文档分类
业务场景描述
在智能文档处理的业务场景中,一个复杂的业务流程可能涉及到处理若干种类型的文档,而不同类型的文档大概率需要调用不同的模型或模块来处理。
比如,客户给供应商发邮件订购产品时,邮件附件中会包含合同、采购单、发票。如果供应商想用RPA来处理收到的订购邮件,那首先需要对邮件的每一个附件进行分类,然后再进行下一步的关键信息提取,比如合同调用合同抽取模型,发票调用通用多票据模型。
使用来也提供的文档分类,通过标注少量数据,就可以训练出一个可投产的文档分类模型来完成上述场景中供应商遇到的问题。
特点
- 简单易用:提供数据管理->标注->训练->评测->上线->优化的工作流程引导,手把手的教你如何打造一个可用于生产环境的模型。
- 模型轻量:以OCR识别的结果作为输入,充分利用视觉和语义信息建模,在低成本(标注数据少、资源占用少)的情况下完成文档分类任务。
使用方法
下面将以英文发票、英文采购单、新闻为例,创建一个文档分类模型。
- 点击这里下载测试数据,跟着引导试一试吧!
创建模型
1)登录平台后点击左侧导航栏的文档理解进入文档分类。
2)点击新建模型,创建一个模型。
- 语言:因为不同语言需要进行不同的预处理,如中文需要切字、英文需要切词;请根据文档上的主要语言选择模型语言。
3)点击 开始或配置 进入模型配置
