数据获取和处理
数据是信息化发展中的必然产物。对数据进行收集、整理、加工、分析等操作,是RPA流程经常遇到的任务。本章以数据的常见操作为主线,分别介绍数据的获取和处理等方法,涵盖网页数据、应用数据、文件数据等不同数据源的获取,以及JSON、字符串、正则表达式、集合、数组等多种数据的处理方法。
数据获取方法
数据抓取
在RPA的流程中,经常需要从某个网页、或某个表格中获得一组数据。比如我们在浏览器中打开某个电商网站,并搜索某个商品后,希望把搜到的每一种商品的名称和价格都保存下来。这里的商品名称和价格等都是界面元素, 可以用流程创造者的“界面元素自动化”,逐一去网页中选择界面元素(商品名称、价格等),再用“获取文本”等命令得到每一项的内容。但显然非常繁琐,而且在搜到的商品种类的数量不事先固定的时候,也会比较难以处理。实际上,流程创造者提供了“数据抓取”的功能,可以用一条命令,一次性地把多组相关联的数据都读出来,放在一个数组中。我们来看看这个功能如何使用:
打开流程创造者,进入流程块编辑,点击工具栏的“数据抓取”按钮,将会弹出一个交互引导式的对话框,这个对话框将会引导用户完成网页数据抓取。根据对话框的第一步提示,流程创造者目前支持四种程序的数据抓取:桌面程序的表格、Java表格、SAP表格、网页。本文以网页数据抓取为例阐述,其它三种程序的数据抓取在操作上并无显著区别。
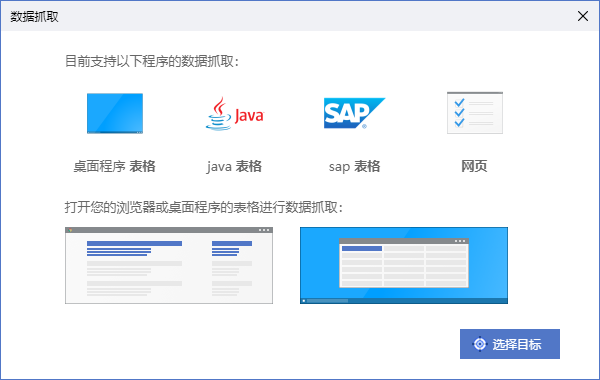
点击“选择目标”按钮,这一按钮与前面我们学习的“界面元素自动化”中的“选择目标”按钮用法一致。需要注意的是:流程创造者并不会帮您自动打开想要抓取的网页和页面,因此在数据抓取之前,需要预先打开数据网页或桌面程序表格。这个工作可以手动完成,也可以通过其它命令组合完成。例如,这里演示的是抓取某电商网站上的手机商品信息,我们可以使用“浏览器自动化”的“启动新的浏览器”命令打开浏览器并打开该网站,使用“设置元素文本”命令在搜索栏输入“手机”,使用“点击目标”命令点击“搜索”按钮。上述步骤在初级开发者指南中都有阐述,不再展开讲解。
网页准备好后,下一步任务是在网页中定位需要抓取的数据,先抓取商品的名称,仔细选择商品名称的目标(红框蓝底遮罩框)。
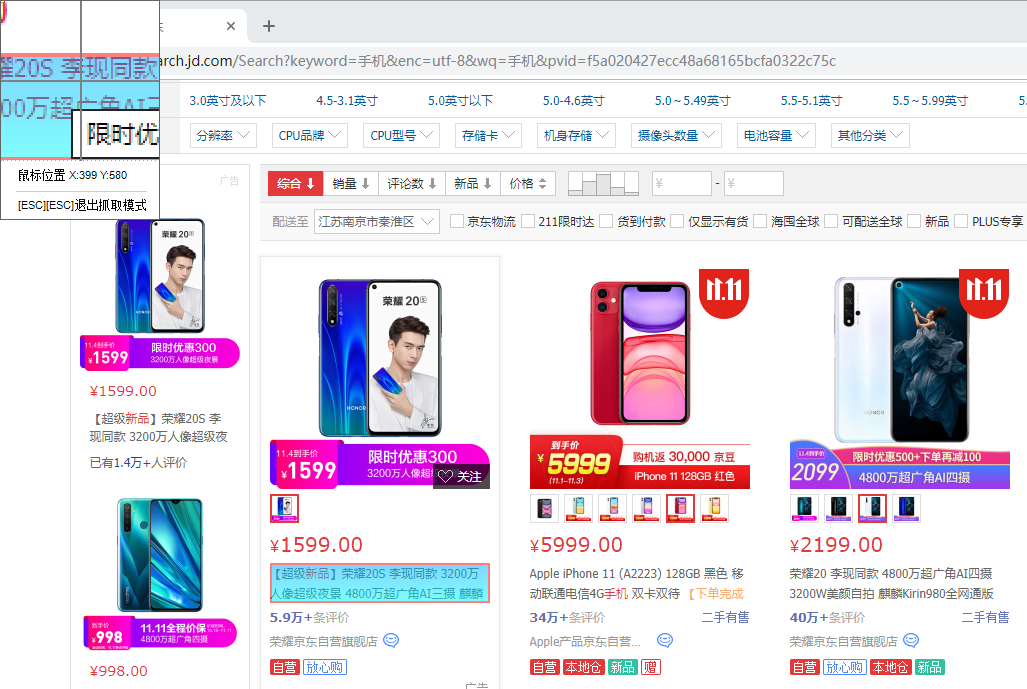
可以看到,此时弹出了提示框:“请选择层级一样的数据再抓取一次”。您可能会感到疑惑:什么叫层级一样的数据?为什么还要再抓取一次呢?这是因为,我们要抓取的是一组数据,必须找到这些一组数据的共同特征。第一次选取目标后,得到了一个特征,但是仍然不知道哪些特征是所有目标的共性、哪些特征只是第一个目标的特性。只有再选择一个层级一样的数据并抓取一次,才能保留所有目标的共性,而刨去每个目标各自的特性。就好比在数学中,两个点才能确定一条直线,我们只有选取两个数据,才能确定要抓取哪一列数据。

定位需要抓取的数据,这里我们先抓取商品的名称,仔细选择商品名称的目标(红框蓝底遮罩框)。
再次在网页中定位需要抓取的数据,也就是商品的名称,第一次抓取的是第一个商品的名称,这次我们抓取第二个商品的名称。这里一定要仔细选择商品名称的目标,保证第二次和第一次抓取的是同一个层级的目标,因为Web页面的层级有时候特别多,同样一个文本标签,可能会嵌套数层目标。如果此时报错,通常都是因为目标选错而导致的。另外,也可以选择第三个、第四个商品的名称进行抓取,这些都不影响数据的抓取结果,只要是同一层级就可以了。
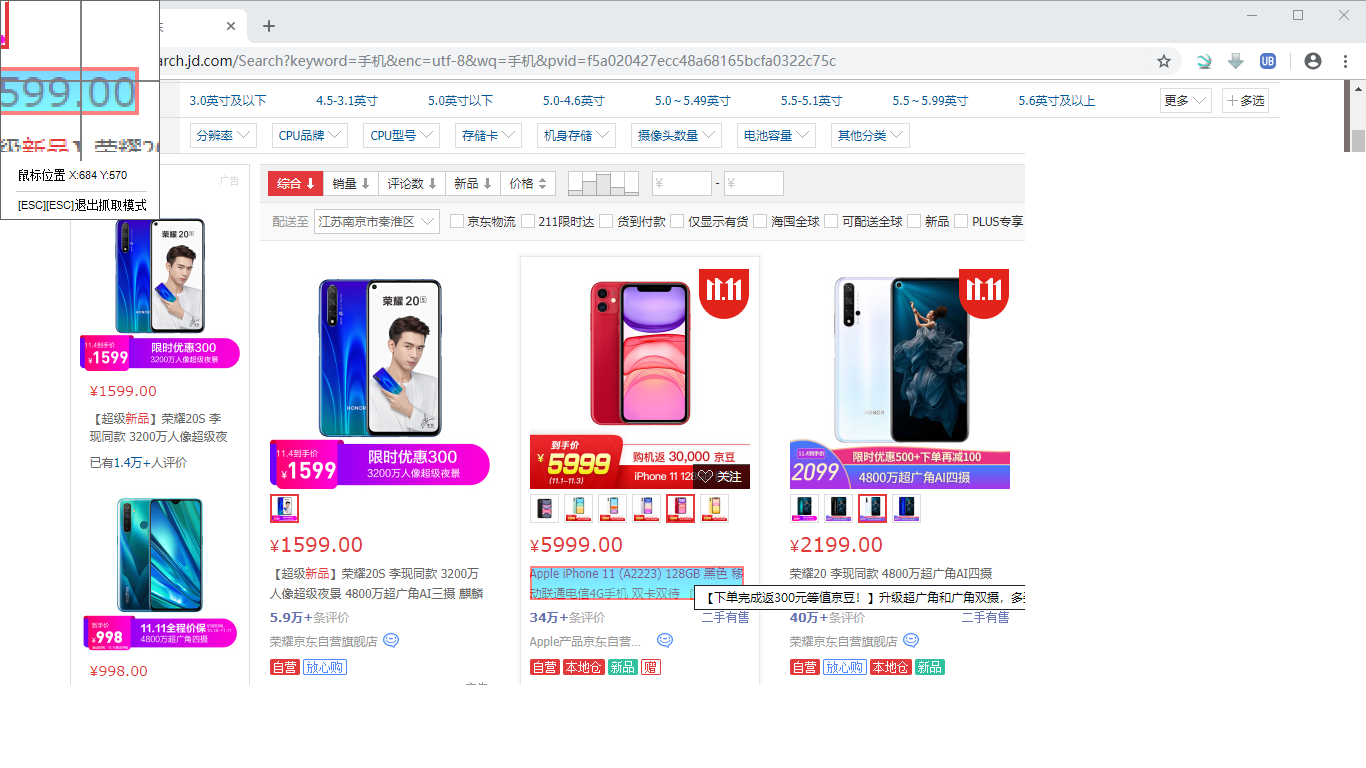
两次目标都选定完成后,再次弹出引导框,询问“只是抓取文字还是文字链接一起抓取”,按需选择即可。
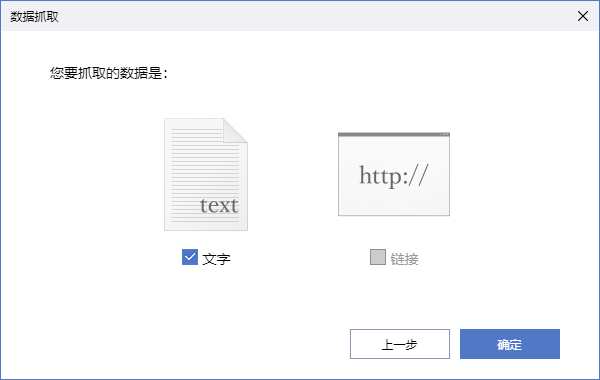
