑫福熙悦两全保险要 怎么缴费 的
- 莱耶鑫福熙悦两全保险的 保障计划 是什么
可以看到,各种保险产品和产品的各类信息组成了一个结构化的二维表格,这就是一个表格知识,相比起问答对,它和业务原始的知识结构更为相似。
| 产品名称 | 保险期限 | 缴费方式 | 保障计划 |
|---|---|---|---|
| 莱耶鑫福熙悦两全保险 | 25年 | 期缴 | 📃富文本内容 |
| 莱耶鑫福熙悦终身寿险 | 终身 | 趸缴 | 📁PDF文件 |
| 莱耶鑫悦满意两全保险 | 70周岁 | 趸缴 | 🖼PNG图片 |
使用这个表格,训练师不需要再拆分3*3个知识点,而只需要配置一个问题:
{产品名称}的{产品属性}是什么
机器人就可以根据用户消息中的提到的具体产品名称和产品属性,定位到表格中的对应知识并返回答案。
这种场景下,通过表格取代的FAQ知识体系,不但更贴近业务原本形态,更在平方级降低了训练师维护成本的同时,提高了机器人的回复效果。
场景二: 问题-用户属性-个性化回复
有一个大型企业的人事机器人,企业有很多办公区,机器人记录了所有办公区的基础设施信息。
不同办公区的员工可能都会问:Wi-Fi密码是多少?
如果搭建一个FAQ实现,训练师需要在一个答案里配置所有办公区的Wi-Fi密码:
机器人的回复会变成:北京办公区的Wi-Fi密码是XXXXXXXXX,上海办公区的Wi-Fi密码是XXXXXXXXX,长沙办公区的Wi-Fi密码是XXXXXXXXX,福州办公区的Wi-Fi密码是XXXXXXXXX
用户需要根据自己所在的办公区,在答案中查找到对应密码。这种情况下,办公区数量越多,答案可读性就会越差,用户对话的体验感也会大幅下降。
为了提升答案可读性和对话体验,训练师就需要搭建一个对话流程:
第一步:机器人读取用户属性
所在办公区
第二步:根据属性值,跳转到不同的分支
第三步:每个分支后添加一个消息单元 第四步:在消息单元中配置对应办公区的Wi-Fi密码

这种方案可以让用户拥有最佳的对话体验,但是对训练师并不友好。仅WiFi密码一个问题,有多少办公区就需要在画布中维护多少个跳转分支。
除了WiFi密码,很多其他基础设施也都与用户所在办公区强相关
不同办公区的员工都可能会问:
- Wi-Fi密码是多少?
- 打印机在哪里
- 办公室详细地址
可以看到,用户所在办公区和办公区的基础信息也组成了一个结构化的二维表格,这也是一个表格知识,相比起流程分支跳转到不同单元,它和业务原始的知识结构也更为相似。
| 办公区 | Wi-Fi密码 | 打印机 | 办公室地址 |
