Intelligent Template Recognition
Introduction
Intelligent Template Recognition, also known as the Self-training Platform provided by Laiye, is suitable for dealing with structured or semi-structured documents, such as delivery notes, non-standardized bills, etc. Creating a one-page extraction model can:
- Annotating a small amount of data, the system can train a usable model
- Adding bad data to retraining will significantly improve the performance of the same type of data
Business scenario description
Universal bill recognition and universal card recognition can deal with semi-structured data in fixed formats, which are defined as national standards in various policy documents. Bill and card recognition can process these data well and complete the tasks of OCR recognition and field extraction.
The national standard of format is for unified management, in the production and operation of enterprises/public institutions in the process of social services, there will be similar management needs, will form a variety of templates with business characteristics in enterprises and public institutions.
The custom template function can extract data from these templates by configuring rules. However, when there are multiple types of data and complex structures, it will increase the time and difficulty of implementing personnel configuration templates, and rules-based on keywords and relative positions cannot meet some real project requirements. Both custom templates and Intelligent Template Recognition are suitable for processing fixed-format, structured or semi-structured documents, but custom templates are based on keyword and relative position extraction rules, while Intelligent Template Recognition are based on small samples for machine learning.
Characteristics
Intelligent Template Recognition has the following characteristics:
- Easy to use : provide data management -> annotation -> training -> evaluation -> publish -> optimize workflow guidance, hand in hand to teach you how to build a model for the production environment.
- Model lightweight : Take OCR recognition results as input, make full use of visual and semantic information modeling, and complete document information extraction task at low cost (fewer annotation data, less resource occupation).
Instruction
The following uses the English invoice as an example to create an invoice extraction model.
- click here Download the test data and follow the instructions to give it a try!
Create model
1) After logging in to the platform, click Document Understand in the left navigation bar to enter Intelligent Template Recognition.
2) Click New model to create a Invoice Extraction model.
- OCR engine: Because the input of the model is non-pure text information such as images and PDF, OCR recognition is required; The effect of OCR will affect the effect of subsequent extraction. Please evaluate the identification effect of OCR before selecting
- Language: because different languages need different preprocessing, such as Chinese need to cut characters, English need to cut words; Please select the language of the model according to the main language on the template.
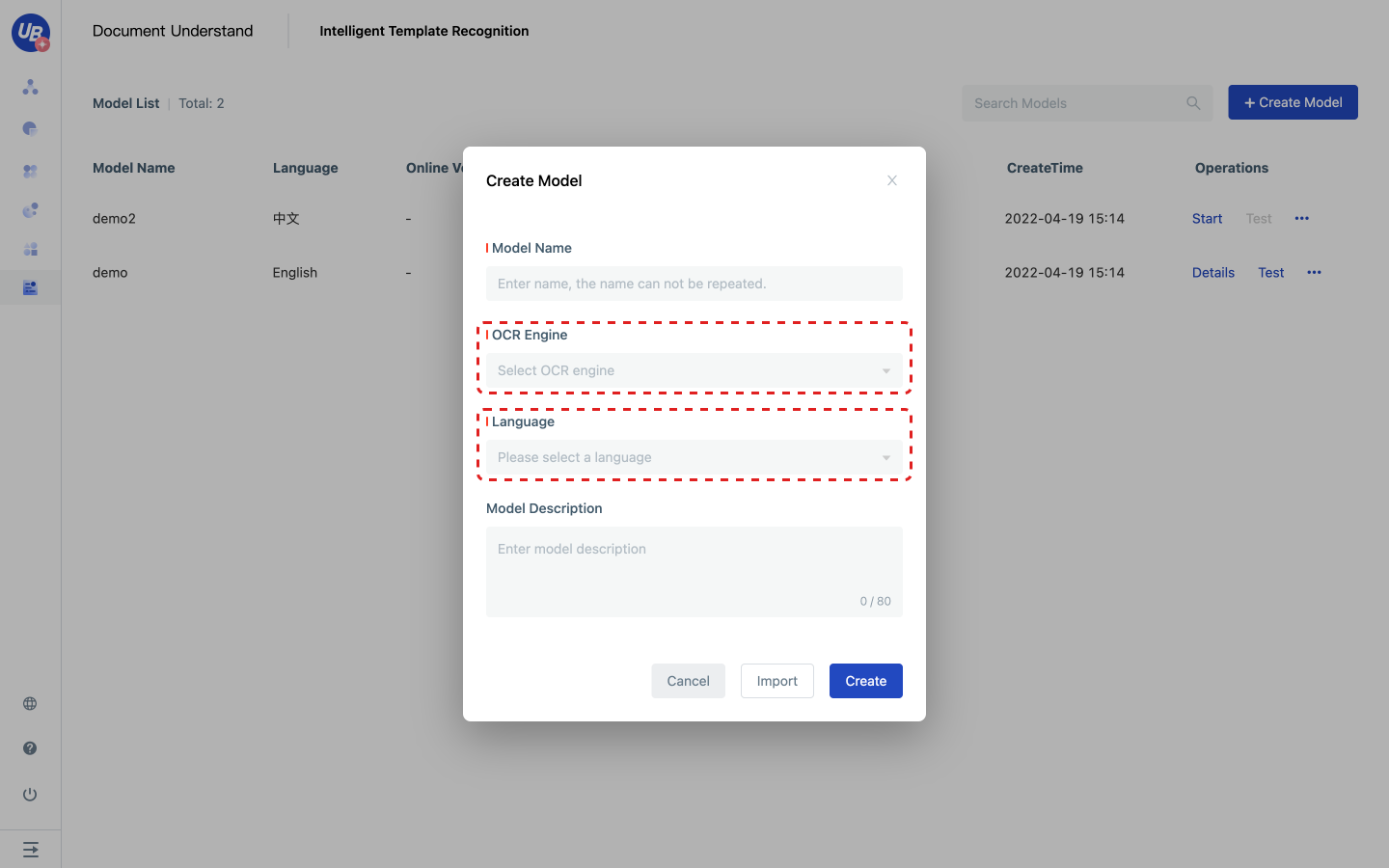
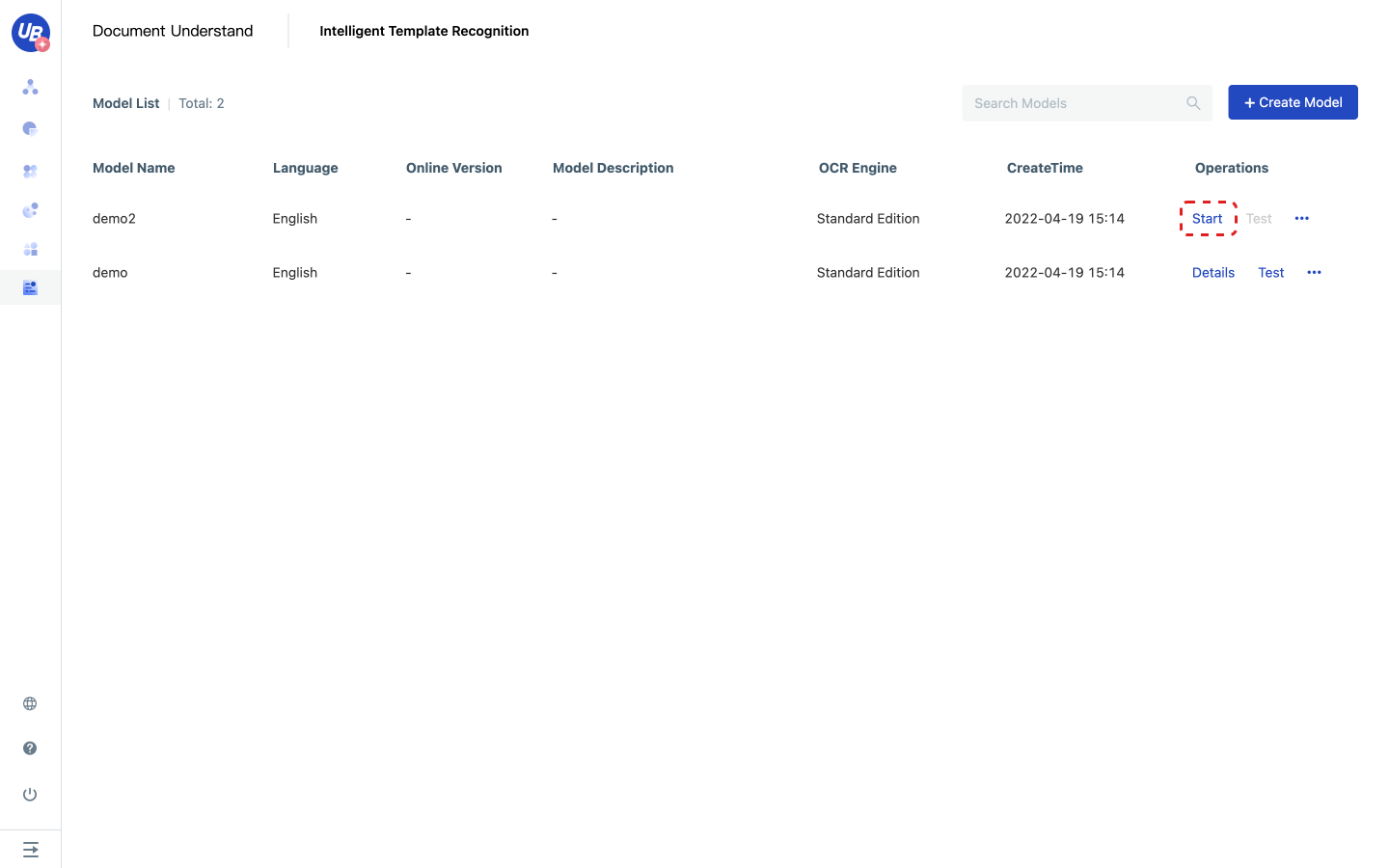
1) Click Start or Details to enter the model configuration
4) After entering the model configuration, you will see that Work Progress boot has been opened in the upper right corner. Please complete the following steps according to the work progress.
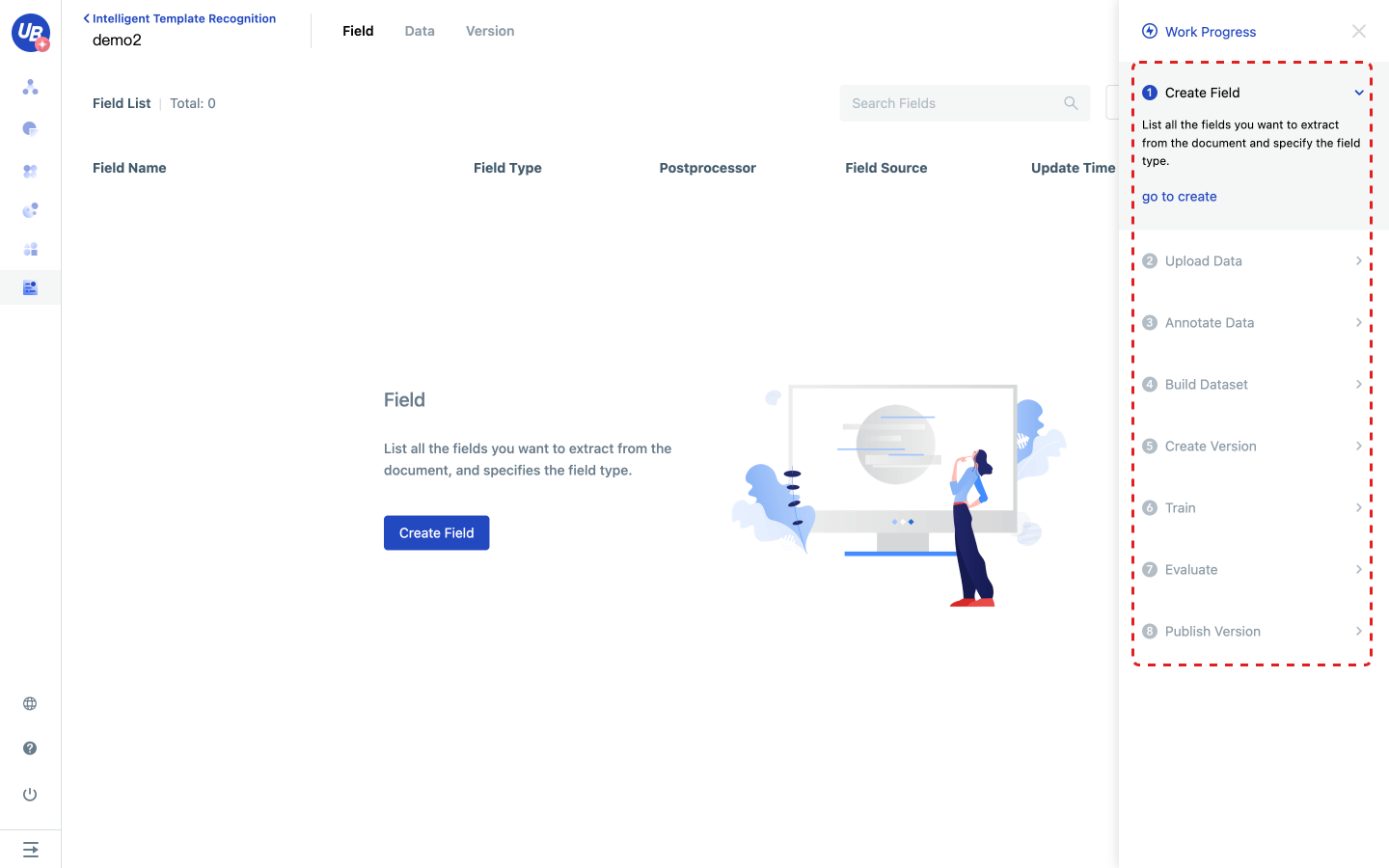
Create a new field
1) Click step 1 in the work progress to create a new field, click go to create, enter the field page.
