自训练抽取
业务场景描述
在企业文档处理的场景中,我们经常会遇到文档关键信息抽取的业务需求。虽然目前市面上已经有非常多开箱即用的文档抽取模型,例如增值税发票识别、采购合同抽取等,但是每个企业的文档版式、内容特征各不相同,开箱即用的模型不能解决所有企业的文档抽取问题。
来也智能文档处理平台利用平台上已有的OCR、NLP原子能力以及深度学习模型,研发了自训练抽取能力,支持用户通过标注数据即可训练出一个文档抽取模型,用于生产环境中对文档进行关键信息自动提取。创建一个自训练抽取模型可以:
- 标注少量数据,系统就可以训练出一个可用的模型
- 将效果不好的数据加入再次训练后,可明显提升同类型数据的效果
此外,来也还根据训练样本类型和数量的不同提供了2种训练方式:
- 单据自训练适用于处理训练数据较少、文档为结构化或半结构化的场景,例如送货单、非标准化票据等
- 文档自训练适用于处理训练数据较多的场景,也非常适合处理非结构化的文档,例如合同、招标公告、简历等
特点
自训练抽取具有以下几个特点:
- 简单易用:提供数据管理->标注->训练->评测->上线->优化的工作流程引导,手把手的教你如何打造一个可用于生产环境的模型。
- 模型轻量:以OCR识别的结果作为输入,充分利用视觉和语义信息建模,在低成本(标注数据少、资源占用少)的情况下完成文档信息抽取任务。
使用方法
下面将以英文发票为例,创建一个发票抽取模型。
- 点击这里下载测试数据,跟着引导试一试吧!
创建模型
1)登录平台后点击左侧导航栏的文档理解进入自训练抽取。
2)点击新建模型,创建一个模型。
- 语言:因为不同语言需要进行不同的预处理,如中文需要切字、英文需要切词;请根据模板上的主要语言选择模型的语言种类。
3)点击 开始或配置 进入模型配置
4)进入模型配置后,会看到右上角的工作进度引导已经打开,请按照工作进度的引导完成后续步骤。
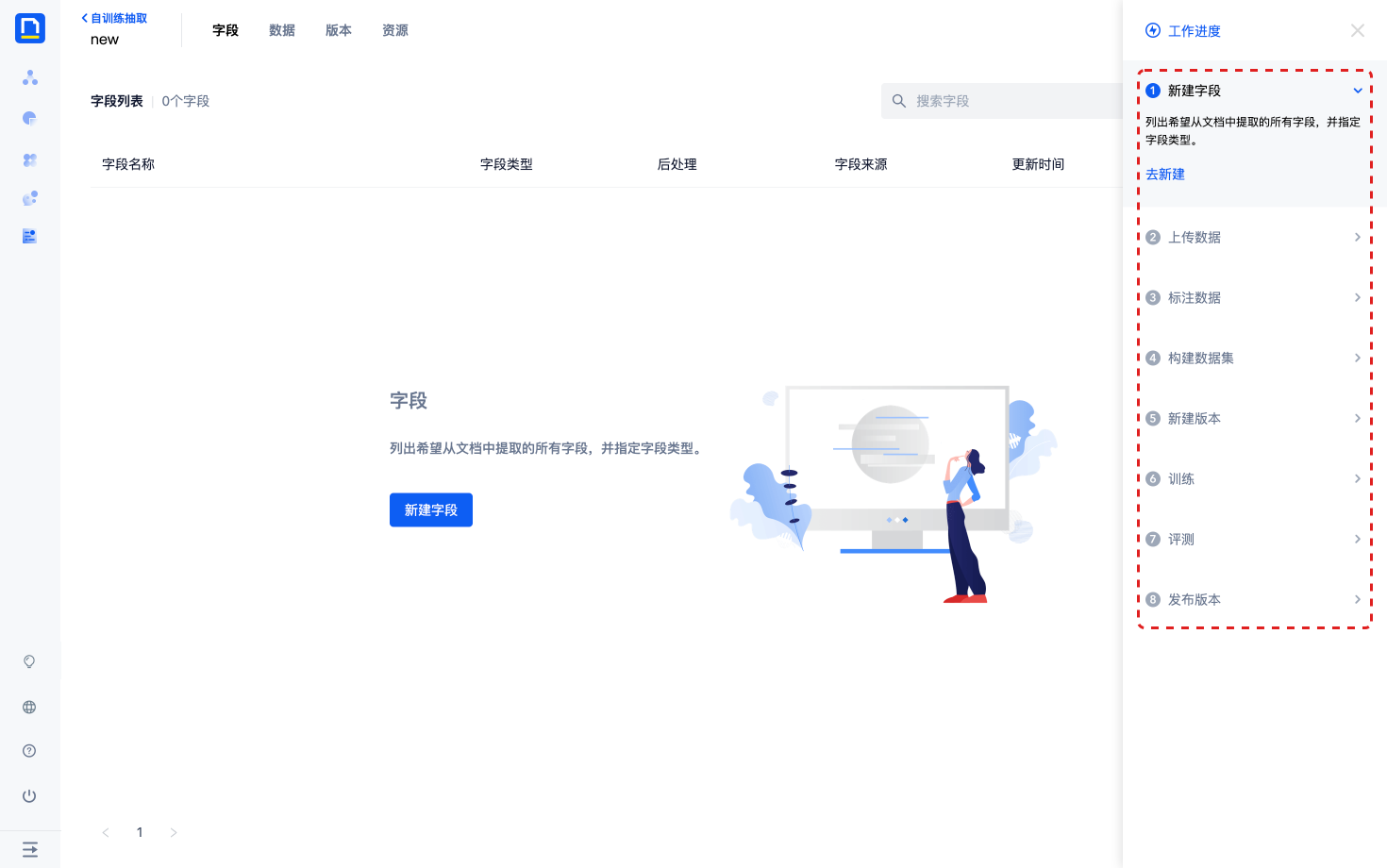
新建字段
1)点击工作进度中的第1步 新建字段,点击去新建,进入字段分页。
2)分析希望模型从文件中提取的内容,根据需求创建字段。
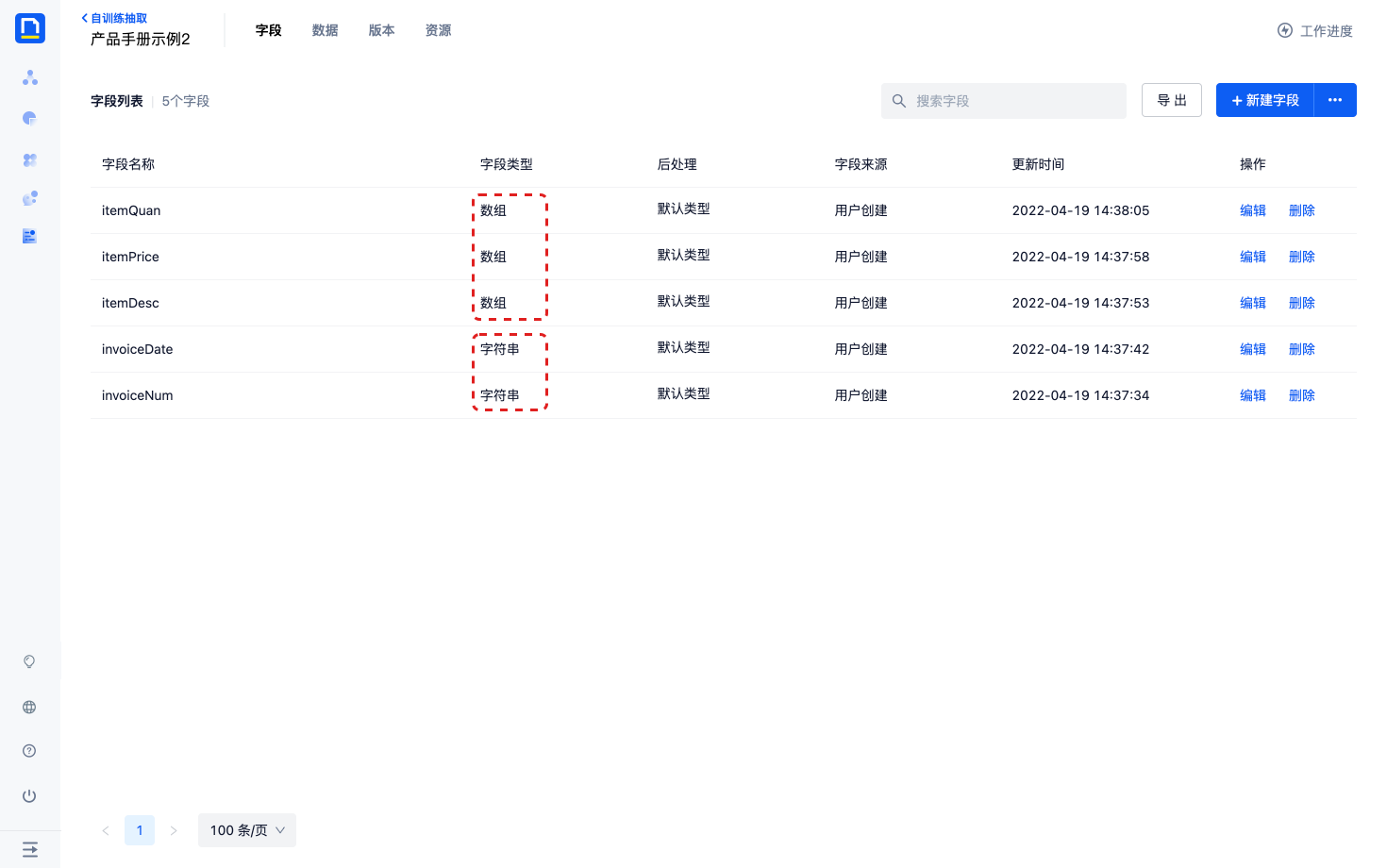