点击“确定”按钮后,流程创造者会给出数据抓取结果的预览界面,您可以查看数据抓取结果与您的期望是否一致:如果不一致,可以点击“上一步”按钮重新开始数据抓取;如果一致,且您只想抓取“商品名称”这一组数据,那么点击“下一步”按钮即可;如果您想抓取更多组数据,例如,还想抓取商品的价格,那么可以点击“抓取更多数据”按钮,则会再次弹出选择目标界面。
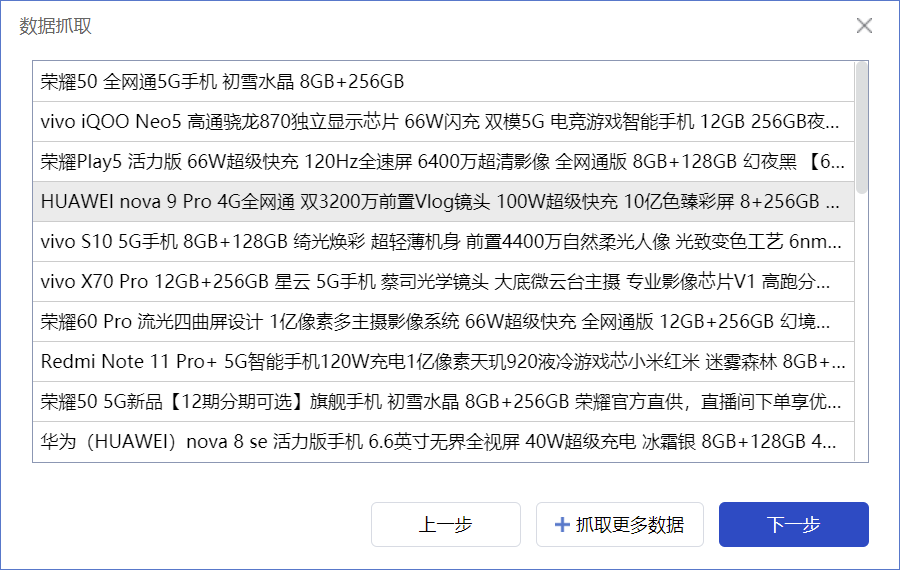
例如,这次我们选择的是商品价格文本标签。
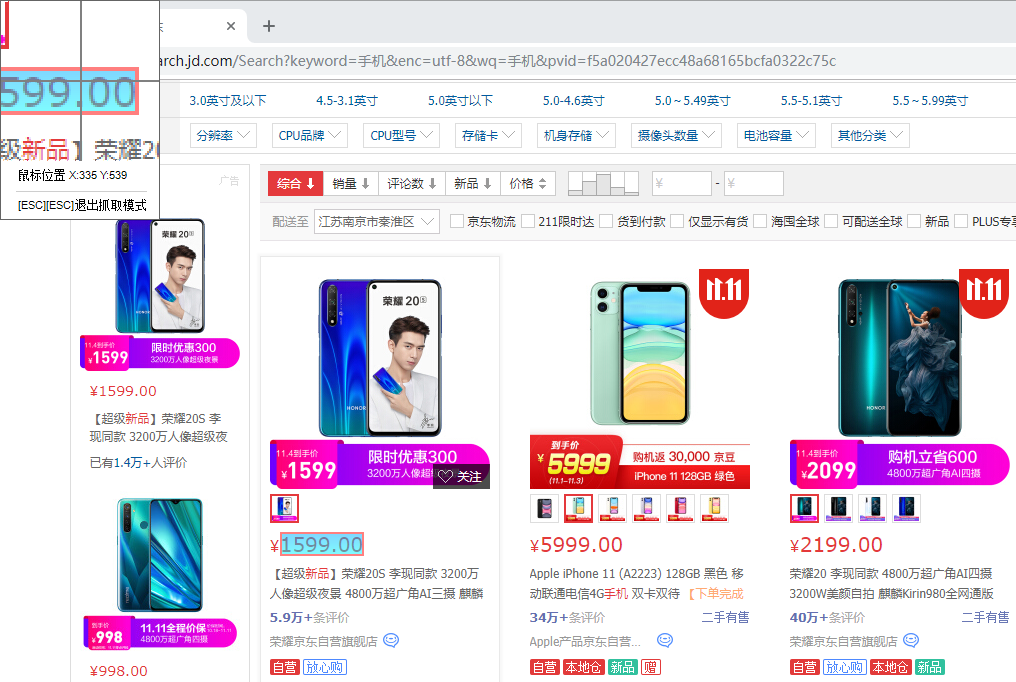
同样经过两次选择目标,再次预览数据抓取结果,可以看到:商品名称和商品价格已成功抓取。而且,这两组数据是一一对应的,第一列的商品名称对应了第二列的价格。
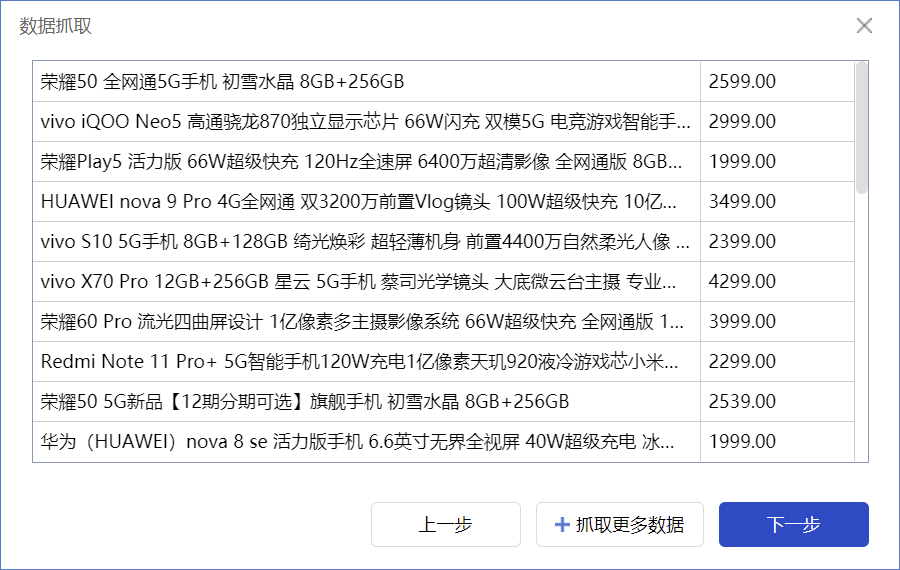
循环使用这个方法,还可以进一步增加多组需要抓取的数据,比如商品的卖家名称、评价数量等。如果不再需要抓取更多数据了,那么点击“下一步”按钮。此时出现的引导页面询问“是否抓取翻页”,这是什么意思呢?假设把网页数据看成一个二维数据表的话,前面的步骤是增加数据表的列数,例如商品名称、价格等,而抓取翻页,是增加数据表的行数。如果只抓取第一页数据,那么点击“完成”按钮即可;如果需要抓取后面几页的数据,那么点击“抓取翻页”按钮。
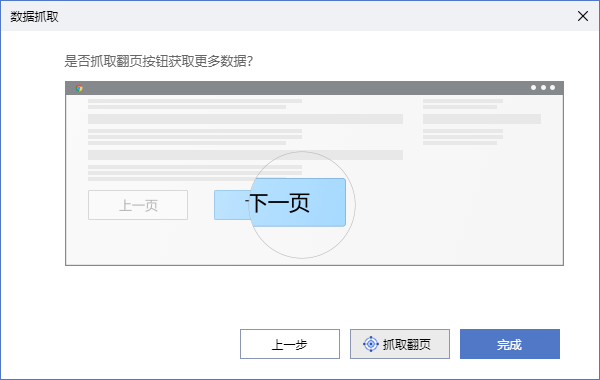
点击“抓取翻页”按钮,弹出“目标选择”引导框,选择Web页面中的翻页按钮,这里的翻页按钮为页面中的">"符号按钮。
当所有步骤完成后,在流程创造者的命令组装区里面,会自动插入一条“数据抓取”命令,且该命令的各个属性都已通过引导框填写完毕。大部分属性通常都不需要再修改了,个别属性还可以再进一步调整:“抓取页数”属性指的是抓取几页数据;“返回结果数”属性限定每一页最多返回多少结果数,-1表示不限定数量;“翻页间隔”属性指的是每隔多少毫秒翻一次页,有时候网速较慢,需要间隔时间长一些,网页才能完全打开。
通用文件处理
除了网页数据抓取,“文件”是另一种非常重要的数据源。流程创造者提供了几种格式的文件的读取操作,包括通用文件、INI格式文件、CSV格式文件等,我们先来看一下通用文件。
通用文件处理通常用来读写没有特定格式的文本文件,比如用Windows自带的“记事本”编写的文件,就属于这种类型。除此之外,通用文件处理还包含了判断文件是否存在、判断文件夹里面有哪些文件等功能。这里只介绍读取文本文件的功能。
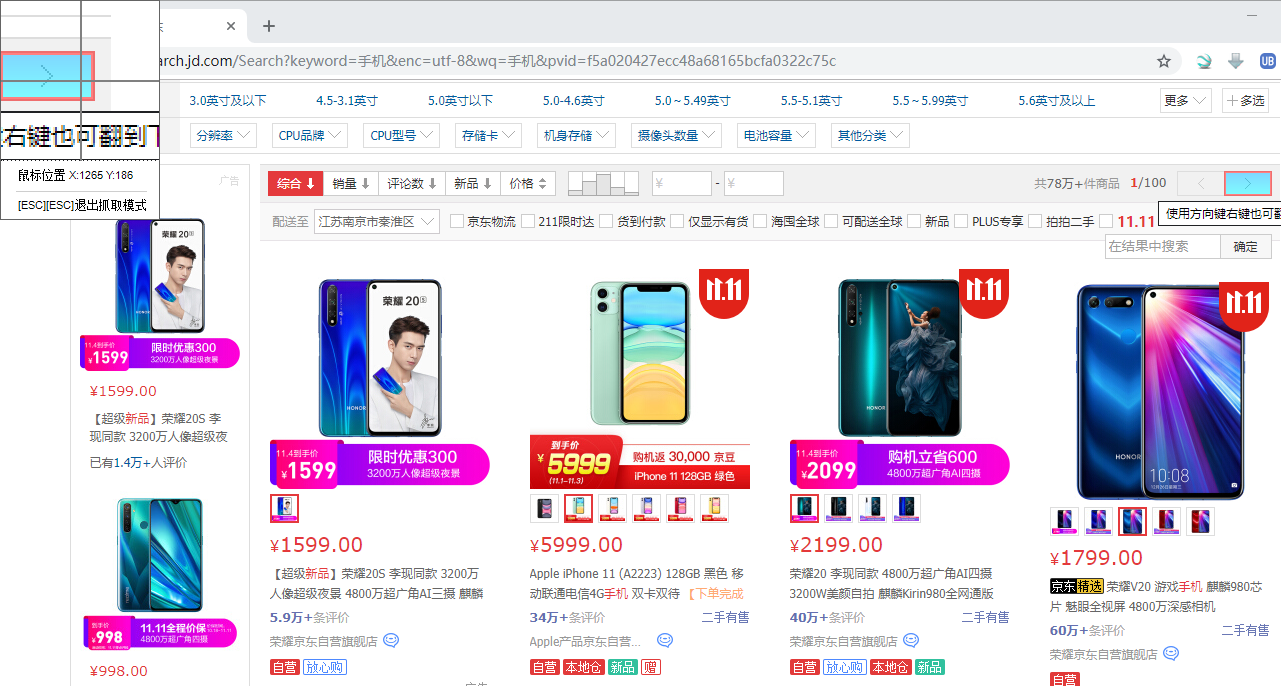
在命令列表中,找到“文件处理”,并展开“通用文件”一项,找到“读取文件”命令,双击或拖动插入这条命令。命令的第一个属性是“文件路径”,填写待读取文件的路径即可。可以是绝对路径,也可以是相对路径。如果采用绝对路径,直接点击后面的文件夹形状的图标进行选取即可;如果采用相对路径,建议切换到专业模式下,输入相对路径@res"test.txt",即流程所在文件夹下的res文件夹下的test.txt文件,前面已经学习过这样的相对路径表示方式了。
特别需要注意的是第二项属性,即“字符集编码”。即使是相同内容的文本文件,也会有不同的编码格式,常见的包括ANSI/GBK、UTF-8、Unicode等等。在流程创造者中,我们一般都采用UTF-8的编码。如果读取的文本文件是其他编码,只要您在这里正确的选择了编码,流程创造者就会自动将其转换为UTF-8,以便后续处理。如果您不了解这些编码的区别,以及您要读取的文件采用了哪种编码,互联网上有大量资料可供参考,本文不再赘述。
“读取文件”命令会把文件全部读出来,放在一个字符串类型的变量中。如果需要对有格式的文本文件进行更加细节的操作,可以根据文件类型,选择特定的文件操作命令,例如INI文件、CSV文件等。
