Invoke large models
Command Description
Call large models to answer questions or process natural language
Command Prototype
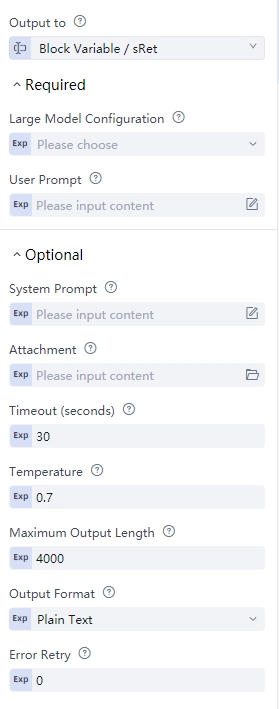
LLM.GeneralChat({"name":"","model":"","base_url":"","api_key":""},"","","",30,0.7,4000,"text",0)
Command parameters
| parameter | mandatory | type | default value | Instructions |
|---|---|---|---|---|
| config | True | object | {"name":"","model":"","base_url":"","api_key":""} | Configure the model by filling in the model name, model access address, and API key |
| content | true | string | "" | user prompt |
| prompt | false | string | "" | system prompt |
| file_path | false | string | "" | Image path (JPEG/PNG/BMP, maximum 10MB, some models may not support all three formats of images) |
| timeout | false | int | 30s | Timeout (seconds) |
| temperature | false | int | zero point seven | temperature |
| max_output_length | false | int | four thousand | Maximum output length (token) |
| format | false | object | Plain text, JSON format | Choose the format of the content returned by the large model |
| max_retry_count | false | int | three | When the large model returns an error or returns a structure that does not conform to the output format, the context content will be resent to the large model, allowing it to output again. The maximum number of retries is 3 |
Running instance
/*************************** Input Text **********************************
Command Prototype:
LLM.GeneralChat({"name":"","model":"","base_url":"","api_key":""},"","","",30,0.7,4000,"text",0)
Input Parameters:
config -- Model configuration, specify model name, access URL, API key
content -- User prompt
prompt -- System prompt
file_path -- Image path (JPEG/PNG/BMP, max 10MB, some models may not support all three formats)
timeout -- Timeout in seconds
temperature -- Temperature
max_output_length -- Maximum output length (tokens)
format -- Format of the LLM response content
max_retry_count -- Maximum retry attempts on failure
Output Parameters:
sRet -- Command execution result assigned to this variable
Important Notes:
Deleting the LLM environment configuration file or removing the invoked LLM in the configuration management interface will prevent the command from running normally
*********************************************************************/
//Using Pre-configured Model:
LLM.GeneralChat({"name":"deepseek"},"Help me translate the content in the image into Chinese","You are a translator with professional translation expertise",'''C:\Users\Administrator\Downloads\1280X1280.PNG''',30,0.7,4000,"text",0)
//Using Custom Model Configuration:
LLM.GeneralChat({"model":"openai/deepseek-chat","api_key":"123456789","base_url":"https://api.deepseek.com"},"Help me translate the content in the image into Chinese","You are a translator with professional translation expertise",'''C:\Users\Administrator\Downloads\1280X1280.PNG''',30,0.7,4000,"text",0)
Visual Example