- 字段名不得超过100个字
- 字段类型可以选择字符串、数组,如果内容会出现在文档的多个位置,请选择数组类型
- 字段后处理来自于资源模块,预设词表的具体处理规则可以在常见问题中查询到
注意: 修改字段类型“数组”为“字符串”时,可能会导致部分标注数据丢失
上传数据
1)点击工作进度中的第2步 上传数据,点击去上传,进入数据分页。
2)上传相关业务数据到数据管理。
- 数据管理中的数据可以用于模型的训练、评测
- 数据上传后将自动进行OCR识别,识别完成后才能进行标注
标注数据,构建数据集
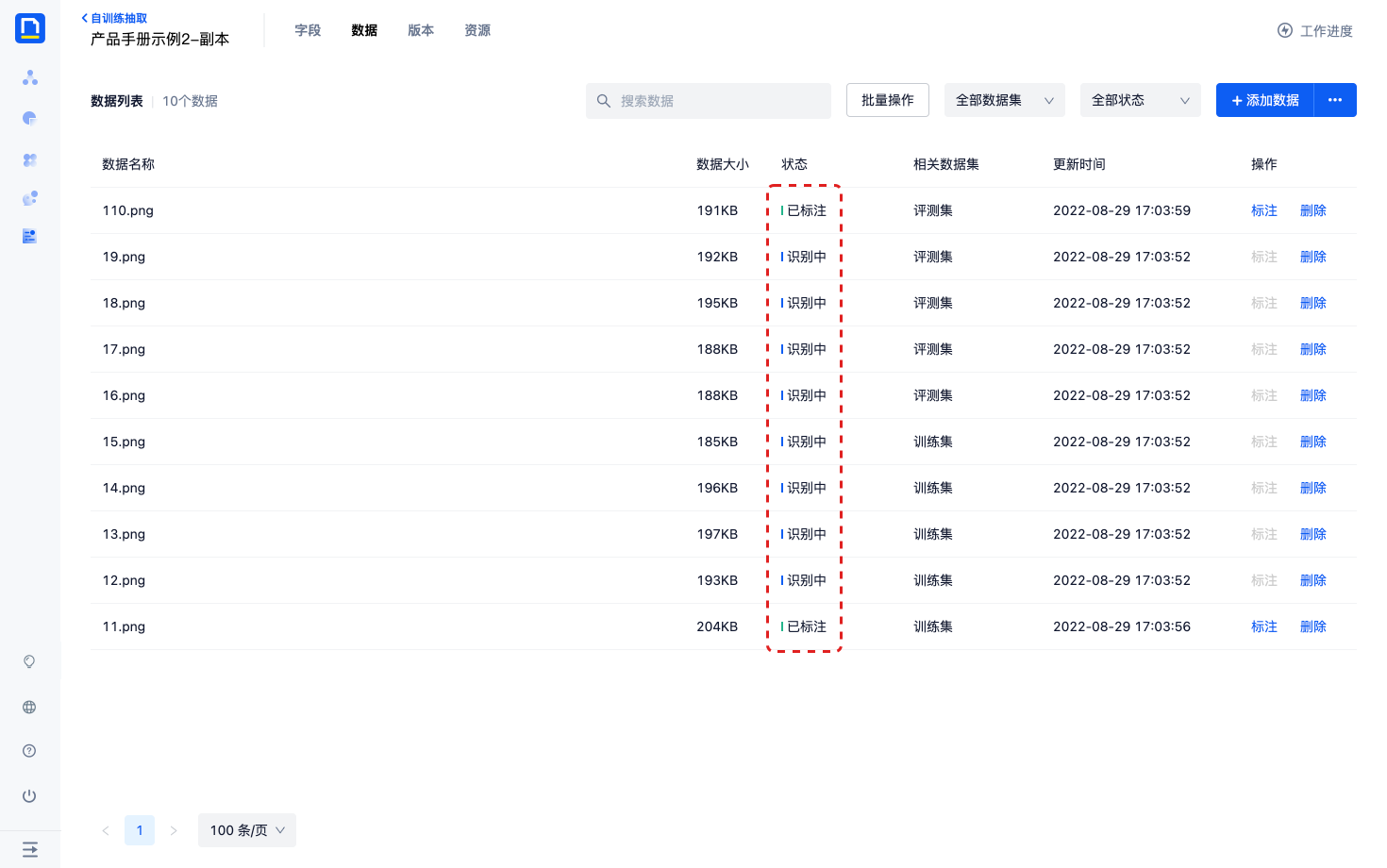
1)点击工作进度中的第3步 标注数据,点击去标注,进入数据分页。
2)点击任意一条数据的标注,进入标注页面。
- 如果模型有已发布的版本,数据上传后会使用已发布版本进行抽取,为用户提供预标注
3)标注页面提供划词、框选2种标注方法,选中字段值区域后,系统会自动弹出标注弹窗,可以在这个弹窗里修改标注结果、选择字段,最后点击确认,保存标注内容。