2) Analyze what you want the model to extract from the file and create fields as required.
- The field name contains a maximum of 100 characters
- The field type can be string, array, or array type if the content will appear in multiple places in the document
- For more details about the rules for field post-processing, see in FAQ
Notes:
If you change the field type Array to String, some annotation data may be lost

Upload data
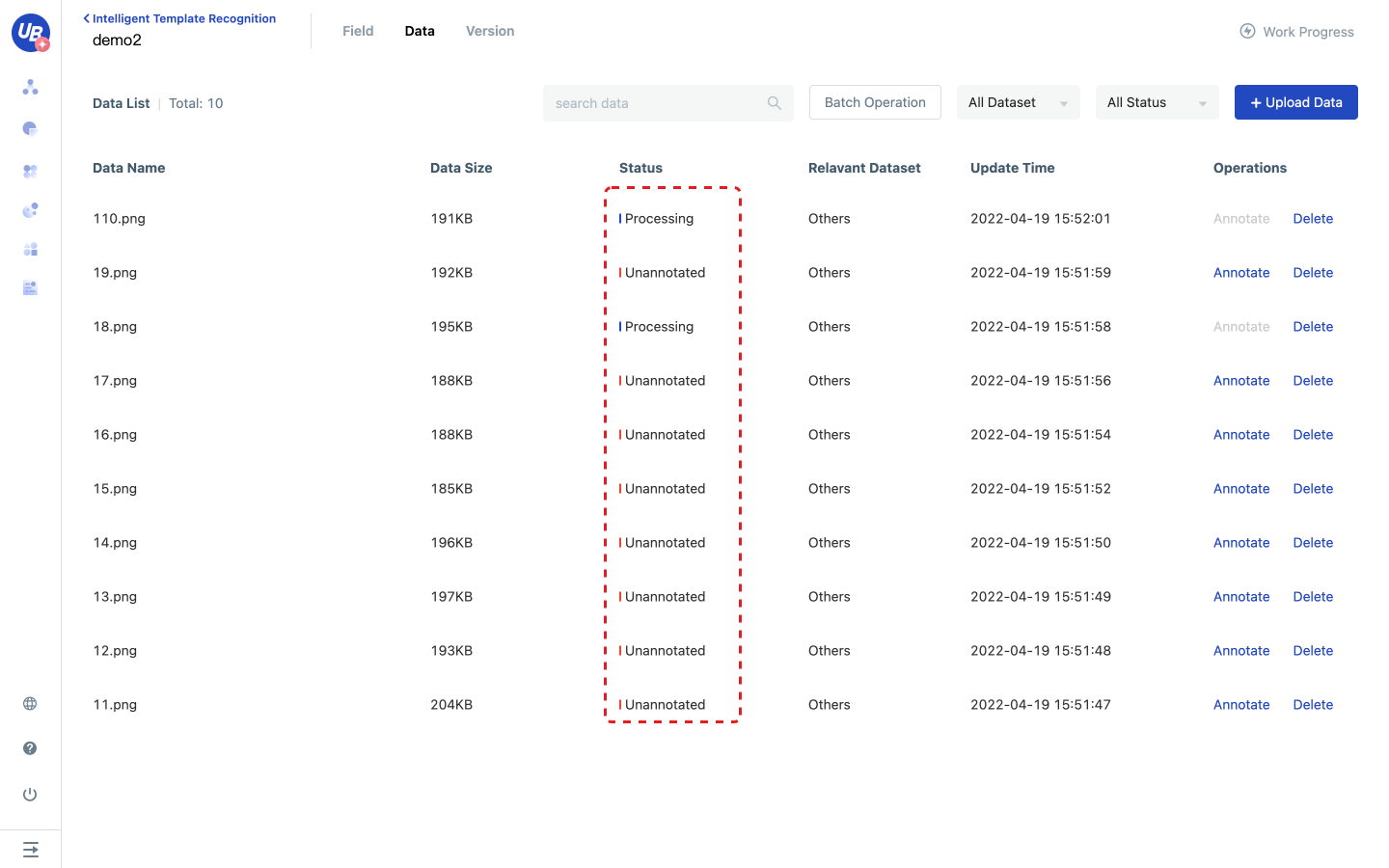
1) Click step 2 in the work progress to upload data, and click go to upload to enter the data page.
