Data availability
Mysql
info
As a toB company, Laiye Technology will build a three-node MGR single-master architecture for customers as the underlying storage when deploying privately for customers. If the master library fails, it can be automatically switched; if the slave library fails, it can be automatically offline.
The middle layer uses multi node proxysql for routing. Configure read / write separation and fault detection to ensure correct distribution of read / write traffic.
In Mgr, downtime of a MySQL instance does not affect normal business use;
In Mgr, when two MySQL instances are down, Paxos voting is not satisfied. It is only readable but not writable.
Proxysql can provide services normally as long as one node survives. (unless you can't bear the pressure!)
Mgr introduction
- Mgr introduction
The full name of Mgr is MySQL group replication, which is a new high availability and high Extension solution officially launched by MySQL in December 2016. Mgr provides MySQL Cluster Services with high availability, high Extension and high reliability. Before Mgr, the common MySQL high availability mode for users was master slave architecture no matter how the architecture was changed. MySQL 5.7 supports lossless semi synchronization, which further prompts the strong consistency of data replication.
MySQL group replication (Mgr) is a database high availability and high Extension solution officially introduced by MySQL in version 5.7.17. It is provided in the form of plug-ins. Based on the distributed Paxos protocol, Mgr implements group replication to ensure data consistency. The built-in fault detection and automatic primary selection functions can continue to work normally as long as most nodes in the cluster are not down. Single master mode and multi master mode are provided. Multi master mode supports multi-point writing.
- Mgr principle
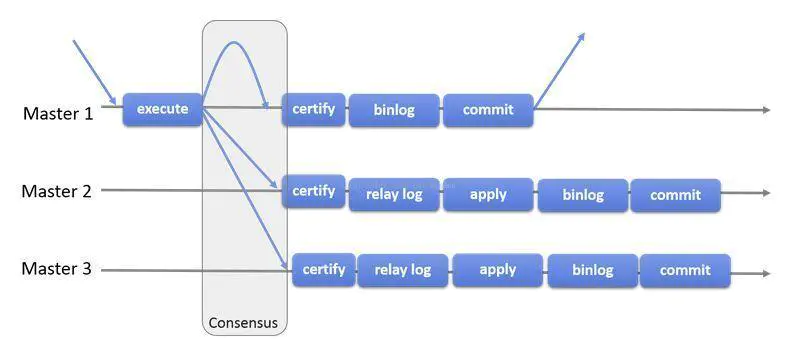
Group replication is a technology that can be used to implement fault-tolerant systems. A replication group is a server cluster that interacts with each other through messaging. The replication group consists of multiple server members, such as master1, master2 and master3 in the following figure. All members complete their own transactions independently.
When a client initiates an update transaction, the transaction is executed locally first. After the execution is completed, the transaction submission operation is initiated. Before committing, you need to broadcast the generated replication write set to other members. If the conflict detection is successful, the group decides that the transaction can be committed and other members can apply it. Otherwise, it rolls back.
Finally, all members of the group receive the same set of transactions in the same order. Therefore, the members in the group apply the same modifications in the same order to ensure strong data consistency in the group.
- Mgr features
High consistency. The group replication technology based on native replication and Paxos protocol is provided in the form of plug-ins to provide consistent data security;
High fault tolerance. As long as most nodes are not broken, they can continue to work. There is an automatic detection mechanism. When resource contention conflicts occur between different nodes, no errors will occur. They are handled according to the first come first principle, and an automatic brain crack protection mechanism is built in;
High Extension. The addition and removal of nodes are automatic. After a new node is added, it will automatically synchronize the status from other nodes until the new node is consistent with other nodes. If a node is removed, other nodes will automatically update the group information and automatically maintain the new group information;
High flexibility. There are single master mode and multi master mode,
single master model: A master node is automatically selected from multiple MySQL nodes in the replication group. Only the master node can write. Other nodes are automatically set to read only. When the master node fails, a new master node will be automatically elected. After the election is successful, it will be set to writable, and other slaves will point to the new master.multi-master model: Any node in the replication group can write. Therefore, there is no concept of master and slave. As long as the number of suddenly failed nodes is small, the multi master model can continue to be available.