INI文件处理
INI文件又叫初始化配置文件,Windows系统程序大多采用这种文件格式,负责管理程序的各项配置信息。INI文件格式比较固定,一般由多个小节组成,每个小节由一些配置项组成,这些配置项就是键值对。
我们来看最经典的INI文件操作:“读取键值”。在命令中心“文件处理”的“INI格式”命令分类下,选择并插入一条“读键值”命令,这条命令可以读取指定INI文件中指定小节下指定键的值。该命令共有五个属性:“配置文件”属性,填写待读取INI文件的路径,这里填写的是相对路径@res"test.ini",说明读取的是流程所在文件夹下的名为res的文件夹下的test.ini文件,内容如下:
[meta]
Name = mlib
Description = Math library
Version = 1.0
[system]
Libs=sysLibs
Cflags=sysCflags
[user]
Libs=userLibs
Cflags=userCflags
“小节名”属性填写键值对的查找范围,这里填写的是"user",说明在[user]小节查找键值对;“键名”属性填写待查找的“键”的名称,这里填写的是"Libs",说明要查找形如"Libs="后的内容;“默认值”属性指的是,当查找不到键时,返回的默认值;“输出到”属性填写一个字符串变量sRet,sRet将保存查找到的键值。注意在下图中,由于我们在“小节名”和“键名”属性栏里面采用了“普通模式”进行输入,所以直接输入字符串内容即可,不需要加双引号。而如果切换到“专业模式”,就需要加双引号了。

添加一条“输出调试信息”命令,打印出sRet,运行流程后,可以看到sRet的值为"userLibs"。
CSV文件处理
CSV文件以纯文本形式存储表格数据,文件的每一行都是一条数据记录。每条数据记录由一个或多个字段组成,用逗号进行分隔。CSV文件广泛用于不同体系结构的应用程序之间交换数据表格信息,解决不兼容数据格式的互通问题。
在流程创造者中,可以使用“打开CSV文件”命令将CSV文件的内容读取到数据表中,然后再基于数据表进行数据处理,数据表的处理方法参见下一节。
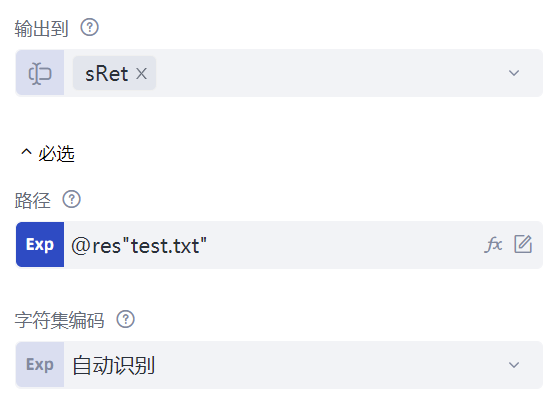
先来看“打开CSV文件”命令,这条命令有两个属性:“文件路径”属性填写待读取CSV文件的路径,这里填写的是相对路径@res"test.csv",说明读取的是流程所在文件夹下的res文件夹下的test.csv文件;“输出到”属性填写一个数据表对象objDataTable,运行命令后,test.csv文件的内容将被读取到数据表objDataTable中,我们可以添加一条“输出调试信息”命令,查看objDataTable数据表的内容。
再来看“保存CSV文件”命令,这条命令也有两个属性:“数据表对象”属性填写上一步得到的数据表objDataTable;“文件路径”属性填写保存CSV文件的路径,这里填写的是@res"test2.csv",仍然是相对路径,其含义已多次解释,不再赘述。
PDF文件处理
在办公场景中,PDF格式文件是Office格式文件之外最常用的文件格式,因此对PDF文件的处理也显得非常重要。流程创造者提供了对PDF文件处理的支持。所支持的命令如下所示:

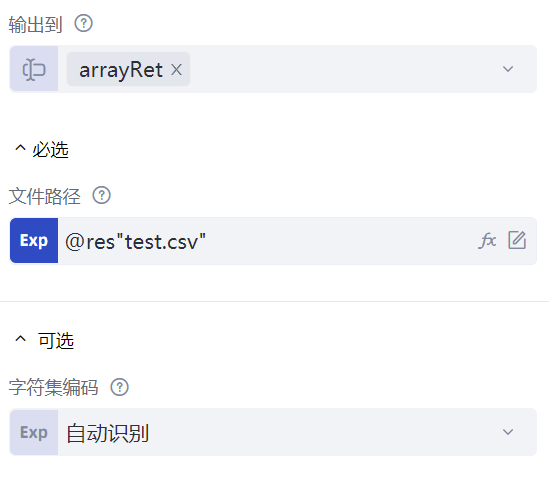
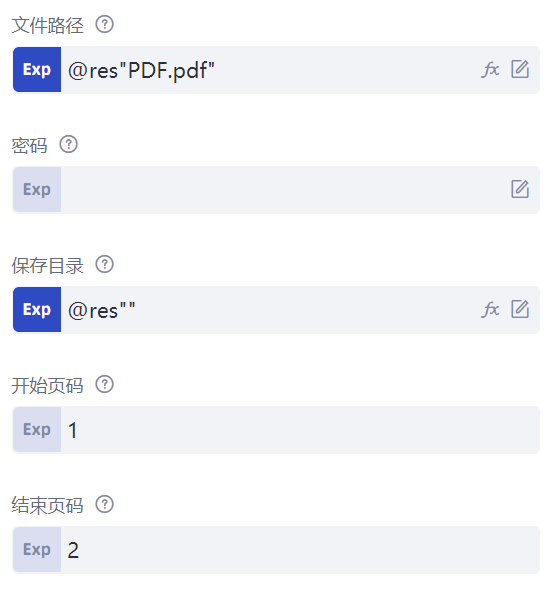
在命令列表中,“文件处理”的“PDF格式”分类下,选择并插入一条“获取总页数”命令,这条命令可以得到指定PDF文件的页数。该命令共有三个属性:“文件路径”属性,填写待读取PDF文件的路径,这里填写的是@res"PDF.pdf",说明读取的是流程文件夹下的res文件夹下的PDF.pdf文件;“密码”属性,填写的是PDF.pdf文件的打开密码,如果无密码,那么保持默认值即可。运行该命令后,“输出到”属性中填写的变量名,将会保存PDF文件的页数。