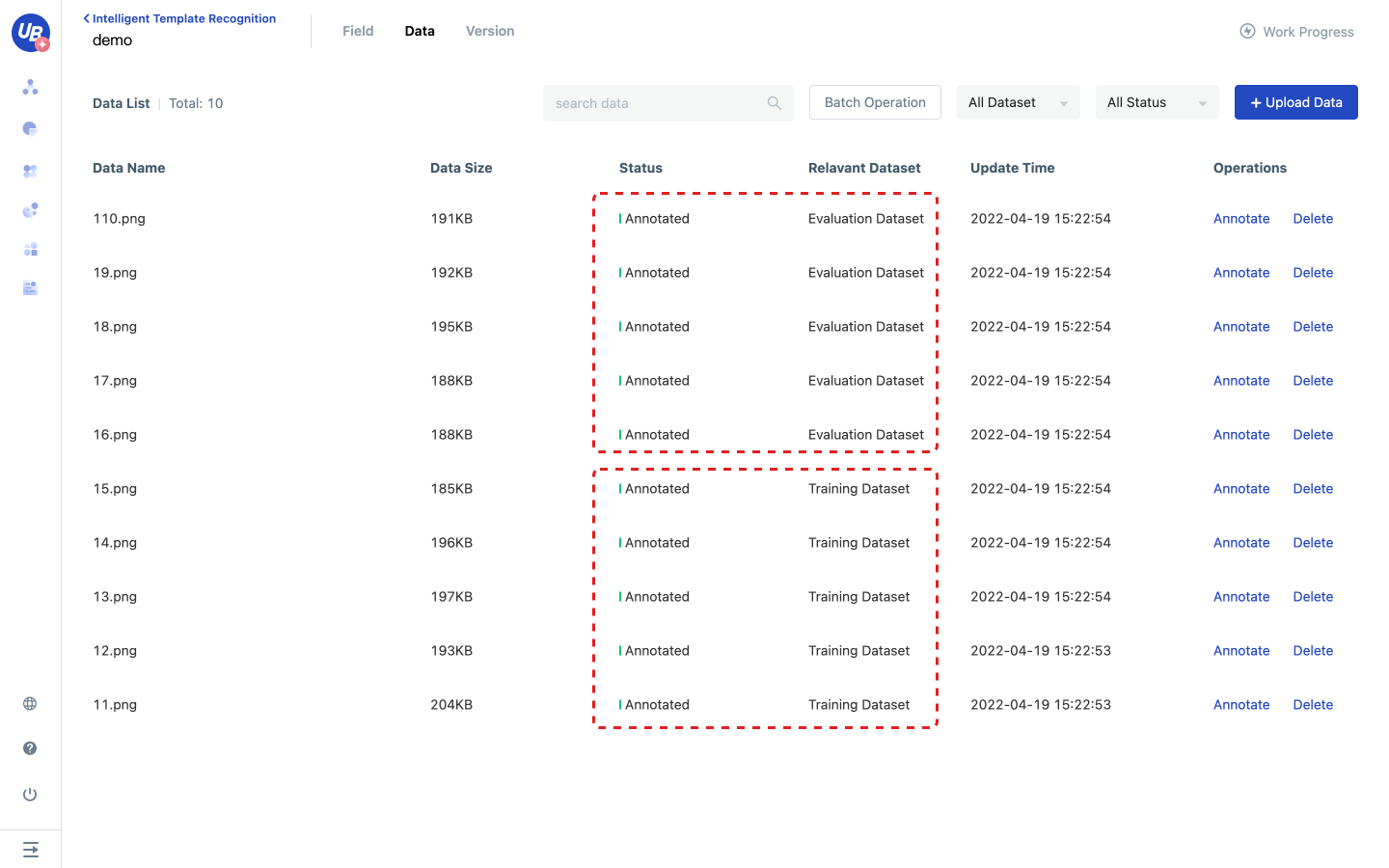
2) Upload relevant business data to data management.
- Data in data management can be used for model training and evaluation
- Data will be automatically identified by OCR after being uploaded. Data can be labeled only after being identified
Annotate the data and build the dataset
1) Click step 3 in the work progress to annotate data, and click go to annotate to enter the data page.
2) Click the Annotate of any data to enter the annotation page.
- If the model has a published version, the data will be extracted using the published version after uploading to provide pre-annotation for users
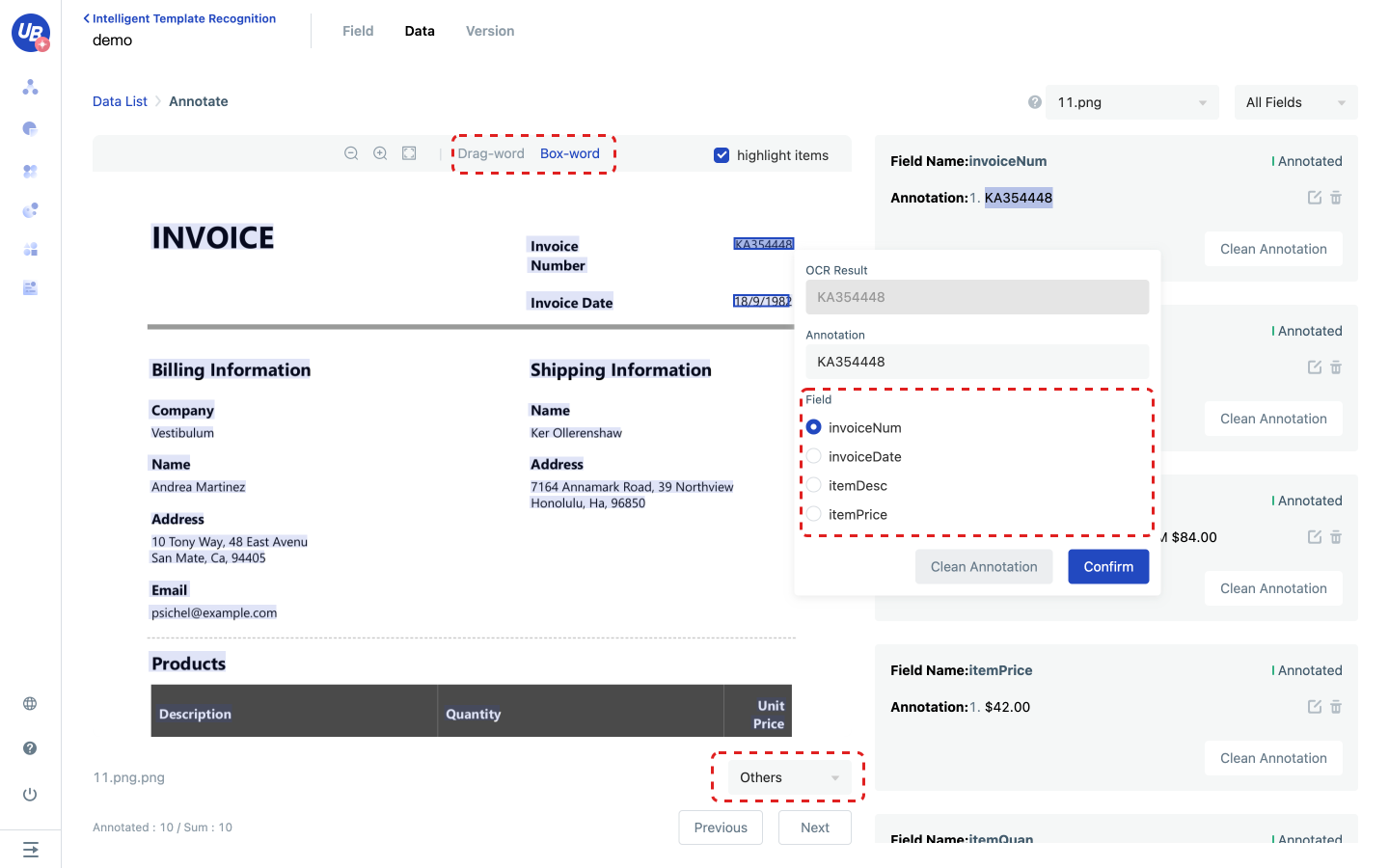
3) The annotation page provides two annotation methods: delimit words and box selection. After selecting the field value area, the system will automatically pop up an annotation popup, in which you can modify the annotation result, select the field, and finally click OK to save the annotation content.