|---|---|---|---|
| 北京 | XXXXXXXXX | 19层财务室旁边 | xx区xx街x号 xx大厦 xx层 |
| 上海 | XXXXXXXXX | 7层财务室旁边 | xx区xx路x号 xx中心 xx栋 |
| 长沙 | XXXXXXXXX | 2层财务室旁边 | xx区xx公园xx小镇 x栋 xx |
使用这个表格,训练师不再需要在对话流程中拆解多条分支,只需要配置好用户的问题,机器人就可以根据用户属性所在办公区,定位到表格中的对应知识并返回答案。
这种场景下,通过表格取代的对话流程分支,不但更贴近业务原本形态,更在提高了用户的对话体验的同时,减少了训练师的维护成本。
表格结构的优点
上面列举的两个场景的业务知识均由结构化的数据组成,这种情况下,使用平台提供的表格知识体系能够使搭建变得更加灵活,表格具有一下几个优点:
维护难度低:相较于多维知识图谱,二维表格已经能够满足绝大多数使用场景,同时又能降低训练师理解成本,并且操作更友好。表格支持通过上传excel或者直接编辑的形式,来维护表格内容。
数据格式丰富:表格的单元格支持维护文本、关联实体、数字、日期、时间、多媒体答案等丰富的数据格式;此外,每种数据格式都有相对应的判断逻辑,使得对话中查表更加灵活便捷。