- 如果字段类型为数组,可以标注多个值
- 如果字段类型为字符串,第二次标注结果将会覆盖上次标注结果
- 如果一个字段在文档中没有出现,请将该字段标记为没有出现
- 标注完一条数据的所有字段后,数据的状态才会变成已标注
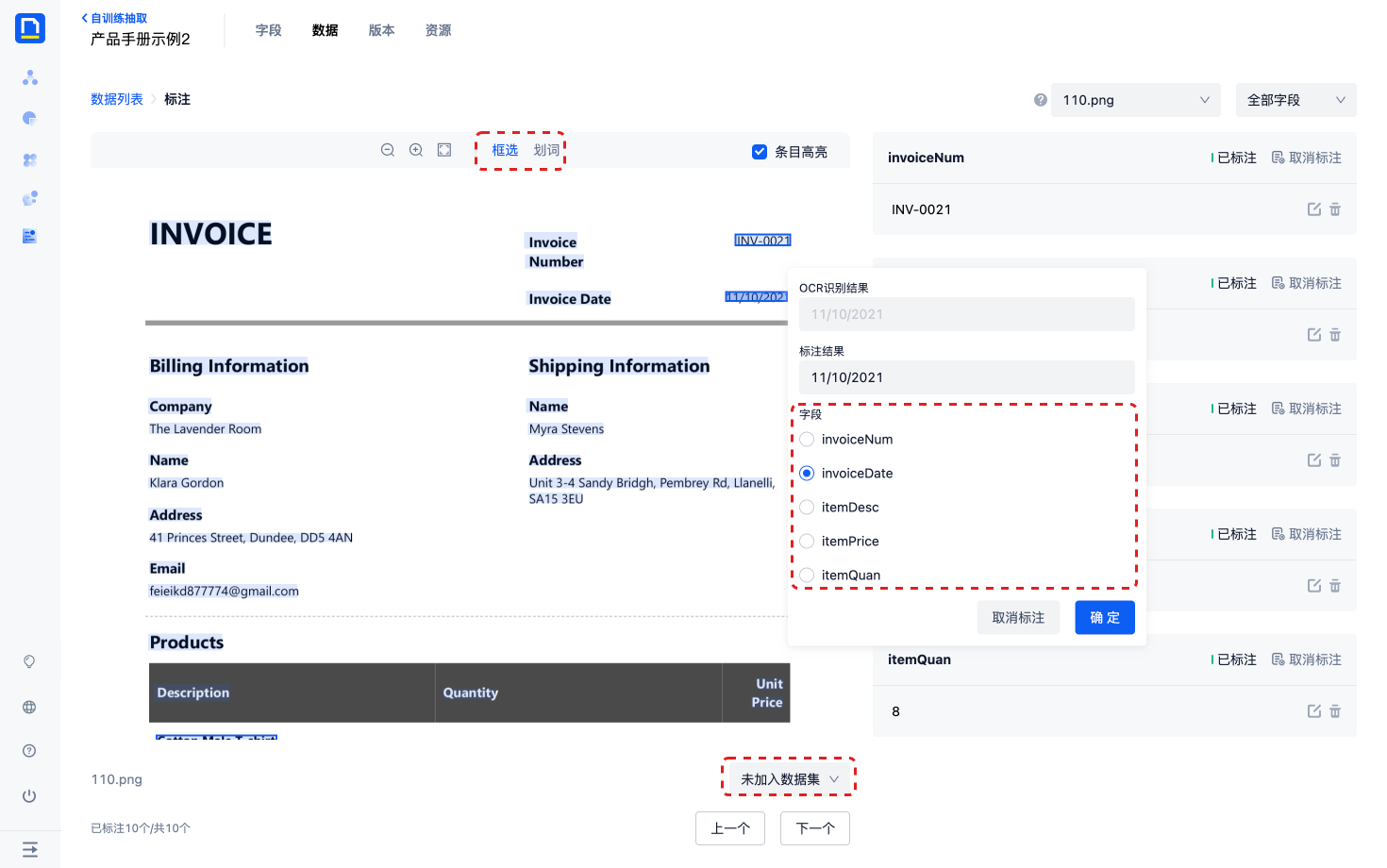
4)标注完所有字段后,将当前数据加入到训练集或评测集。
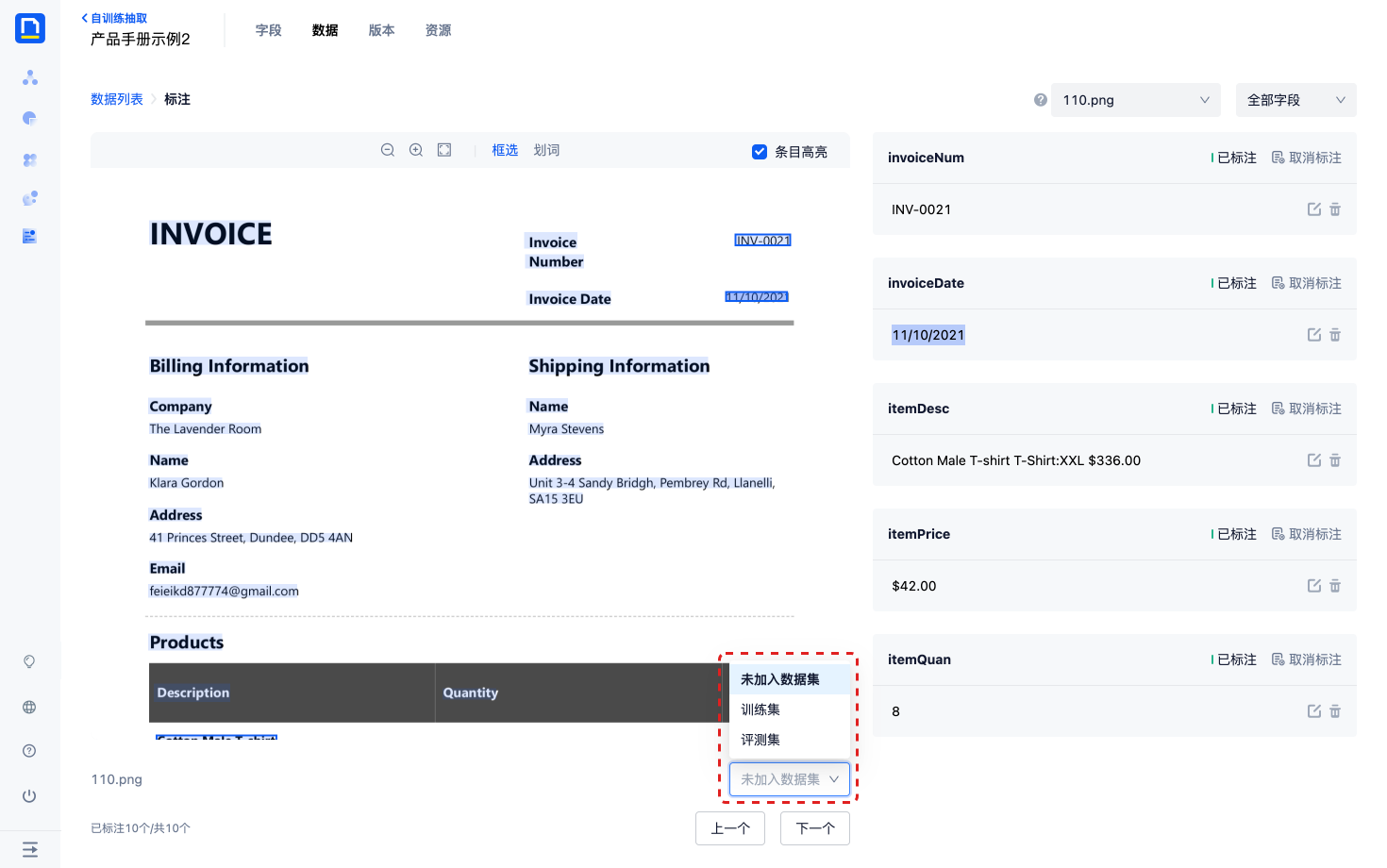
5)配置好训练集和评测集后,就可以进入下一步了。
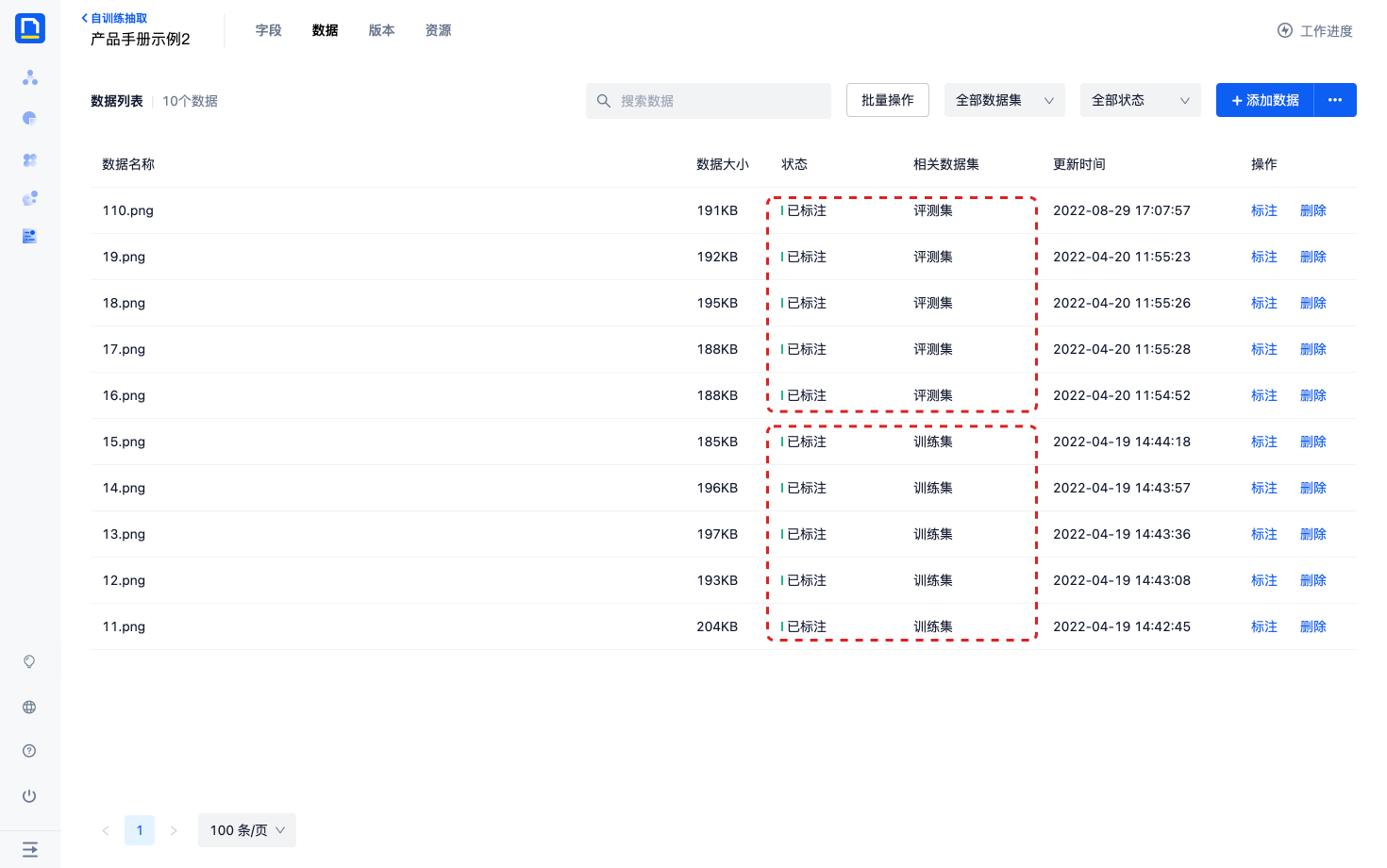
新建版本
1)点击工作进度中的第5步 新建版本,点击去新建,进入版本分页。
2)点击新建版本,创建一个名称为V1的版本。

训练
1)点击工作进度中的第6步 训练,点击去训练,进入版本分页。
2)点击V1版本的训练,根据需求选择训练方式、发起模型训练,等待训练完成后,可以继续下一步。