- Multiple values can be annotated if the field type is the array
- If the field type is a string, the result of the second annotation will overwrite the result of the last annotation
- If a field does not appear in the document, mark it as Not Exist
- The state of data will change to Annotated only after all fields of the data are annotated
4) After annotating all fields, add the current data to the training set or evaluation set.
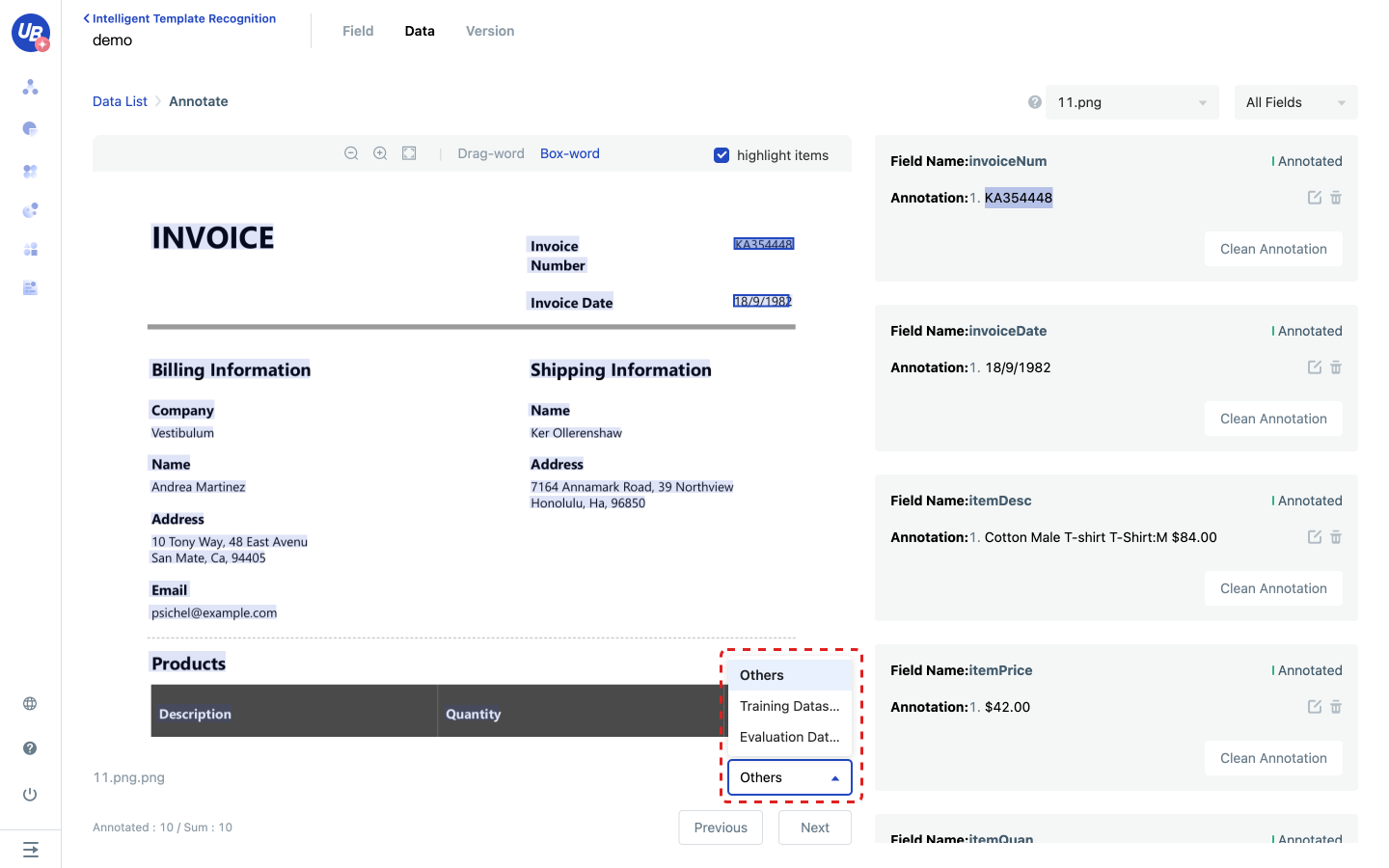
5) After configuring the training set and evaluation set, you can proceed to the next step.