使用场景多样:知识问答FAQ和对话流程FLOW中均可以使用表格实现按条件查表回复。
表格管理
点击机器人菜单“搭建-资源-表格”,就可以进入到表格管理界面,训练师可以在这个页面中维护当前机器人的所有表格。
点击“新建表格”按钮,输入表格名称,选择表格类型即可创建一个新的表格。
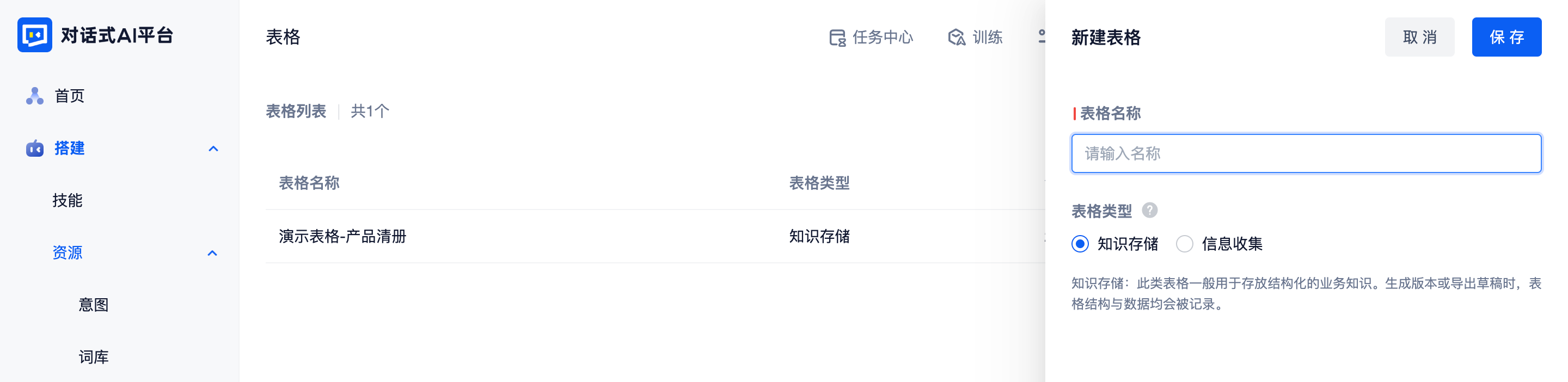
平台提供“知识存储”和“信息收集”两种类型的表格:
- 知识存储:在生成版本或者导出草稿时,表格结构与数据均会被记录。
因此,此类表格比较适合训练师在表格中搭建沉淀的业务知识,可以在技能中使用。 - 信息收集:生成版本或导出草稿时,只会记录表格结构。数据需要单独定期导出表格内容。
因此,此类表格一般用于收集用户在对话中提供的,希望机器人留存的信息。
- 知识存储:在生成版本或者导出草稿时,表格结构与数据均会被记录。
warning
表格类型一旦选定后不可再更改。
caution
信息收集场景中,表格内的数据量会随着会话量而变化。一些流量较大的收集类机器人表格中收集的信息很可能达到万级、十万级。
如果错误地使用“知识存储”类表格进行“信息收集”的操作,表格中的数据量过大时,可能会导致创建版本或导出机器人的服务报错或操作失败。
