词库
本章节将讲解:什么是实体、专有词汇,以及如何在平台创建和使用实体词库。
基本概念
实体 是自然语言中的信息元素,由字词或短语组成。包括人名、组织机构名、地理位置、时间、日期等。
note
实体本身与意图、技能均无关,它是解决很多自然语言处理问题的基础
—— ——不管是否在意图中,机器⼈仅根据用户的话中就能够抽取出实体。
实体抽取 是解决很多自然语言处理的基础,目的是从自然语言文本中抽取出关键信息,更好的理解和处理自然语言。它主要做两件事情:
- 抽取出文本中的实体值或实体值的多种说法。
如:北京、帝都、首都、中国首都。
- 将抽取出来的片段归一化为标准实体值。
如:帝都的天气怎么样,将“帝都”归一化为“北京”,机器人只需要处理“北京的天气怎么样”就可以。
平台将实体分为 枚举实体、正则实体和 预设实体 三种实体类型,用于不同的实体抽取场景中。
枚举实体
枚举实体指实体值可枚举,根据词表匹配进行归一化的实体。理论上,每个实体值添加的多种说法越多,在进行实体抽取时,越容易抽取到该实体。
- 实体名称:从用户语句中提取的关键信息名称,一般表示同一类领域词。
例如:城市、食材、订单号、品牌名称、购买渠道等等。
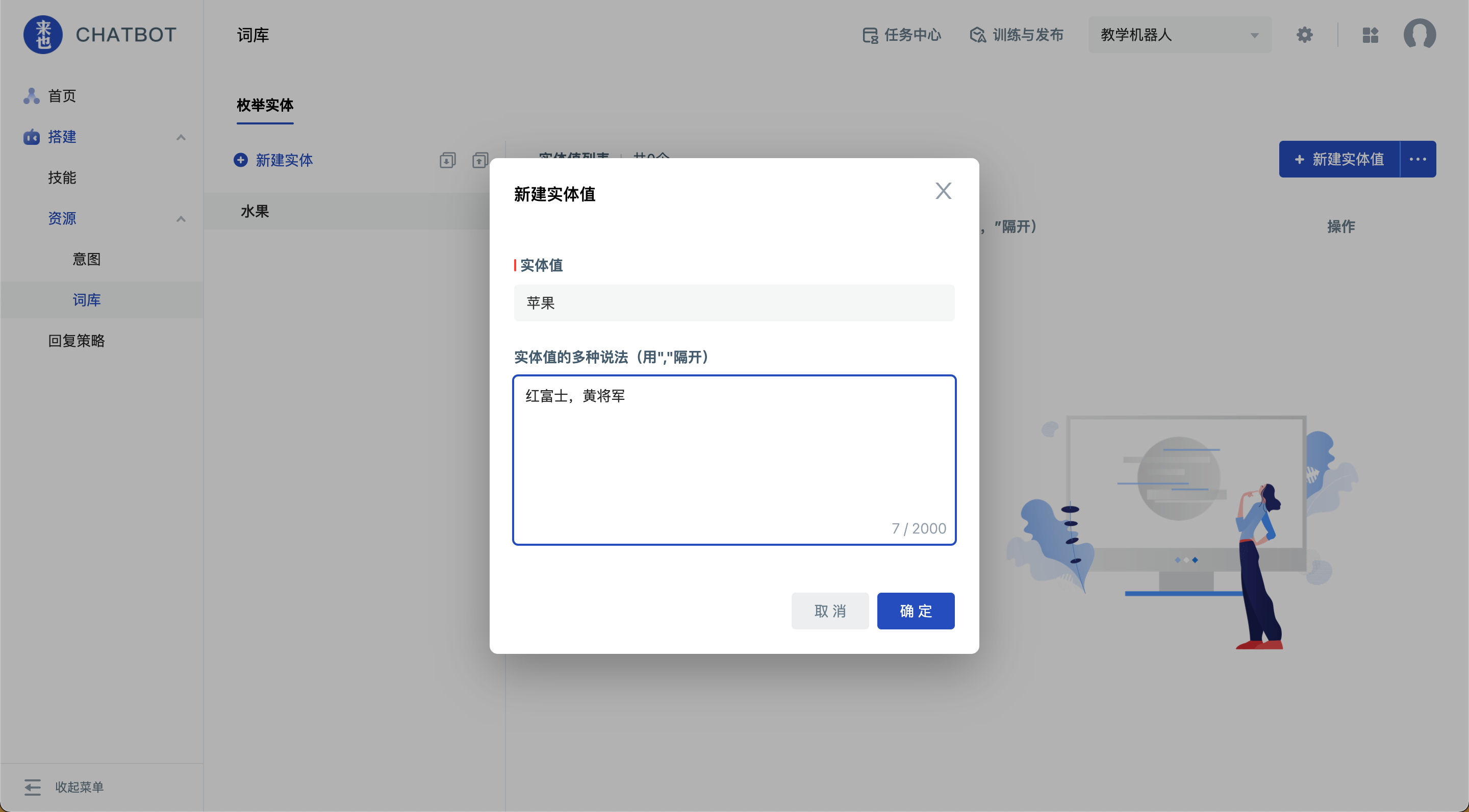