流程创造者还可以将PDF的单页转换成图片文件,选择并插入一条“将指定页另存为图片”命令,该命令共有五个属性:“文件路径”属性和“密码”属性的含义同“获取总页数”命令;“开始页码”和“结束页码”属性指定PDF文件的开始和结束页码,这里填写1和2,表示转换第1页到第2页;“保存目录”属性填写转换后图片的保存路径,这里填写的是@res"",说明转换后图片保存到流程所在文件夹下的res文件夹下。运行后,会自动生成两个文件:PDF_1.png和PDF_2.png,它们都是图片文件,分别是第1页和第2页的内容。
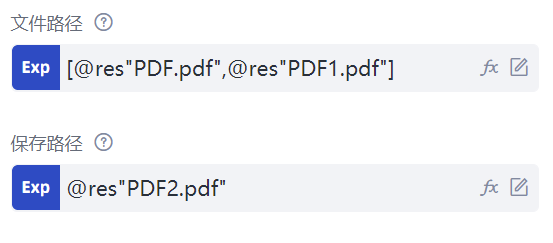
除了处理单个PDF文件,流程创造者还能将多个PDF文件合并成一个PDF文件,选择并插入一条“合并PDF”命令,该命令共有两个属性:“文件路径”属性填写需要合并的多个PDF文件路径。既然是合并文件,自然需要有不止一个文件才具有合并的意义。因此,必须输入多个PDF文件的路径,也就是需要填写一个数组,这里填写的是[@res"PDF.pdf", @res"PDF1.pdf"],表示合并流程所在文件夹下的res文件夹下的PDF.pdf文件和PDF1.pdf文件;“保存路径”属性填写合并后的PDF文件路径,这里填写的仍然是相对路径@res"PDF2.pdf"。运行后,两个PDF文件即可合二为一,且在合并后的文件中,原先的两个PDF文件的排列顺序和它们在数组中的顺序是一致的。
数据处理方法
当数据完成读取后,接下来就要对数据进行处理。根据数据格式的不同,流程创造者提供了不同的数据处理方法和命令,包括数据表、字符串、集合、数组、时间或者正则表达式等。下面分别介绍这些方法。
数组
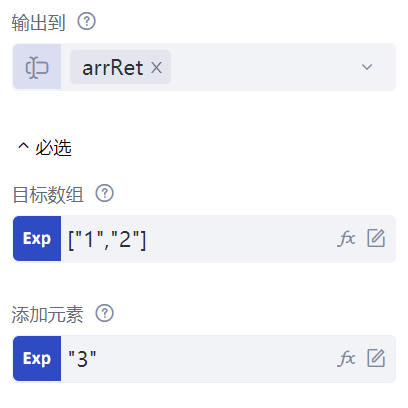
我们在前文中已经学习了采用数组来存储多个数据的方式。当构造好一个数组之后,流程创造者还提供了一系列命令,对其进行各种处理。包括数组编辑(添加元素、删除元素、截取合并数组)、数组信息获取(长度、下标等)等等。例如,可以在流程创造者的命令列表中,找到“数据处理”的“数组”分类,选择并插入一条“在数组尾部添加元素”命令,该命令可在数组的末尾添加一个元素。该命令有三个属性:“目标数组”属性,填写添加元素前的数组,这里填写["1", "2"];“添加元素”属性填写待添加的元素,这里填写"3";“输出到”属性保存添加后的数组变量。添加完成后,用“输出调试信息”显示该变量的内容,预期输出结果为["1", "2", "3"]。
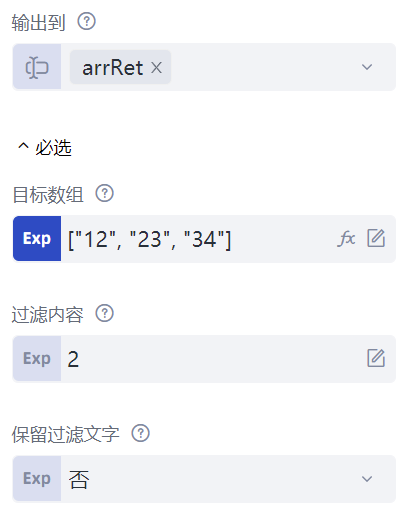
再来看“过滤数组数据”命令,这条命令可以快速对数组中的元素进行筛选,留下或者剔除满足条件的元素。该命令有四个属性:“目标数组”属性,填写待过滤的数组,这里填写的是["12", "23", "34"];“过滤内容”属性填写按照什么条件过滤数组,这里填写"2",表示数组元素只要是字符串,并且包含了"2"就满足条件;“保留过滤文字”属性有两个选项,“是”表示满足条件的数组元素将会保留,剔除不满足条件的元素;“否”表示满足条件的数组元素将会剔除,保留不满足条件的元素。
可以尝试一下,对“保留过滤文字”的属性选择“是”,并输出过滤后的数组变量arrRet,输出结果为[ "12", "23" ],可见包含了字符串"2"的数组元素都被保留;而如果“保留过滤文字”属性选择“否”,过滤后的数组变量arrRet的输出结果为[ "34" ],包含字符串"2"的数组元素都被剔除了。
集合
集合可视作一种特殊的一维数组,它和数组的不同之处主要有两点:
- 数组中的元素可以重复,而集合中的元素不允许重复。例如,
[1, 2, 2, 3]是一个普通的数组,但如果将其转换为一个集合的话,就会剔除掉其中一个2,只保留1, 2, 3这三个元素。 - 数组中的元素是有序的,而集合中的元素是无序的。例如,往一个数组中依次添加元素
1, 2, 3,往另一个数组中添加3, 2, 1,得到的会是两个不同的数组。而如果往两个集合中分别依次添加元素1, 2, 3和3, 2, 1,这两个集合仍然是等价的。
我们首先尝试创建一个集合。在命令列表中,找到“数据处理”下面的“集合”分类,选择并插入一条“创建集合”命令。该命令只有一个“输出到”属性,它会创建一个空集合,并将此集合置入ObjSet变量中。如果您熟悉流程创造者的源代码视图,这里还有一个技巧:可以切换到源代码视图,把一个数组当作Set.Create命令的输入,可以直接把这个数组转换为集合。如果您还不熟悉源代码视图也没关系,后续版本会允许在可视化视图中把数组转换为集合。
当创建一个集合后,还可以继续往这个集合中插入元素。使用“添加元素到集合”命令,该命令有两个属性:“集合”属性填写上一步创建的集合ObjSet;“添加元素”属性填写集合元素,可以是数字、字符串等,也可以是变量。
同一个集合中,能否既有数字元素,又有字符串元素呢?答案是肯定的!我们可以调用两次“添加元素到集合”命令,一次插入1,一次插入“2”,再输出调试信息,可以看到两个元素都成功的插入集合。
如果创建了多个集合,还可以计算它们的交集、并集(这些概念在初中数学课本中有阐述,如果您还不熟悉,可以忽略这段内容)。以取集合的并集为例。通过插入元素构建出两个集合,一个为{1, "2"},另一个为{"1", "2"}。添加一条“取并集”命令。该命令有三个属性:“集合”属性和“比对集合”分别填写需要合并的两个集合;“输出到”属性填写合并之后的集合变量。输出调试信息,可以看到合并之后集合变为{1, "1", "2"},这说明并集剔除了重复元素"2",1和"1"一个是数值,一个是字符串,不属于重复元素,因此同时选入并集。
以上内容的关键源代码如下:
ObjSet=Set.Create()
Set.Add(ObjSet,1)
Set.Add(ObjSet,"2")
TracePrint(objSet)
ObjSet2=Set.Create()
Set.Add(ObjSet2,"1")
Set.Add(ObjSet2,"2")
objSetRet = Set.Union(ObjSet,ObjSet2)
TracePrint(objSetRet)
创建好一个集合,或者计算出交集、并集之后,还可以把集合转换为普通的数组,流程创造者提供了一条命令实现此功能,请读者自行练习。
数据表
我们在前文中学习了二维数组的概念。数据表可以看作是一种特殊的二维数组,但比普通的二维数组增加了很多功能,例如可以包含表头,可以进行排序、过滤等实用的操作。
通过一个例子来看如何构建数据表。在命令列表中找到“数据处理”的“数据表”命令分类,选择并插入一条“构建数据表”命令。这条命令可以通过表头和构建数据,来生成一个数据表,该命令共有三个属性:“表格列头”属性,用于表示数据表的表头,可填写一个一维数组,我们这里填写的是["姓名", "科目", "分数"];接下来是“构建数据”属性,可以填写一个二维数组,表示数据表中的初始数据,这里填写的是[["张三", "语文", "78"],["张三", "英语", "81"],["张三", "数学", "75"],["李四", "语文", "88"],["李四", "英语", "84"],["李四", "数学", "65"]]。您也可以选择不要表头,或者不要初始数据,在相应的属性里输入null即可。
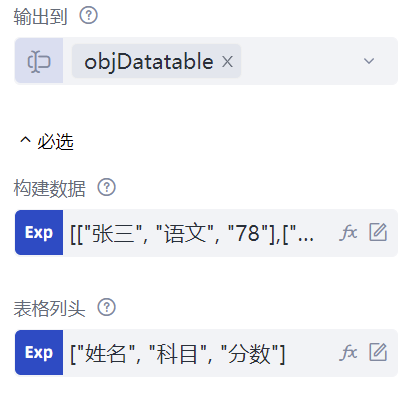