4)进入模型配置后,会看到右上角的工作进度引导已经打开,请按照工作进度的引导完成后续步骤。
新建分类
1)点击工作进度中的第1步 新建分类,点击去新建,进入分类分页。
2)创建需要模型推荐的全部分类
- 分类名不得超过100个字
- 如果需要修改分类名称,请将鼠标移动到名称区域并点击编辑按键激活修改。
上传数据
1)点击工作进度中的第2步 上传数据,点击去上传,进入数据分页。
2)上传具有代表性的业务数据到数据管理,用于模型的训练、评测。
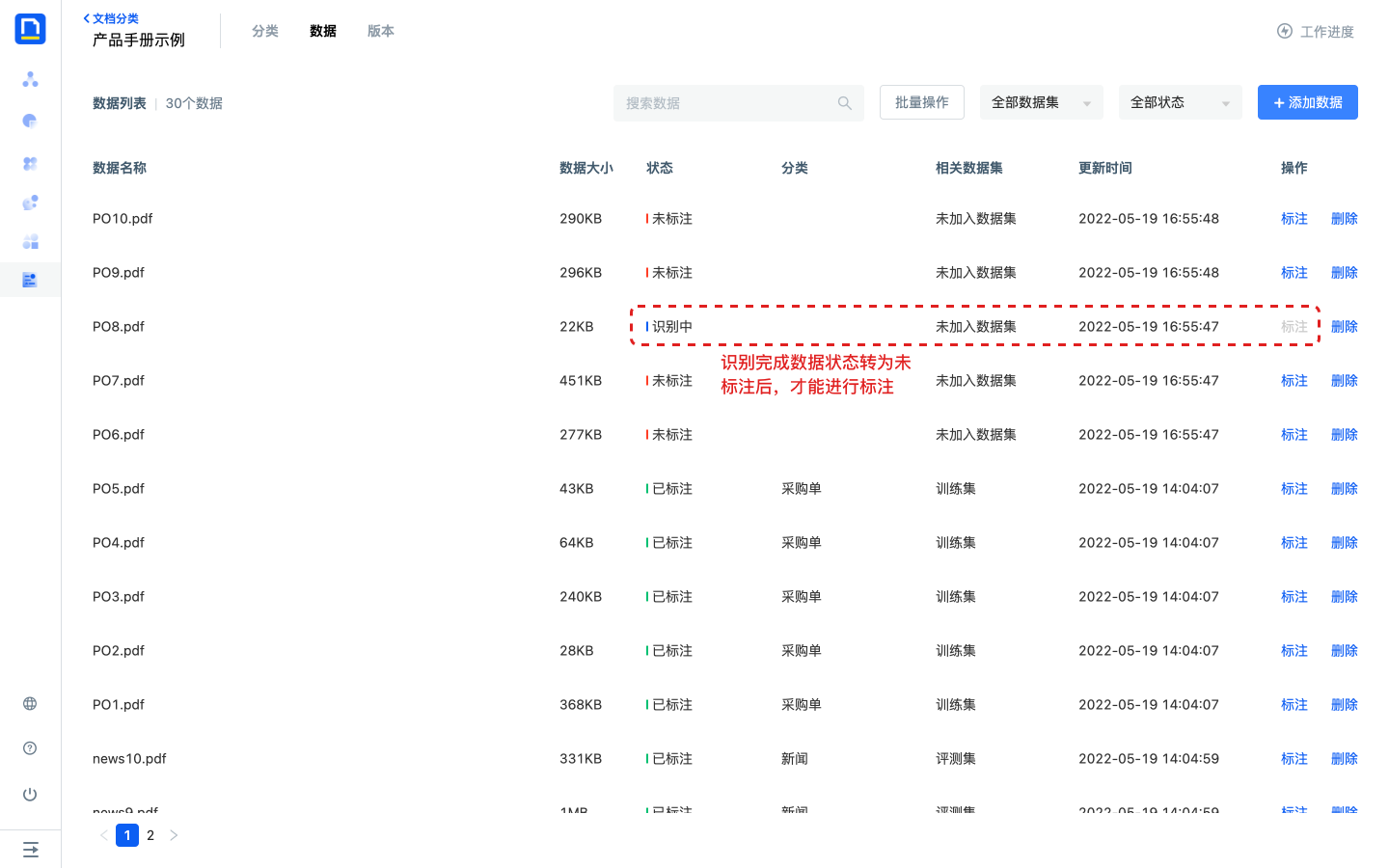
- 数据上传后将自动进行OCR识别,识别完成数据状态转为未标注后,才能进行标注。
- 上传限制:文件大小不超过10M,格式为jpeg、jpg、png、bmp、tiff、pdf
标注数据,构建数据集
1)点击工作进度中的第3步 标注数据,点击去标注,进入数据分页。
2)点击任意一条数据的标注,进入标注页面。
- 如果模型有已发布的版本,数据上传后模型会自动调用已发布版本,为用户提供预标注
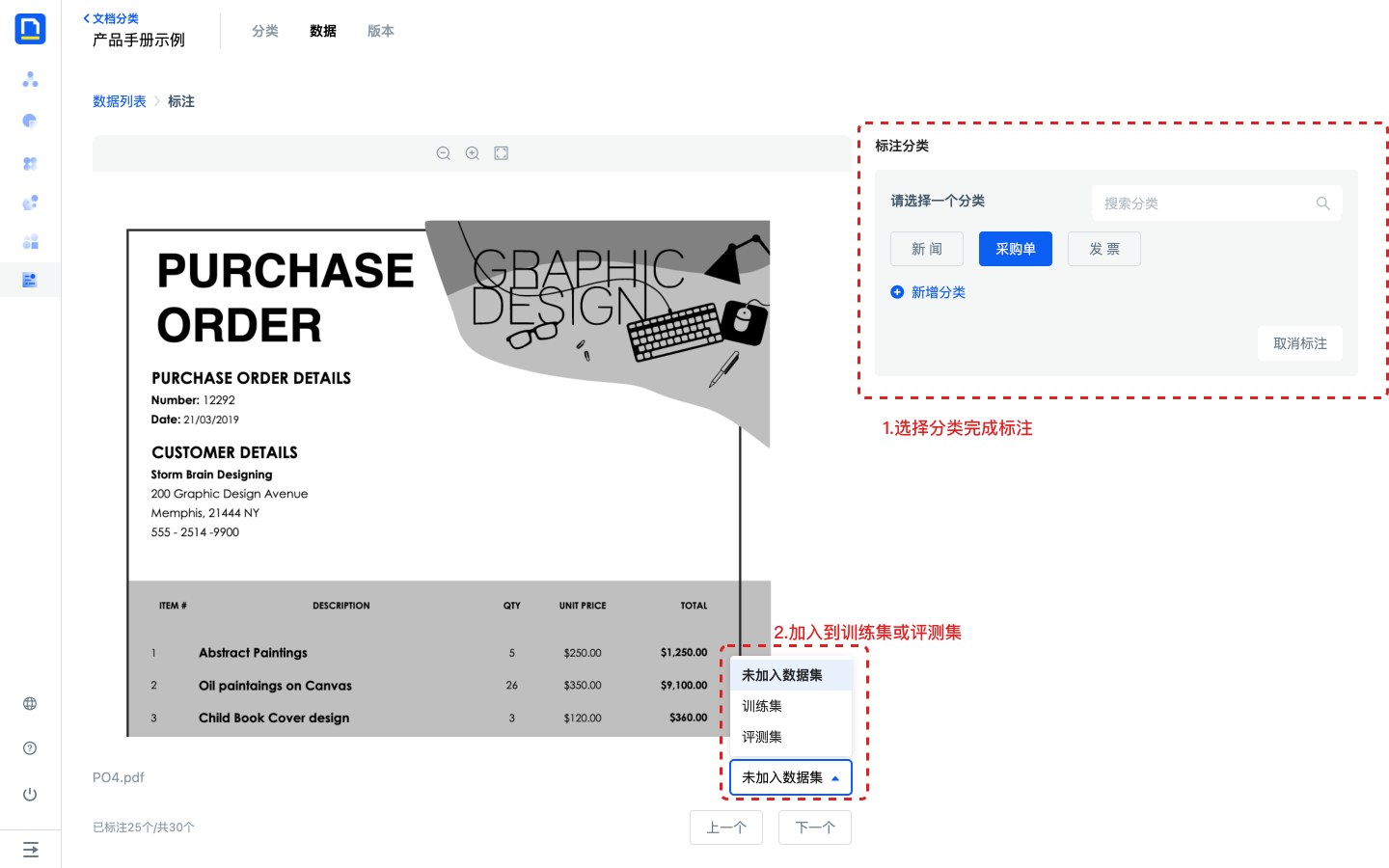
3)进入标注页面后,所有分类都会展示在页面右侧,等待数据预览加载成功后,选择对应的分类完成标注后,直接将当前数据加入到训练集或评测集。