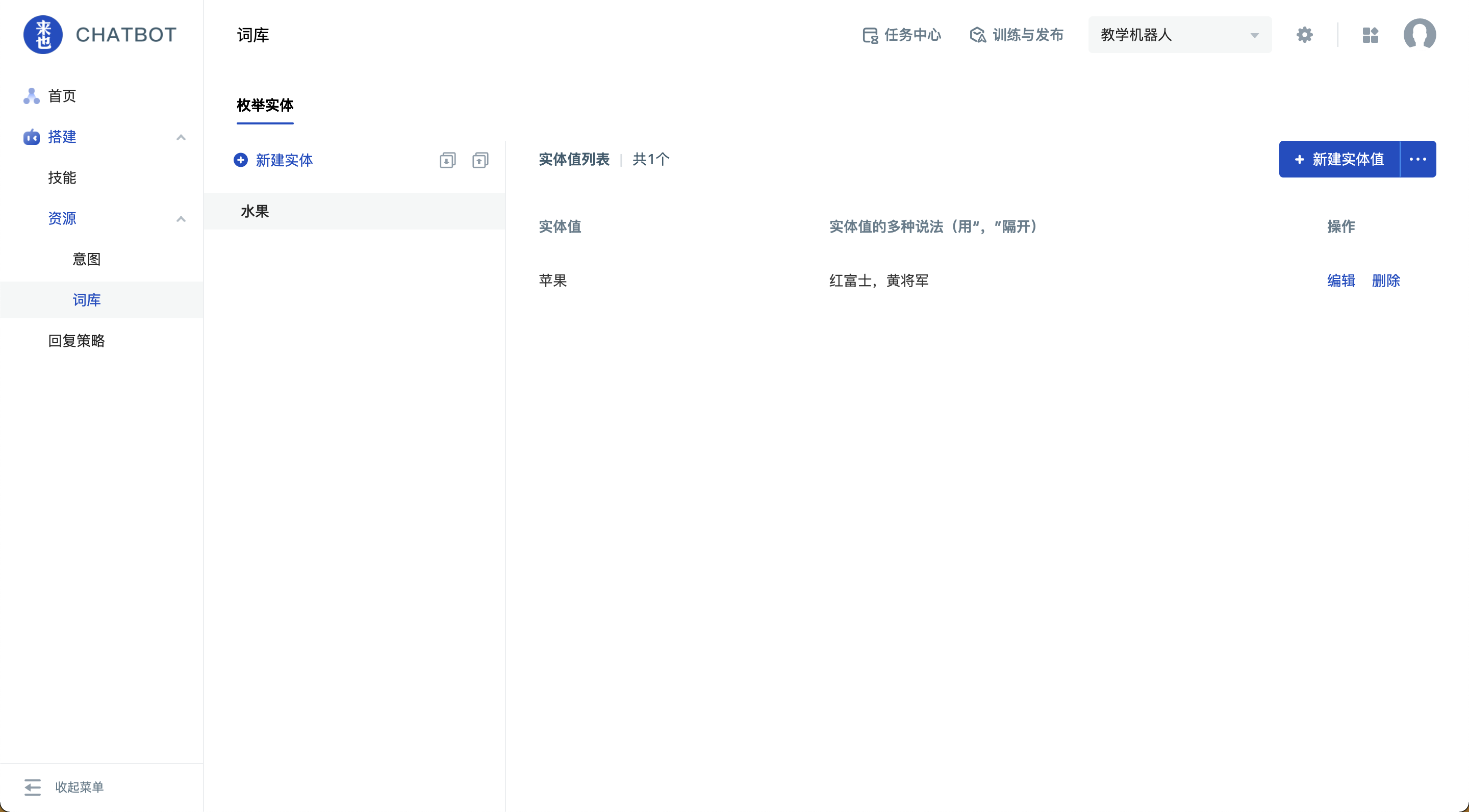
- 实体值:表示信息通用的标准说法,每一个实体,都至少需要提供一个实体值。
例如:城市的标准实体值有“北京”、“上海”、“深圳”等。
- 实体值的多种说法:表示标准实体值的多种说法。每个多种说法都是同样含义的,用户消息中包含任意一个多种说法,都会归一化为标准实体值。
例如“北京”的多种说法有“帝都”、“首都”、“中国首都”等。都能被机器人通过实体抽取获得,并都归一化为实体值“北京”
编辑与新建
从菜单“搭建-资源-词库”,就可以进入到实体管理界面。
点击“新建实体”按钮,输入实体名称并回车即可创建一个新的枚举实体,鼠标悬浮可以编辑和删除当前实体。
点击“新增实体值”,可逐一添加枚举实体的实体值和多种说法。
批量处理
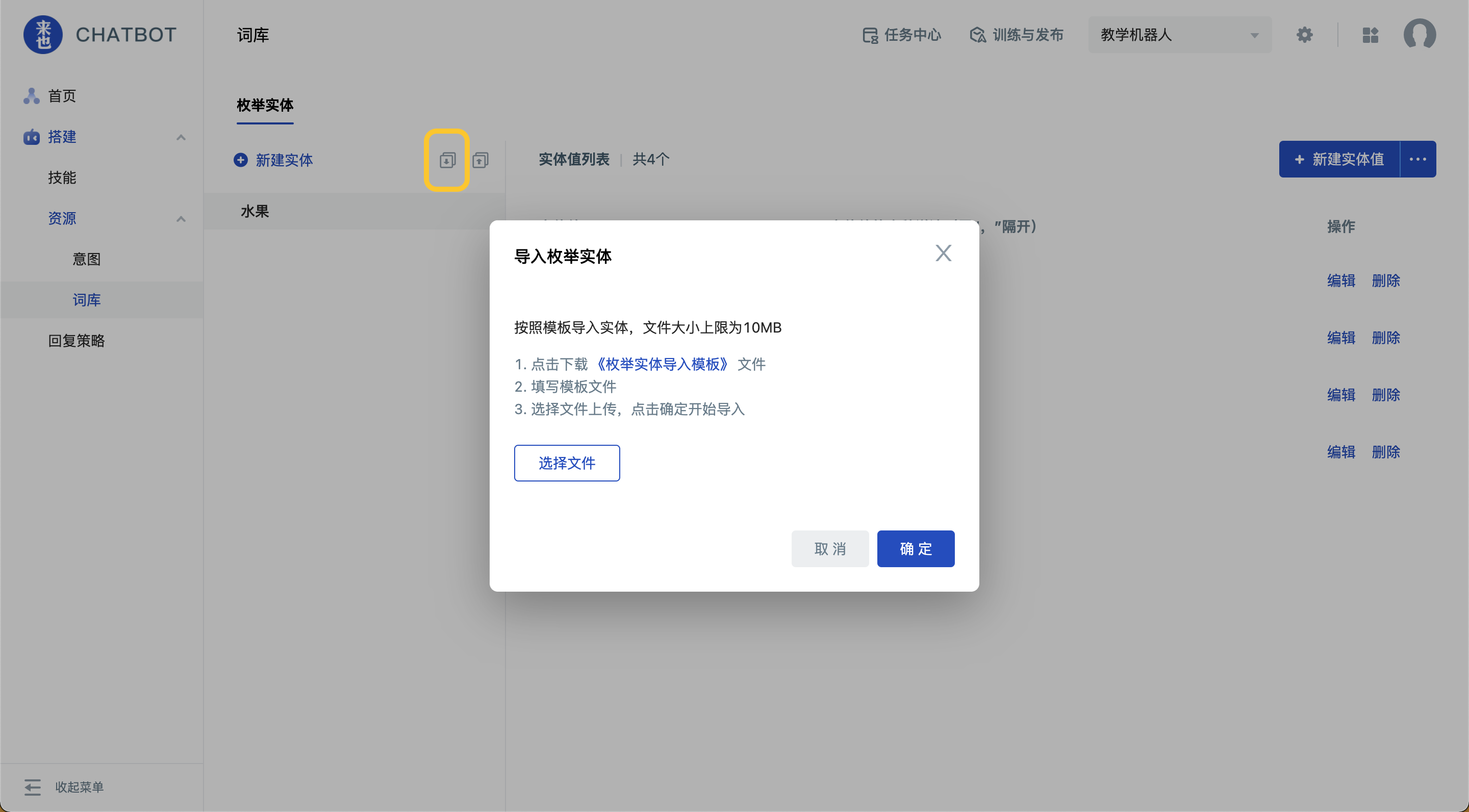
- 点击左栏“新建实体”第一个按钮,可以批量导入多个枚举实体
caution
批量导入多个枚举实体时:
a. 实体名称和实体值均为新增逻辑:增加平台没有的内容,不更改平台已有的内容。
b. 实体值的多种说法为覆盖逻辑,即用文件中的多种说法直接覆盖平台上的数据
点击左栏“新建实体”第二个按钮,可以批量导出全部枚举实体

