PDF文字识别
命令说明
将 PDF 指定的页码通过 Laiye Intelligent Document Processing 通用文字识别,识别结果返回 JSON 格式。在识别多页过程中如果其中一页失败则整个识别会返回错误,且会消耗配额
命令原型
jsonRet = Mage.PDFOCRText(config, path,password,all_pg_state,page_cfg,sleepTime,time)
命令参数
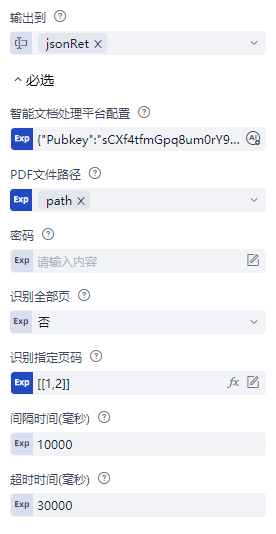
| 参数 | 必选 | 类型 | 默认值 | 说明 |
|---|---|---|---|---|
| config | True | expression | {} | Laiye Intelligent Document Processing 的调用配置 |
| path | True | path | '''C:\Users''' | PDF文件路径 |
| password | True | string | "" | PDF文件密码,无密码不需要填写 |
| all_pg_state | True | boolean | False | 当全部页码设为"是",则识别全部且指定页码输入无效。设为否时,可指定页码识别 |
| page_cfg | True | expression | [[1,2]] | 支持正整数和数组格式,如输入2,则识别第2页;如输入[1,3,5],则识别第1,3,5页;如输入[1,[6,9],4],则识别1,4页和第6到第9页。当识别全部页码设为"是",则识别指定页码的输入失效。超出PDF页码总数的部分会报错,页码重叠部分仅识别1次 |
| sleepTime | True | number | 10000 | 识别PDF每页的间隔时长(以毫秒为单位),默认10000毫秒(10秒)。识别页数较多,间隔较短可能会导致调用频率超限错误 |
| time | True | number | 30000 | 指定等待时间(以毫秒为单位),如果超出该时间,则引发异常。默认30000毫秒(30秒) |
返回结果
jsonRet,将命令运行后的结果赋值给此变量。
运行实例
/**********************PDF文字识别**********************
命令原型:
jsonRet = Mage.PDFOCRText({}, '''C:\Users''',"",false,[[1,2]],10000,30000)
入参:
config--mage配置,需配置Pubkey和Secret.Type:Dict
path--待识别图片的路径.Type:String
password--密码.无密码则不需要填写.Type:String
all_pg_state--是否识别全部页.Type:Bool
page_cfg--识别指定页码.Type:List
sleepTime--间隔时间.默认单位:毫秒.Type:Int
time--超时时间.默认单位:毫秒.Type:Int
出参:
jsonRet:函数调用的输出保存到的变量
注意事项:
需要获取mage对应的Key/Secret和URL
****************************************************/
Dim path='''''' // 待识别PDF的路径
Dim jsonRet="" // 输出结果
jsonRet = Mage.PDFOCRText({"Pubkey":"sCXf4tfmGpq8um0rY9MOvApD","Secret":"KLAhZgzHVqb975HAywi5sAhbxkakSHGx","Url":"https://demo.laiye.com:8082"}, path,"",false,[[1,2]],10000,30000)
TracePrint(jsonRet)
可视化样例