这样,数据表就构建好了,并且存储到了“输出到”属性中填写的变量objDatatable中。这个数据表实际上表示的是如下的一个表格,类似的表格在办公领域中经常遇到,可以举一反三:
| 姓名 | 科目 | 分数 |
|---|---|---|
| 张三 | 语文 | 78 |
| 张三 | 英语 | 81 |
| 张三 | 数学 | 75 |
| 李四 | 语文 | 88 |
| 李四 | 英语 | 84 |
| 李四 | 数学 | 65 |
数据表构建完成后,可以基于数据表进行读取、排序、过滤等各种数据操作。先来看数据的排序操作。插入一条“数据表排序”命令,这条命令共有四个属性:“数据表”属性填写待排序的数据表,这里填写上一步获得的数据表对象objDatatable;“排序列”属性表示按哪一列进行排序,这里填写的是"科目";“升序排序”属性指的排序方法,“是”表示升序,“否”表示降序。
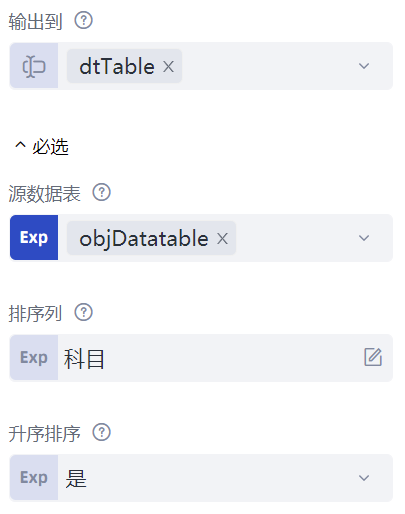
“输出到”属性填写排序之后的数据表对象,这里仍然填写objDatatable。使用“输出调试信息”命令查看排序后的数据表,如下所示:
| 序号 | 姓名 | 科目 | 分数 |
|---|---|---|---|
| 2 | 张三 | 数学 | 75 |
| 5 | 李四 | 数学 | 65 |
| 1 | 张三 | 英语 | 81 |
| 4 | 李四 | 英语 | 84 |
| 0 | 张三 | 语文 | 78 |
| 3 | 李四 | 语文 | 88 |
再来看数据的筛选。插入一条“数据筛选”命令,这条命令共有四个属性:“数据表”属性填写待筛选的数据表,这里填写上一步获得的数据表对象objDatatable;“筛选条件”属性指的是筛选出哪些满足条件的数据,点击属性栏右边的“更多”按钮,会弹出“筛选条件”输入框。筛选条件包括为“列”、“条件”、“值”的组合,例如"科目 等于 '语文'",表示筛选出科目为“语文”的所有数据。我们可以增加筛选条件,多个筛选条件可以是“且”的关系,也可以是“或”的关系。
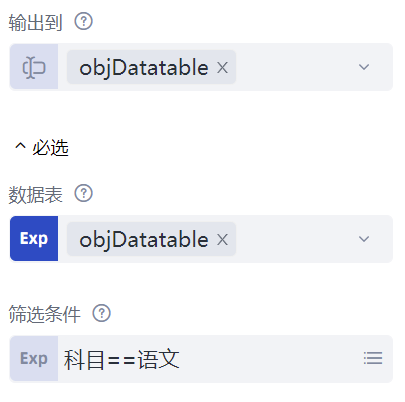
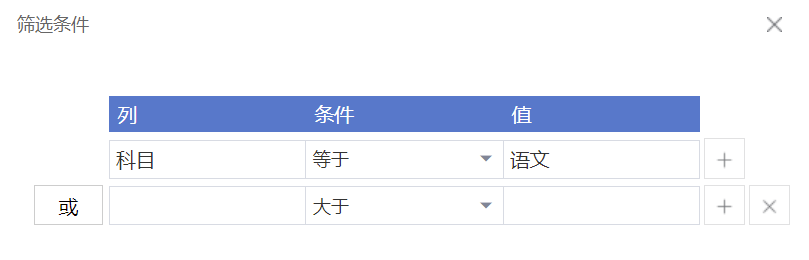
使用“输出调试信息”命令查看筛选后的数据表,如下所示:
| 序号 | 姓名 | 科目 | 分数 |
|---|---|---|---|
| 0 | 张三 | 语文 | 78 |
| 3 | 李四 | 语文 | 88 |
数据表还可以转换为二维数组,流程创造者提供了一条命令实现此功能,请读者自行练习。
字符串
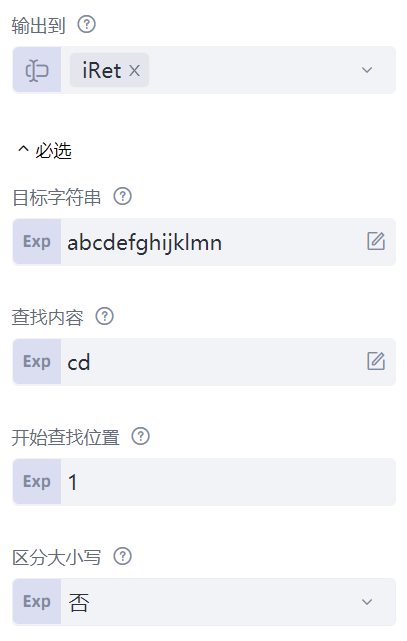
字符串是我们最常用的数据类型,字符串操作也是最常见的数据操作。熟练掌握字符串操作,后续开发将会受益良多。先来看一条最经典的命令:“查找字符串”。这条命令将会查找字符串内是否存在指定的字符,该命令有五个属性:“目标字符串”属性填写被查找字符串,这里填写的是"abcdefghijklmn";“查找内容”属性填写待查找的指定字符,这里填写的是"cd";“开始查找位置”属性指的是从哪个位置开始查找,起始位置为1;“区分大小写”属性指的是查找时是否区分大小写,默认为“否”;“输出到”属性填写一个变量iRet,该变量保存查找到的字符位置。运行命令,显示变量iRet的值,输出结果为3,表明"cd"出现在"abcdefghijklmn"的第3位。如果要查找的字符串不存在,输出的结果将会是0。
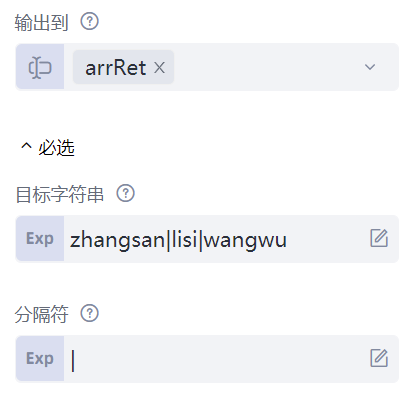