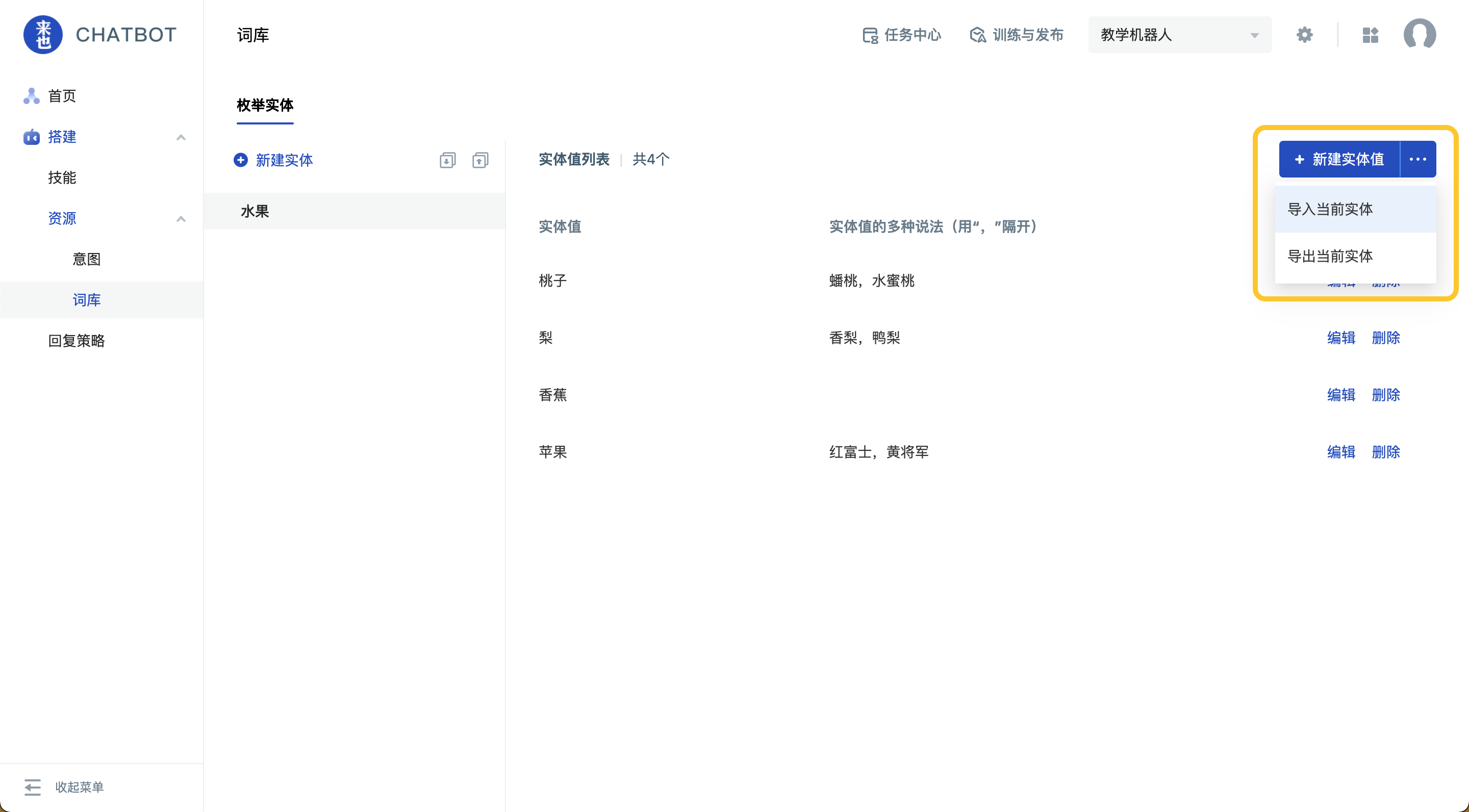
点击新建实体值右侧按钮,可批量导入或导出当前实体的实体值。
caution
批量导入当前实体的实体值时:
a. 实体值为新增逻辑:增加平台没有的内容,不更改平台已有的内容。
b. 实体值的多种说法为覆盖逻辑,即用文件中的多种说法直接覆盖平台上的数据
正则实体
有些实体需要匹配规则,而不是匹配具体字词。 例如,身份证号码、手机号、订单号、牌照等都可以使用正则表达式实体,通过正则表达式进行匹配,识别出用户消息中的片段,作为实体抽取结果。
点击机器人菜单“搭建-资源-词库”,就可以在正则实体切签查看全部正则实体的详情。
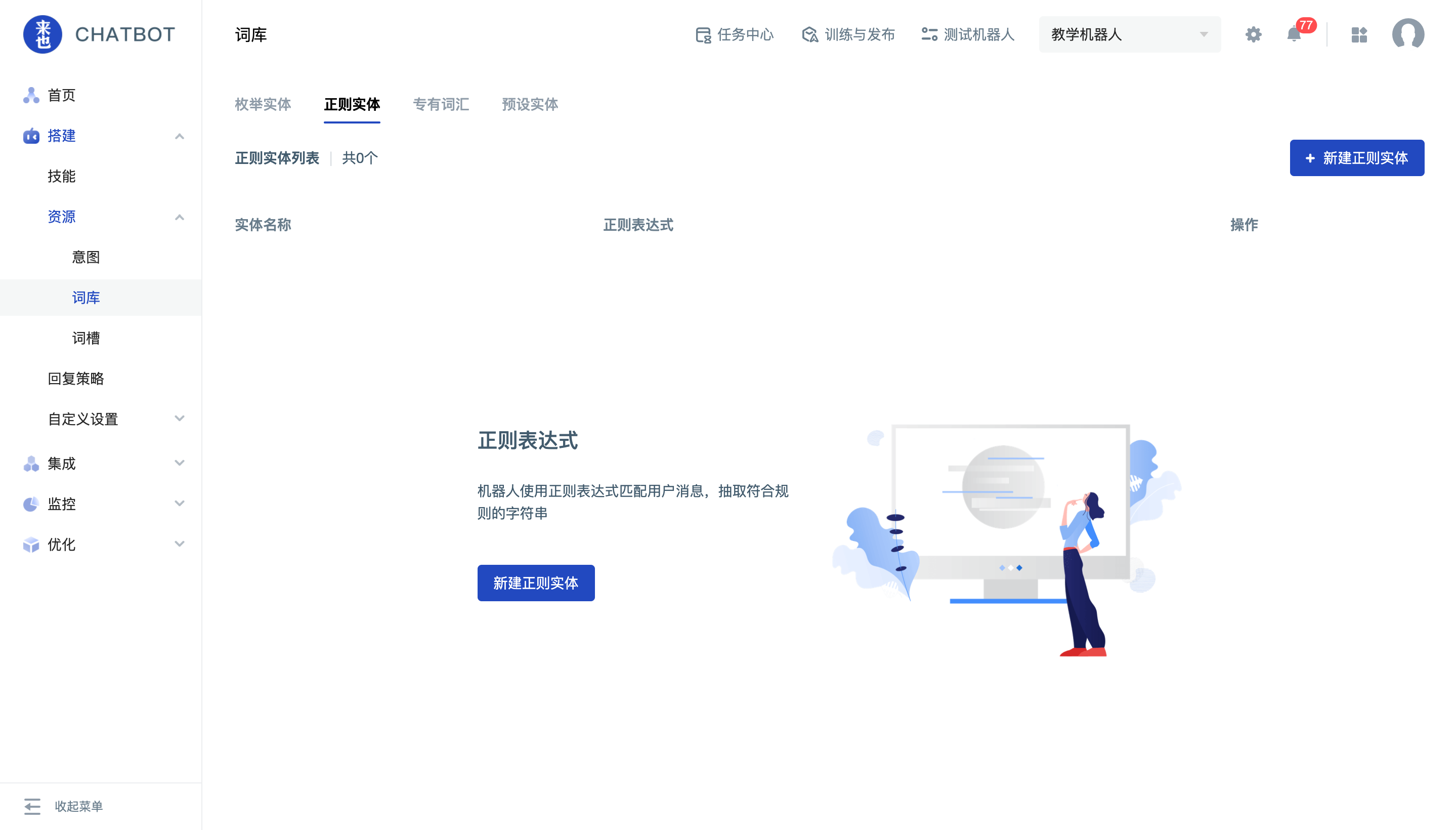
点击“新建实体”,在弹窗中,输入实体名称、正则表达式及正则标签。
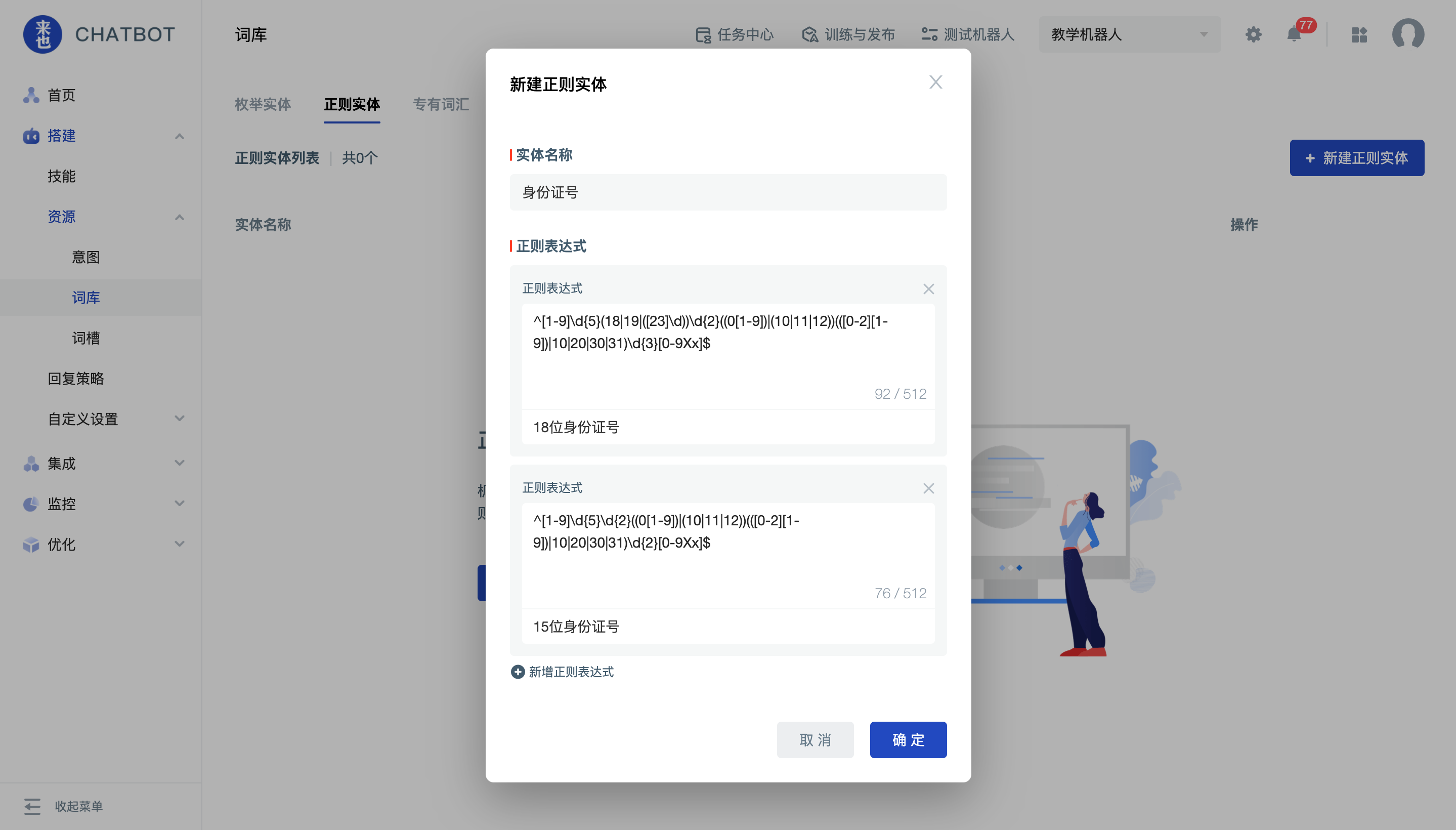
配置完成后,先测试一下待匹配文本的抽取是否符合预期。之后点击保存即可创建成功。
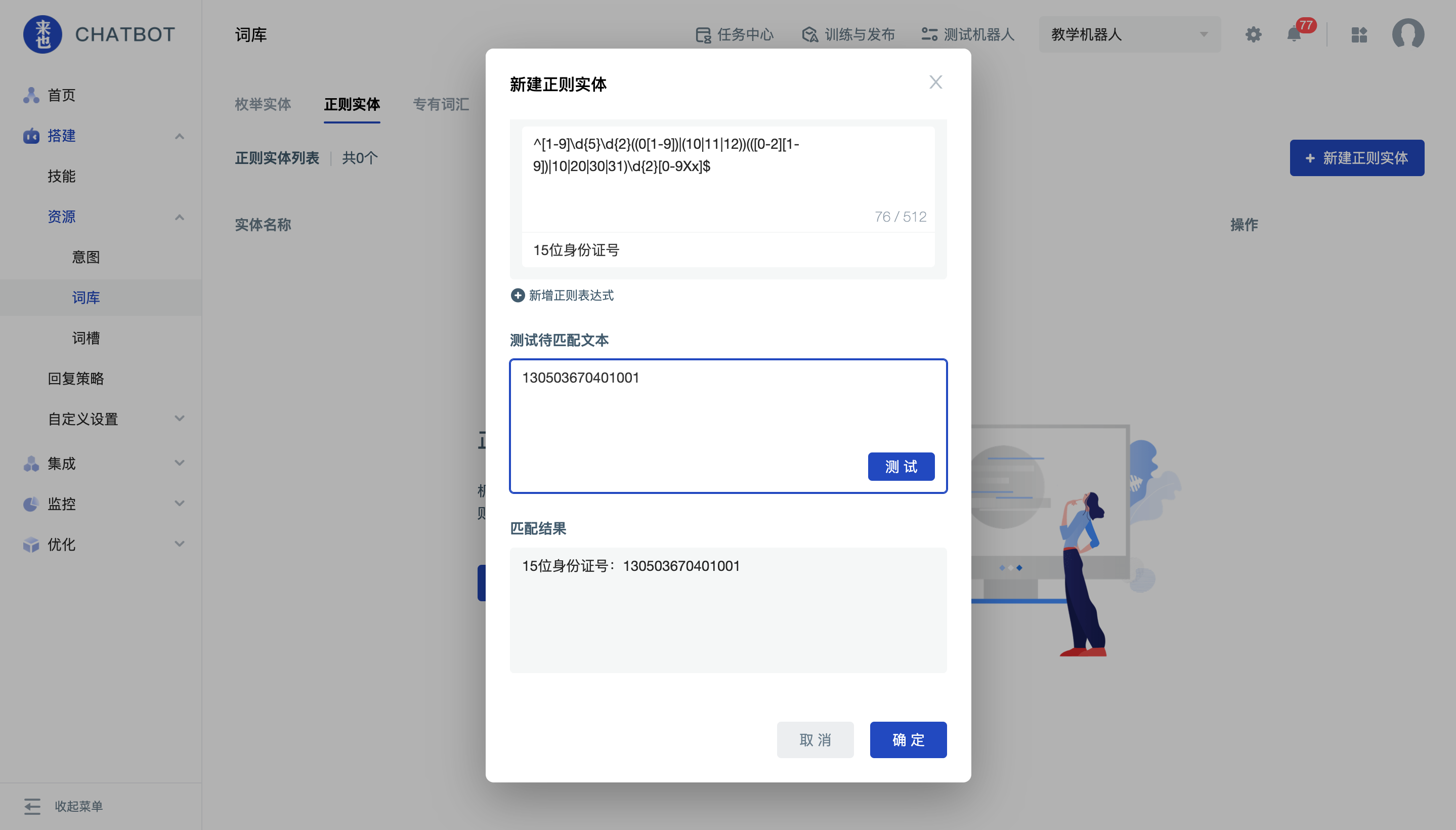
常用的正则表达式
QQ号:[1-9][0-9]{4,}