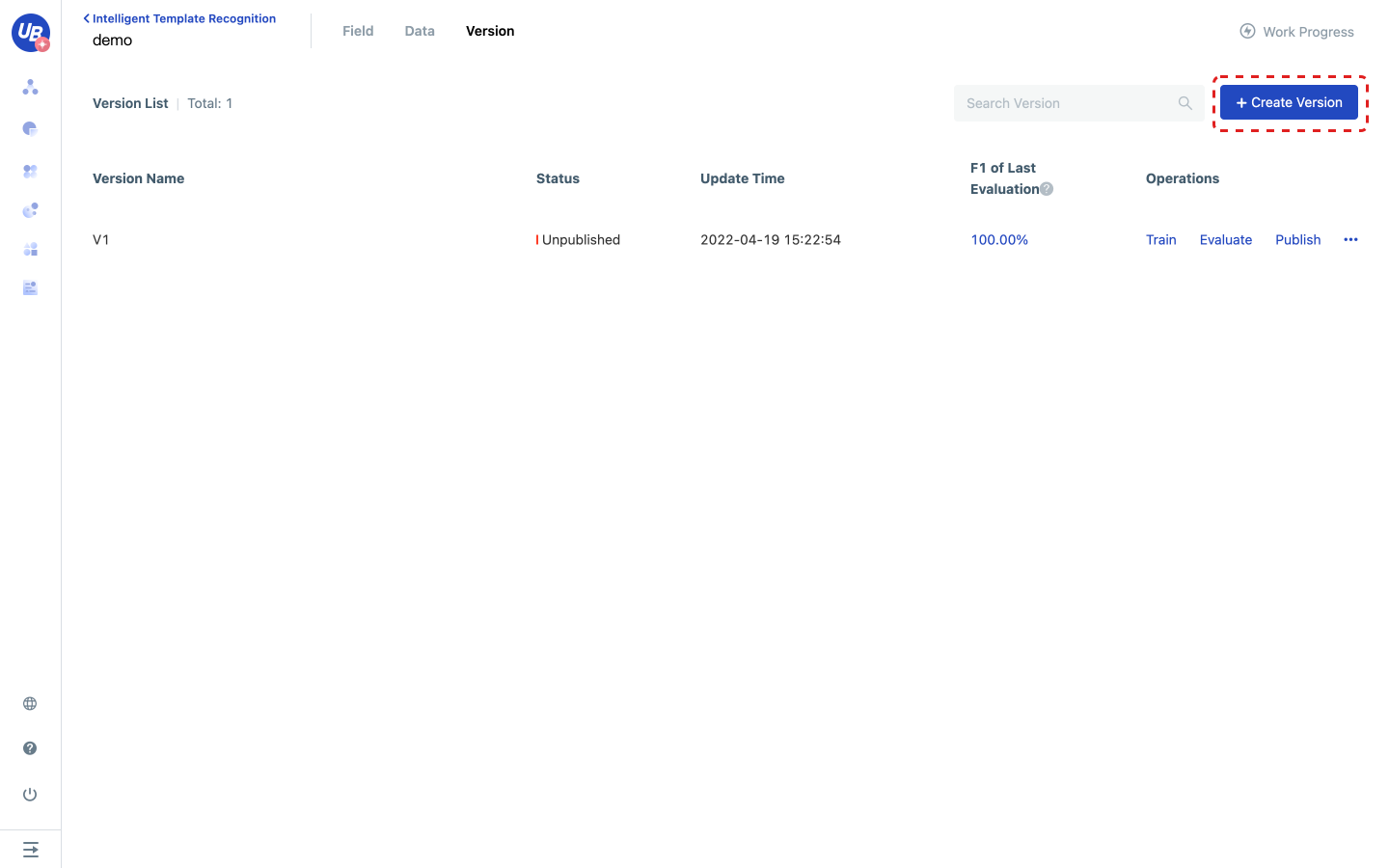
Create a new version
1) Click step 5 in the work progress to create a new version, and click go to create to enter the version page.
2) Click Create version to create a version named V1.
Training
1) Click step 6 in the work schedule and click go to train to enter the version page.
2) Click V1 version Train to initiate model training.
- The system will use the data in the training set to train the model. The training set should contain real and representative data in business scenarios, with about 30-50 pieces in each format. The more data, the better the model effect.
- The training may take a period. The more data in the training set, the longer the training takes. You can view the remaining training time by moving the mouse over the state of the version you are training.
3) After the training is completed, you can continue the next step.
- If the data of the evaluation set has been configured before the training, the system will automatically initiate an evaluation.
- If you need to roll back the model, create a new version for training. Retraining the version overwrites the previous training results, making the history unrecoverable.
Evaluation
1) Click step 7 in the work progress, and click go to evaluate to enter the version page.
2) Click Evaluate of V1 version to initiate a model evaluation.
- The system will use the data in the profiling set to evaluate the model. Note that the benchmark set should contain the same distribution of data as the training set.
- Evaluation takes a period. The more data in the evaluation set, the longer the evaluation takes. You can see the remaining time of the review by hovering over the version's status.
3) After the evaluation is completed, click the last evaluation F1** value of the version to download this evaluation report.
- The evaluation report contains four sheets: summary of results, field extraction statistics, all extraction results, and document extraction details, which can view the effect of the model from different dimensions.
- Reevaluation directly overwrites the last evaluation results. If you want to compare the effects of the model and keep a record of each evaluation, copy the new version for evaluation.
Release
1) Click step 8 to publish in the work schedule and click go to publish to enter the version page.
2) Click Publish under the operation to release the version to release the current version.