- 请注意,训练集中应该包含业务场景中的真实且具有代表性的数据,如果评测集不会空,系统将在训练完成后主动发起一次评测。
评测
1)点击工作进度中的第7步 评测,点击去评测,进入版本分页。
2)点击V1版本的评测,发起模型评测。
- 请注意,评测集中应该包含与训练集同分布的数据,如果偏离训练集较大,可能效果会不尽人意。
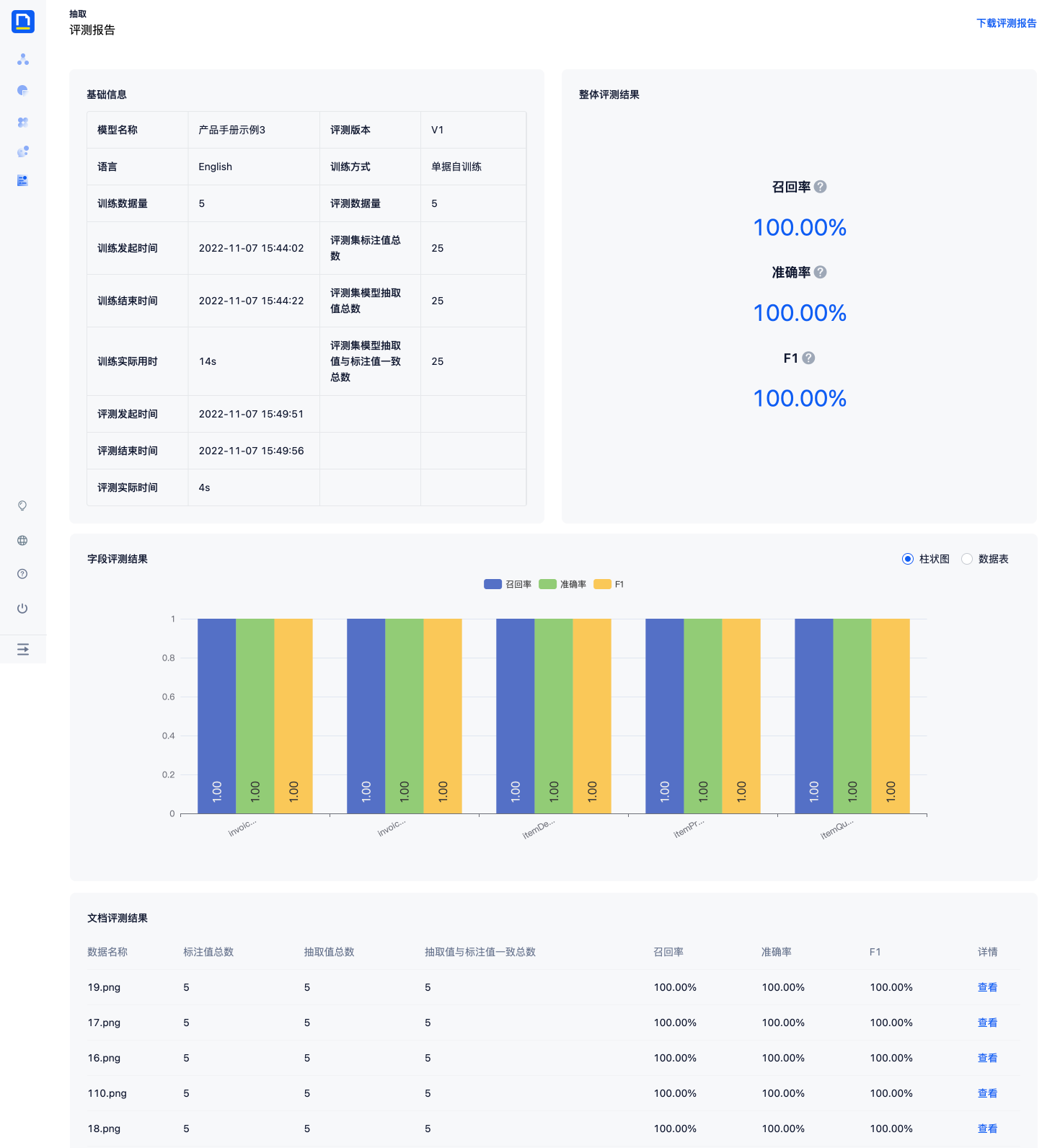
3)等待评测完成后,点击版本的上次评测F1值,可以打开本次评测的详细报告。

- 评测报告包含基础信息、整体评测结果、字段评测结果、文档评测结果等信息,可以从不同维度查看模型的效果。
发布版本
1)点击工作进度中的第8步 发布,点击去发布,进入版本分页。
2)点击需要发布版本操作下的发布,将当前版本发布。
3)发布之后回到模型列表页面,点击模型的测试,测试效果是否满足预期。
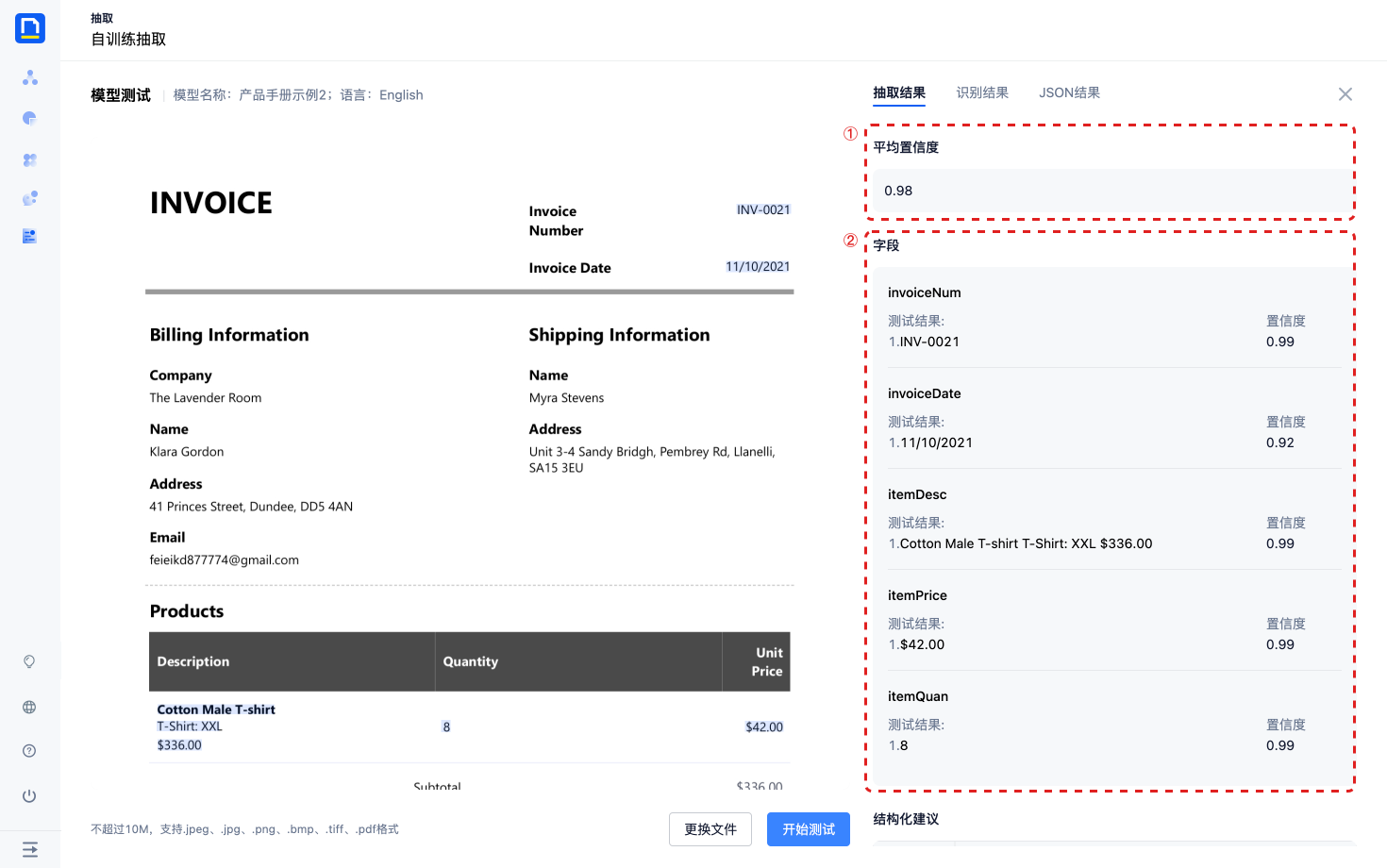
抽取结果包含了以下部分:
- 平均置信度:用每个结果的置信度加权平均,一定程度上能反应这张数据的整体准确度
- 字段:以字段粒度呈现抽取结果,包含了每个结果的置信度
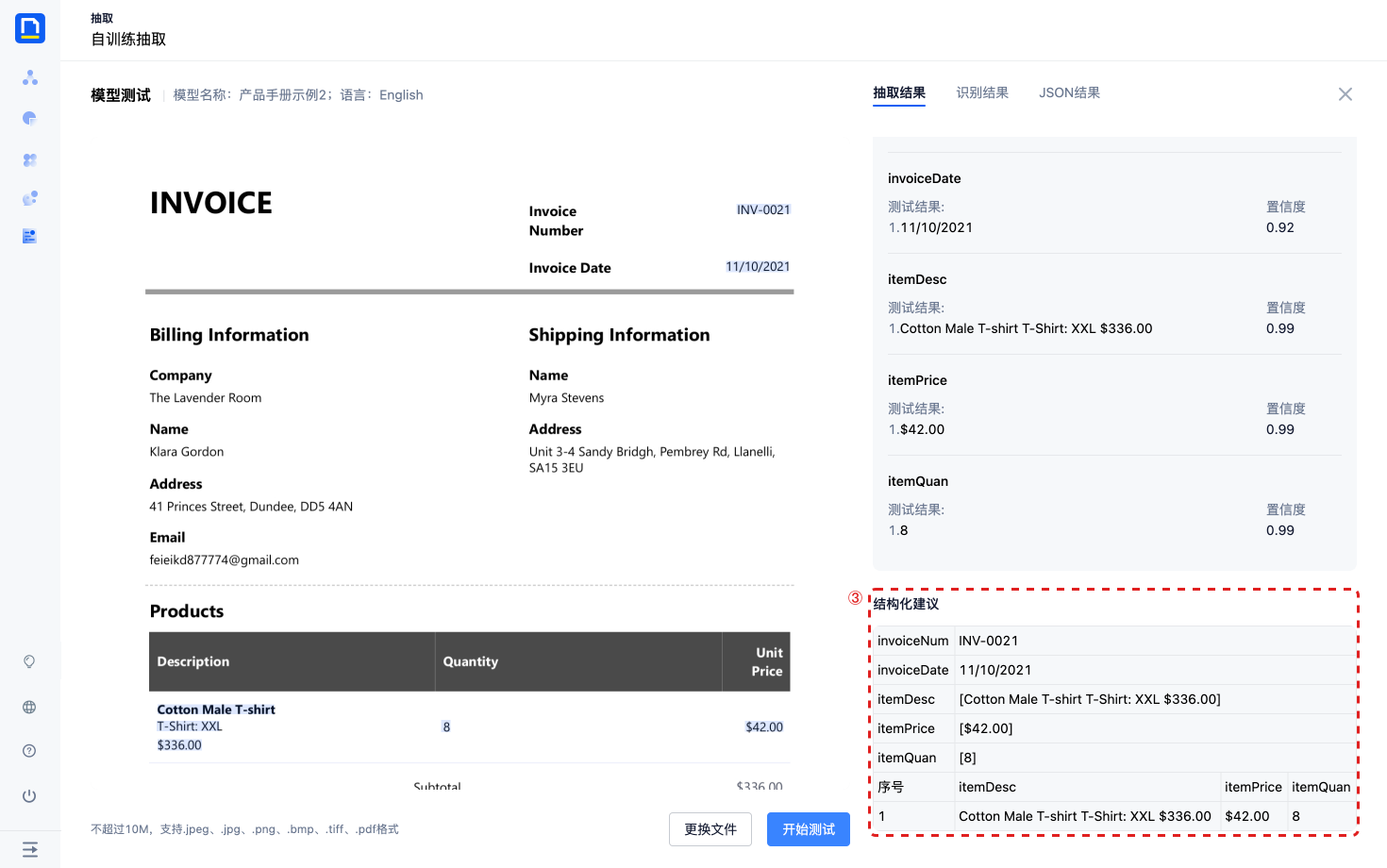
- 结构化建议:当模型训练方式为单据自训练时,考虑到单据上经常会出现表格,模型提供了通用行还原,对抽取模型的结果进行组装,提供结构化建议。
常见问题
次数扣减逻辑
自训练抽取是一个综合型AI能力,平台将会以页数来扣减次数。以下是会发生次数扣除的动作:
- 数据管理:上传数据后,按文件页数扣除次数
- 模型测试、API调用:调用成功后,按文件页数扣除次数
如何选择训练方式
我们根据训练样本类型和数量提供了2种训练方式:
单据自训练适用于处理训练数据较少、文档为结构化或半结构化的场景,例如送货单、非标准化票据等。
文档自训练适用于处理训练数据较多的场景,也非常适合处理非结构化的文档,例如合同、招标公告、简历等。
如何配置训练数据
单据自训练训练数据推荐配置:如果版式较少(少于10种),每种版式30-50张左右;如果版式较多(大于100种),每种版式10张左右。版式越多,模型对于每种版式的数据量要求越少。
文档自训练训练数据推荐配置:当训练集数据达到50份以上时,可以选择文档自训练训练方式,如果需要获得稳定、不错的泛化效果,建议训练数据增加到2000份。
如何提高自训练抽取召回率
自训练抽取“版本”选项,更多选项中,点击配置规则,对无召回情况,补充自定义模板规则,尝试二次召回。
预设词表使用说明
| 中文名 | 说明 | 后处理前 | 后处理后 |
| 数字 | 提取结果中的第一个数字,包含整数、小数、百分数 | :1234 | 1234 |
| a12.34x | 12.34 | ||
| a-3.45% | -3.45% | ||
| 整数 | 提取结果中的第一个整数 整数:自然数、0、自然数的负数 | :1234 | 1234 |
| a12.34x | 12 | ||
| a-3.45% | -3 | ||
| 小数 | 提取结果中的第一个小数,包含负号 | :1234 | \[空] |
| a12.34x | 12.34 | ||
| a-3.45% | -3.45 | ||
| 百分数 | 提取结果中的第一个百分数,包含负号 | :1234 | \[空] |
| a12.34x | \[空] | ||
| a-3.45% | -3.45% | ||
| 汉字 | 提取结果中的汉字,直到第一个非汉字出现 | 中国电子大厦东门19层 | 中国电子大厦东门 |
| 签名x123好 | 签名 | ||
| 字母 | 提取结果中的字母,直到第一个非字母 | TOTAL ORIGIN 1320.00 USD | TOTAL ORIGIN |
| 日期 | 提取结果中的第一个日期,目前处理的格式包含2020年08月13日、2020-8-13、08/13/2020、13/08/2020、2020/08/13 | 2020年08月13日x | 2020年08年13日 |
| 2020-8-132 | 2020-8-13 | ||
| 1208/13/2020 | 08/13/2020 | ||
| 币种 | 提取结果中的币种,不区分大小写,结果输出会进行归一化处理,都转成大写 | cny | CNY |
| 100.00(USD | USD |