手机号:(13[0-9]|14[579]|15[0-3,5-9]|16[6]|17[0135678]|18[0-9]|19[89])[ -]?(\d{4})[ -]?(\d{4})
微信号:\^[a-zA-Z][a-zA-Z0-9_-]{5,19}$
身份证号:^(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)$
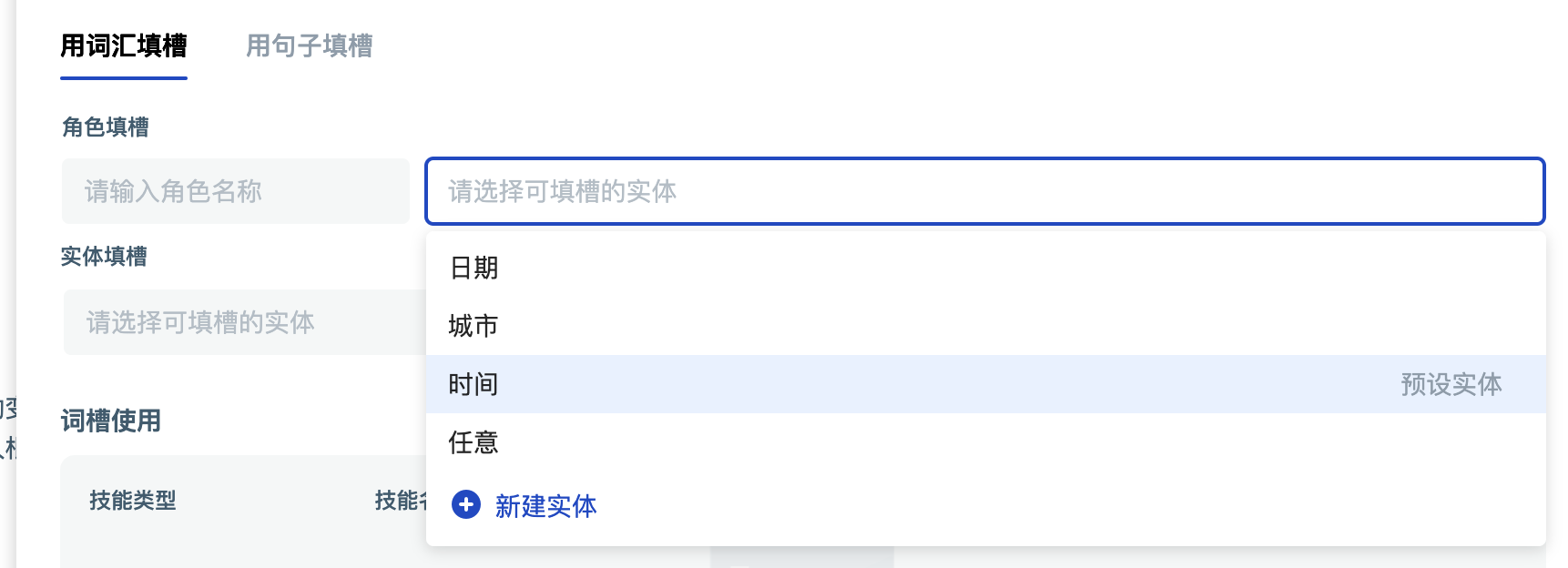
预设实体
预设实体是平台提供的预置好的实体,用于处理常见且不可枚举或正则计算的实体。目前有四类:日期、时间、城市及任意。
点击机器人菜单“搭建-资源-词库”,就可以在预设实体切签查看全部预设实体的详情。

这些实体无需配置就可以直接在词槽、意图中直接使用。
专有词汇
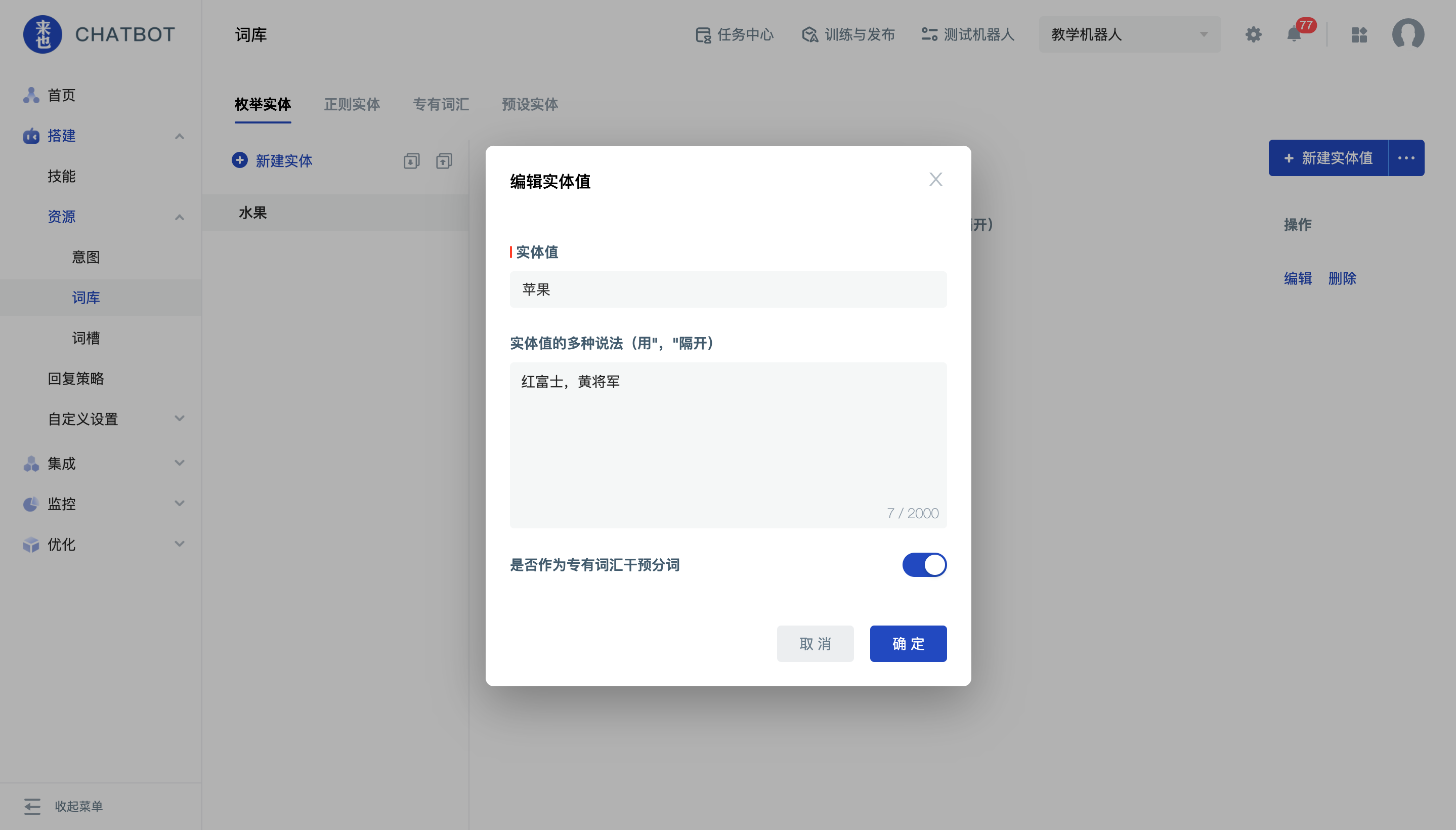
专有词汇主要影响问答对话的分词服务,添加专有词汇后,机器人将会把这个词当成一个整体进行处理,不再进行分词。
在枚举实体中,选择需要添加专有词汇的实体值,点击编辑,并开启 作为专有词汇干预分词 开关,即可成功添加专有词汇。
在专有词汇切签也可以管理已开启干预的列表,点击移除操作后,该实体将不再作为专有词汇干预分词。

实体消歧