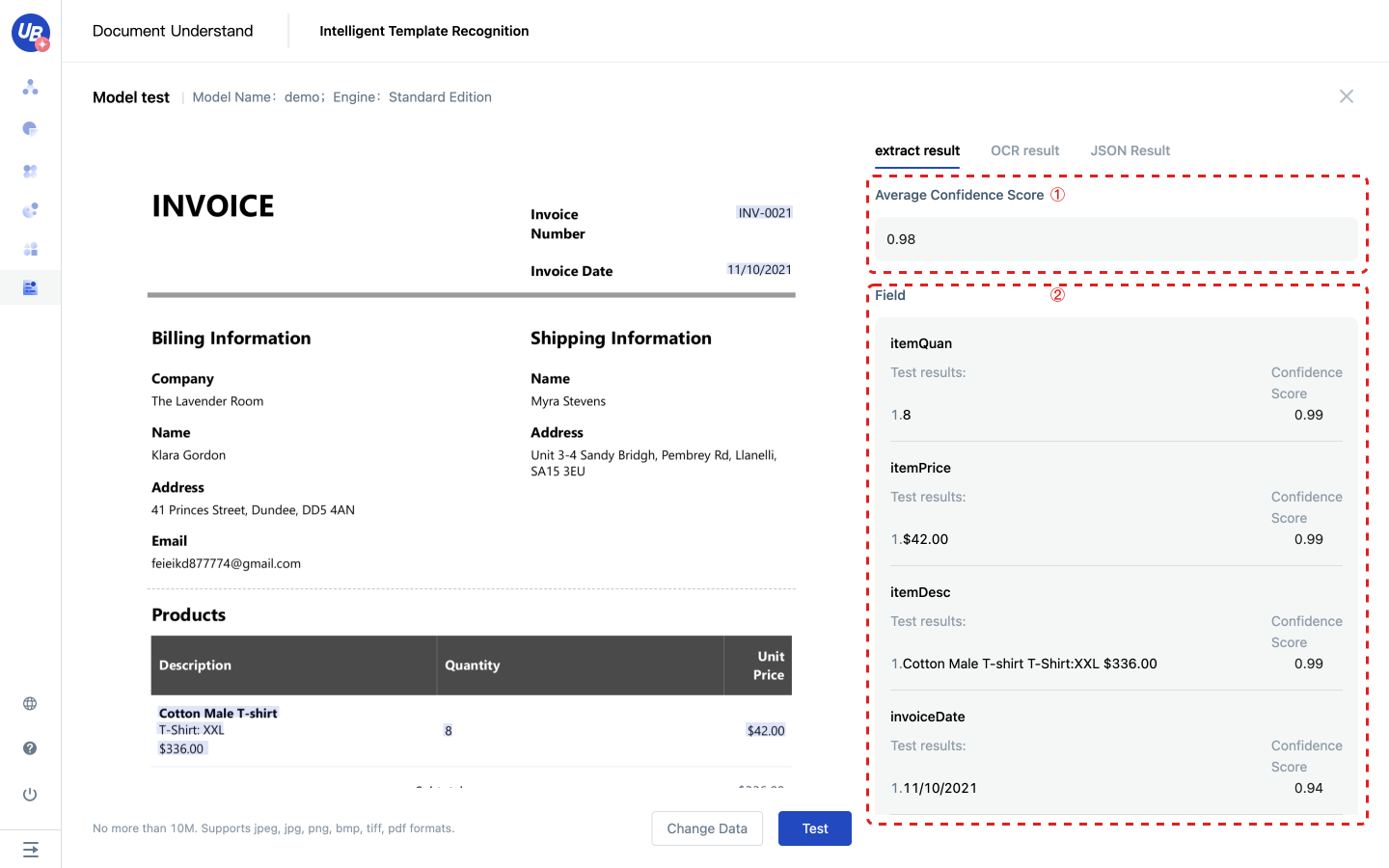
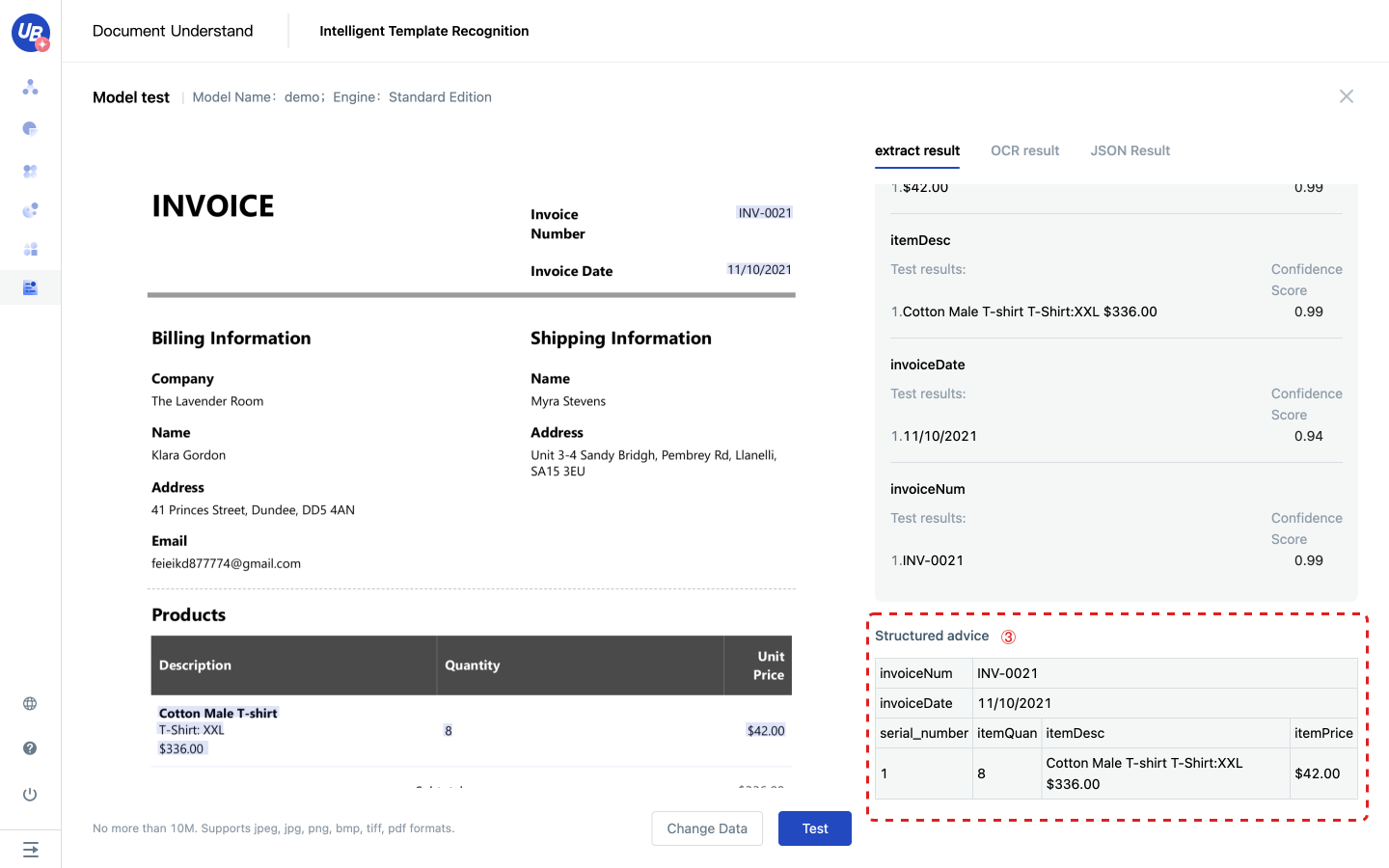
3) After the release, return to the page of Intelligent Template Recognition and click Test of the model to test whether the effect meets the expectation.