再来看一条常见的字符串操作:“分割字符串”命令。这条命令使用特定分隔符,将字符串分割为数组。比如可以用这条命令来处理前面提到的CSV格式文件,因为CSV格式文件中是有明确的分隔符的。该命令有三个属性:“目标字符串”属性填写待分割的字符串,这里填写"zhangsan|lisi|wangwu";“分隔符”属性填写用以分割字符串的符号,这里填写的是"|";“输出到”属性保存分割后的字符串数组到arrRet。为了查看结果,我们再来添加一条“输出调试信息”命令,输出变量arrRet的值,可以看到结果为[ "zhangsan", "lisi", "wangwu" ],表明字符串"zhangsan|lisi|wangwu"通过分隔符"|",被成功地分割为字符串数组[ "zhangsan", "lisi", "wangwu" ]。
正则表达式
在编写字符串处理流程时,经常会需要查找和测试某个字符串是否符合某些特定的复杂规则,正则表达式就是用于描述这些复杂规则的工具,它不仅可以很方便地对单个字符串数据进行查找和测试,也可以很好地处理大量数据(如:数据采集、网络爬虫等)。
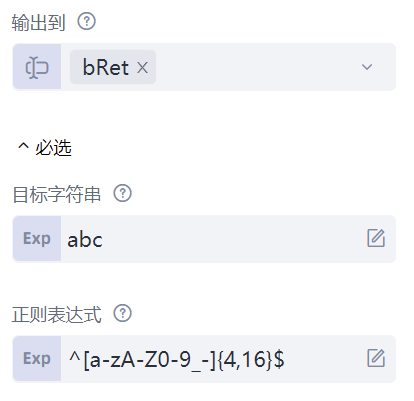
先来看“正则表达式查找测试”命令,这条命令尝试使用正则表达式查找字符串,能够找到则结果为真(True),找不到则结果为假(False),该命令可用于判断一个字符串是否满足某个条件。该命令有三个属性:“目标字符串”属性填写待测试的字符串;“正则表达式”属性填写正则表达式;“输出到”属性保存测试结果。举个例子,网站判断用户输入的注册用户名是否合法,首先将合法用户名的判断条件写成正则表达式,然后使用正则表达式去测试用户输入的字符串是否满足条件。具体来看,“正则表达式”属性填入"^[a-zA-Z0-9_-]{4,16}$",表示注册名为4到16位,字符可以是大小写字母、数字、下划线、横线;“目标字符串”如果填入"abc_def",测试结果为True,说明"abc_def"符合正则表达式。“目标字符串”如果填入"abc"或"abcde@",测试结果为False,因为"abc"的长度为3,"abcde@"中含有字符"@",都不符合正则表达式规则。
注意:在上面的正则表达式中,开头的"^"符号和结尾的"$"符号代表匹配到字符串的开头或者结尾,有了这两个符号,待测试的字符串必须全部匹配正则表达式,才会得到True的结果。如果没有这两个符号,则待测试的字符串中只要包含了能匹配的子串,就会得到True的结果。
再来看“正则表达式查找全部”命令,这条命令使用正则表达式查找字符串,并找出所有满足条件的字符串。该命令也有三个属性:“目标字符串”属性填写待查找的字符串;“正则表达式”属性填写正则表达式;“输出到”属性则以数组的形式,保存所有找到的子串。举个例子,“目标字符串”属性填写网络爬虫爬回来的一段网页,如下所示:
<p/>
<img src="https://avatar.csdn.net/A/4/C/3.jpg"/>
<p/>
<img src="https://g.csdnimg.cn/static/1x/11.png"/>
<p/>
“正则表达式”属性填写 https?://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|],这段正则表达式看起来很复杂,其实它不是我写出来的,是我在互联网上找到的一段可以用来匹配URL的正则表达式。
通过这个正则表达式,就可以把爬回来的网页中的所有链接全部抽取出来。
配置好属性之后,选中这一行命令,点击右边的三角形,单独运行这一行命令,即可自动输出结果。可以看到结果为:
arrRet = [
"https://avatar.csdn.net/A/4/C/3.jpg",
"https://g.csdnimg.cn/static/1x/11.png"
]
两个URL都被成功地抽取出来了!