- 表格创建成功后,会按创建时间顺序展示在列表中,展示项包括:表格名称、表格类型、创建时间及操作按钮。
表头管理
点击“打开表格”按钮即可进入对应表格内部,表格左上角的“返回”展示表格名称,点击即可返回表格管理列表。

新创建的表格如果还未设置任何表头字段,就无法添加表格数据。
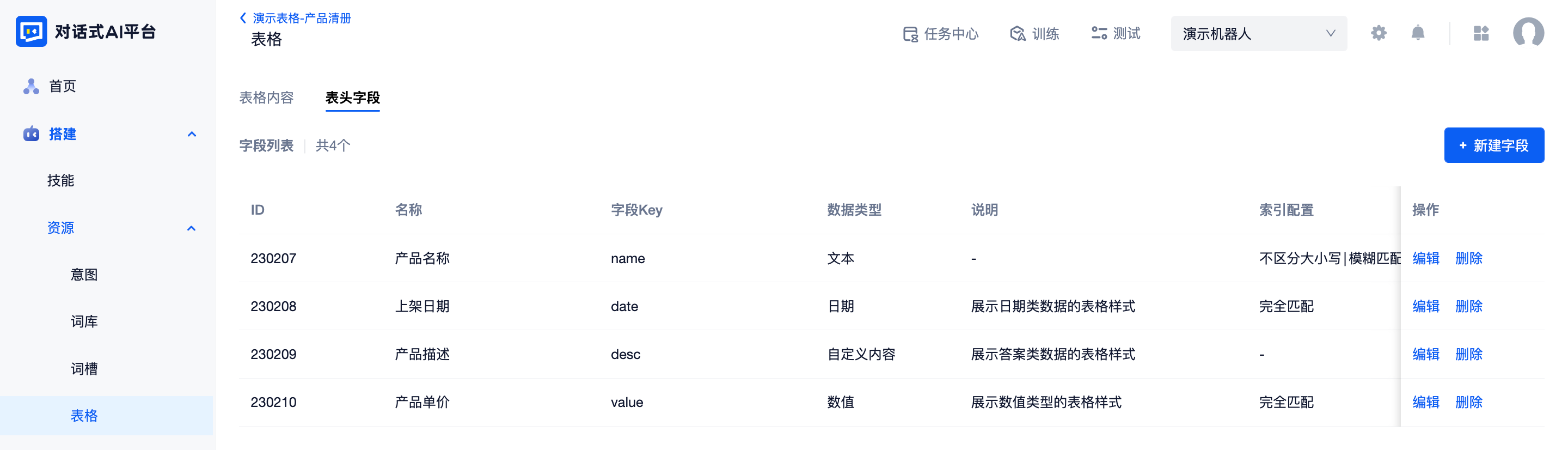
切换页面到“表头字段”即可对表头进行管理。表头是表格的骨架,根据业务场景定义好表头字段才能为后续工作打好基础。点击“新建字段”按钮,配置字段属性,即可创建一个新的字段。
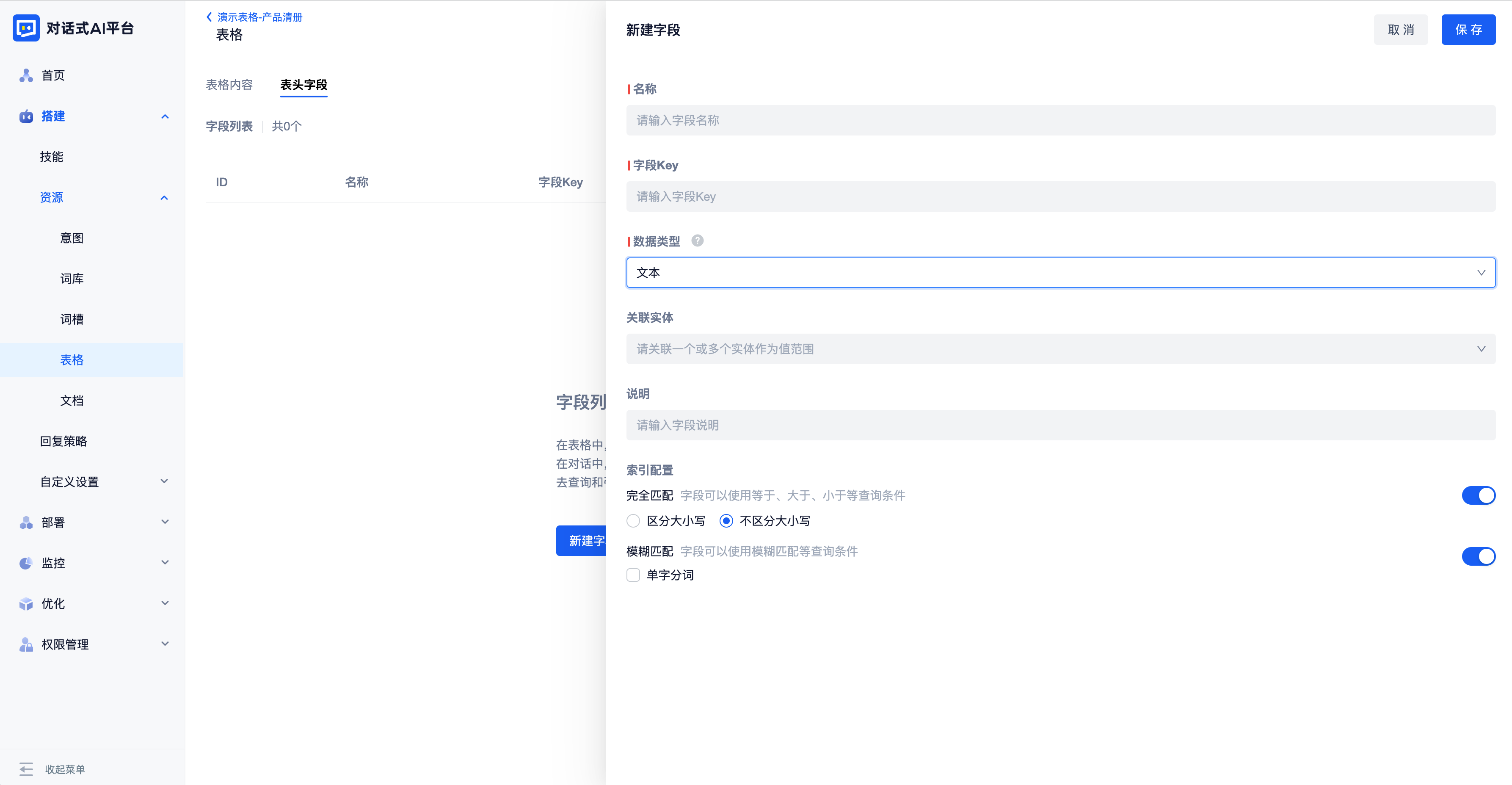
名称:字段的名称,将会作为表格列名展示。创建后可以修改,在当前表格内不可重复
字段Key:字段的唯一识别标识(用于接口处理,仅允许英文字母,数字和下划线),将会展示在导出的excel的表头。创建后不可更改,在当前表格内不可重复
说明:字段的补充描述,将会展示在新增一行表格数据时的输入框提示中。
数据类型:平台支持配置常见的六大类业务数据类型:纯文本、数值、日期、时间、日期和时间,以及配置答案。创建保存后不可二次更改。
为字段配置正确的数据类型,可以简化表格数据操作:
数据类型 编辑框样式 检索策略 纯文本 文本输入框/下拉选择(关联实体) 支持按照ascll码值进行比较
支持按语义进行模糊匹配日期时间 日期时间类的选择控件 支持进行日期时间的比较 数值 数值输入框,支持输入整数和浮点数 支持进行数值的比较 配置答案 答案编辑组件,可添加多媒体内容 不可检索 关联实体:数据类型选择“纯文本”时,可以选择关联一个或多个实体。如果字段关联了实体,输入框会变为下拉选择框,通过选择实体的实体值即可填充。
索引配置:如果字段可能作为表格查询条件,就需要为其配置索引(日期时间及数值类型默认配置了索引,配置答案类型目前不支持作为查表条件,因此只有纯文本类型需要进行索引配置);如果字段不会作为查询条件,只会成为返回信息,则无需配置索引。创建保存后不可二次更改。
note
- 索引配置开启“完全匹配”,字段可以使用等于、大于、小于、为空等查询条件
- 索引配置开启“模糊匹配”,字段可以使用模糊匹配查询条件。如果机器人语言为中文,模糊匹配中还支持配置自定义分词模式,默认是按语义分词,也可改为单字分词。
表格字段创建成功后,会按创建时间由先到后地展示在列表中,展示项包括:ID、名称、字段Key、数据类型、说明、索引配置及操作按钮。
维护表格内容
回到“表格内容”页,这时表头字段已经存在,表头顺序默认按照创建顺序从左到右依次排列。