Extraction results include the following three parts:
- Average confidence score: weighted average of the confidence of each result can reflect the overall accuracy of the data to a certain extent
- Field: Presents the extracted results in field granularity, including the confidence degree of each result
- Structured advice: Considering that tables often appear on documents, we provide general row restoration to assemble the results of the extraction model and provide structured suggestions.
FAQ
Number deduction logic
The Intelligent Template Recognition is a comprehensive AI capability, and the platform will deduct the number of pages. Here are the actions that can occur:
- Data management: After data is uploaded, the system deducts the number of times based on pages of files
- Model tests and API calls: deduct by pages of files number of times
How to choose the training methods
We provide two training methods according to the type and number of training samples:
Template Self-training is suitable for processing less training data, structured or semi-structured documents, such as delivery notes, non-standard bills, etc.
Document Self-training is suitable for processing a lot of training data scenarios, also very suitable for processing unstructured documents, such as contracts, tender announcements, resumes, etc.
How to configure training data
Template Self-training: if there are fewer formats (less than 10), about 30-50 sheets of each format; If there are more formats (more than 100), each format is about 10 sheets. The more formats, the less data the model requires for each format.
Document Self-training: When the training data reaches more than 50, you can select Document Self-training. To obtain stable and good generalization effect, you are advised to increase the number of training data to 2000.
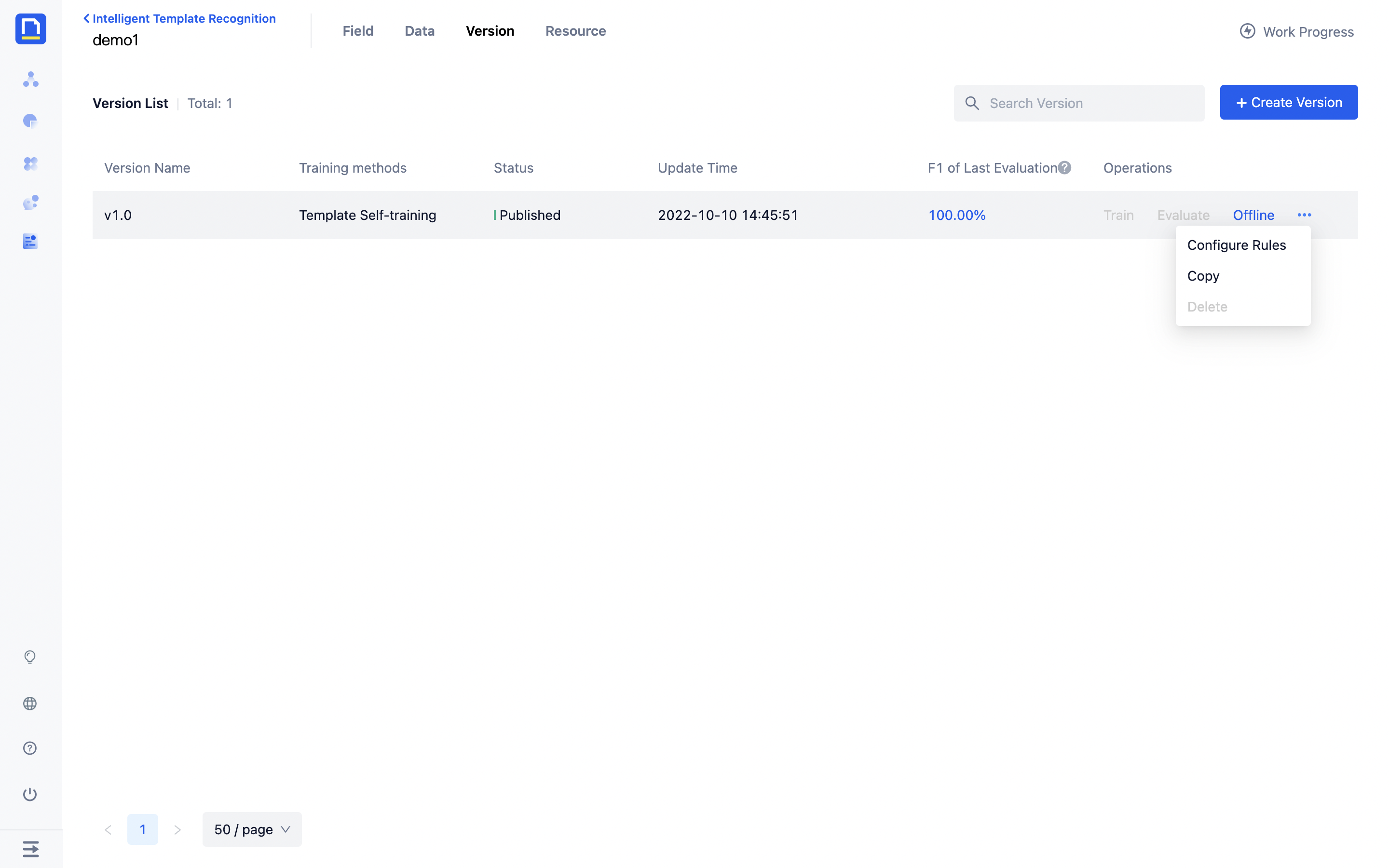
How to impove recall in ITR
Configure rules to recall data points.
Postprocessor explanation
| EnglishName | instructions | Before | After |
| Number | Extract the first number in the result, including integer, decimal, percentage | :1234 | 1234 |
| a12.34x | 12.34 | ||
| a-3.45% | -3.45% | ||
| Integer | Extract the first integer in the result Integer: natural number, 0, negative of natural number | :1234 | 1234 |
| a12.34x | 12 | ||
| a-3.45% | -3 | ||
| Decimal | Extract the first decimal in the result, including the minus sign | :1234 | [null] |
| a12.34x | 12.34 | ||
| a-3.45% | -3.45 | ||
| Percentage | Extract the first percentage in the result, including the minus sign | :1234 | [null] |
| a12.34x | [null] | ||
| a-3.45% | -3.45% | ||
| Letters | Extract the letters in the result up to the first non-letter | TOTAL ORIGIN 1320.00 USD | TOTAL ORIGIN |
| Date | Extract the first date in the result in the format contained 2020-8-13、08/13/2020、13/08/2020、2020/08/13 | 2020-8-132 | 2020-8-13 |
| 1208/13/2020 | 08/13/2020 | ||
| Currency | The currency in the extraction result is case insensitive and needs to be normalized | cny | CNY |
| 100.00(USD | USD |