Service availability
Mgr status can be checked on each node using the command, or visually checked through deployment monitoring
// {mysql_user}: mysql username
// {mysql_password}: mysql password
// {mysql_host}: mysql hostname
Input:
mysql -u{mysql_user} -p{mysql_password} -h{mysql_host} 'select * from performance_schema.replication_group_members;'
Output:
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| group_replication_applier | 20fe9019-da90-11ec-80e7-00163e014012 | 172.18.86.20 | 3306 | ONLINE |
| group_replication_applier | 2b38a74a-da90-11ec-a1bb-00163e0169aa | 172.18.86.21 | 3306 | ONLINE |
| group_replication_applier | 34d1d458-da90-11ec-b0a9-00163e013f6a | 172.18.86.22 | 3306 | ONLINE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
- normal : When the number of outputs in the above results is equal to the number of nodes, it means that the Mgr service is running normally and one machine is allowed to be down
- warning : When the output number of the above results is less than the number of nodes and more than one instance, it means that the Mgr is running normally, but no more downtime is allowed
- abnormal : When there is only one instance of the above result output, it indicates that the Mgr is running abnormally and the service is unavailable
Data backup
caution
After the deployment is completed, aScheduled Tasks。 Do not delete it unless necessary 。
The planned Task is similar to the following (the meaning of this Task is to automatically back up the database in full at 0:01 every day)
01 00 * * * sudo docker run --rm -v /home/rpa/mysql/mysql-backup:/mysql-backup ......
By default, the server will retain your data for the last 21 days. This means that if you have a large amount of data, this backup plan is completely unnecessary, and it will cause unnecessary waste to your disk. So you can change this plan according to your data volume 。
Find backup script
If you do not change the service deployment directory during deployment, your backup script will be saved in
/home/laiye/mysql/conf/backup.conf, Otherwise you need to/home/laiyeReplace with your actual deployment directoryChange configuration item
...
local_maintain=21
minio_maintain=21
...caution
You only need to modify
local_maintainandminio_maintainThe Parameter is the actual number of days. Save and exit
Data recovery
If one of the Mgr nodes in the multiple nodes is interrupted for a short time, then the service is restored. Execute SQL statements under the failed node to rejoin the Mgr cluster:
set global group_replication_allow_local_disjoint_gtids_join=on;
START GROUP_REPLICATION;
select * from performance_schema.replication_group_members;
If all Mgr nodes in the multi node are interrupted, then the service is restored. One node can be used as a write node, and the other node can be used as a read node to rebuild the cluster:
# master node
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
# slave node
set global group_replication_allow_local_disjoint_gtids_join=on;
START GROUP_REPLICATION;
select * from performance_schema.replication_group_members;
Redis
Redis introduction
Redis is completely open source and free. It complies with the BSD protocol. It is a flexible high-performance key value data structure storage, which can be used as a database, cache and message Queues. Compared with other key value cache products, redis has the following three characteristics: redis supports data persistence, and can save the data in memory in the disk. It can be loaded into memory again when restarting.
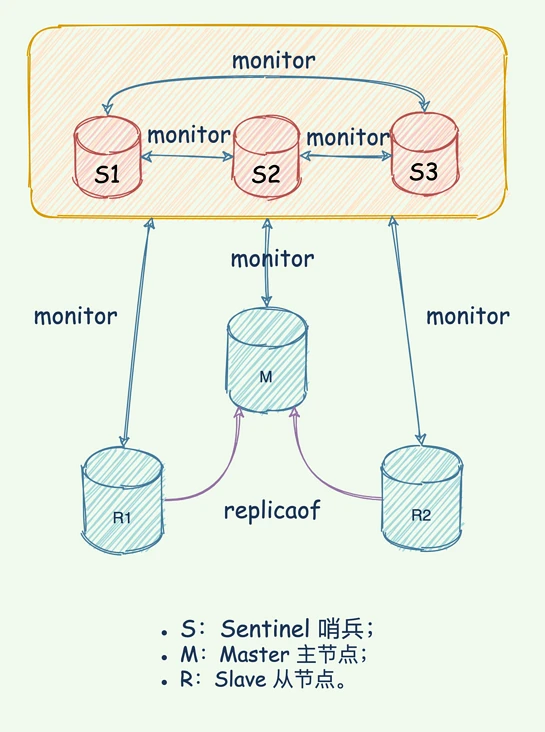
As a tob company, laiye technology will build a three node sentinel cluster high availability architecture for customers as the underlying storage if the customers do not provide redis high availability environment during private deployment. If the main warehouse fails, it can be switched automatically; If the slave library fails, it can be automatically offline.
Sentry is an operation mode of redis, which focuses on Monitoring the running status of redis instances (master and slave nodes) , And be able to When the master node fails, a series of mechanisms are used to realize master selection and master-slave switching to achieve failover and ensure the availability of the entire redis system
Service availability
You can use the command to check the redis status on each node, or visually check the redis status through deployment monitoring
// {redis_password}: redis password
// {redis_host}: redis hostname
Input:
redis-cli -a {redis_password} -h {redis_host} info replication
Output:
# Replication
role:master
connected_slaves:2
slave0:ip=172.18.86.21,port=6379,state=online,offset=373561574,lag=1
slave1:ip=172.18.86.22,port=6379,state=online,offset=373561574,lag=0
master_replid:ef5dd92edc2ea1e6579b546372d7d667c77ad6c5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:373562258
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:372513683
repl_backlog_histlen:1048576
- normal : When connected_ When slaves=2, it means that the redis cluster is running normally and one is allowed to be down
- warning : When connected_ When slaves=1, the redis cluster is running normally, but no more downtime is allowed
- abnormal : When connected_ When slaves=0, the redis cluster runs abnormally and the service is unavailable
Data backup
We all know that redis has good read and write performance. However, as it is a memory database, if it is not backed up in advance, redis data will be lost immediately after power failure.