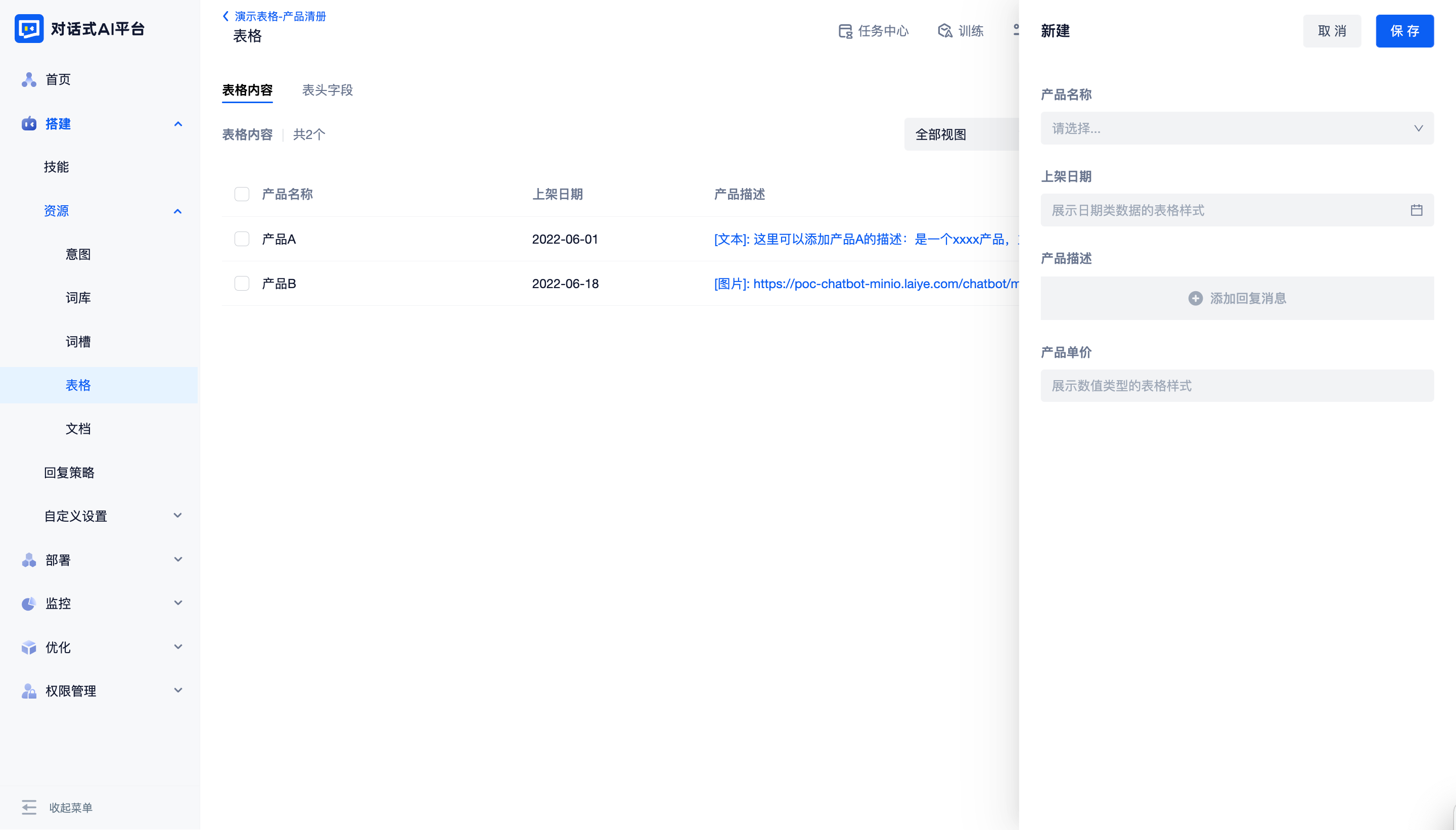
点击“新增一行”按钮,填写表格内容即可。平台会根据表格字段的数据类型提供最适合的输入控件。
配置列可以自定义表头的顺序和表格中表头的可见性(只影响页面展示效果,不会影响新增编辑时的顺序)
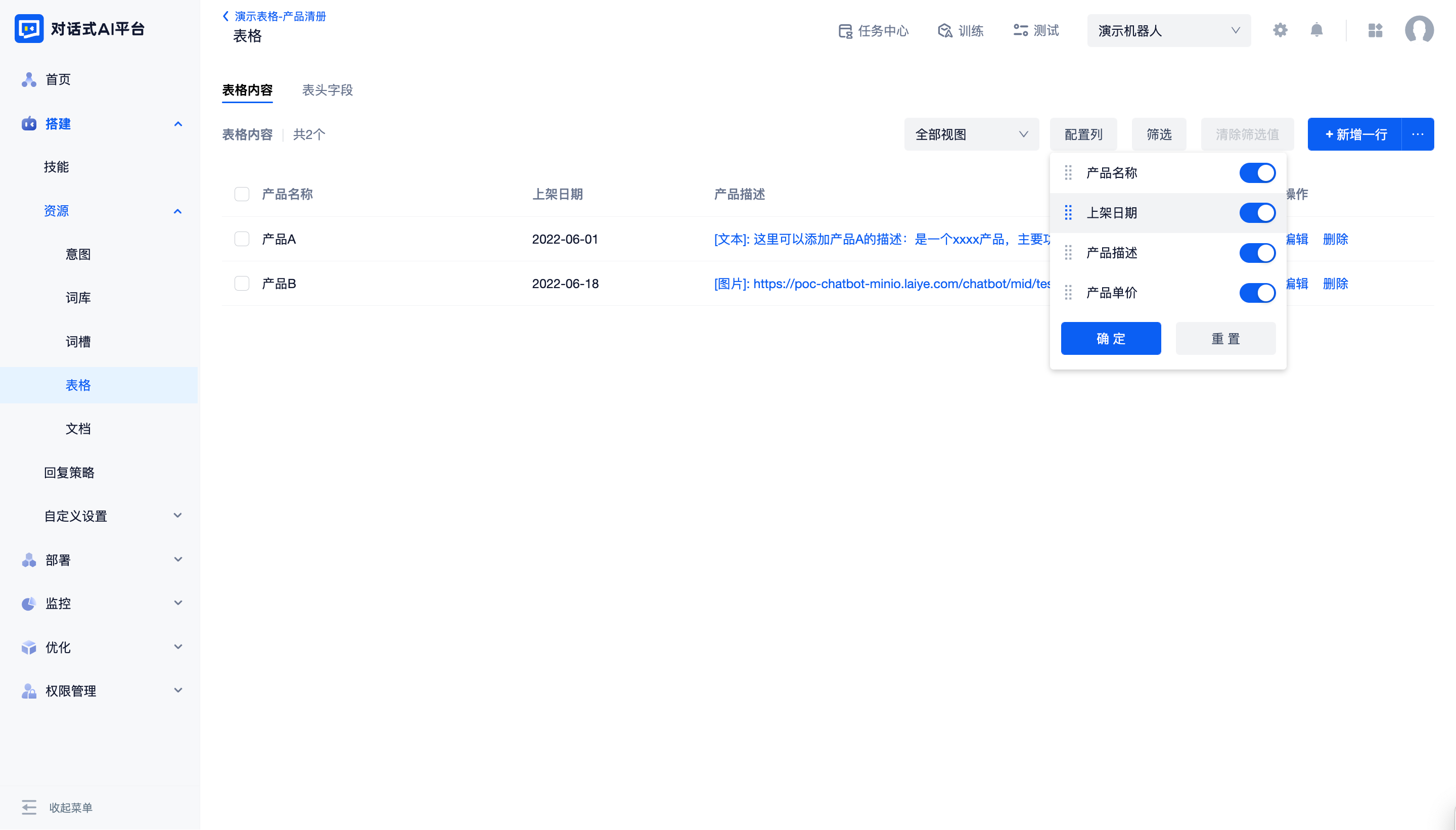
表格内容过多时,可以通过“筛选”控件缩小查看范围。可以选择任意表头字段(数据类型为配置答案除外)进行且关系的筛选,筛选条件与表头的索引 配置相关。
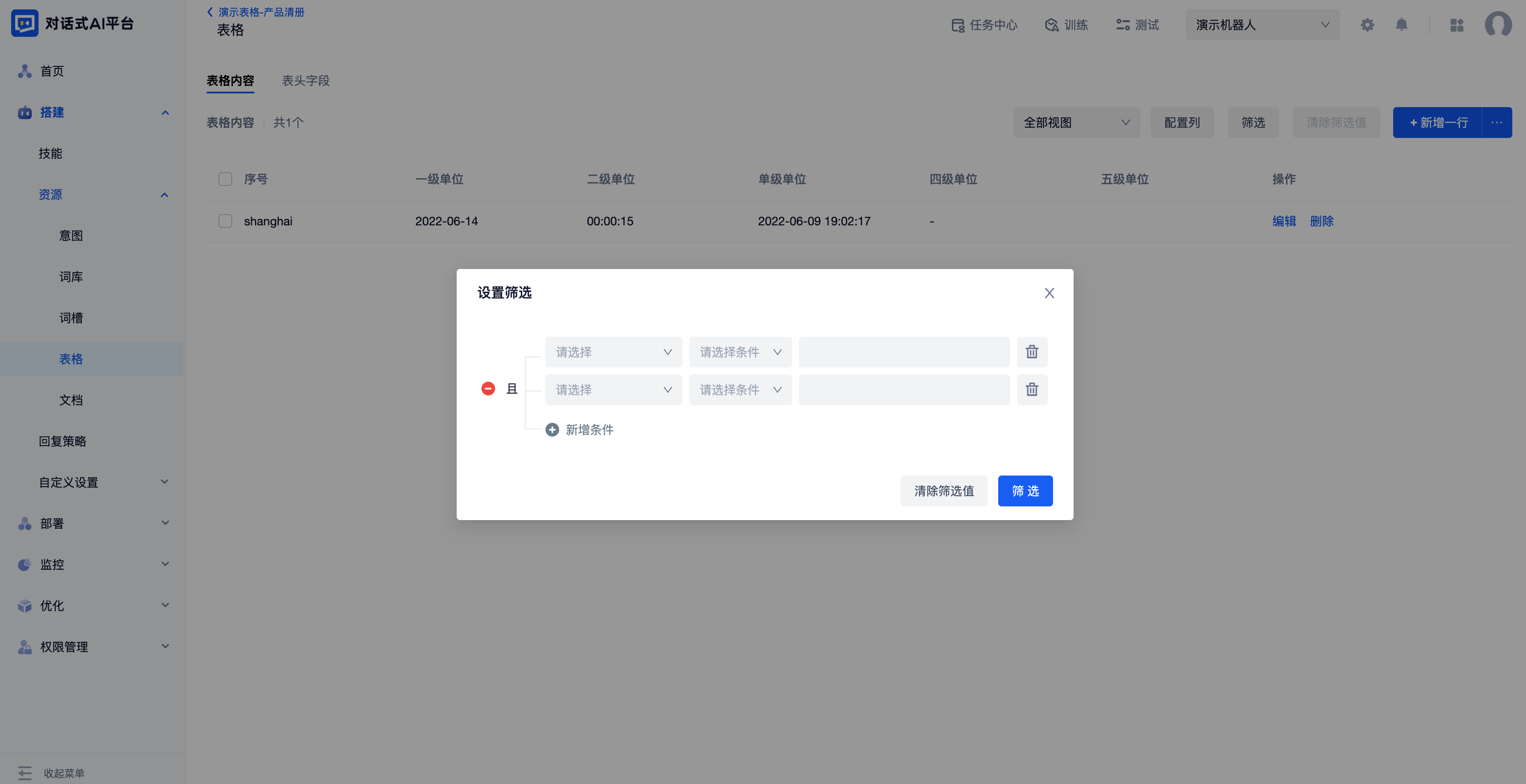
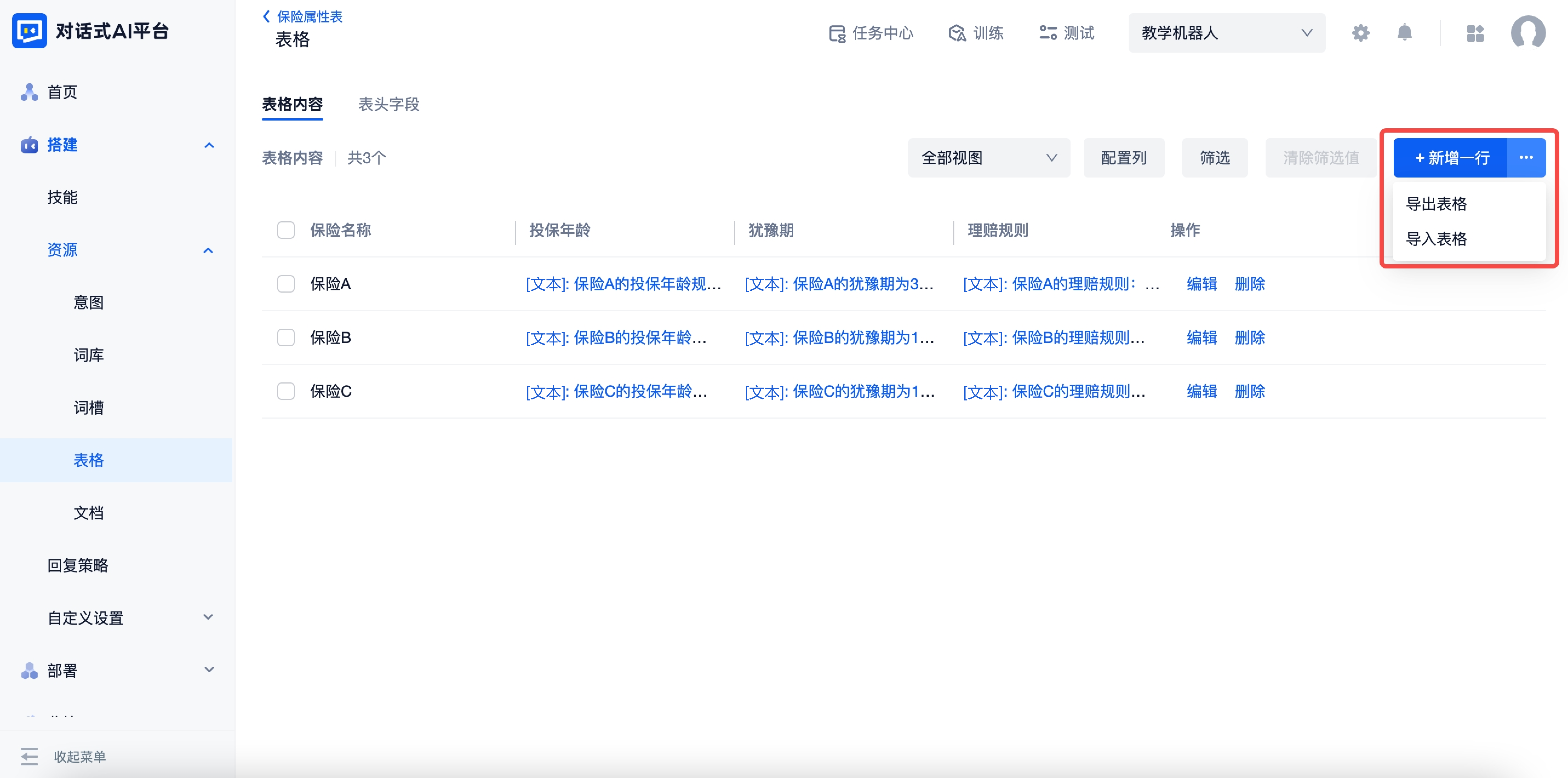
导入与导出
点击新建一行右侧扩展按钮,“导出/导入表格内容”支持对表格数据进行批量操作。目前表格的导入导出仅处理表格内容部分,不包含表头字段配置。
导入判断与逻辑(待研发补全)
- 导入表格内容的判断逻辑:
- 更新还是插入:根据ID对比插入还是修改,相同更新,不同插入
- 导入表格内容字段范围:导入文档根据表头字段的key来匹配,仅导入key对应的
- 导入表格内容校验与处理:
- 文本:文本
- 文本(关联实体):
