Instructions for use
Let's try according to the instructions!
Using Guidance
1. Configure extraction model
Complete the configuration of extraction model under the self training extraction AI Capability of Laiya Laiye Intelligent Document Processing, and test whether the effect meets the expectations.
For the specific operation process, see How to Configure a Self trained Extraction Model
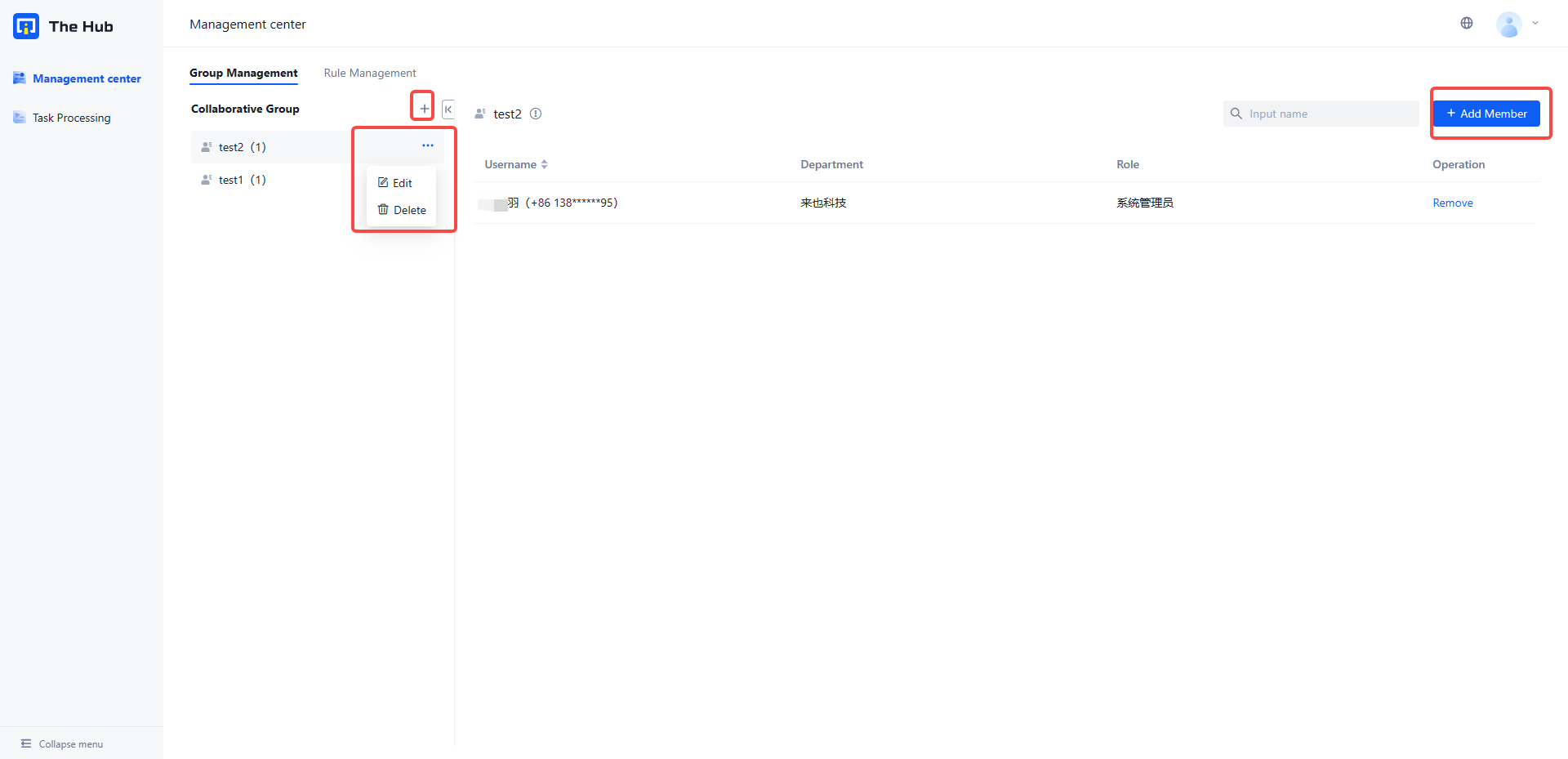
2. Configure Collaborative Group
Click on the 'Management Center' directory Collaboration group management , Members of the Collaborative Group or Collaborative Group can be managed
Before adding a member to the Collaborative Group, please ensure that the user belongs to the same organization as you, and has opened the task Processing module for the user, otherwise the user cannot enter the platform for processing after receiving the collaboration task
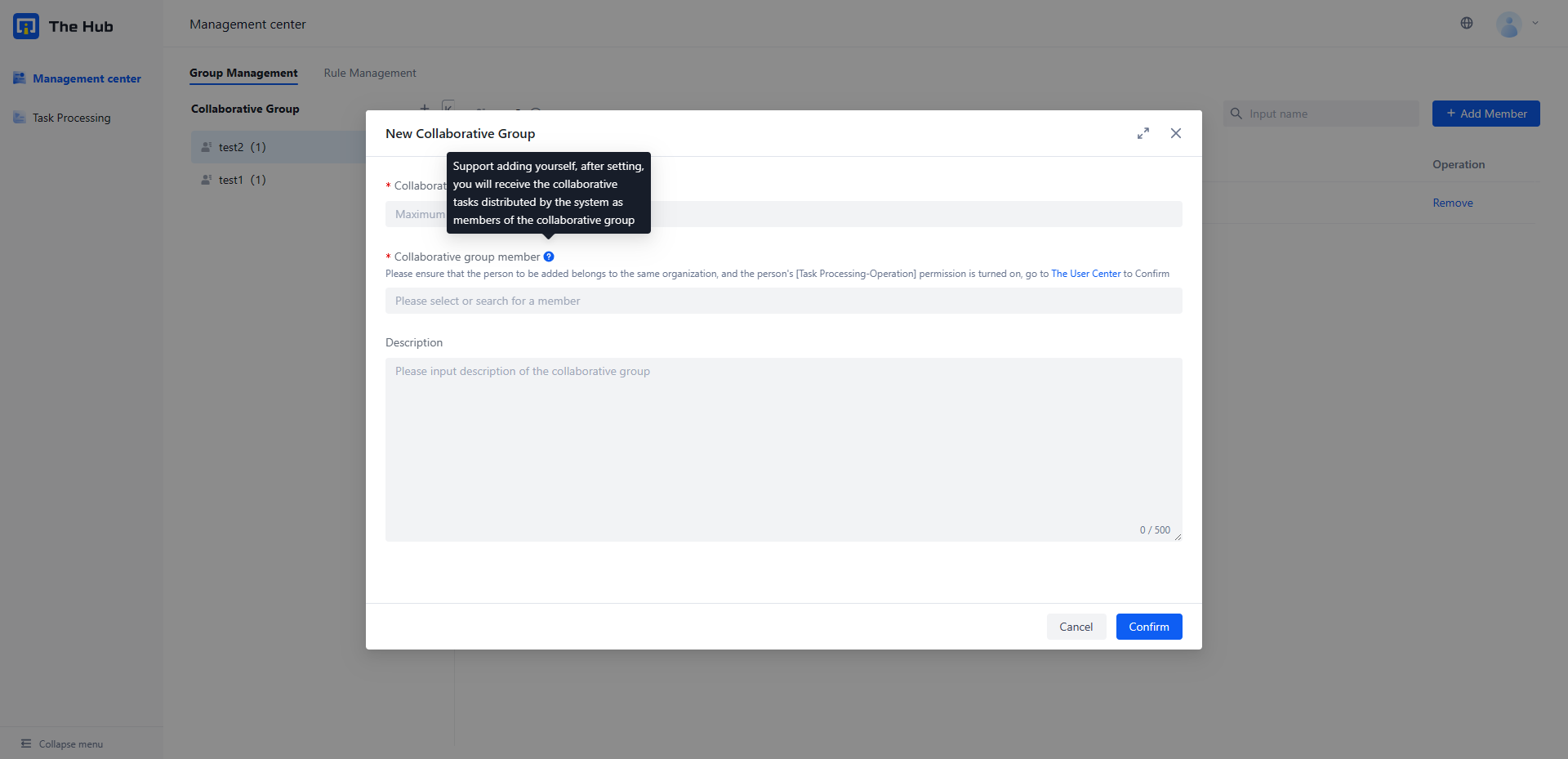
3. Configure Collaboration Rules
Basic: Click on the 'Management Center' directory Collaborative Rule Management , Open the [New Collaboration Rule] pop-up window and complete the basic information filling
Select the collaboration group: Only members within the collaboration group can receive and process the collaborative tasks generated based on this collaboration rule, and other personnel cannot view them.
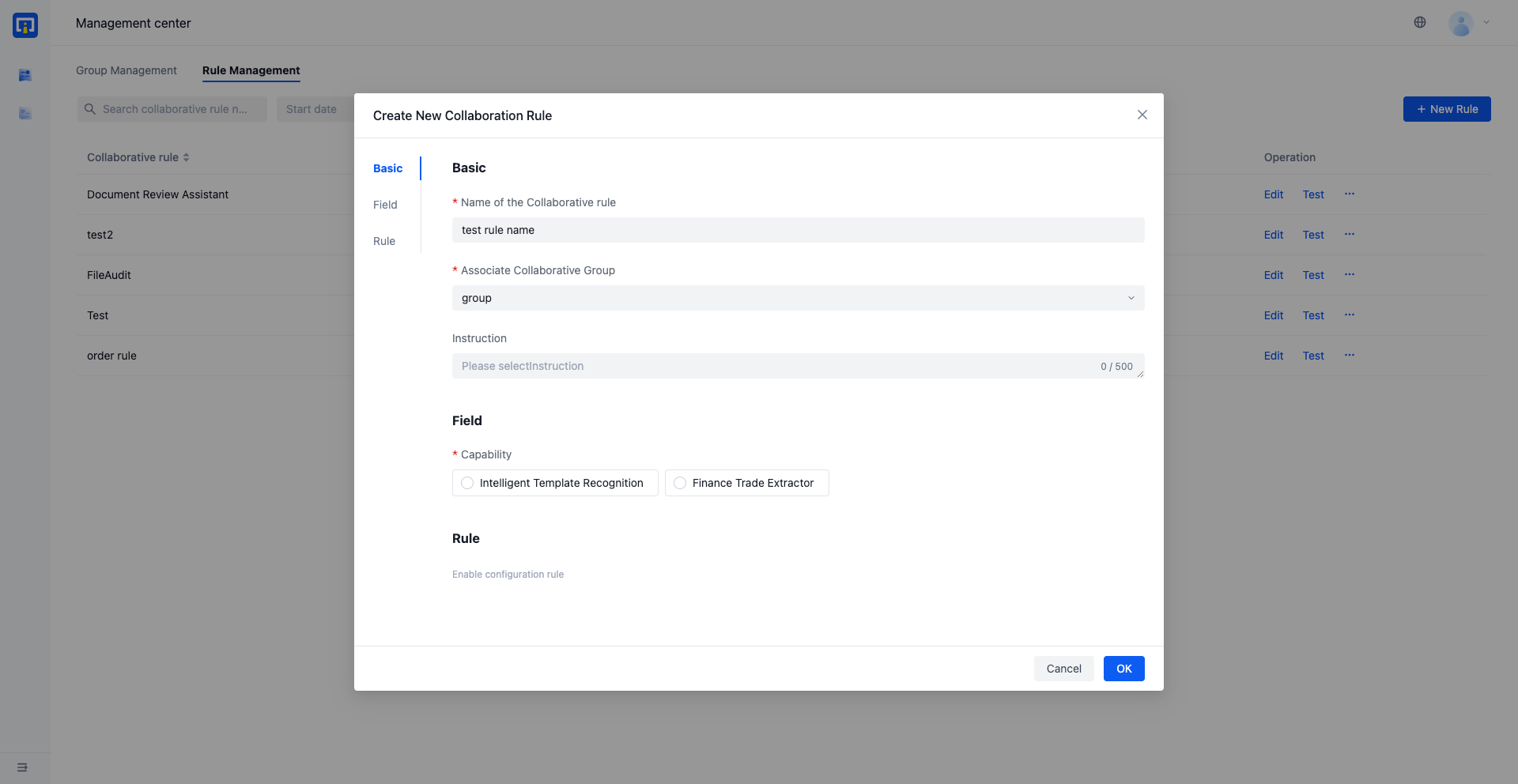
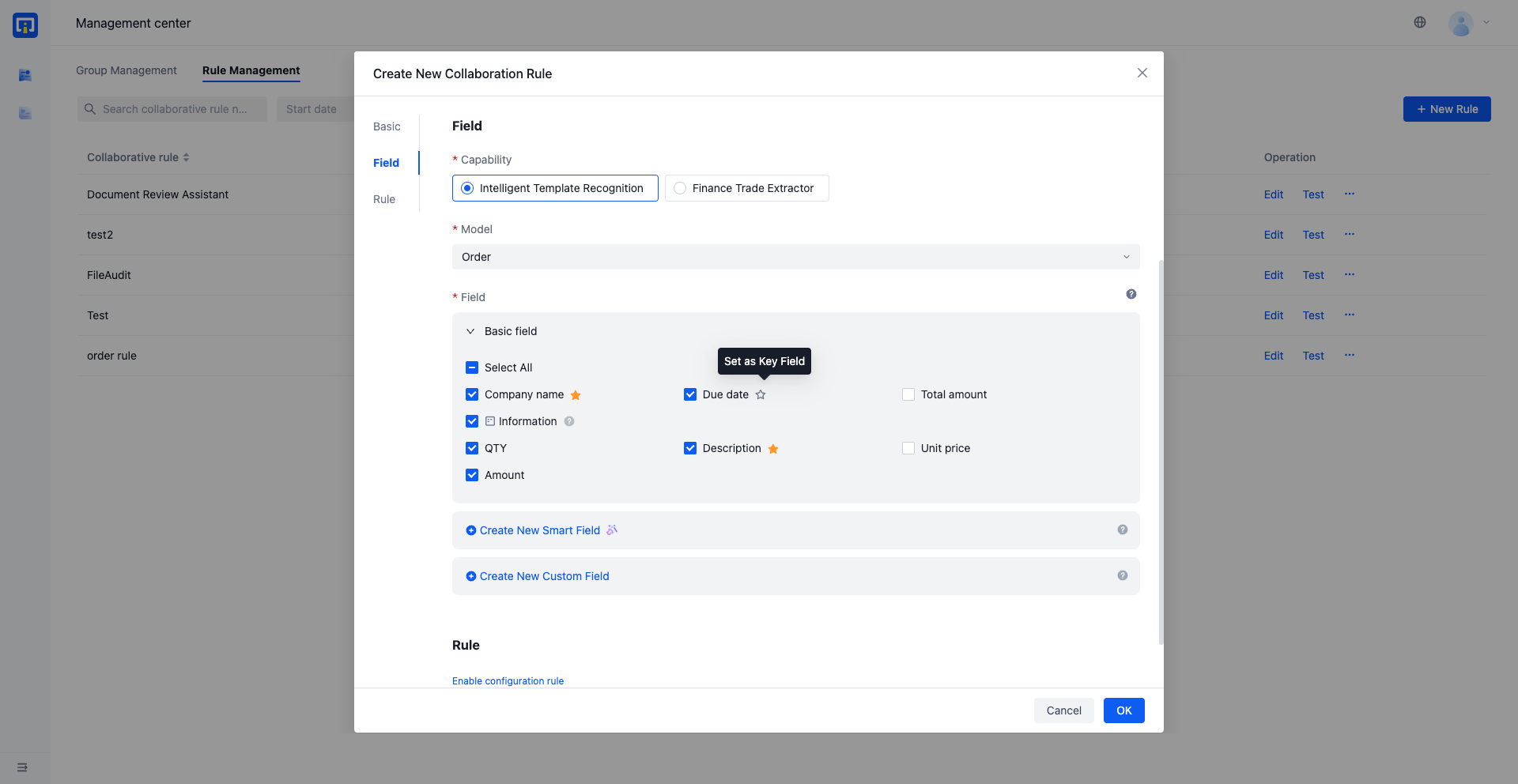
Field: Select the model that has the live version and check the fields that you want to extract. You can select Basic fields or flexibly add Intelligent fields or Custom fields
Basic field: Check the existing fields in the model
Intelligent fields: Extracts document information based on field names and descriptions based on a large language model
Custom fields: Define fields other than the model extraction results to meet specific business requirements
Set key fields: Click the star mark after the field to set it as a key field, and it can be filtered and viewed during task processing.
Rule: Select to enable rule settings, and personalized requirements can be added to the current collaboration rules. Support basic review, intelligent review, and Empty Field Setting.
Basic audit: When on, the system will meet the conditions for manual processing, only support the selection of basic fields; When turned off, the system leaves all collaborative tasks for manual processing
Intelligent audit: Based on the large language model, the audit goals and expectations are set in natural language. If any audit rule is not passed, the business personnel will be asked to review, and only the intelligent field can be selected
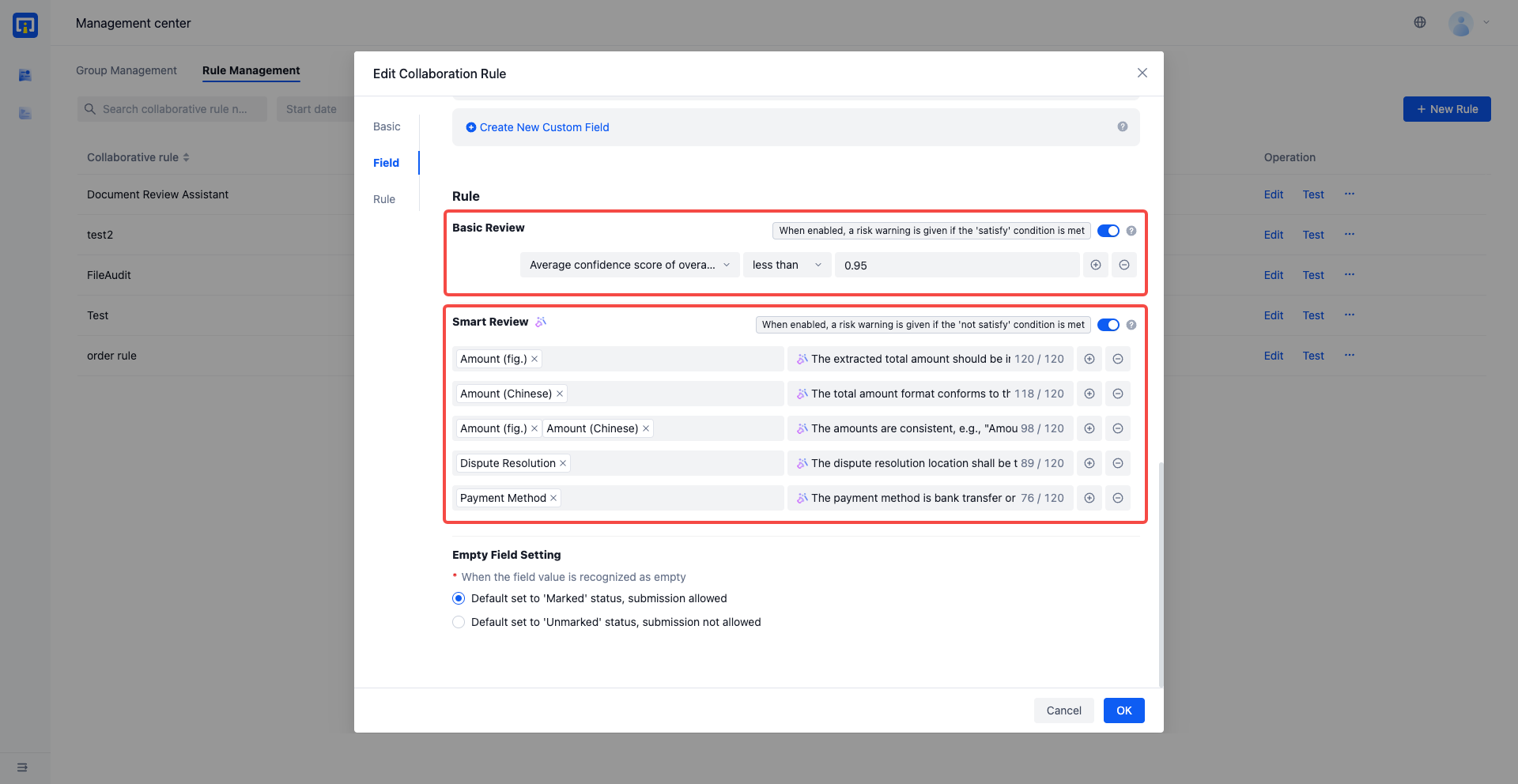
Empty Field Setting:It supports configuring the initial state of tasks in the collaborative form according to business requirements, so as to meet various business requirements.
When the field value is recognized as empty, it is defaulted to the marked state and submission is allowed.
When the field value is recognized as empty, it is defaulted to the unmarked state and submission is not allowed.
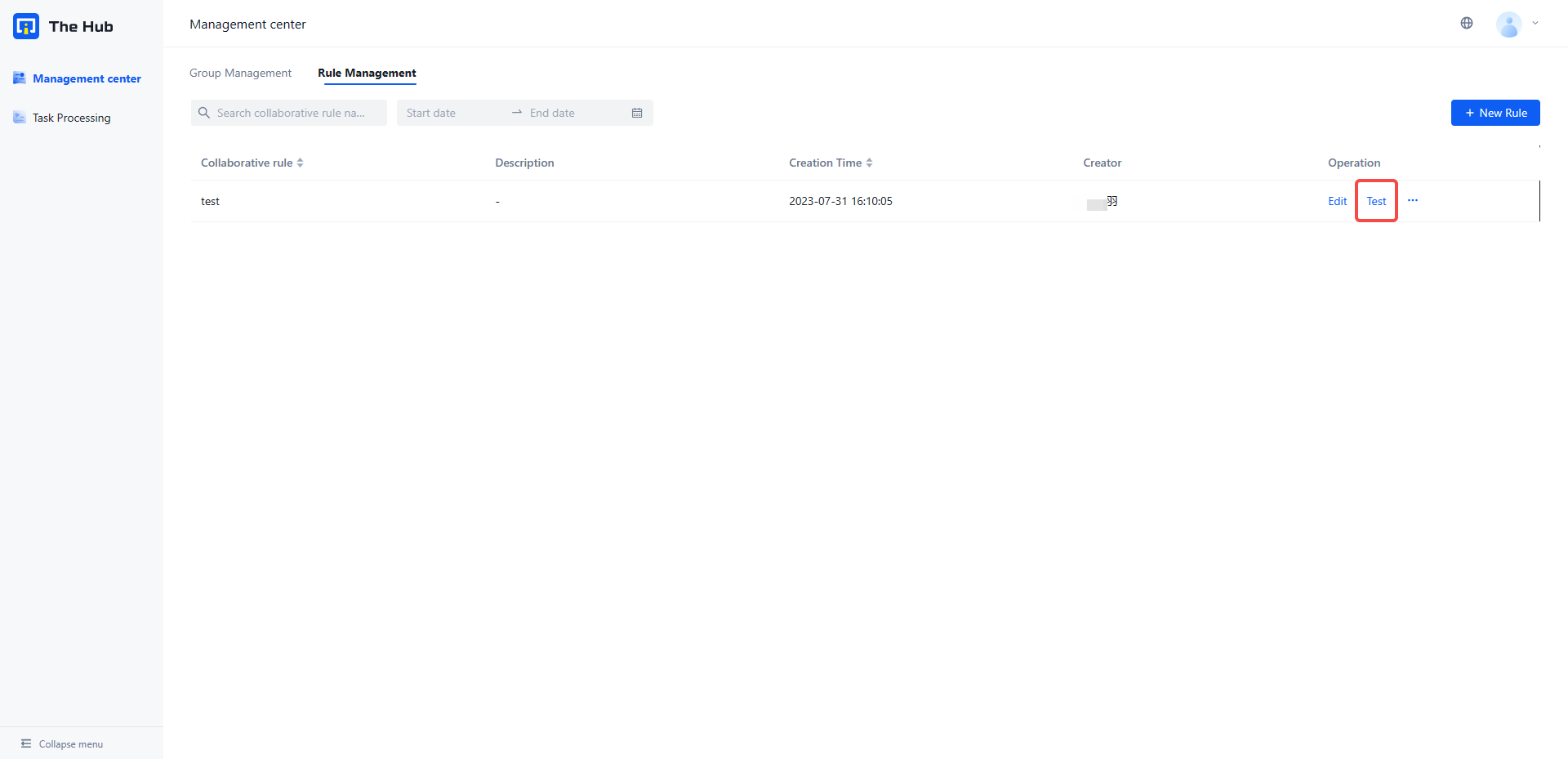
- Test Collaboration Rules
- Select the newly configured collaboration rule and click on the test , Open the new collaboration rule task pop-up window
- After uploading the document, submit the collaborative task and go to Task processing Check whether the collaboration task has been generated successfully
- Receive and handle collaborative task
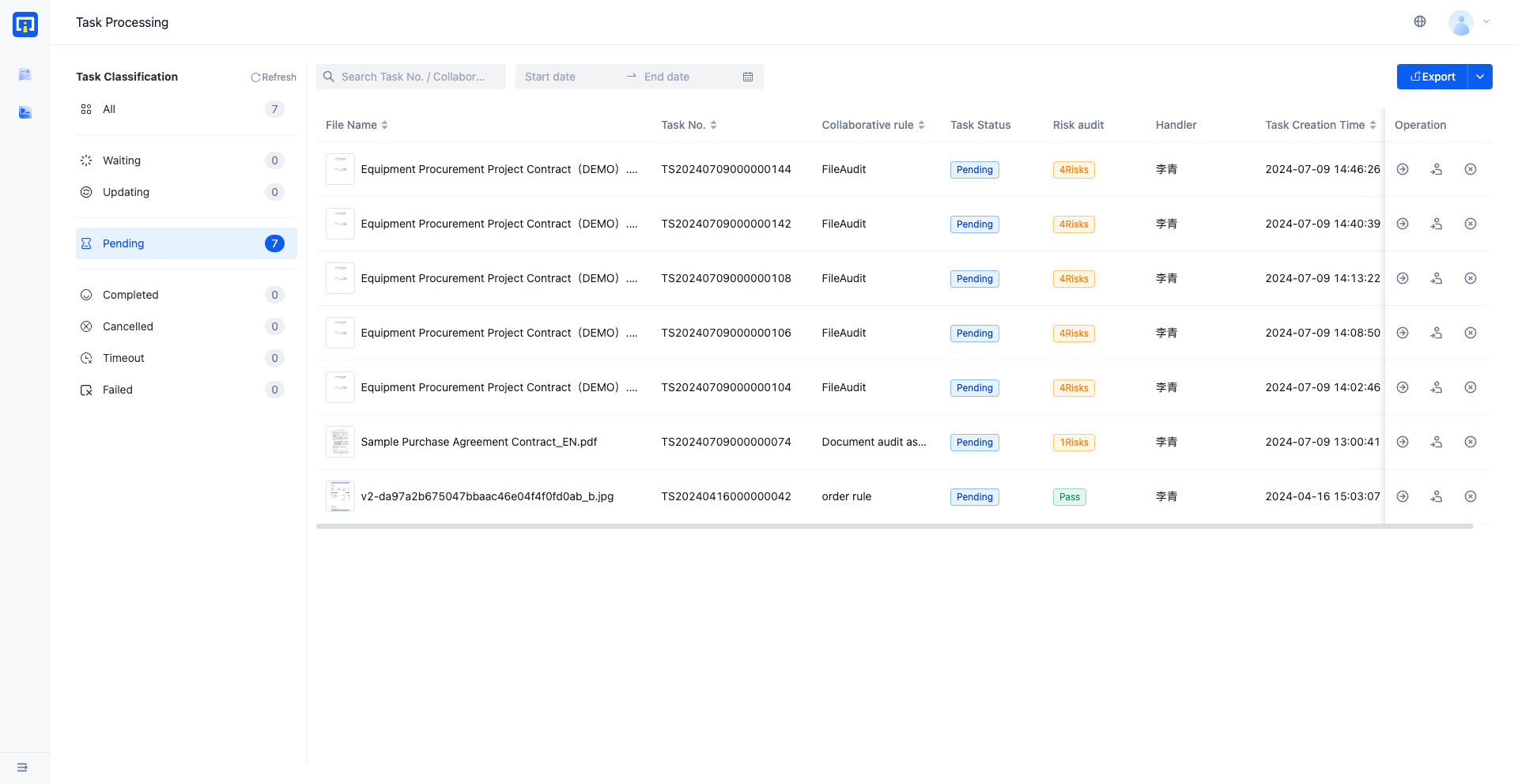
4. Process collaborative task
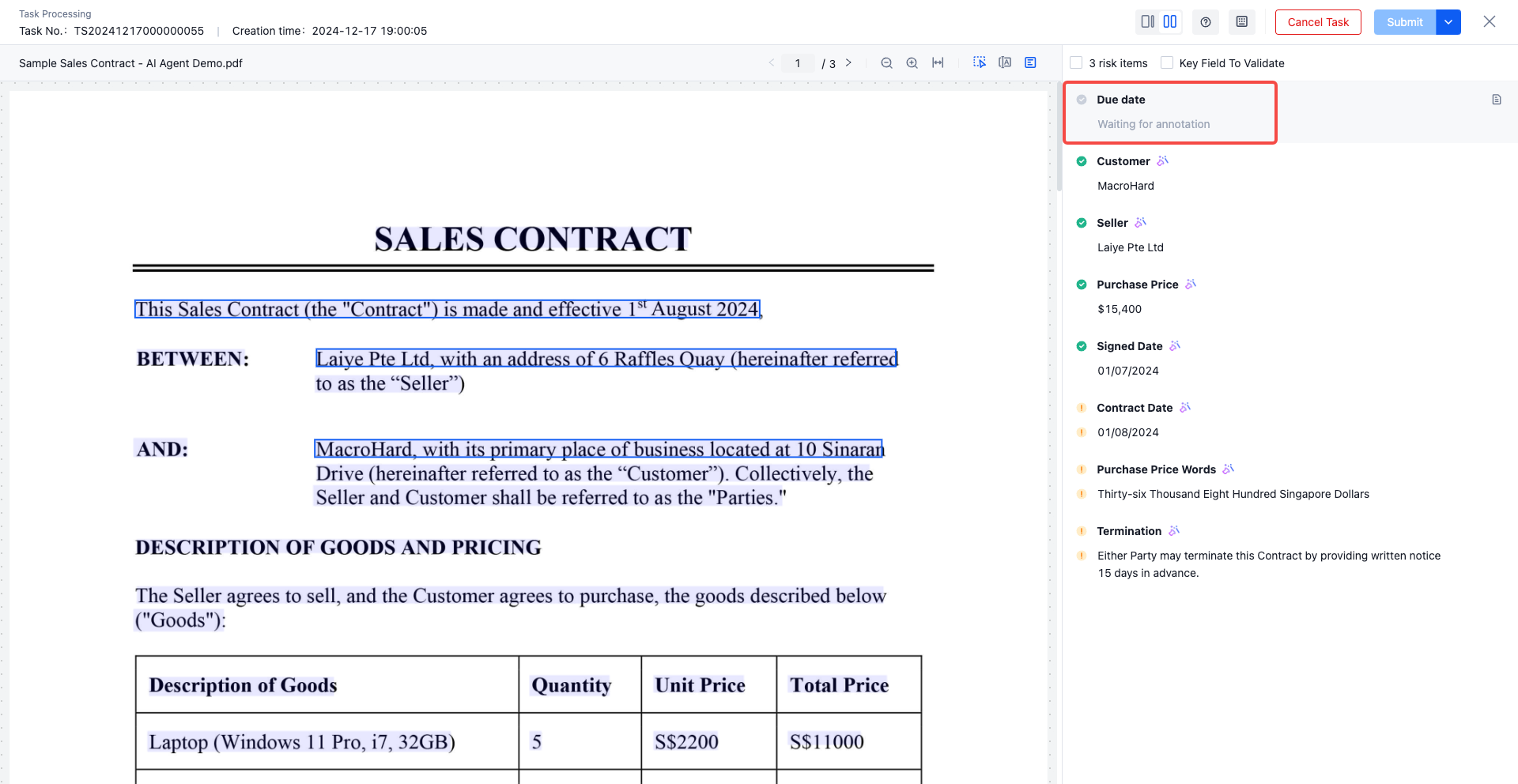
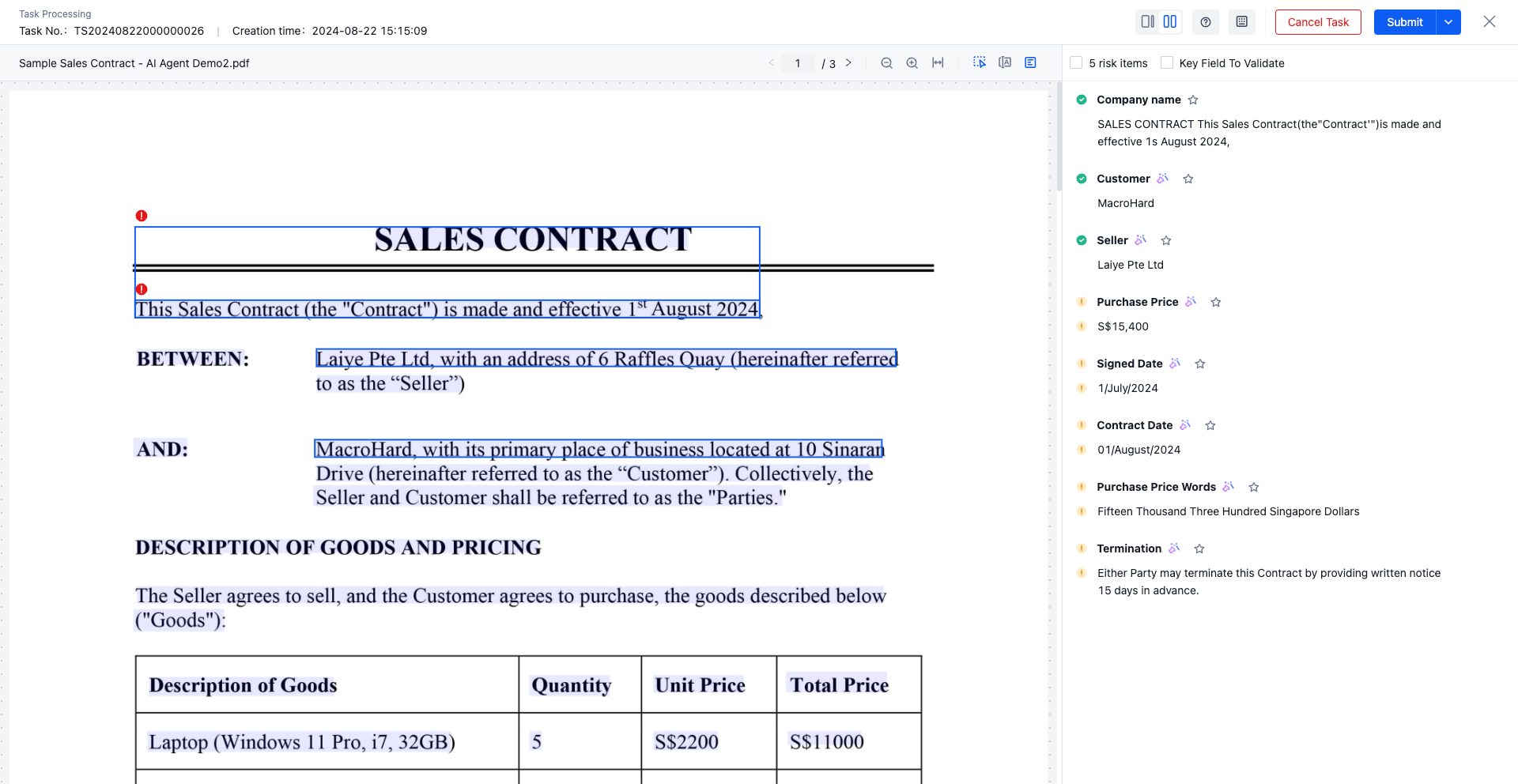
- Select a collaboration task to be processed, and open the task processing UI. The left side is the data file view, and the right side is the extracted key information
- Business personnel can review and modify the information extraction results in this UI
- Click on the extracted value ->Highlight the corresponding position of the left image data
- Double click on the extracted value ->enter editing status
- You can clear the extracted key information by clicking the "Delete Mark" of the left document box selected value hover or clicking the "Delete" button of the right extracted value
- After reviewing all fields, click Submit , Task processing completed
Task Processing UI
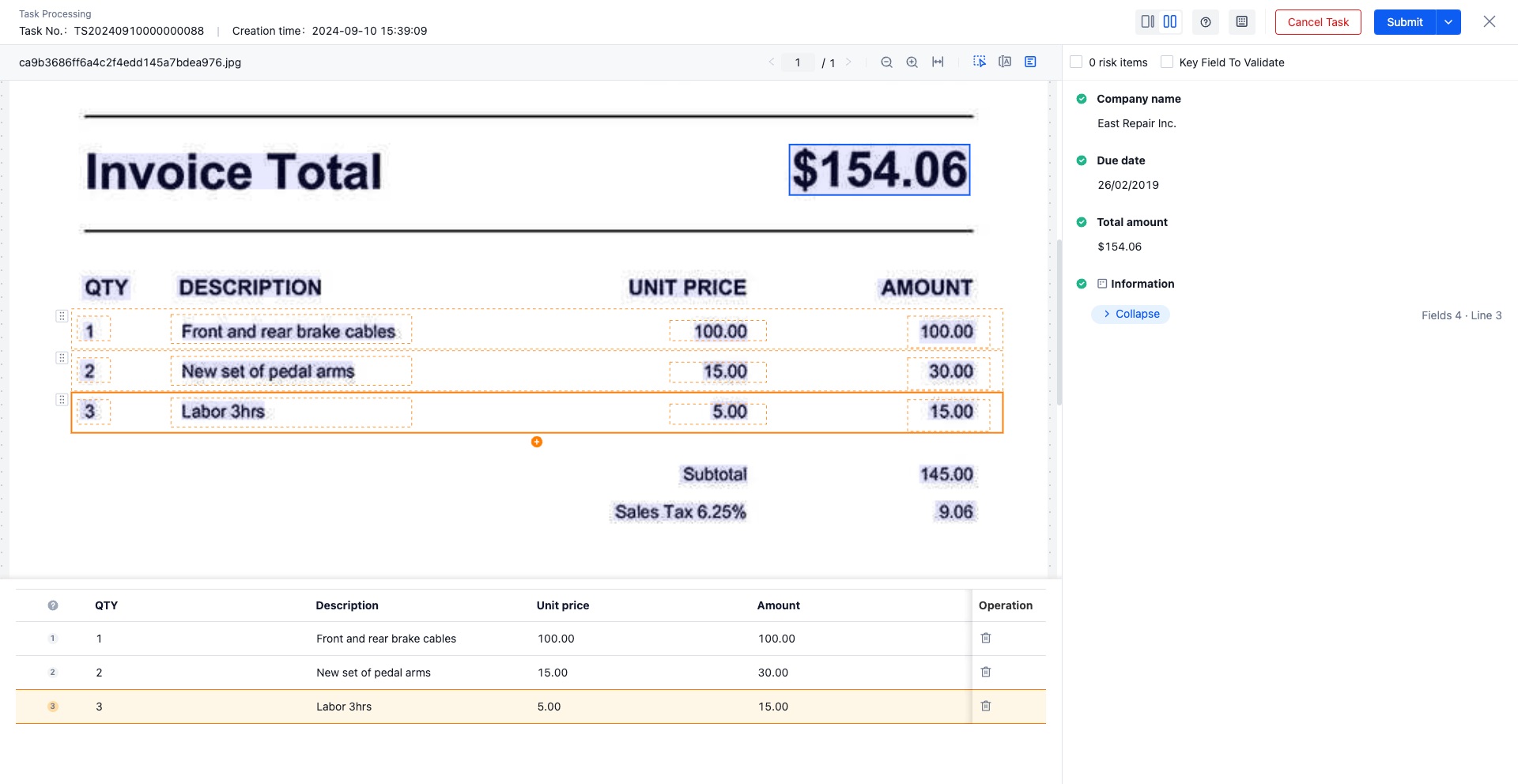
- On the left is the data file view, and on the right is the extracted key information, arranged in vertical columns
Task processing UI (with structured display)
- Model launch version selection Document self training Training method, and the model contains line_extract Field or group Field, the task processing UI will display the extracted line_extract or group Field Information in fields
5. Initiate collaborative task through API and obtain processing results
- Since the processing of collaborative task requires manual intervention and the processing time is uncertain, we provide two asynchronous interfaces - initiating task and obtaining results, which support flexible configuration of business process
- Select the corresponding collaboration form and click on the API , Obtain API call credentials
- According to** Interface document **Making API calls
- Initiate a collaboration task by creating a collaboration task interface, and obtain the final extraction result of a document by querying the collaboration task result interface
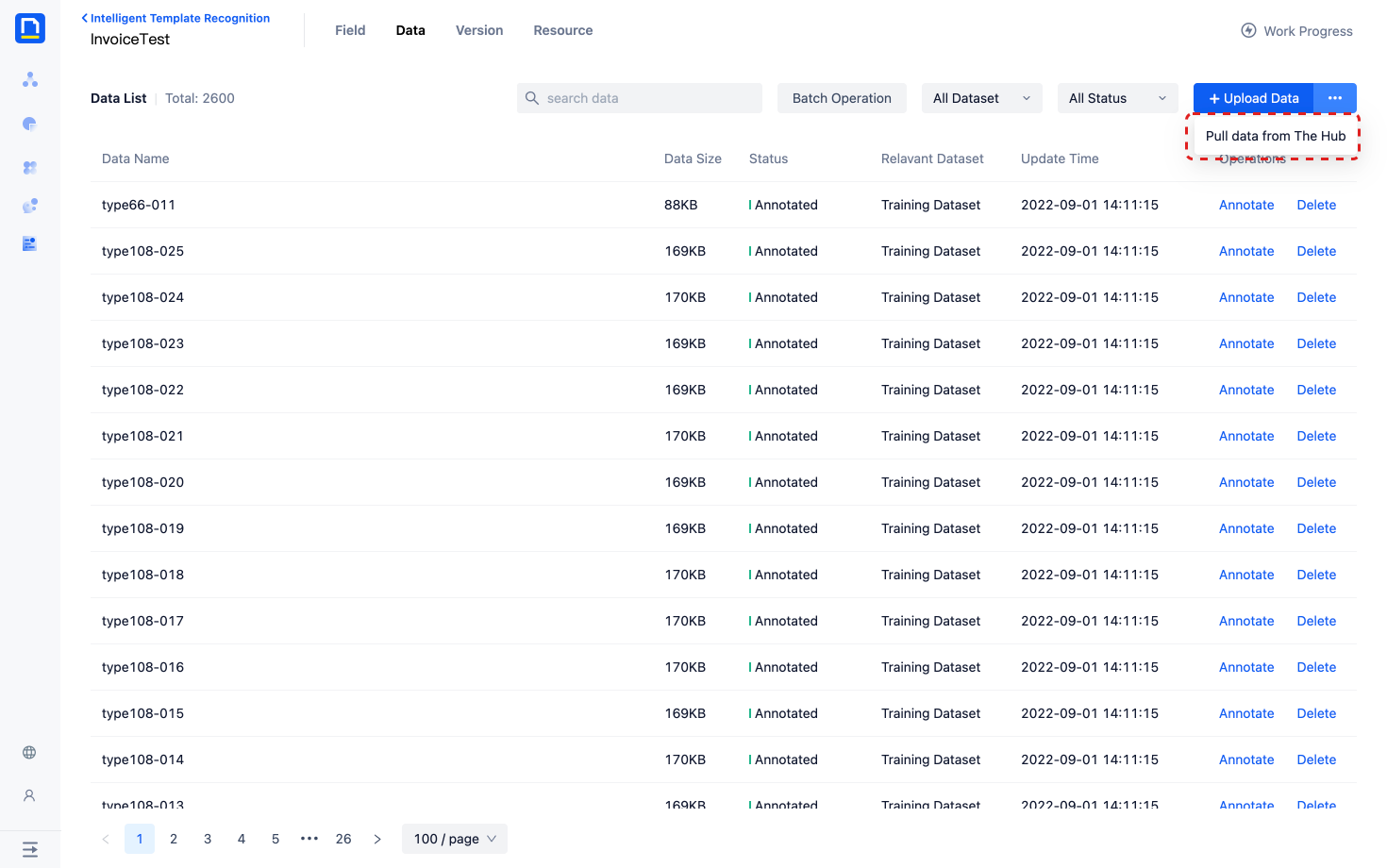
6. Obtain business data to enhance model effectiveness
- Support obtaining processed data on the human-machine collaboration platform under the same AI capabilities to optimize the model in IDP Intelligent Template Recognition.
Specific scenario usage
1. I hope to define fields outside of the IDP extraction model results
Examples of applicable customer scenarios:
- Scenario A : The business demand to extract the Goods Purchase Document. Information such as "commodity name" can already be extracted from the bill, but the quality business of these commodities has its own classification system (the original bill does not contain this information, and the previous business flow used manual identification and handwritten marks on the document)
- Solution: Additional creation Product grade Custom fields, created through OpenAPI for Product grade Add "first class goods", "second class goods", "third class goods" and other alternative value ranges in the field, and the business personnel can quickly select values from the drop-down box on the task processing page
- Scenario B : The business demand extracts the Purchase PO Document, hoping to combine its information with the Production MO Document in the enterprise ERP system, and link the upstream and downstream information of the goods (production reason ->production number)
- Solution: Additional creation Production MO number Custom fields, export production MO order number product data from the enterprise ERP system (or other internal systems), and configure this data information through OpenAPI as Production MO number The range of alternative values for fields allows business personnel to fuzzily search for option content and quickly label downstream production information for purchase PO documents
- Scenario A : The business demand to extract the Goods Purchase Document. Information such as "commodity name" can already be extracted from the bill, but the quality business of these commodities has its own classification system (the original bill does not contain this information, and the previous business flow used manual identification and handwritten marks on the document)
Restriction Description :
- Restrict custom fields to 'string' type and post process to 'not processed'
- The default input method for custom field values is' manual input '
- To configure the "dropdown list input field value" method for fields, please implement it through the human-machine OpenAPI
Rule Configuration Page :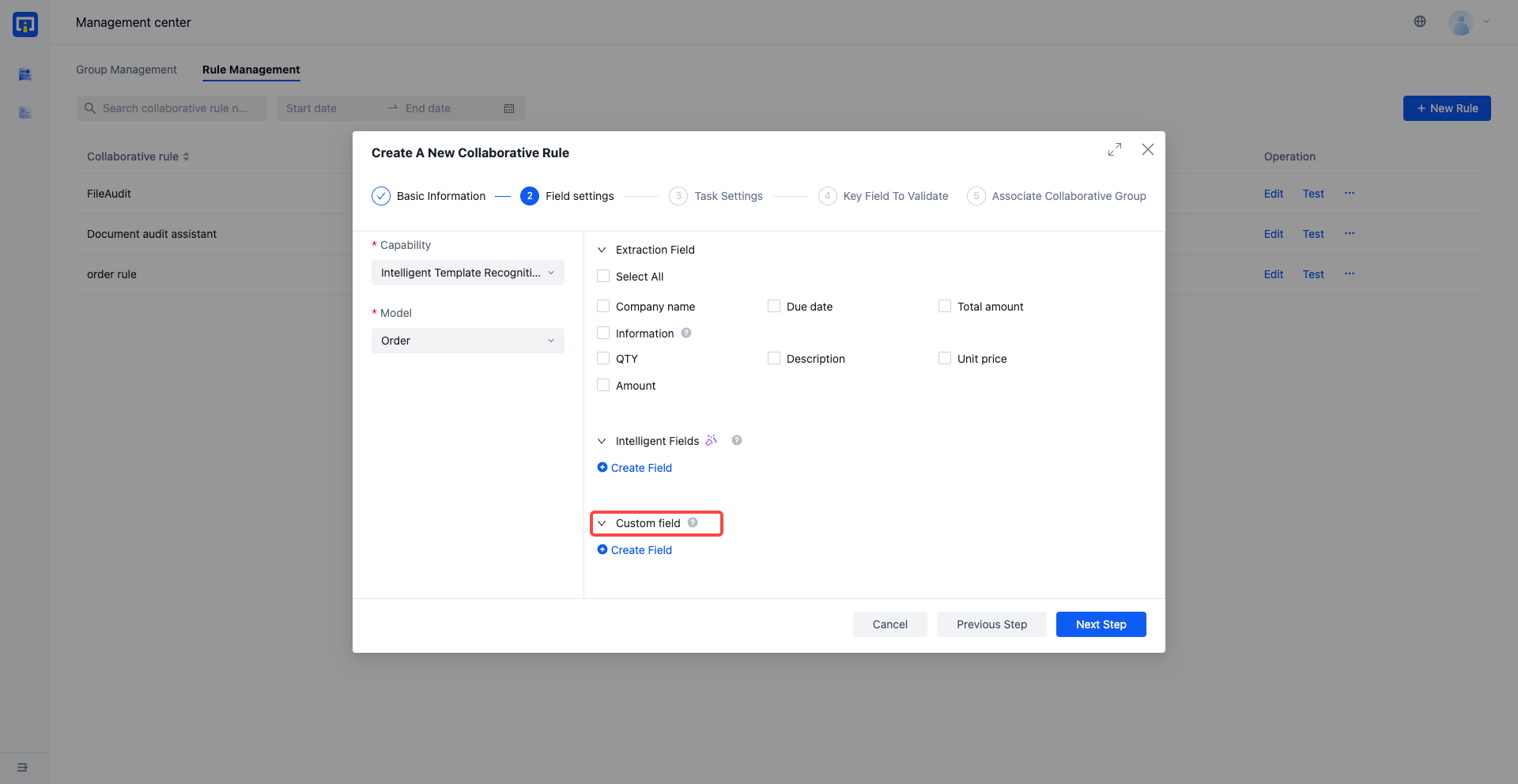
Task Processing Page :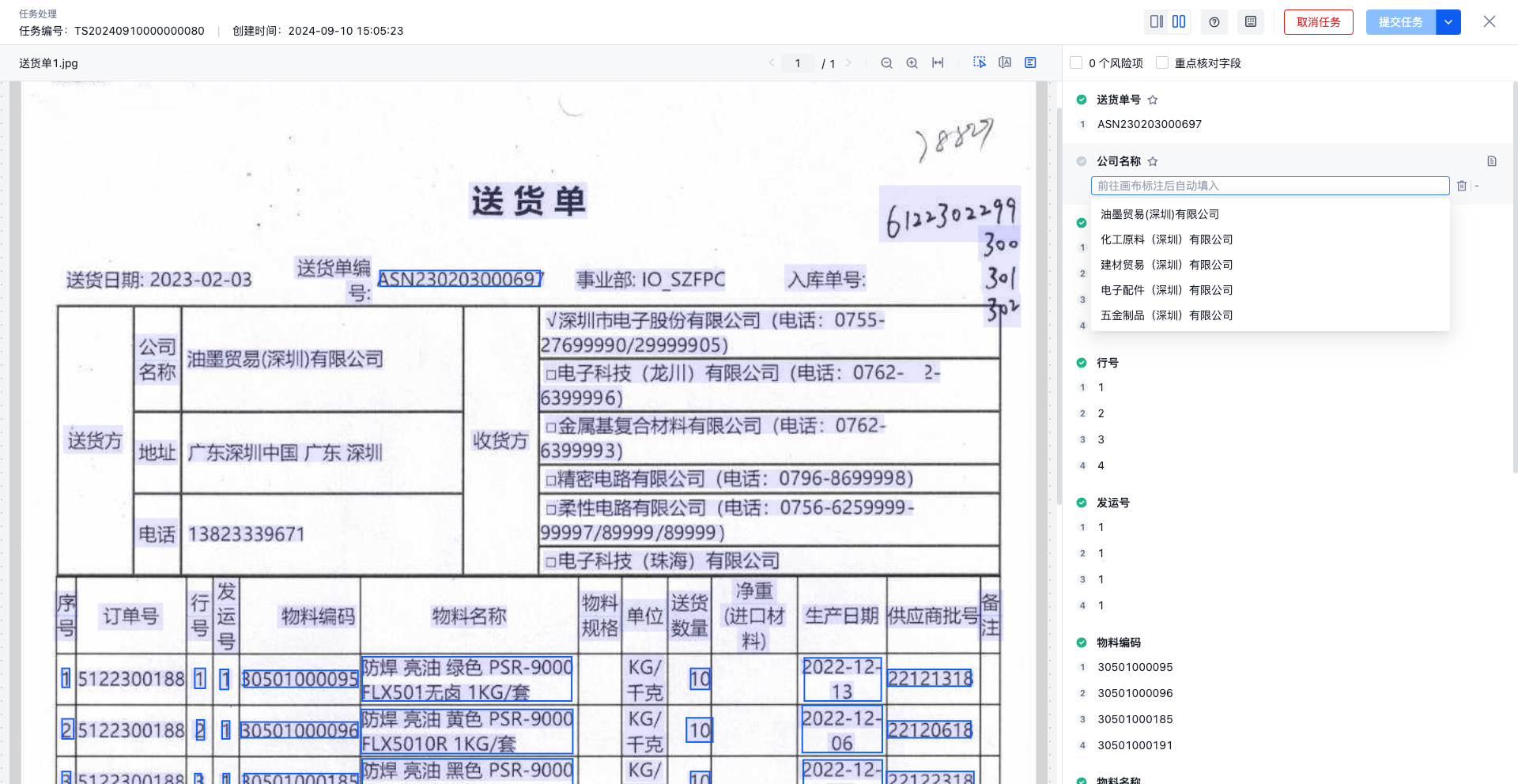
2. I hope to modify the values in the IDP extraction model results (such as linking RPA to achieve batch "post processing" of the extraction results)
Achieve this goal through Hub's openAPI-update collaborative tasks
Examples of applicable customer scenarios:
- Scenario A: The customer needs to extract multiple pages of cargo transportation documentation, each page of which has information such as the “amount” “date” “quantity” of the goods, but the business department has more complex conversion logic in the face of these numbers in the documentation to calculate the degree of cargo transportation risk.
- Solution: Create a custom risk value field through human-machine collaboration, the initial value is empty, and obtain the “amount” “date” “quantity” of each page in the IDP model through OpenAPI-query collaborative task results, and complete the conversion through a third party. Finally, use OpenAPI-update collaborative task to update the calculated value to the risk value field.
- Scenario B: The customer has complex post-processing logic for the extraction results of the IDP model and cannot meet the business scenario through pre-set post-processing or Regular Expression. Therefore, it is decided to use RPA and other three-party methods for more complex post-processing.
- Solution: Obtain the extraction results of the IDP model through OpenAPI-query collaborative task results, complete post-processing through RPA and other three-party methods, and use OpenAPI-update collaborative task to batch refresh the final data to the corresponding fields.
- Scenario A: The customer needs to extract multiple pages of cargo transportation documentation, each page of which has information such as the “amount” “date” “quantity” of the goods, but the business department has more complex conversion logic in the face of these numbers in the documentation to calculate the degree of cargo transportation risk.
3. I hope to see the extraction results of structured styles in the The Hub
When extracting structured and semi-structured document/documents, the business demand to see the form style consistent with that of paper documents during manual proofreading, so as to improve user verification efficiency and use experience and reduce proofreading risk!
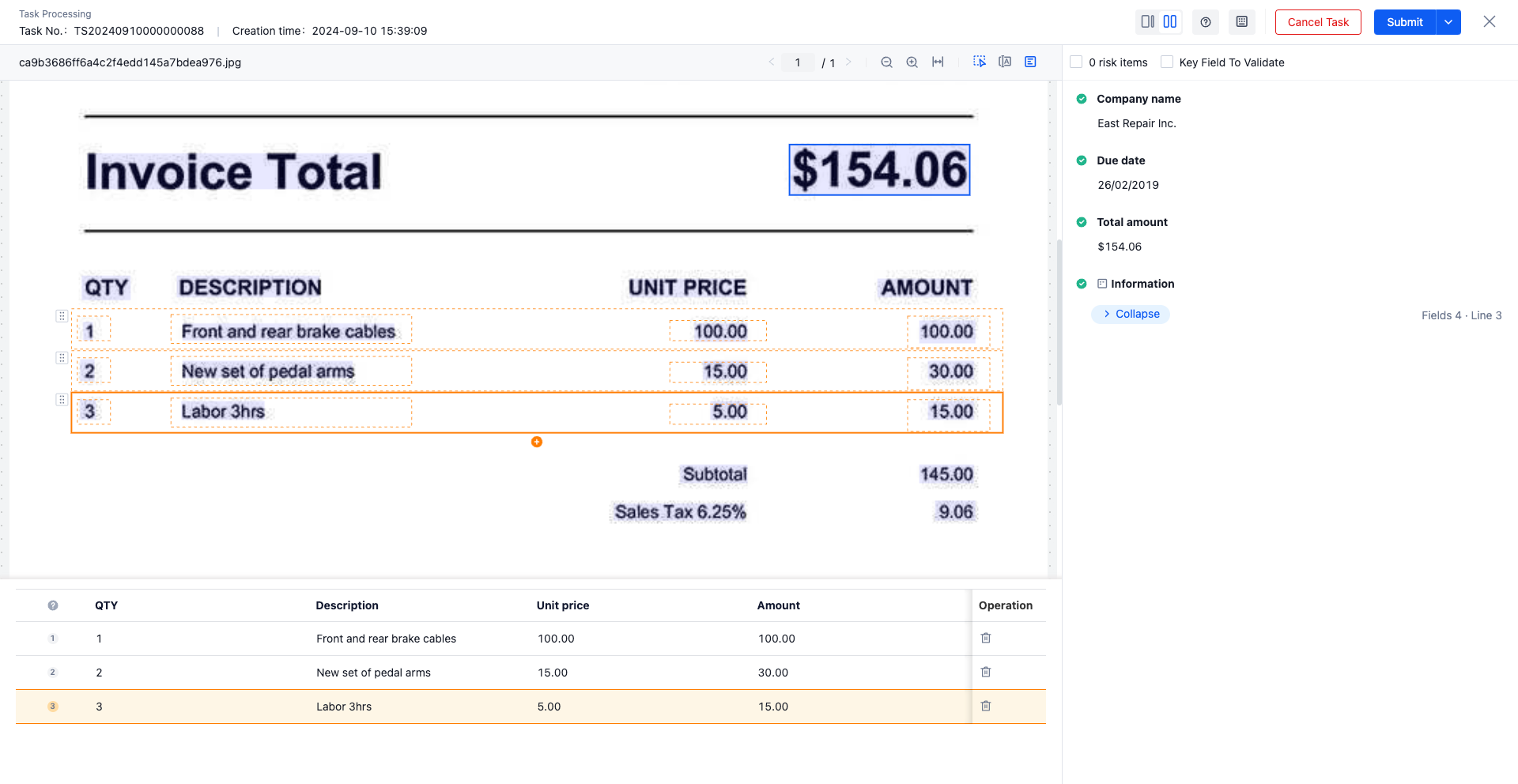
Instructions for use:
- Triggering conditions (three points of abc need to be achieved simultaneously):
- The training method of the model is Templete self training
- Training model with line_ extract fields or group fields(display the structured and row dimension of the line_ extract or group fields, The field name and value information covered in the field, and supports flexible editing operations
- Configure Collaboration Rules - Extract Fields When, check the box of line_ extract field
- Triggering conditions (three points of abc need to be achieved simultaneously):
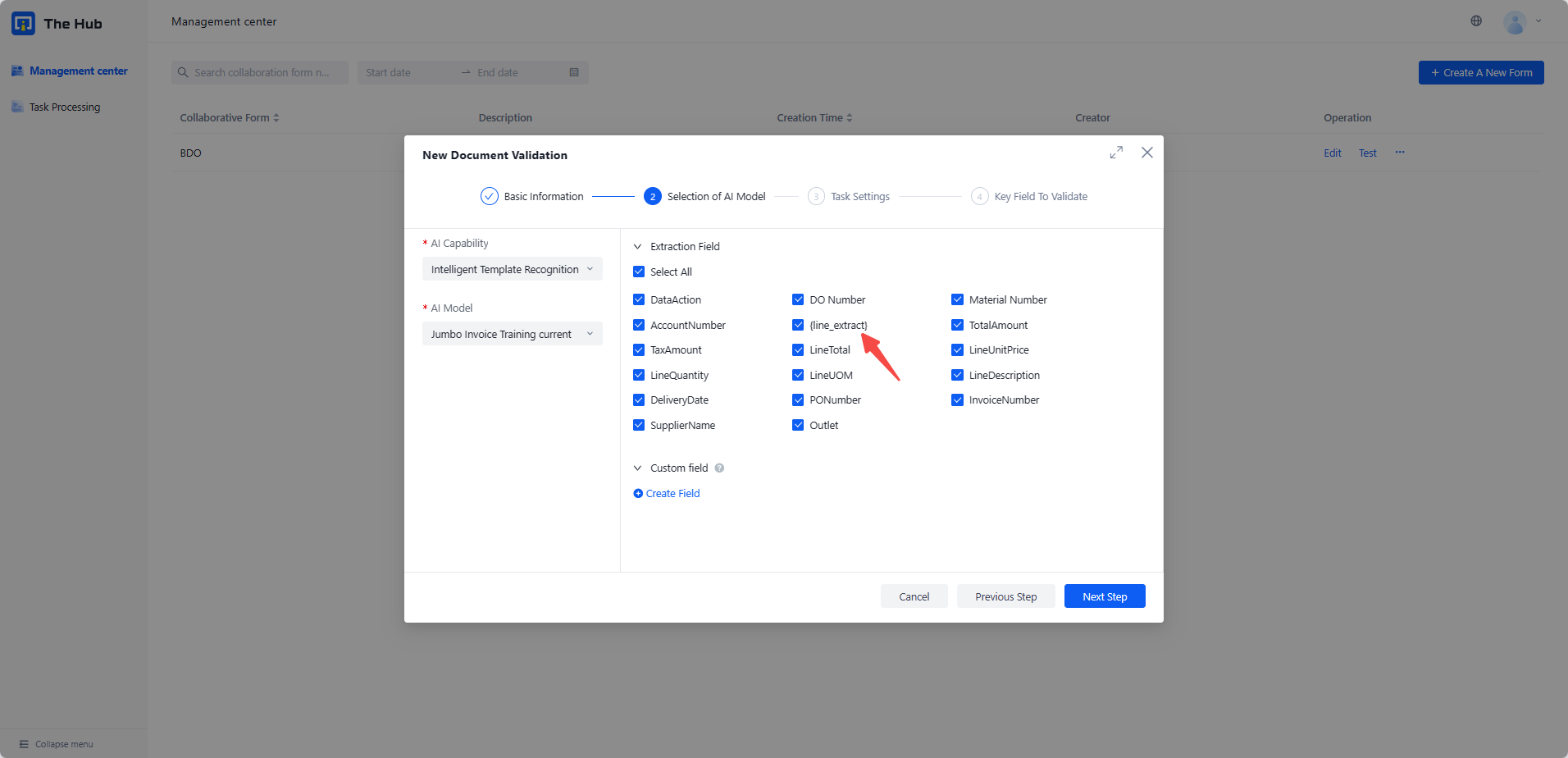
- Adapt to OpenAPI:
- Can be accessed through OpenAPI - Create Collaborative task Interface, create a task with structured display, trigger conditions\&trigger effects are consistent with the direct configuration of the function page
- Can be accessed through OpenAPI - Query collaborative task results Interface to obtain the location relationship of structured information from the submitted collaborative task results, so as to realize the free assembly of table information outside the platform
4. I hope to define intelligent fields that automatically extract data beyond the results of the IDP extraction model
Feature Description: Enhance the functions of the human-computer collaboration center using a large language model, filling in the gaps in business coverage for financial trade documents and self-trained extractions within IDP products. Upon user addition of field descriptions, content is automatically extracted, aiding users in rapidly deploying customized requirements. Support the creation of "intelligent fields," adding meaningful field names, as well as other optional supplementary information beyond the field name such as output format and business logic description, to achieve intelligent extraction based on the large language model.
Restriction Description :
- Number of Intelligent Fields limited in 10
- The first 100 pdf pages are captured for recognition and extraction when input a multi-page PDF file
- Restrict intelligent fields to 'string' type
Rule Configuration Page :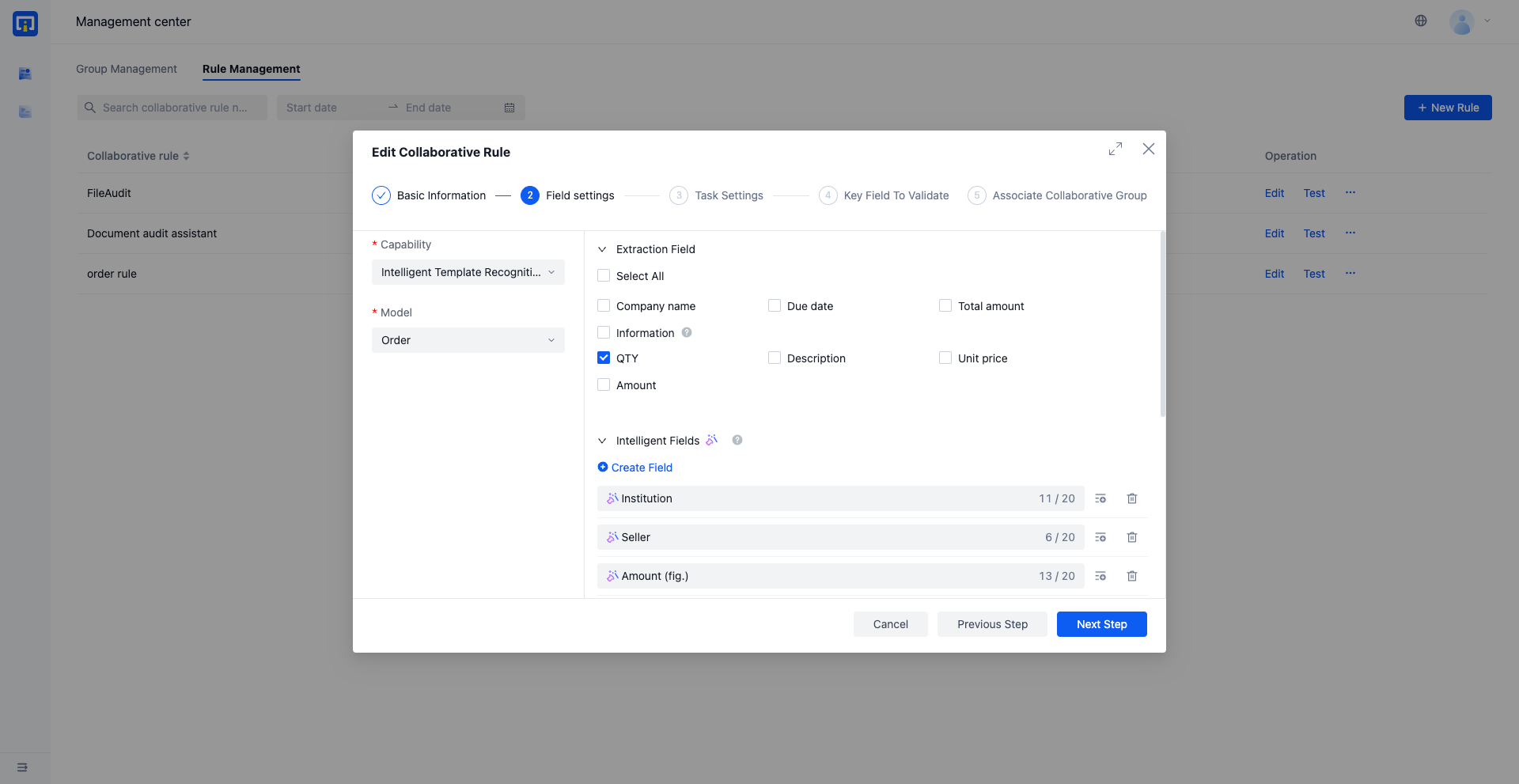
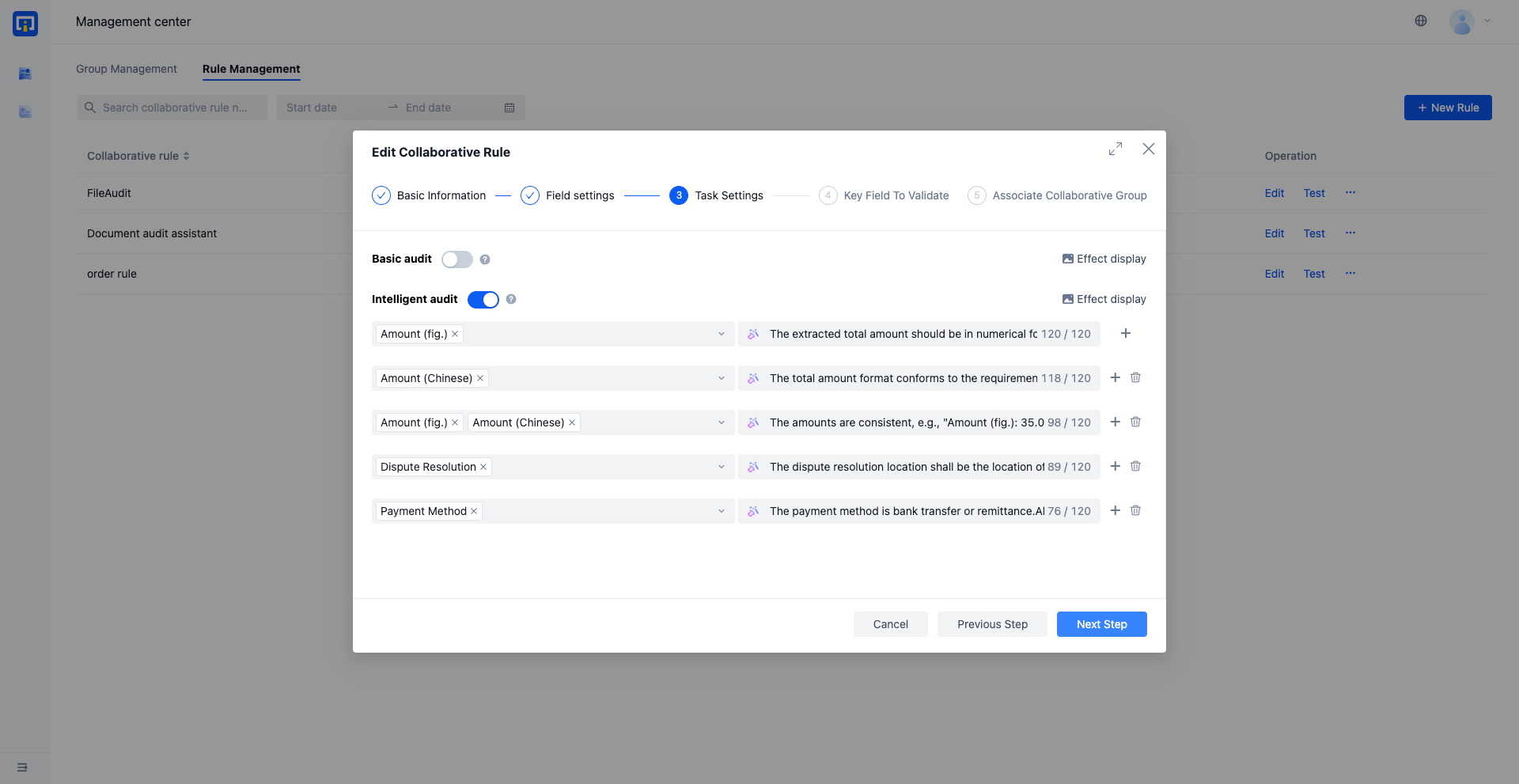
5. Wish to define audit conditions using natural language and receive intelligent audit suggestions
Intelligent audit assistant based on large language models, using natural language to set audit objectives and expectations for intelligent fields.
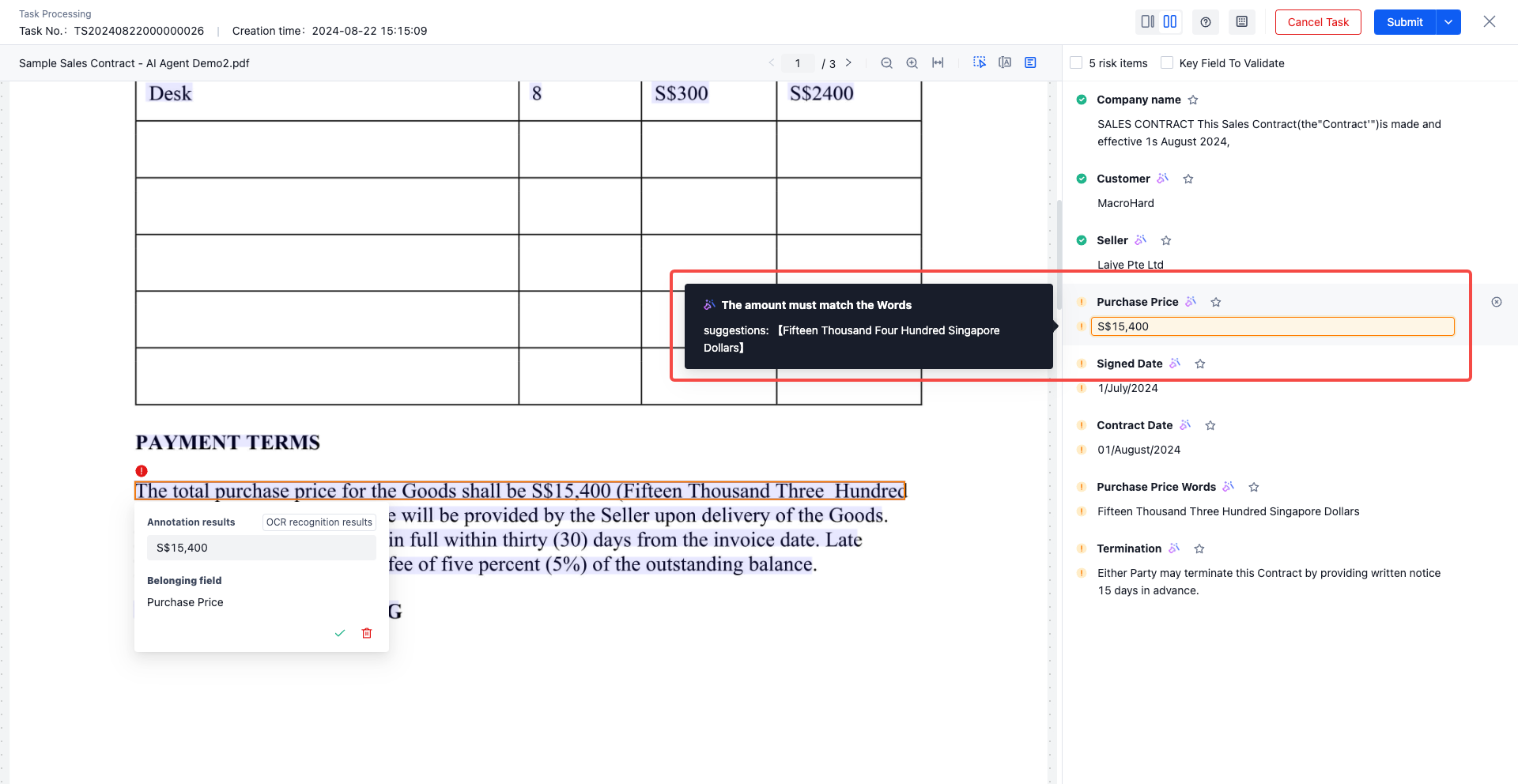
If the intelligent audit is not passed, the task processing page will provide more detailed modification suggestions.
When describing audit objectives, it is necessary to use clear, unambiguous, and specific expressions. If the output is not satisfactory, try illustrating it with examples. Below are examples of correct and incorrect descriptions:
- ✅ Correct Descriptions
- The extracted total amount in the contract must comply with the numeric uppercase format requirements, include the word "RMB," and end with "元整."
- The signing date cannot be later than the acceptance date.
- The signing date must be in the format: YYYY-MM-DD.
- The dispute resolution location must be the party A's location. - ❌ Incorrect Descriptions
- The extracted total amount in the contract must comply with the format requirements.
- Whether the signing date and acceptance date are reasonable.
- The signing date format must be reasonable.
- Whether the dispute resolution location is the party A's location.
- ✅ Correct Descriptions