Fortunately, redis provides two methods for persistence: 1. RDB persistence 2. AOF persistence. To ensure your data security, this product adopts two backup modes.
RDB The persistence mode is: 1000 keys are automatically backed up every 1, 5, and 15 minutes.
AOF The backup mode is: Appendfsync everysec saves once per second
RDB persistent backup
info
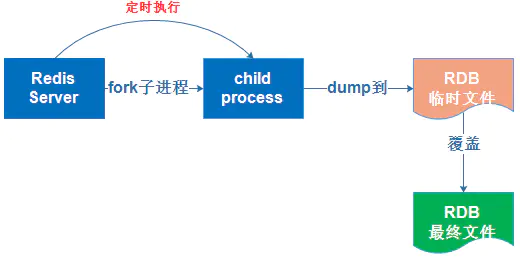
Regularly dump redis' data in memory to the disk. The actual operation process is fork A subprocess that writes data to a temporary file first. After successful writing, it replaces the previous file and uses binary compression storage
- Automatically turn on RDB persistence
Modify redis.conf configuration file
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir ./bak
- Enable RDB persistence manually
# Need to link redis operations
127.0.0.1:6379> save
OK
127.0.0.1:6379> bgsave
Background saving started
# The difference between the SAVE and BGSAVE commands is that the SAVE command blocks the main process. After the save operation is completed, the main process starts to work and the client can connect; the BGSAVE command is to fork a special save sub-process, and this operation will not affect the main process.
# Note: SAVE only backs up the current database, the backup file name is dump.rdb by default, and the backup file name dbfilename xxx.rdb can be modified through the configuration file (a problem is found: if you want to back up multiple databases, you can only back up in the end The last database, since the dump.rdb files overwrite each other)
Aof persistent backup
info
The redis operation log is written to a file in the form of file appending. Only write and delete operations are recorded, and query operations are not recorded (similar to MySQL's binlog log)

Redis is a dictionary storage server. A redis instance provides multiple containers for storing data. The client can specify which container to store the data in (similar to the database in MySQL)
Redis supports 16 databases by default, which can be accessed through redis.conf The number of databases modified in the configuration file is 0 by default after the client establishes a connection with redis
open
AOFfunctionappendonly yes
appendfilename appendonly.aofSet save mode
Aof has three ways to save operation commands into AOF files
1. appendfsync no do not save
Execute only
WHRITEOperation,SAVEOperation will be skipped, and only in Redis is closed 、 Aof function is turned off 、 The write cache of the system is flushed (for example, the cache is full),SAVEThe operation will be executed, but these three conditions will cause the redis main process to block2. appendfsync everysec is saved every second
In this mode,
SAVEIn principle, it will be executed every second. The specific execution cycle is related to the status of redis when the file is written and saved. In this modeSAVEThe operation is called by the background sub thread and will not cause blocking of the server main process3. appendfsync always save every time you execute a command
In this mode, each time a command is executed,
WRITEandSAVEWill be executed, andSAVEOperation will block the main processmode Write block Save block Amount of data lost during downtime Appendfsync no block block Data after the last time the operating system triggers the save operation on the AOF file Appendfsync everysec block Non blocking Generally, data within 2 seconds Appendfsync always block block At most one command's data is lost
After setting the AOF write mode, as long as the write conditions are met (for example, one second, execute a command), the AOF file will be automatically generated in the specified path and the operation commands will be recorded in it
Data recovery
Since we are attaching the host directory to the redis container, the two recovery methods are the same. Place the backed up RDB or AOF files in the specified directory and restart redis to recover the data
tip
When there are both RDB files and AOF files in the specified directory, the priority of AOF files is higher than that of RDB files when restoring data, so AOF files are preferred to restore data
Rabbitmq
Rabbitmq introduction
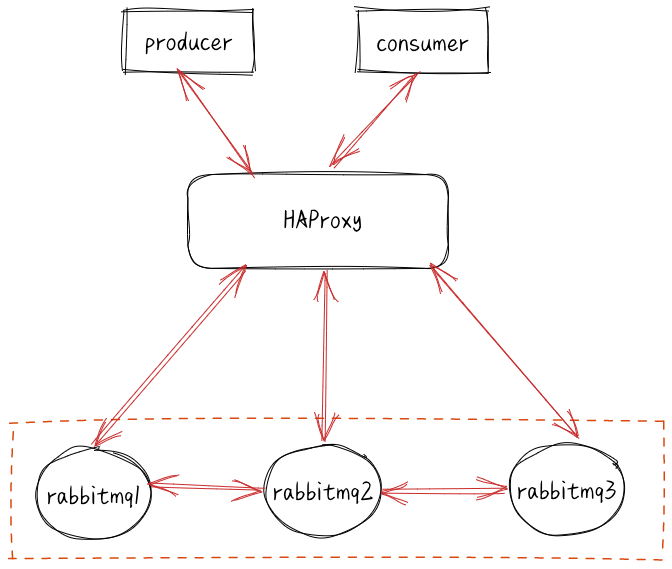
Rabbitmq, a message queue Queues middleware product, is written based on Erlang. Erlang language is inherently distributed (it is realized by synchronizing magic cookies of each node of the Erlang cluster). Therefore, rabbitmq naturally supports clustering. This makes it unnecessary for rabbitmq to implement the HA scheme and save the metadata of the cluster through zookeeper like ActiveMQ and Kafka. Cluster is a way to ensure reliability. At the same time, it can increase message throughput through horizontal Extension
Cluster mode
The very classic mirror image mode ensures 100% data loss. It is also used most in practical work, and the implementation is very simple. Generally, large Internet manufacturers will build this image cluster mode.