- 导入的数据不存在与关联的实体的实体中,如何处理
- 日期:
- 时间:
- 日期时间:
- 正常格式yyyy-MM-ddTHH:mm:ss.SSSZ(UTC时间?北京时间?导入到正式环境是否会做时区处理?)
- 是否有其他可以转换的格式:yyyy-MM-dd?
- 如果不是可以转换的格式,如何处理
- 数值:
- 整数
- 如果是小数,小数点如何保留
- 如果不是数字,如何处理
- 配置答案:json格式错误如何处理
- 导入表格是否涉及权限判断:
- 导入表格内容的判断逻辑:
导出样式与逻辑(待研发补全)
- 导出表头的展示:表头字段key
- 导出表头的顺序:
- 导出表格内容的展示:
- 文本:文本
- 日期:
- 时间:
- 日期时间:yyyy-MM-ddTHH:mm:ss.SSSZ(UTC时间?北京时间?导入到正式环境是否会做时区处理?)
- 数值:浮点数?
- 配置答案:json格式
- 导出表格内容的顺序:
- 导出表格是否涉及权限判断:
在技能中使用表格
维护好的表格数据可以在知识问答FAQ和对话流程中被使用。
在对话中,机器人会根据技能中配置的查表条件进行表格查询。查表结果会作为答案回复给用户,或被填充到配置好的词槽中。
详情请见个性化回复和表格读取单元