当用户语句同一个片段中,抽取到多个值,当其文本关系为“包含”时,提供一下三种冲突处理策略配置:
- 不处理,全部返回(默认策略)
policy:0 - 当抽取到的值属于同一实体时,去掉被包含的值,返回最长的值。
policy:1 - 不判断抽取到的值是否属于同一实体,直接去掉被包含的值,返回最长的值。
policy:2
- 不处理,全部返回(默认策略)
配置方式:根据机器人具体场景,选择冲突策略并复制:
- 全部返回
- 同实体下,返回最长
- 返回最长
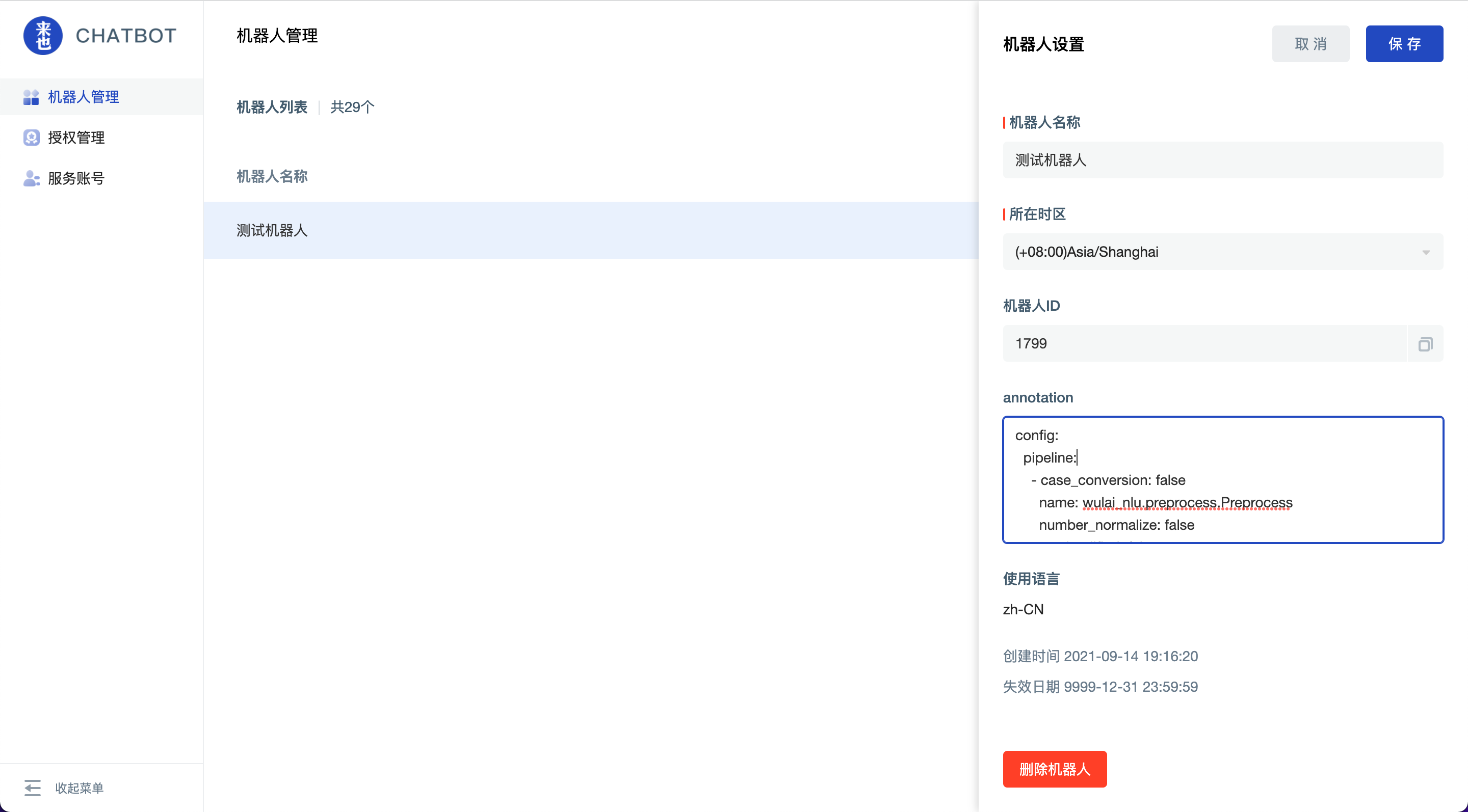
config:
pipeline:
- case_conversion: false
name: wulai_nlu.preprocess.Preprocess
number_normalize: false
to_simplified: false
- name: JiebaTokenizer
- name: wulai_nlu.custom_entity_extractor.CustomEntityExtractor
catelog:
- sys.city
- sys.date
- sys.time
policy: 0