Make the required Queues Mirror Queues , There is an HA scheme that belongs to rabbitmq with multiple nodes. This mode solves the problems in the Normal Mode. Its essence is different from the Normal Mode in that the message entity will actively synchronize between the mirror nodes, rather than temporarily pull data when the client fetches data. The side effects of this mode are also obvious. In addition to reducing the system performance, if there are too many image Queues and a large number of messages enter, the network bandwidth within the cluster will be greatly consumed by this synchronous communication. Therefore, it is applicable in the occasions with high reliability requirements.
The mirror Queues is basically a special backingqueue, which is internally wrapped with a common backingqueue for local message persistence. On this basis, the function of copying messages and acks to all mirrors is added. All pairs of mirrors_ queue_ The master operation will be synchronized to each slave node through multicast GM (described below). GM is responsible for broadcasting messages, mirror_ queue_ The slave is responsible for callback processing, while the coordinator is responsible for callback processing on the master. Mirror_ queue_ The slave contains a common backingqueue for message storage, and the master node contains a backingqueue in the mirror_ queue_ It is called by amqqueue in the master.
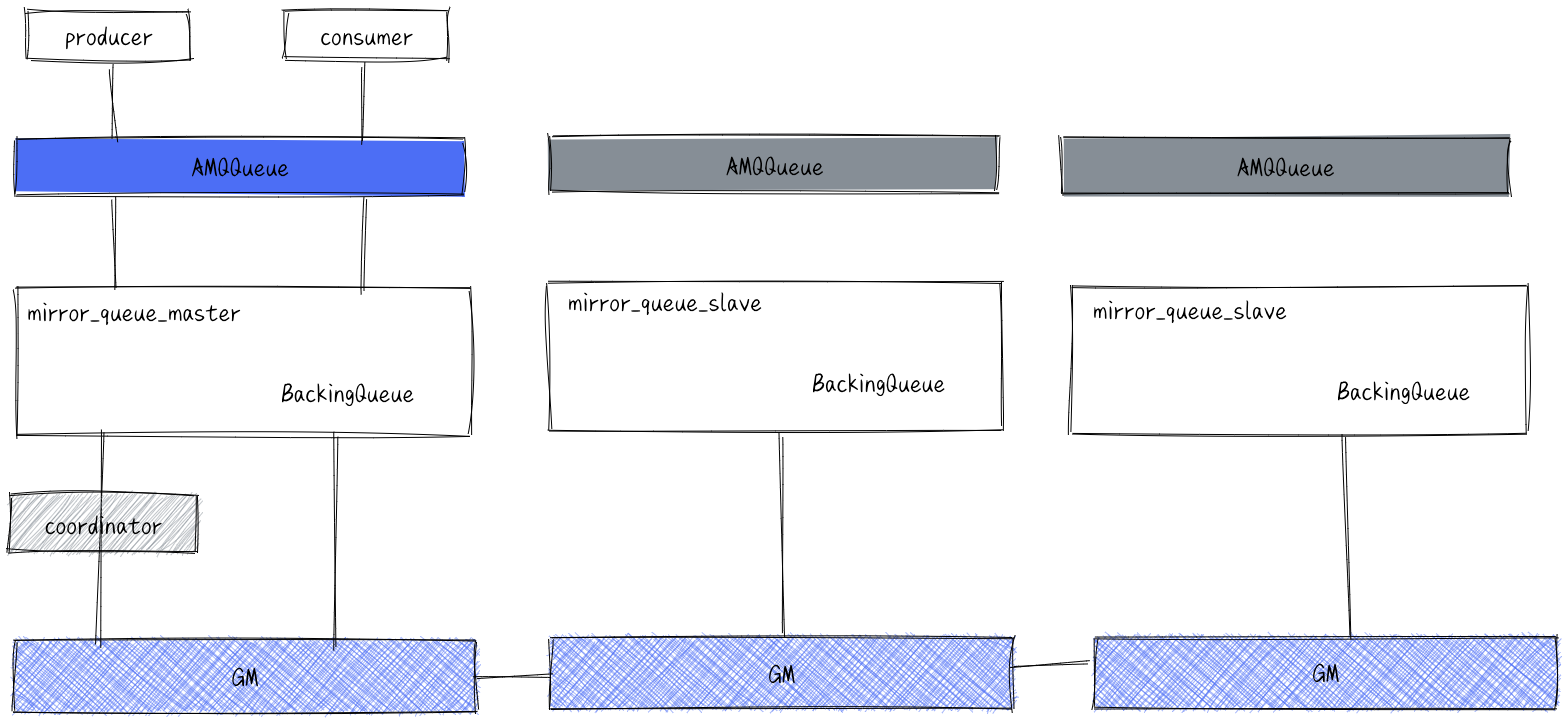
Service availability
The rabbitmq status can be checked on each node using the command, or visually checked by deployment monitoring
Input:
docker exec -it rabbitmq rabbitmqctl cluster_status|grep "Running Nodes" -A5
Output:
Running Nodes
rabbit@saas-rabbitmq-01
rabbit@saas-rabbitmq-02
rabbit@saas-rabbitmq-03
- normal : When running nodes = 3, it means that the rabbitmq cluster is running normally, and one is allowed to be down
- warning : When running nodes = 2, it means that the rabbitmq cluster is running normally, but no more downtime is allowed
- abnormal : When running nodes = 1, the rabbitmq cluster is running abnormally and the service is unavailable
Data backup
Rabbitmq only needs to back up {/home/laiye}/rabbitmq/docker-compose Yaml file and {/home/laiye}/rabbitmq/config directory
remind : {/home/laiye} needs to be replaced with the actual deployment directory
Data recovery
Copy the backed up files to the new directory, and use docker compose up -d to start
Minio
Minio introduction
Minio is a high-performance object store released under the GNU affino general public license v3.0. It is an API compatible with Amazon S3 cloud storage services. Use Minio to build a high-performance infrastructure for machine learning, analytics, and Applications data workloads.
248 / 5000 translation results this readme file provides quick start instructions for running Minio on bare metal hardware, including container based installation.
data protection
