人工智能功能
传统RPA实现的是基于固定规则的流程自动化。而在企业实际业务场景中,还有大量不基于固定规则的业务流程,需要人的认知和判断。 例如:合同是企业业务场景中常见的文档之一,在业务流程中,经常需要阅读电子合同,识别大量文字并从中抽取出甲乙方名称、合同日期等关键信息。 对于这些场景,我们可以使用人工智能(AI,下文将统一使用这一简称)技术,让机器人实现对合同等信息的“认知”,我们称之为“认知自动化”。 因此,RPA和AI一起,将流程自动化与认知自动化结合起来,让企业中更多复杂的、高价值的业务场景实现自动化。
对软件机器人来说,如果说AI是它的大脑,认知能力是它的眼睛、嘴、耳朵,RPA是它的双手。结合了AI能力,RPA从只能帮助基于规则的、机械性、重复性的任务实现自动化, 拓展到了更丰富的业务场景,将物理世界与数字世界有效连接,满足实际业务中更灵活、多元的自动化需求。而企业采用具备丰富AI能力的RPA平台,也可以快速、经济、灵活地将AI技术应用到业务中。
流程创造者中集成了大量的AI能力,并且还会在未来持续增强这部分能力。本章将为大家介绍如何在流程创造者中使用AI能力。
智能文档处理平台
来也科技智能文档处理平台是专门为来也科技流程自动化平台打造的AI能力平台,可提供执行流程自动化所需的各种AI能力。
在用“流程创造者”编写RPA流程时,对于社区版的流程创造者,在联网的前提下,用户登录后,可以使用智能文档处理提供的各类AI能力,进而将图片、文档中的非结构化信息转变成结构化数据; 对于企业客户,智能文档处理平台既可以联网使用,也可以私有部署,对于后者来说,即使不连接互联网,也可以享受智能文档处理的AI能力。智能文档处理还提供了标准化的调用接口,灵活适应业务需求。
智能文档处理的产品特点包括:
- 内置OCR、NLP等多种适合RPA机器人的AI能力。
- 提供预训练的模型,无需AI经验,开箱即用。
- 在预训练之外,也提供定制化的模型,仅需少量配置或训练,即可让AI具有较强的泛化能力。
- 与流程创造者无缝衔接,方便在流程中以低代码的形式使用AI模型。
- 能够识别多种类型的文档,适用于财务报销、合同处理、银行开户等不同的业务场景。
目前,智能文档处理中包含的AI功能如下所示:
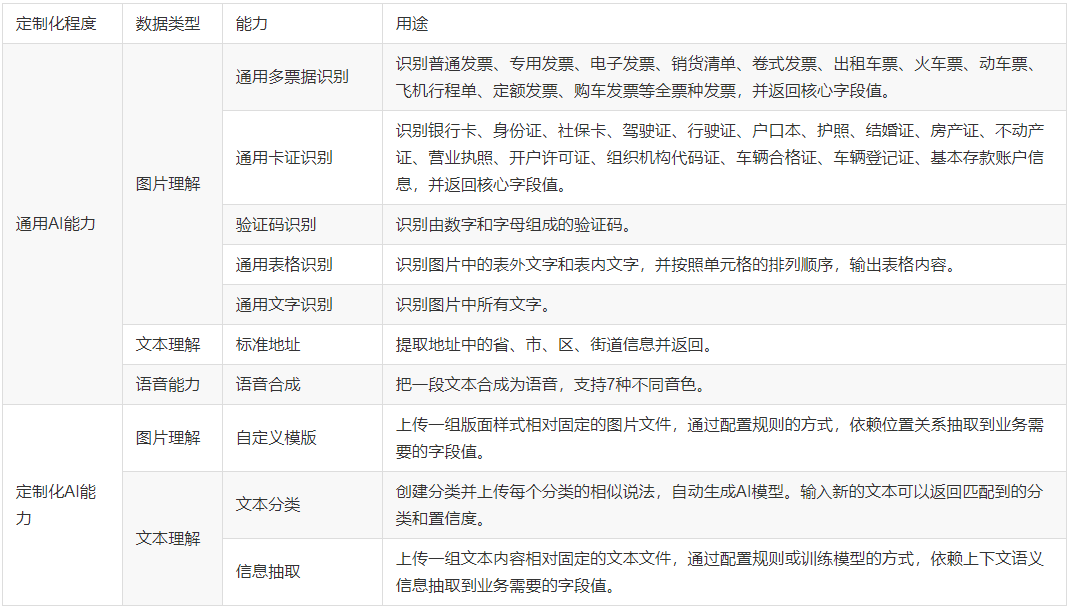
由此可见,智能文档处理中的AI功能非常丰富,而且还在不断的扩展过程当中。功能虽多,但大致可以分为两类:一类称为“通用AI能力”,是指您基本上不需要进行太多的设置,开箱即用的AI功能,其中比较常用的是对图片的各种识别,如标准化的票据(发票、出租车票等)、标准化的卡证(身份证、营业执照等)。另一类称为“定制化AI能力”,是指您在使用这些AI能力之前,还需要花费一番功夫,在智能文档处理中先做一定的配置或训练才可以,用起来稍微麻烦一点儿,但能处理更加广泛的数据。
考虑到内容侧重,本章暂时只介绍“通用AI能力”中的图片识别功能。其他功能将在后续篇章中讲述,也可参考智能文档处理的在线帮助。
流程创造者中的智能文档处理命令
在流程创造者中,已经把智能文档处理的很多AI功能都包装成了相应的命令,这些命令被放在一个叫做“智能文档处理”的分类里面。其中又包含了“信息抽取”、“通用卡证识别”等二级分类,每个二级分类再展开以后,下面还有很多命令。

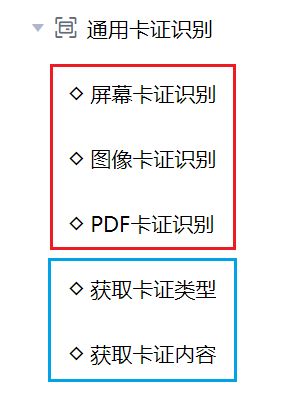
比如,我们把“通用卡证识别”这个二级分类展开,可以看到下面还有“屏幕卡证识别”、“图像卡证识别”、“获取卡证类型”等五条命令,这五条命令有什么区别,各用在什么场合呢?
其实,无论是“通用卡证识别”也好,还是“通用文字识别”或者“通用票据识别”也好,这种“识别”类的智能文档处理命令,最主要的使用过程都是分两个步骤进行的:
- 从指定的图像中,识别出所有结果
- 从识别的结果中,获取出所需信息
上图中红框表示的命令,实际上是在做第1步,因为这些命令的最后两个字都是“识别”;上面蓝框中的命令,实际上是在做第2步,因为它们的前两个字都是“获取”。所以,如果我们要用智能文档处理来识别一张身份证的话,需要先根据数据源的不同,从红框里面选择一条命令,再根据要获取的具体信息,从蓝框里面选择一条命令。
红框里面的三条命令,主要区别在于图像来源的不同,其中:
- 屏幕识别:图像来源于屏幕上某个窗口,或窗口的某个区域。
- 图像识别:图像来源于本地硬盘上的某个图像文件。
- PDF识别:图像来源于本地硬盘上的某个PDF文件,还可以通过识别全部页或指定页码范围来划分识别范围。
除了数据源不同之外,这三条命令其实没有其他区别,对于同样的图像,识别出的结果也是相同的。但它们的识别结果通常很难直接使用,所以才需要用蓝框里面的两条命令来进一步的获取其中的关键信息。其中:
- 获取卡证类型:由于“通用卡证识别”可以识别很多种卡证,包括身份证、驾驶证、房产证、营业执照等。这条命令可以自动判断被识别的图像属于哪一种卡证。
- 获取卡证内容:对于特定的卡证,这条命令可以提取其中的各个字段。比如身份证,可以提取姓名、性别、民族、身份证号码等字段。
我们来实际测试一下。首先,找一张身份证的图像文件。在本文中,为了不泄漏个人隐私,我们在互联网上找到了下面这张虚构的身份证图像,仅供参考:

这张身份证图像显然是网友们恶搞出来的,形状格式并不规范,而且在照片中还倾斜了一定的角度。但是,智能文档处理仍然能够准确地获得其中的信息。
假设身份证图像保存在 C:\temp\id_card.jpg 文件中。新建一个流程,拖入一条“图像卡证识别”命令,这条命令有两个属性是我们必须填写的,如下图所示:
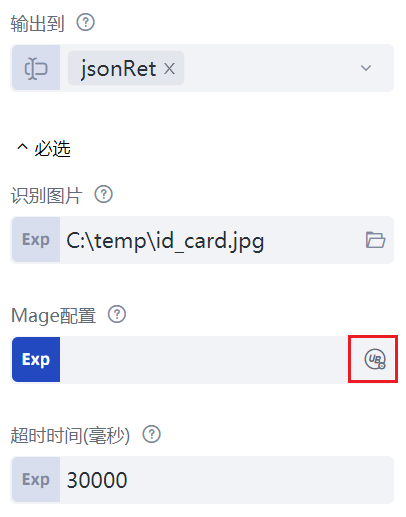
对于“识别图片”属性,选择 C:\temp\id_card.jpg 文件即可;对于“智能文档处理平台配置”属性,千万不要手动填写,点击属性右边的按钮(上图红框位置),弹出如下所示的对话框。
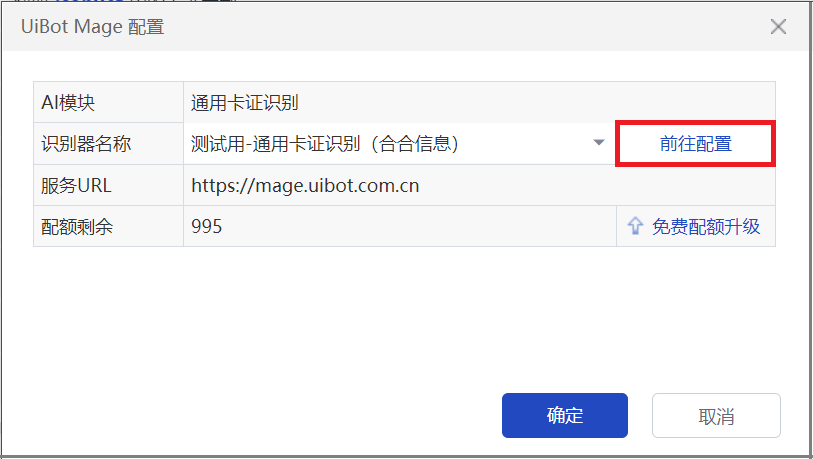
对于社区版的流程创造者来说,在这个对话框中,唯一需要设置的就是“识别器名称”这个下拉框。如果下拉框中没有内容,点击右边的“前往配置”(上图红框位置),会自动打开浏览器,并跳转到智能文档处理平台的主页。可以在智能文档处理平台中新建一个通用卡证识别模型,并选择后端的AI引擎,其中标有“原生”的引擎是来也科技自行研发的AI能力,标有“第三方”的引擎是其他AI厂商为来也科技专供的AI能力。不同的AI引擎在不同的场景下各有优势,可以根据实际情况,选择效果较好的AI引擎。
在智能文档处理平台上建好了识别模型之后,即可在流程创造者中选择到这一模型,并且,之前空缺的“智能文档处理平台配置”属性也会被自动填写上,我们无需关心它填写的内容。
接下来,我们再依次拖入“获取卡证类型”、“获取卡证内容”命令,获取识别结果中的卡证类型、姓名、出生日期、地址等信息。注意:这些命令都有一个共同的属性叫“卡证识别结果”,把“图像卡证识别”命令的输出填写在这里即可。 每次获取一项信息,可以拖入一条“输出调试信息”的命令将其显示出来。
按照上述步骤,最终形成的流程大致如下所示:

运行后,可以得到如下的结果:

值得说明的是,智能文档处理类的命令在运行的时候,都需要连接智能文档处理的服务器。如果您使用的是社区版的流程创造者,我们已经在互联网上建好了服务器,直接使用即可。如果是企业版的流程创造者,既可以使用互联网上的服务器,也可以自己部署并使用自己的智能文档处理服务器。如果使用互联网上的服务器,我们限定了每个月的免费使用次数,每运行一次“识别”类的智能文档处理命令,就会自动扣除一次。每月初再自动补齐次数的额度。如果免费的次数不够,还可以付费购买更多的使用次数。
当我们想要提取的字段较多,逐一编辑“获取卡证内容”的命令和属性的过程比较繁琐。这个时候,我们可以使用智能文档处理识别向导,会更加方便快捷。
智能文档处理识别向导
上文描述了如何在流程创造者中使用智能文档处理功能,来识别一张身份证中的信息。可以看到,当要获取的字段比较多的时候,操作略显繁琐。使用智能文档处理还可以识别发票等票据信息,如果按照上述方法去操作,还会更加繁琐。因为智能文档处理在做卡证识别的时候,每次只识别一张卡证(比如一张身份证)。而在做票据识别的时候,由于很多财务部门都规定要把多张不同的票据贴在同一张纸上去报销,比如把增值税发票、火车票、出租车票都贴在一起,等等。智能文档处理也会一次性地把这些票据全都识别出来。这样一来,在编写流程的时候,就会有些麻烦了,因为识别完以后,还要判断总共识别出了多少张票据,每张分别是什么类型的票据,不同类型的票据还会有不同的字段,比如火车票上会有出发地、目的地等,而增值税发票没有这些信息。对于流程创造者老手来说,编写这样一段流程不算太难,但新手可能就会有些犯难了。
为此,在流程创造者中,还提供了智能文档处理的向导功能,可以通过图形化界面,快速引导您配置图像识别器,设置提取类型和字段,并自动生成相关的命令框架,过程流畅,简单易用。
打开流程创造者,在编写任何一个流程块的时候,工具栏上都可以找到标有“智能文档处理”的图标,如下图红框所示。

点击这个按钮,即可弹出智能文档处理识别向导的窗口。可以看到,这个向导包含了“配置识别器、选择图像来源、提出类型和字段”三个步骤。
使用这个向导,可以自动生成一系列命令,大大简化我们的操作。比如,下面的这张图像中,既有发票,又有出租车票,我们希望一次把这些票据中的关键字段提取出来。发票的方向即使是倒置的也没有关系,智能文档处理会自动识别。

只要按照智能文档处理识别向导的三个步骤,逐一填写相关信息即可。如下所述:
步骤一:打开智能文档处理识别向导,首先进行识别器的配置,即选择AI模块、选择AI能力及其识别器。这和前文中配置智能文档处理识别器的操作基本类似,只需依次选择所需的功能和识别器即可。
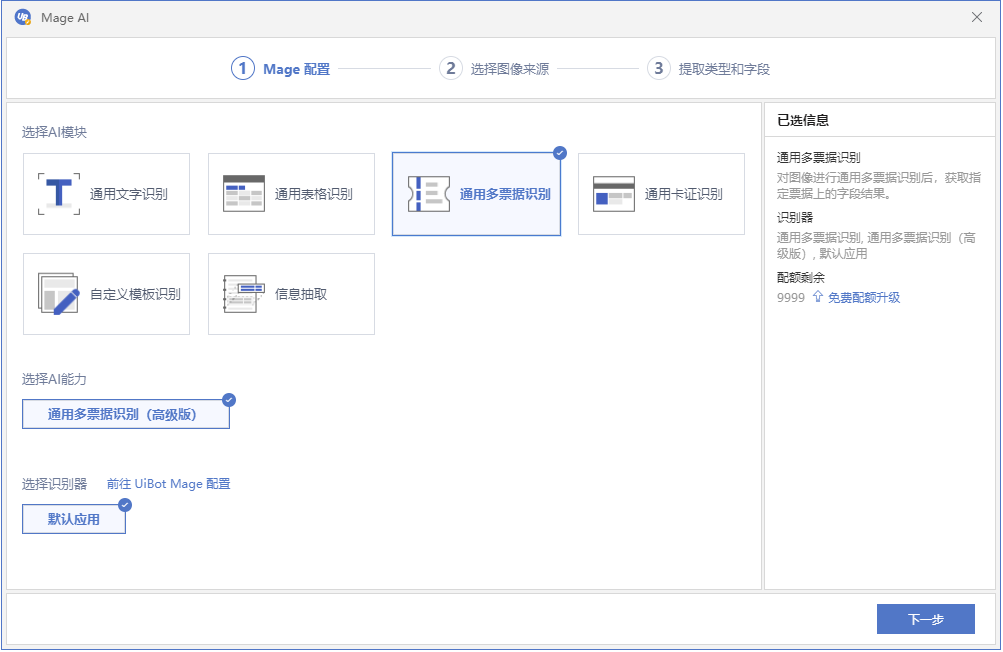
步骤二:选择图像来源。可以采取“选择目标”的方式,使用鼠标从电脑屏幕中选择/截取一个识别区域;或者采取“选择图像”,选择或拖拽一个本地的图像文件;或者“选择PDF”,选择一个PDF文件并指定页面范围。
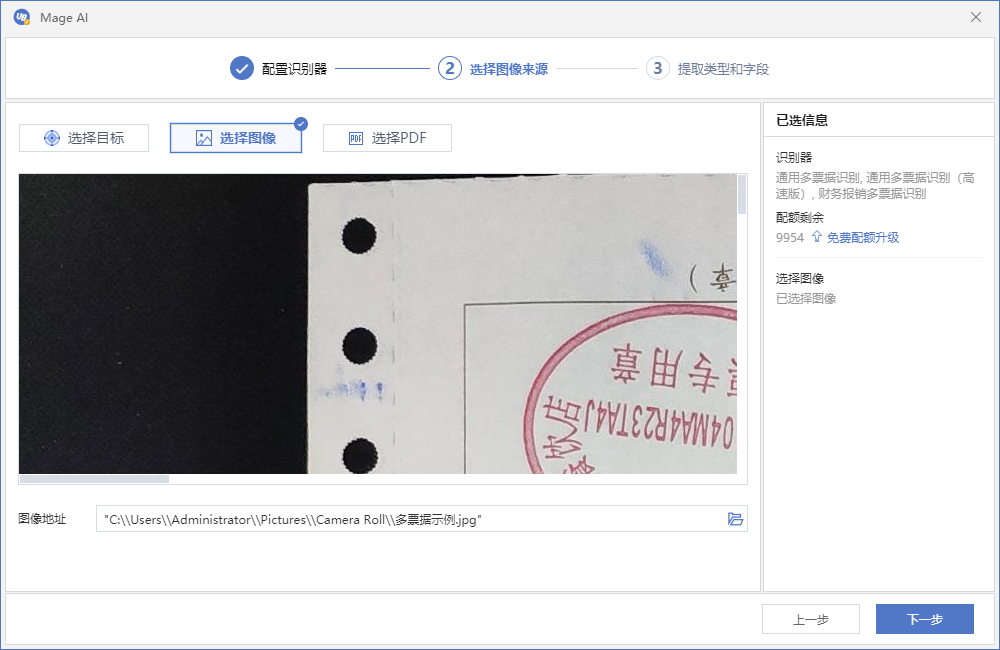
我们以选择本地图像为例,直接在本地硬盘上选取图像文件的路径即可。选择完成后,对话框中会自动把图像显示出来,以方便预览。
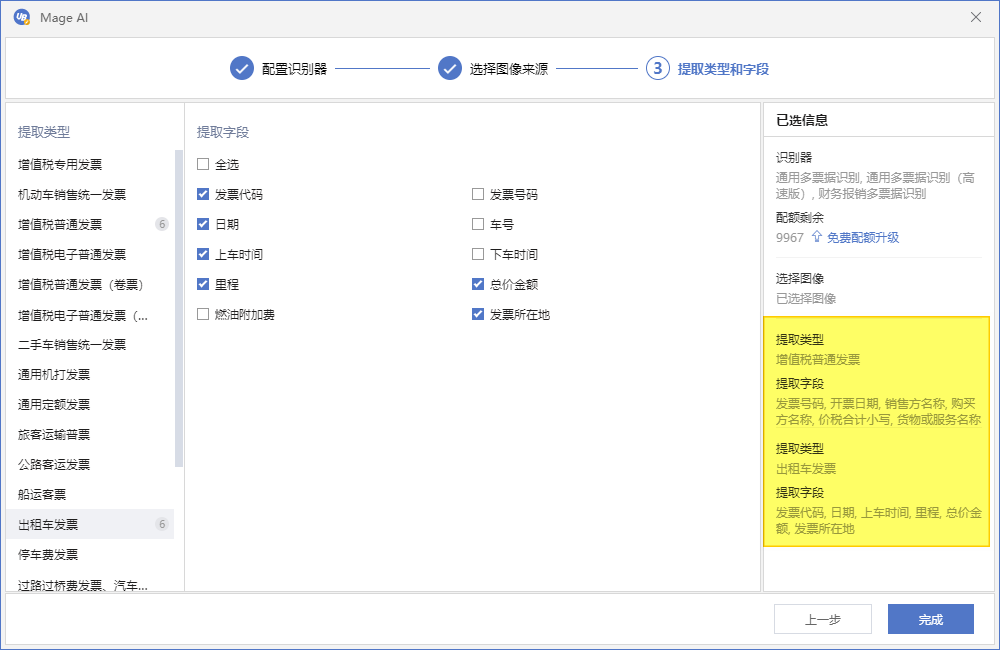
步骤三:选择提取类型和提取字段。支持同时配置多种票据及其提取字段,配置之后,可以在右侧“已选信息”中确认自己的选择。
上述三个步骤都完成后,点击“完成”,流程创造者会自动生成一系列的命令,如下图所示。
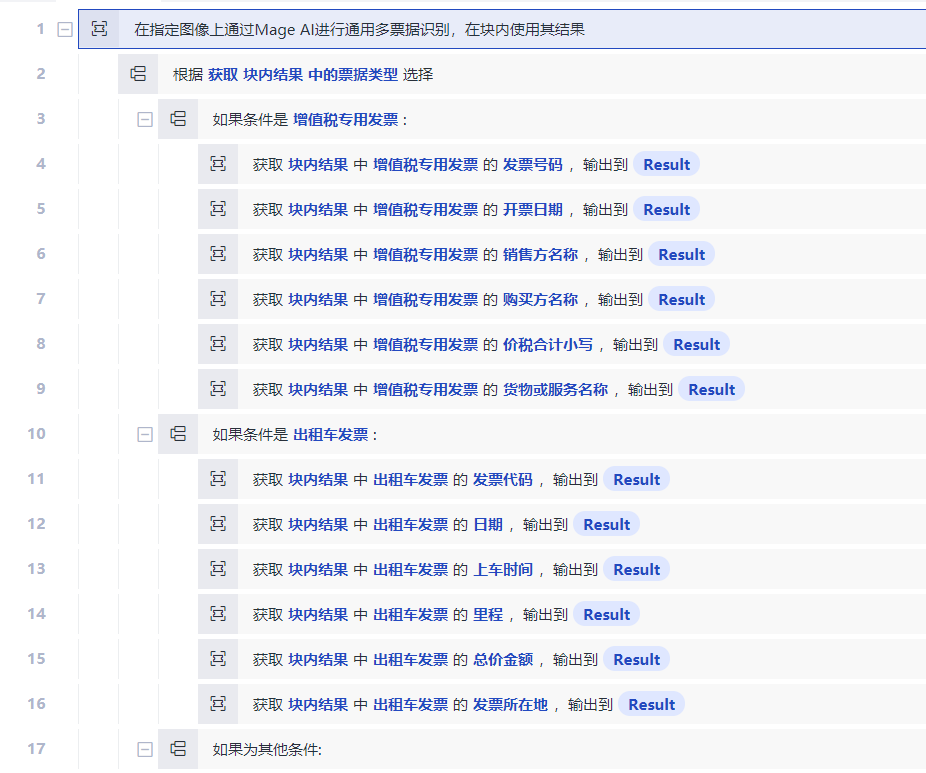
可以看到,对于上述场景,流程创造者自动生成了17行命令,节省了我们的工作量。但这些命令仍然只是一个框架,还需要您再继续往里面填充其他命令,才能满足业务要求。比如,您可能需要把识别出的每一张增值税发票的信息填写到一个Excel文件里,把识别出的每一张出租车票填写到另外一个Excel文件里。识别后的效果如下图所示:
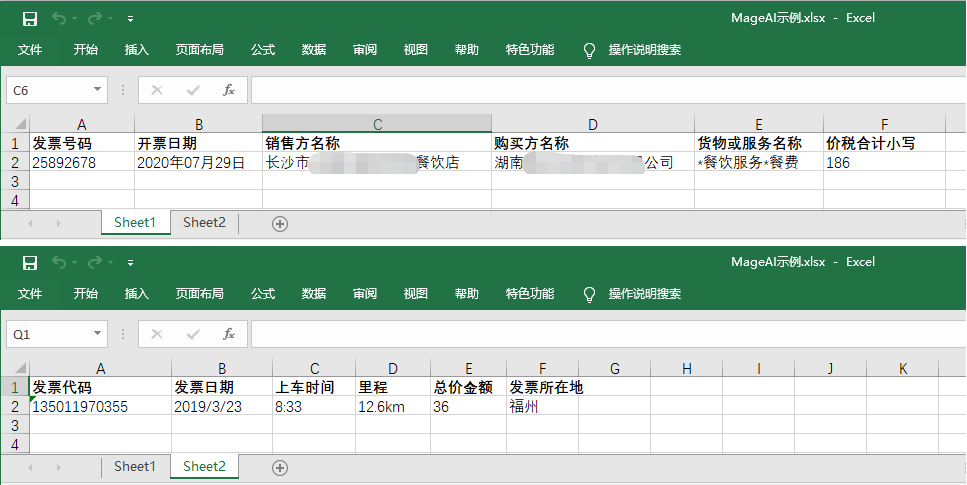
那么,您可能需要在流程中恰当的位置,插入打开和关闭Excel文件的命令,并在恰当的位置,插入写入Excel文件的命令。基于自动生成的框架,插入这些命令应该对您来说已经没有难度了,本章不再列出示例流程,请自行练习。通过练习,不难发现,上述识别发票并把不同类型的发票自动录入Excel文件的流程,只需要不到10分钟就可以开发完成,在开发过程中,大多数时候也只需要用鼠标点选,连敲键盘的场景都很少。可见流程创造者中“智能文档处理向导”的便利性。
本地OCR
OCR的全称是“光学字符识别”,这是一项历史悠久的技术,早在上个世纪,OCR就可以从纸质的书本中扫描并获得其中的文字内容。如今,OCR的技术也在不断演进,已经融入了流行的深度学习等技术,识别率不断提高。我们现在用OCR去识别屏幕上的文字,由于这些文字不像纸质书本一样存在印刷模糊、光线不好等问题,所以识别率是非常高的。
其实,前文提到的智能文档处理中就包含了OCR的功能。但有的场合并不适合使用智能文档处理,例如下面的场景:
我们在前面的内容中提到,有些情况是无法获取界面元素的。此时,使用“图像”类命令,可以找到准确的操作位置。但还不能像有目标的命令那样,把界面元素中的内容读出来。
比如著名的游戏平台Steam,其界面使用了DirectUI技术绘制,我们无法获得其中的任何文字(虽然这些内容用肉眼很容易看到),如图所示。
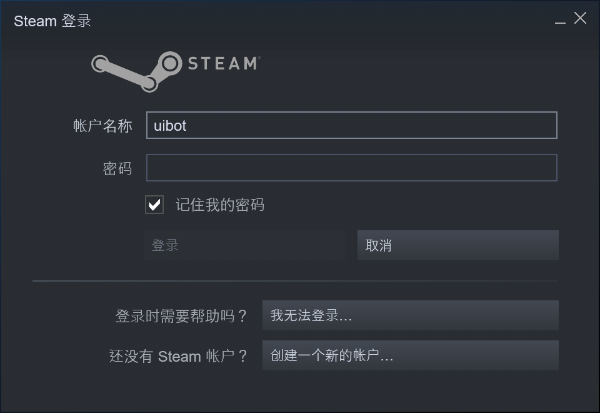
使用智能文档处理,固然可以得到其中的文字,但未免“高射炮打蚊子”。而且智能文档处理的AI能力必须连接互联网才能使用,免费版也有配额限制。此时,就需要祭出流程创造者的“本地OCR”命令了。
“本地OCR”具体包含了以下的OCR命令:
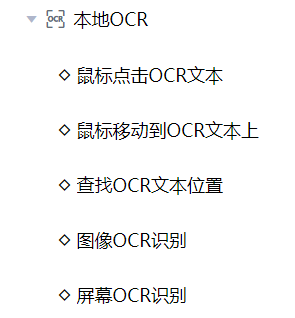
顾名思义,这些命令都是不需要连接互联网的,直接在您运行流程创造者的计算机上即可执行。
我们先试一下“屏幕OCR识别”命令。双击或拖动插入一条“屏幕OCR”命令,点击命令上的“查找目标”按钮(此时流程创造者的窗口会暂时隐藏);把鼠标移动到Steam的登录窗口上,此窗口会被红框蓝底的遮罩遮住;此时拖动鼠标,划出一个要进行文字识别的区域,这个区域会用紫色框表示。如图所示。
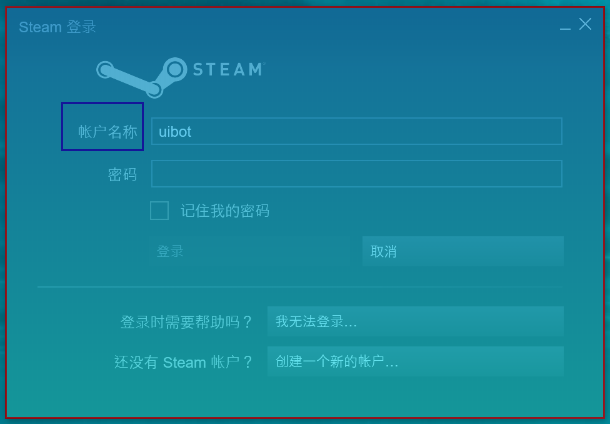
当然,您也可以不划出要识别的区域,直接在窗口上点击鼠标左键,代表识别整个窗口。这样的一条命令,会在运行的时候,自动找到Steam的登录窗口,并在指定的区域(相对于窗口的位置)截图,然后识别截图里面的文字,最后把识别到的文字输出到指定的变量中。
根据前文学到的经验,可以直接点击命令右侧的三角形,运行单条命令,会在运行完成后,自动输出结果。可以看到,只要Steam的登录窗口存在,且窗口大小没有发生变化,就能识别出我们所划的区域中的文字“账户名称”。
上文演示了“屏幕OCR识别”。此外还有“图像OCR识别”命令,和“屏幕OCR识别”类似,只不过前者需要提供一个图像文件,流程创造者会在流程运行到这一条命令的时候,不考虑屏幕图像内容,直接采用指定的图像文件去进行识别。
另外,还有“鼠标点击OCR文本”、“鼠标移动到OCR文本上”、“查找OCR文本位置”等命令,他们类似于“图像”类命令中的“点击图像”、“鼠标移动到图像上”,“查找图像”命令,只不过不需要传入图像了,只需要在属性中标明要找的文字即可。流程创造者会在运行的时候,自动在屏幕上找到指定的文本,并根据文本的位置,进行鼠标点击或移动等操作。
百度OCR
市面上很多云厂商都提供了在线的OCR服务,其中,百度OCR的口碑相对较好,很多用户都自行购买了百度OCR的服务。在这种情况下,流程创造者也提供了百度OCR的相关命令,可以方便快捷地使用百度OCR的功能。而且,百度OCR也对发票、身份证、火车票等票据、卡证的图像进行了特别优化,能较为准确的识别其中的关键内容,其识别效果和智能文档处理相比各有千秋。用户可以根据实测效果和实际情况选用。
为了能够正常接入百度云的OCR,首先需要满足以下三个要求:
要能够接入互联网。百度云是基于互联网的云服务,而不是本地运行的软件,个人使用的话,必须接入互联网。如果是企业用途,不能接入互联网,可能需要和百度云进行商务谈判,购买其离线服务。
可能需要向百度付费。百度OCR服务是收费的,但提供了每天若干次(通用文字识别每天5000次,证照等识别每天500次)的免费额度。个人使用的话,免费额度也基本够用了。当然,百度可能会随时修改免费额度和收费价格等政策,我们无法预估您需要向百度付多少费用。
由于百度云是收费的,不可能流程创造者的用户都共用一个账号。所以每个用户要申请自己的百度云账号,以及百度OCR服务的账号(一般称为Access Key和Secret Key),申请方法很简单,请点击这里查看我们的在线教程。
流程创造者中包含了以下的百度OCR命令:

可以看到,与上文所述的“本地OCR”命令相比,百度OCR命令中也有“鼠标点击OCR文本”、“鼠标移动到OCR文本上”、“查找OCR文本位置”、“图像OCR识别”和“屏幕OCR”这五条命令,这五条命令的使用方法与流程创造者的“本地OCR”命令大体类似,唯一的区别是,需要在“属性”中填写我们在百度云上申请的Access Key和Secret Key。
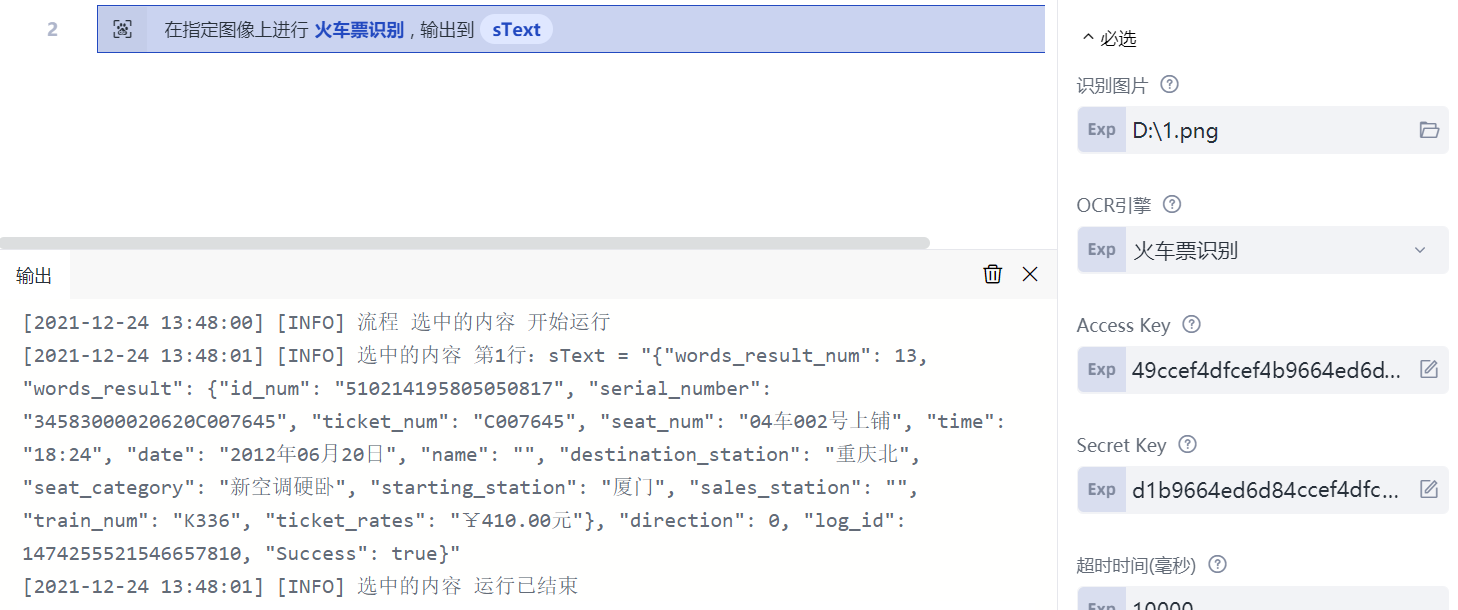
再来看看“图像特殊OCR识别”命令。所谓“特殊”,是指我们要测试的是某种特定的图像,如身份证、火车票等。假设在 D:\1.png 文件中保存了如下的图像:

插入一条“图像特殊OCR识别”命令,按图示修改其属性。除了前文提到的Access Key和Secret Key之外,还需要指定要识别的图片的文件名,以及选择OCR引擎为“火车票识别”。其他属性均保持默认值,运行后,可以在输出栏看到识别的结果。这个结果实际上是一个JSON文档,如果需要进一步处理,需要采用流程创造者提供的JSON类命令,但与本章关系不大,略过不表。