正则表达式命令的使用本身不难,难点在于正则表达式如何书写。对于这方面内容,互联网上已经有大量的教程了,本文不再赘述。
JSON
JSON是一种轻量级的数据交换格式,用于存储和交换文本信息。JSON易于被人阅读和编写,同时也易于机器解析和生成。JSON在用途上类似XML,但比XML更小、更快,更易解析。
流程创造者共有两条JSON命令,一条是“JSON字符串转换为数据”,一条是“数据转换为JSON字符串”。这里的数据,指的是流程创造者中数组、字典格式的数据。也就是说,通过这两条命令,可以把JSON字符串和流程创造者中的数组、字典进行双向转换。其中流程创造者中的数组对应于JSON中的Array(中文通常也称为数组),流程创造者中的字典对应于JSON中的Object(中文通常称为对象)。
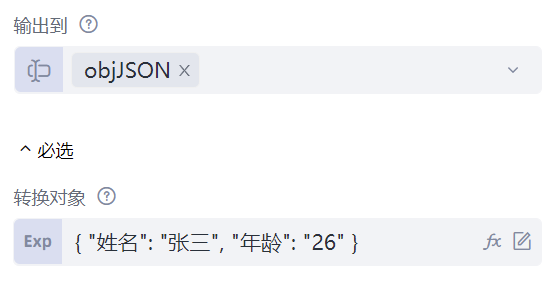
先来看“JSON字符串转换为数据”命令,这条命令可以将JSON形式的字符串转换为流程创造者中的数组或者字典。该命令有两个属性:“转换对象”属性,填写JSON字符串,这里填写的是{ "姓名": "张三", "年龄": "26" }。“输出到”属性,填写转换后的流程创造者变量,例如我们这里填写objJSON。
使用“输出调试信息”命令,可以输出结果:{ "姓名": "张三", "年龄": "26" }。有的读者可能会觉得疑惑,这输入和输出看起来没啥区别?其实不然!注意在上图中,我们在填写JSON字符串的时候,是采用普通模式输入的(左边的Exp按钮为灰色),实际上流程创造者会进行必要的转义后,将其变成一个字符串。切换到专业模式(点击Exp按钮,使其变为蓝色),就可以看到这个字符串的细节。而输出则是一个流程创造者中的字典。输入字符串,输出字典,两者在使用时差别很大。例如,流程创造者中的字典可以采用objJSON["姓名"]的方式,来使用其中相应元素的值,其结果为"张三",而字符串就不能使用这种方式来操作了。
切换到源代码视图来尝试一下:
TracePrint(objJSON["姓名"])
既然能访问,应该也能修改,添加一条赋值语句,该语句将objJSON的"年龄"修改为30。
objJSON["年龄"]="30"
最后,再通过“数据转换为JSON字符串”命令,将修改后的JSON对象转换为字符串。这条命令共有两个属性:“转换对象”属性,填写待转换的数组或字典,也就是前面一直使用的objJSON;“输出到”属性填写一个字符串变量,该变量将会保存转换后的JSON字符串。使用“输出调试信息”命令查看转换后的JSON字符串:"{ "姓名" : "张三", "年龄" : "30" } ",可以看到,其内容修改成功。
下面来做一个综合的实验:读取一个JSON格式的文件,将读到的数据修改后再写回。首先,我们新建一个流程,并在流程所在文件夹下的res文件夹下新建一个person.json文件,其内容为:
{ "姓名" : "张三", "年龄" : "30" }
打开流程块,切换到源代码模式,把下面的源代码粘贴进去。
Dim obj
File.Read(@res"person.json","auto")
obj=JSON.Parse($PrevResult)
obj['性别']='男'
JSON.Stringify(obj)
File.WriteFile(@res"person.json", $PrevResult)
这个简单的流程综合使用了本章所述的文件读写和JSON数据处理的命令,运行后,再次打开person.json文件并进行查看,可以看到,在其内容中增加了一个字段“性别”,取值是“男”。
这段流程并不复杂,即使不加注释,相信读者也不难读懂。稍微值得注意的一点是:这段流程里面两次使用了系统变量$PrevResult,来指代“上一条命令的结果”。如果某条命令的输出仅作为下一条命令的输入,而不会用在其他地方,那么采用这个系统变量,可以减少对变量的定义和使用。并且,把流程切换到可视化视图的时候,也会更加简洁易读。
时间
时间操作命令主要包括时间数据和字符串的互相转换,以及对时间数据的各种操作。首先来看如何获取当前时间,在命令中心“数据处理”的“时间”命令分类下,选择并插入一条“获取时间”命令。这条命令可以获取从1900年1月1日起到现在经过的天数,该命令只有一个“输出到”属性,保存当前时间,这里填写dTime。在可视化视图下,点击这一行命令右边的三角形,运行这一行命令,会自动输出得到的结果:43771.843969907,说明从1900年1月1日到现在,已经过去了43771.843969907天,后面的小数位代表了一天当中的时、分、秒,大家可以大致估算一下是否正确。
用这种方式来保存时间,有时候会更容易处理,比如要获得100天以后的时间,只需要把上面的值加100就可以了,而不用考虑年、月、日的进位。当然,这种表示时间的方式毕竟不符合我们的日常习惯,不适合给人阅读。如果需要把时间展示给人去看,则可以通过“格式化时间”命令,将时间数据转换成各种格式的字符串。“格式化时间”命令有三个属性:“时间”属性填写刚刚得到的时间数据dTime;“格式”属性填写时间格式,其中年(yyyy)占4位、月(mm)、日(dd)、24小时(hh)、分(mm)、秒(ss)都占2位,例如"yyyy-mm-dd hh:mm:ss"填写时间后转换为:"2019-11-02 20:29:58";“输出到”属性保存格式化时间的字符串。细心的读者可能已经发现了:用这种格式,“月”和“分”的格式都是mm,这是因为这两个词在英语中分别是"month"和"minute",都是以字母m开头的。所以格式都是mm,而流程创造者会根据上下文来判断mm到底是指代“月”还是“分”。如果您希望更加明确地指定,而不要让流程创造者去判断,也可以用大写的MM来作为“月”的格式,而用nn来作为“分”的格式,效果是一样的。
除了将时间数据转换成各种格式的字符串,也可以直接获取时间数据的某一分项。例如可以使用“获取月份”命令获取时间数据dTime中的月份,以此类推,其它命令类似。