Distributed Minio uses erasure codes to prevent multiple node downtime and bit attenuation. Distributed Minio requires at least 4 nodes (4 servers), and the function of erasure code is automatically introduced by using distributed Minio. Erasure code is a mathematical algorithm for recovering lost and damaged data. Minio uses Reed Solomon code to split objects into n/2 data and n/2 parity blocks. This means that if there are 12 disks, an object will be divided into 6 data blocks and 6 parity blocks. You can lose any 6 disks (whether they are stored data blocks or parity blocks), and you can still recover from the data in the remaining disks. The working principle of erasure correction code is different from that of raid or replication. For example, raid6 can not lose data when two disks are lost, while Minio erasure code can still ensure data security when half of the disks are lost. Moreover, the Minio erasure code is used at the object level to restore one object at a time, while raid is used at the volume level, and the data recovery time is very long. Minio encodes each object separately. Once the storage service is deployed, it usually does not need to replace or repair the hard disk. The design goal of Minio erasure code is to improve performance and use hardware acceleration as much as possible. Bit attenuation, also known as data rot and silent data corruption, is a serious data loss problem of hard disk data at present. The data on the hard disk may be damaged unconsciously, and there is no error log. As the saying goes, it is easy to hide a gun when it is open, and it is difficult to defend against an arrow when it is hidden. This kind of secret mistake is more dangerous than the direct failure of the hard disk. Therefore, the Minio erasure correction code uses a high-speed highwayhash based checksum to prevent bit attenuation.
High availability
There is a single point of failure in the single Minio service. On the contrary, if it is an n-node distributed Minio, as long as n/2 nodes are online, your data is safe. However, you need at least n/2+1 nodes to create new objects. For example, in an 8-node Minio cluster, each node has a disk. Even if four nodes are down, the cluster is still readable, but you need five nodes to write data.
limit
The distributed Minio single tenant has a limit of at least 4 disks and at most 16 disks (limited by erasure codes). This restriction ensures Minio's simplicity while still having scalability. If you need to build a multi tenant environment, you can easily use kubernetes to manage multiple Minio instances. Note that you can combine different nodes and several disks per node as long as you comply with the limitations of distributed Minio. For example, you can use 2 nodes with 4 disks per node, or 4 nodes with 2 disks per node, and so on.
uniformity
In the distributed and stand-alone modes, all read and write operations of Minio strictly follow the read-after-write consistency model.