- name: wulai_nlu.keyword_classifier.KeywordClassifier
- name: wulai_nlu.intent_searcher.IntentSearcher
- name: wulai_nlu.example_classifier.ExampleClassifier
threshold_entity: 0.6
threshold_intent: 0.5
threshold_ngram: 0.8
template_only: true
- name: wulai_nlu.rerank_classifier.RerankClassifier
- name: FallbackClassifier
ambiguity_threshold: 0
threshold: 0.75
config:
pipeline:
- case_conversion: false
name: wulai_nlu.preprocess.Preprocess
number_normalize: false
to_simplified: false
- name: JiebaTokenizer
- name: wulai_nlu.custom_entity_extractor.CustomEntityExtractor
catelog:
- sys.city
- sys.date
- sys.time
policy: 1
- name: wulai_nlu.keyword_classifier.KeywordClassifier
- name: wulai_nlu.intent_searcher.IntentSearcher
- name: wulai_nlu.example_classifier.ExampleClassifier
threshold_entity: 0.6
threshold_intent: 0.5
threshold_ngram: 0.8
template_only: true
- name: wulai_nlu.rerank_classifier.RerankClassifier
- name: FallbackClassifier
ambiguity_threshold: 0
threshold: 0.75
config:
pipeline:
- case_conversion: false
name: wulai_nlu.preprocess.Preprocess
number_normalize: false
to_simplified: false
- name: JiebaTokenizer
- name: wulai_nlu.custom_entity_extractor.CustomEntityExtractor
catelog:
- sys.city
- sys.date
- sys.time
policy: 2
- name: wulai_nlu.keyword_classifier.KeywordClassifier
- name: wulai_nlu.intent_searcher.IntentSearcher
- name: wulai_nlu.example_classifier.ExampleClassifier
threshold_entity: 0.6
threshold_intent: 0.5
threshold_ngram: 0.8
template_only: true
- name: wulai_nlu.rerank_classifier.RerankClassifier
- name: FallbackClassifier
ambiguity_threshold: 0
threshold: 0.75
- 进入机器人管理页面-机器人设置-将复制内容粘贴仅“annotation”字段中: