Document Category
Business scenario description
In the business scenario of Laiye Intelligent Document Processing, a complex business process may involve processing several types of document, and different types of document may need to call different models or modules for processing.
For example, when a customer sends an email to a supplier to order products, the email attachment will include the contract, purchase order, and invoice. If the supplier wants to use RPA to process the received order mail, it needs to Category each attachment of the mail first, and then extract the key information in the next step, such as calling the contract extraction model for contracts and calling the general multi bill model for invoices.
Using the document Category provided by the company, a document Category model that can be put into production can be trained by labeling a small amount of data to complete the problems encountered by suppliers in the above scenarios.
Characteristic
- Easy to use: Provided Data Management ->Annotation ->Training ->Evaluation ->Launch ->Optimization The process of the project is to guide you to create a model that can be used in the production environment.
- Model lightweight: Using OCR recognition results as input, fully utilizing visual and semantic information for modeling low cost Complete the document Category Task with less annotation data and less resource consumption.
Usage method
Next, we will take English invoices, English purchase orders, and news as examples to create a document Category model.
- click here Download test data and follow the guide to give it a try!
Create Model
1) After logging in to the platform, click document Understanding on the left navigation bar to enter document Category.
2) Click on New Model to create a model.
- Language: Different languages require different preprocessing, such as Chinese requiring word segmentation and English requiring word segmentation; Please select the model language according to the main language on the document.
3) Click Start or Configure to enter model configuration
4) After entering the model configuration, you will see that the work progress guide in the upper right corner has been opened. Please follow the work progress guide to complete the subsequent steps.
New Category
1) Click Step 1 in the work progress to create a new Category, and click New to enter the Category page.
2) Create All Category that need model recommendations
- Category name cannot exceed 100 characters
- If you need to modify the Category name, move the mouse to the name area and click the edit button to activate the modification.
Upload data
1) Click on the second step in the work progress to upload data, then click on 'upload' to enter the data page.
2) Upload representative business data to data management for model training and evaluation.
- After uploading the data, OCR recognition will be automatically performed. After the recognition is completed, the data status will be changed to unlabeled before labeling can be performed.
- Upload limit: The file size should not exceed 10M, and the format should be jpeg, jpg, png, bmp, tiff, pdf
Annotate data and construct a dataset
1) Click on the third step in the work progress to annotate the data, then click on 'de annotate' to enter the data page.
2) Click on any data annotation to enter the annotation page.
- If the model has a published version, the model will automatically call the published version after data upload, providing pre annotations for users
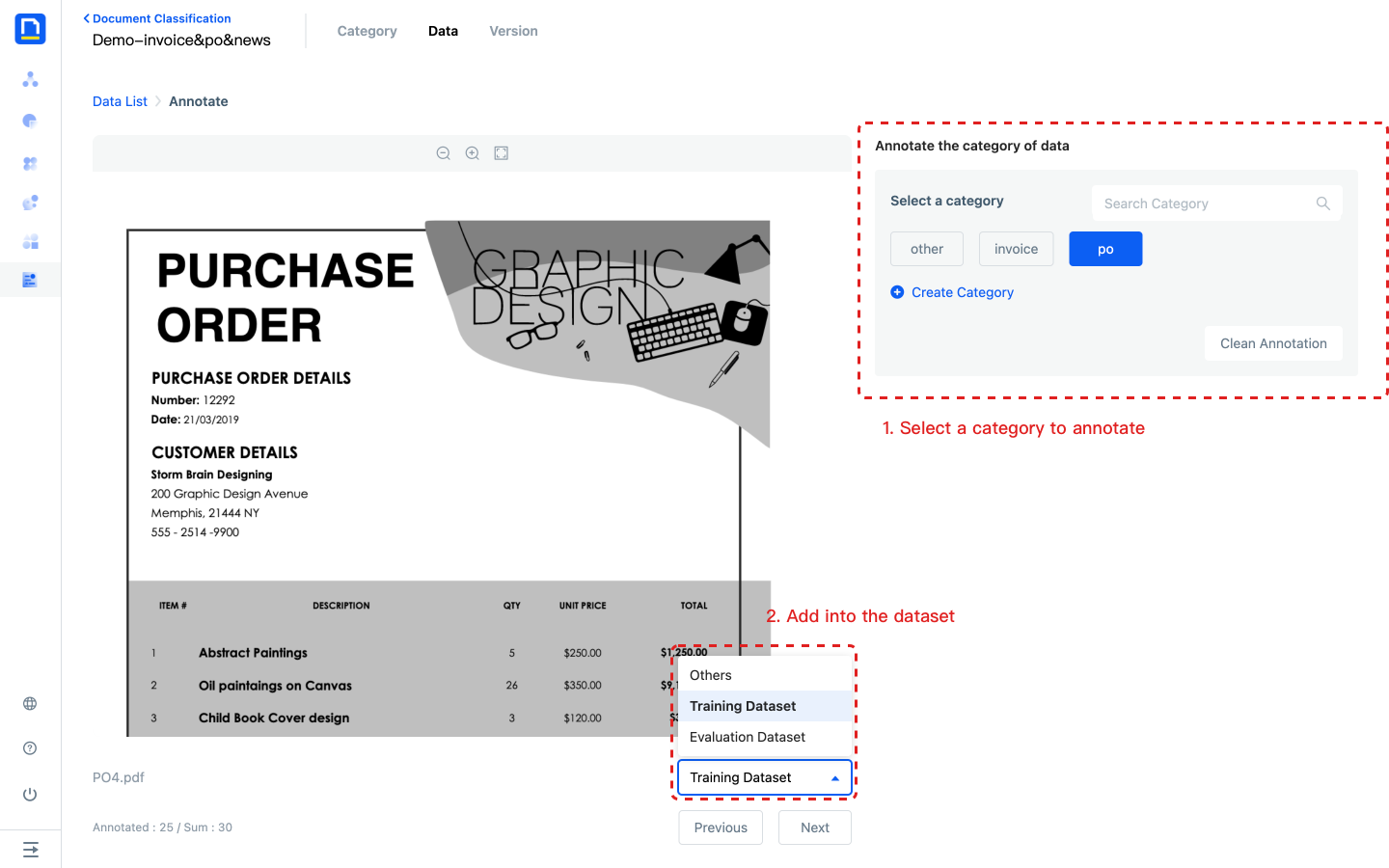
3) After entering the annotation page, all Category will be displayed on the right side of the page. After the data preview is successfully loaded, select the corresponding Category to complete the annotation, and directly add the current data to the training set or evaluation set.
- You can also batch add annotated data to the dataset through the data list page.
New Version
1) Click on step 5 in the work progress to create a new version, and then click on "Create" to enter the version page.
2) Click on New Version to create a version named V1.
Train
1) Click on the 6th step of training in the work progress, click on "Train" to enter the version page.
2) Click on the V1 version of training to initiate model training.
- The system will use the data in the training set to train the model. The training set should contain real and representative data in the business scenario. Only when there are at least two Category and at least five training samples under each Category can training be initiated. In order to improve the prediction effect, the number of training data for each Category is relatively balanced.
- Training may take some time, and the more data in the training set, the longer the training takes. You can view the remaining training time by moving the mouse to the version's status.
3) After the training is completed, you can proceed to the next step.
- If the data of the evaluation set has already been configured before starting the training, the system will automatically initiate a evaluation.
- If you need to keep multiple versions of the model for comparing the effects of old and new versions, please create a new version for training. Restarting training on the version will directly overwrite previous training results, resulting in the inability to retrieve historical records.
Evaluating
1) Click on step 7 of the work progress evaluation, click on "go to evaluation" to enter the version page.
2) Click on V1 version evaluation to initiate model evaluation.
- The system will use the data from the evaluation set to evaluate the model. Please note that the evaluation set should contain data that is distributed the same as the training set.
- Evaluation takes some time, and the more data in the evaluation set, the longer the evaluation takes. You can view the remaining time for evaluation by moving the mouse to the version's status.
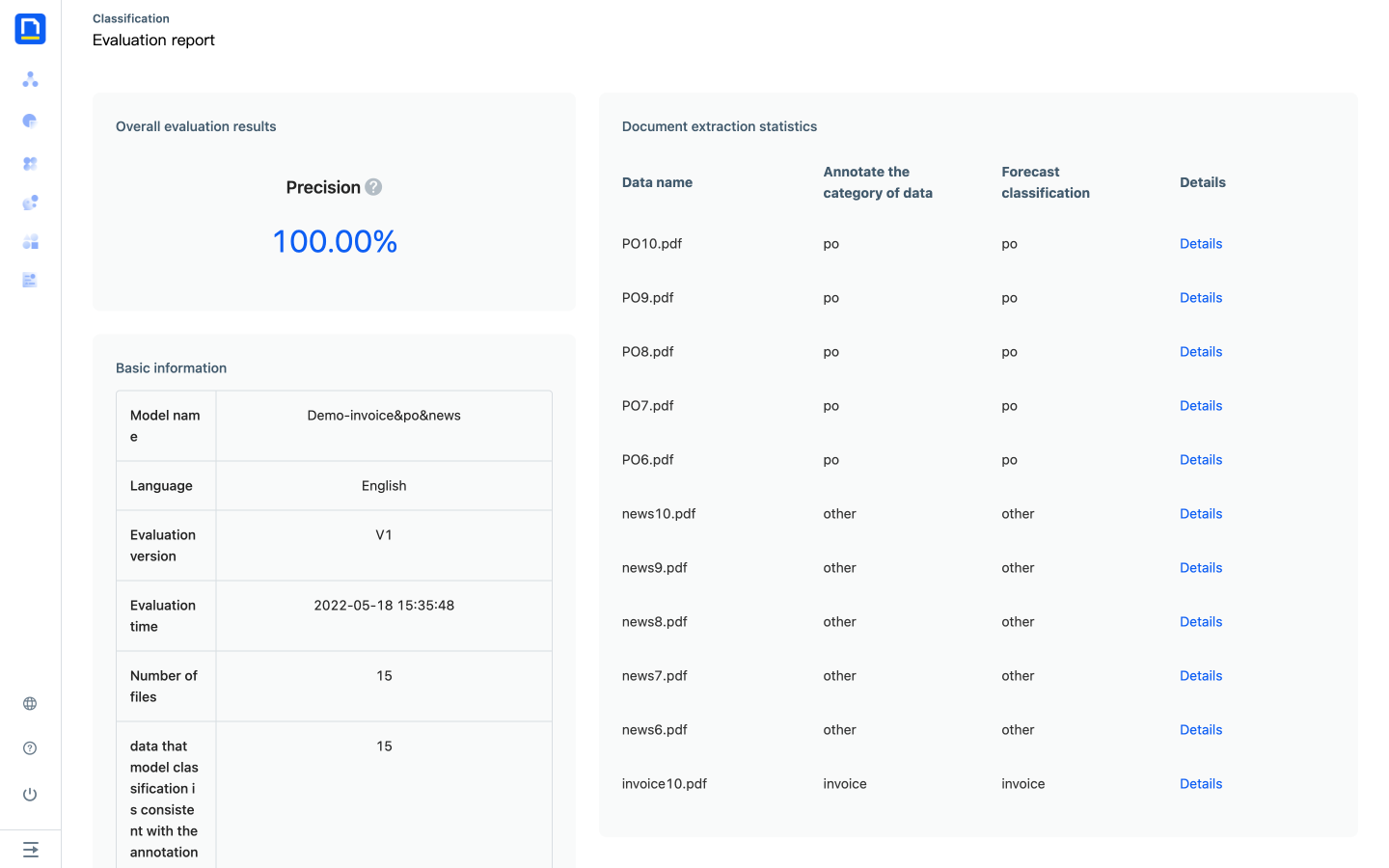
3) After waiting for the evaluation to be completed, click on the last evaluation accuracy of the version to view the current evaluation report.
4) The evaluation report includes the overall evaluation results, basic information and the evaluation results of each document.
Release version
1) Click on step 8 in the work progress to publish, then click on 'publish' to enter the version page.
2) Click 'Publish' under the 'Release Version Required' operation to publish the current version.
3) After publishing, return to the model list page and click on "Test Model" to test whether the results meet expectations.
- You can also directly test the model's effectiveness through testing in version operations before release
Model testing
The model test results include visualization results and JSON results:
- Visualization results
- Category Results
- Document level: the predicted Category results and corresponding confidence level of Task document
- Page level: when the number of pages of the document is greater than 1, the model will also provide the predicted Category results for each page of the document in the format: page number per page - predicted Category - corresponding confidence level.
- Suspected unknown type prompt
- In addition to the Category model that has been set, the model that distinguishes "known samples" and "unknown samples" will be trained separately, and when the confidence of this model is>0.5, the Category result will be marked with a prompt property of "suspected unknown type"
- For example: the image data contains a variety of animals, and it is difficult to enumerate Category. Through the Category model of "cat" and "dog", all images will be Category into the "cat" and "dog" categories, but images that are not "cat" and "dog" will be marked with a prompt property of "suspected unknown type". This property can be used for post business judgment filtering, or to add Category and training sets for other types of images.
- Category Results
- JSON Results
- You can view the format and results returned by the API call, and All details of the Category model test through the JSON results.
.png)
Frequently Asked Questions
What is the difference between document Category and Text Classification?
1) Input different
The input of Text Classification is text. To complete the Category of a document, users need to use RPA to build their own Category process, first call OCR recognition, obtain OCR recognition results, and call the Text Classification model. If the number of pages of a document is large, it may exceed the 30000 word call limit of Text Classification. There are many details to consider.
Document Category is an end-to-end AI Capability of a document, and document is the minimum strength for training, evaluation, and model invocation.
2) Different characteristics of model learning
The intelligent model of Text Classification only learns text semantic features, while the document Category model learns document semantic features and location features.