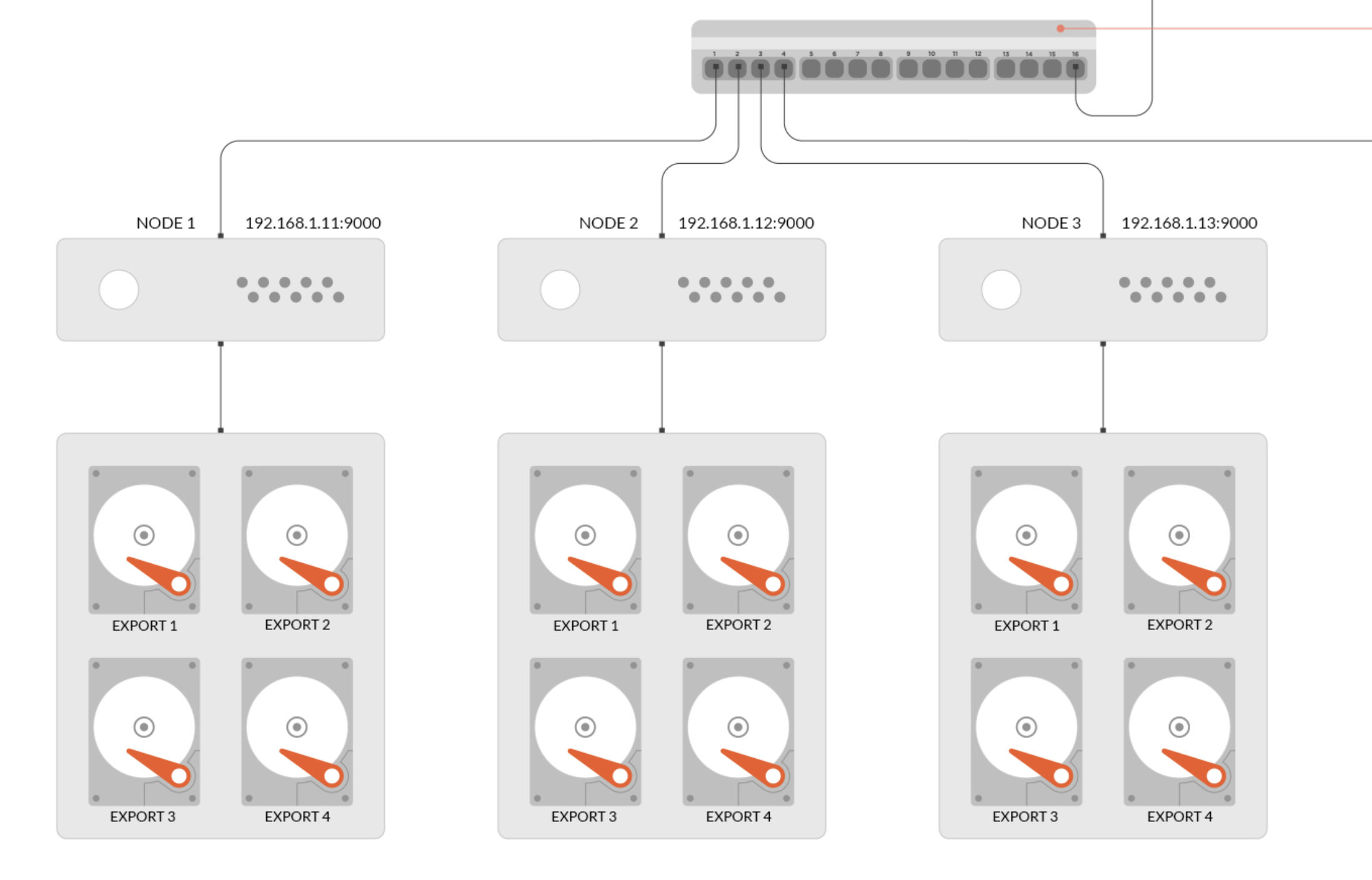
Service availability
- normal : When the number of Minio instances = the number of nodes, it means that the Minio cluster is running normally and one is allowed to be down
- warning : When the number of Minio instances is less than the number of nodes and greater than 1, the Minio cluster is running normally, but no more downtime is allowed
- abnormal : When the number of Minio instances is less than 1, the Minio cluster runs abnormally and the service is unavailable
Data backup
Minio only needs to back up {/home/laiye}/minio/docker-compose Yaml file and {/home/laiye}/minio/data directory
remind : {/home/laiye} needs to be replaced with the actual deployment directory
Data recovery
If only one node is down, you only need to back up {/home/laiye}/mini/docker-compose Yaml file recreates a Minio container, and Minio will automatically synchronize the data in the cluster
If all All nodes are down, copy the backup file to the new directory and execute docker compose up -d
Harbor
Harbor introduction
Harbor is an enterprise level registry service used to store docker images.
Registry is an official private warehouse image of dcoker. You can property the local image and then push it to the private warehouse of the container starting from registry. Enterprises can use dokcerfile to generate their own images according to their own needs and push them to private warehouses, which can greatly improve the efficiency of pulling images
In short, harbor is a docker image repository, and all our container images will be stored in this service
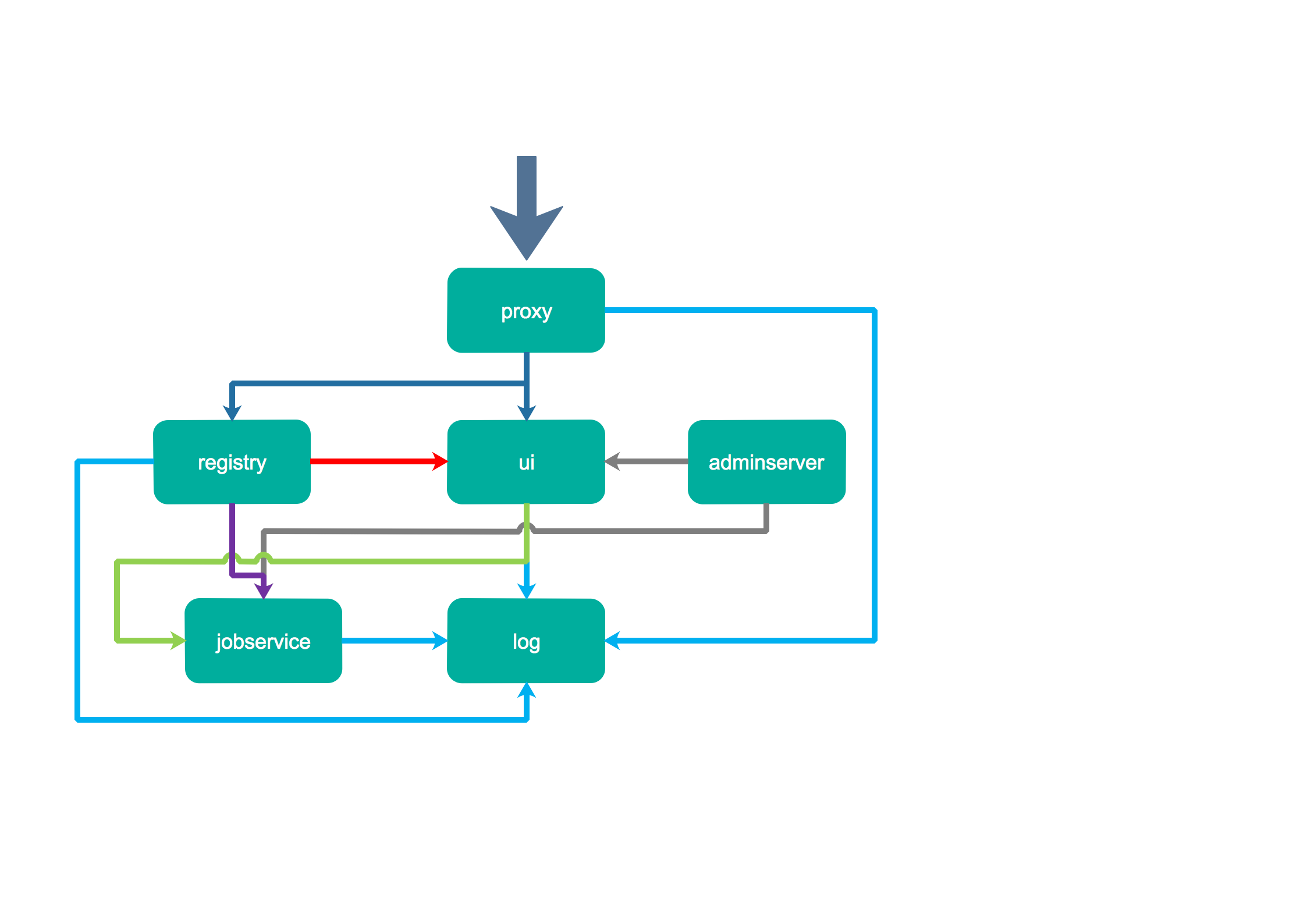
1. Proxy:
The registry, UI, token and other services of harbor uniformly receive the requests from the browser and docker clients through a front-end reverse proxy, and forward the requests to different back-end services.
2. Registry:
Store docker images and handle docker push/pull commands. Because we need to control users' access, that is, different users have different read and write permissions to docker images, registry will point to a token service, forcing users to carry a legal token with each docker pull/push request, and registry will decrypt and verify the token through the public key.
3. Core services:
This is the core function of harbor. It mainly provides the following services:
1) UI: provides a graphical interface to help users manage images on the registry and authorize users.
2) Webhook: to get the status changes of the image on the registry in time, configure webhook on the registry to pass the status changes to the UI module.
3) Token service: responsible for issuing tokens to each docker push/pull command according to user permissions The request from the docker client to the registry ø try service, if it does not contain a token, will be redirected here. After obtaining the token, the request will be made to the registry again.
4) Database:
It provides database services for core services, and is responsible for storing user permissions, audit logs, docker image grouping information and other data.
5) Log collector:
To help monitor harbor operation, collect logs of other components for future analysis.
Service availability
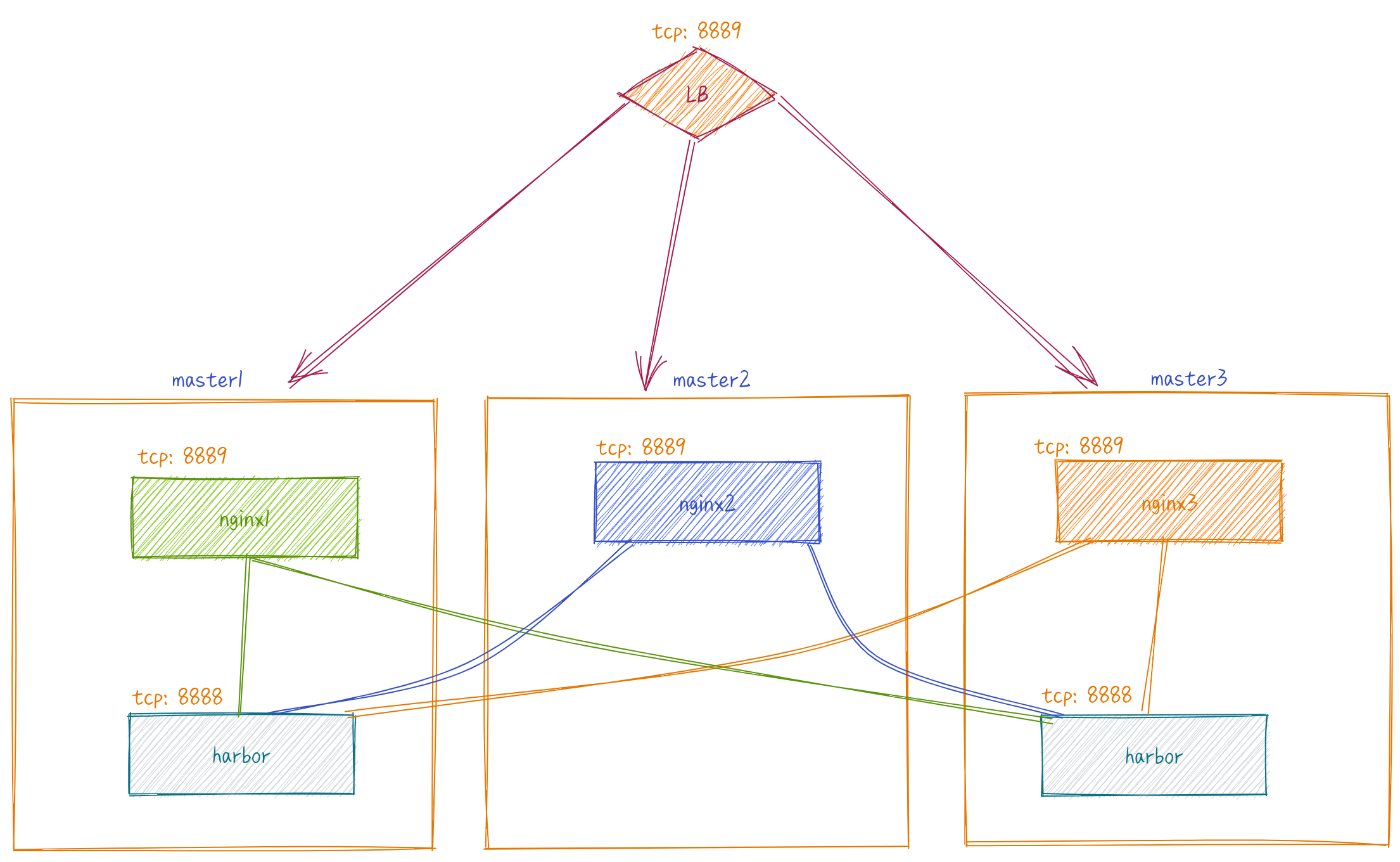
Since harbor is used in low frequency, it is only installed in master1 and master3. Only one harbor instance is allowed to be down
Data backup
Harbor only needs to back up the {/home/laiye}/harbor directory
remind : {/home/laiye} needs to be replaced with the actual deployment directory
Data recovery
If all All nodes are down, copy the backup file to the new directory and execute docker compose up -d