- 也可以通过数据列表页批量将已标注的数据加入到数据集。
新建版本
1)点击工作进度中的第5步 新建版本,点击去新建,进入版本分页。
2)点击新建版本,创建一个名称为V1的版本。
训练
1)点击工作进度中的第6步 训练,点击去训练,进入版本分页。
2)点击V1版本的训练,发起模型训练。
- 系统将利用训练集中的数据来训练模型,训练集中应该包含业务场景中的真实且具有代表性的数据,至少有2个分类且每个分类下至少有5个训练样本才可以发起训练。为了提升预测效果,每个分类的训练数据数量相对均衡。
- 训练可能需要一段时间,训练集的数据越多训练耗时越长。你可以通过将鼠标移动到版本的状态上查看训练剩余时间。
3)等待训练完成后,可以继续下一步。
- 如果在开始训练前,已经配置了评测集的数据,系统会自动发起一次评测。
- 如果需要保留多个版本的模型,用于比较新旧版本的效果,请创建新版本进行训练。对版本重新发起训练会直接覆盖以前的训练结果,导致历史记录无法找回。
评测
1)点击工作进度中的第7步 评测,点击去评测,进入版本分页。
2)点击V1版本的评测,发起模型评测。
- 系统将利用评测集中的数据来对模型进行评测。请注意,评测集中应该包含与训练集同分布的数据。
- 评测需要一段时间,评测集的数据越多评测耗时越长。你可以通过将鼠标移动到版本的状态上查看评测剩余时间。
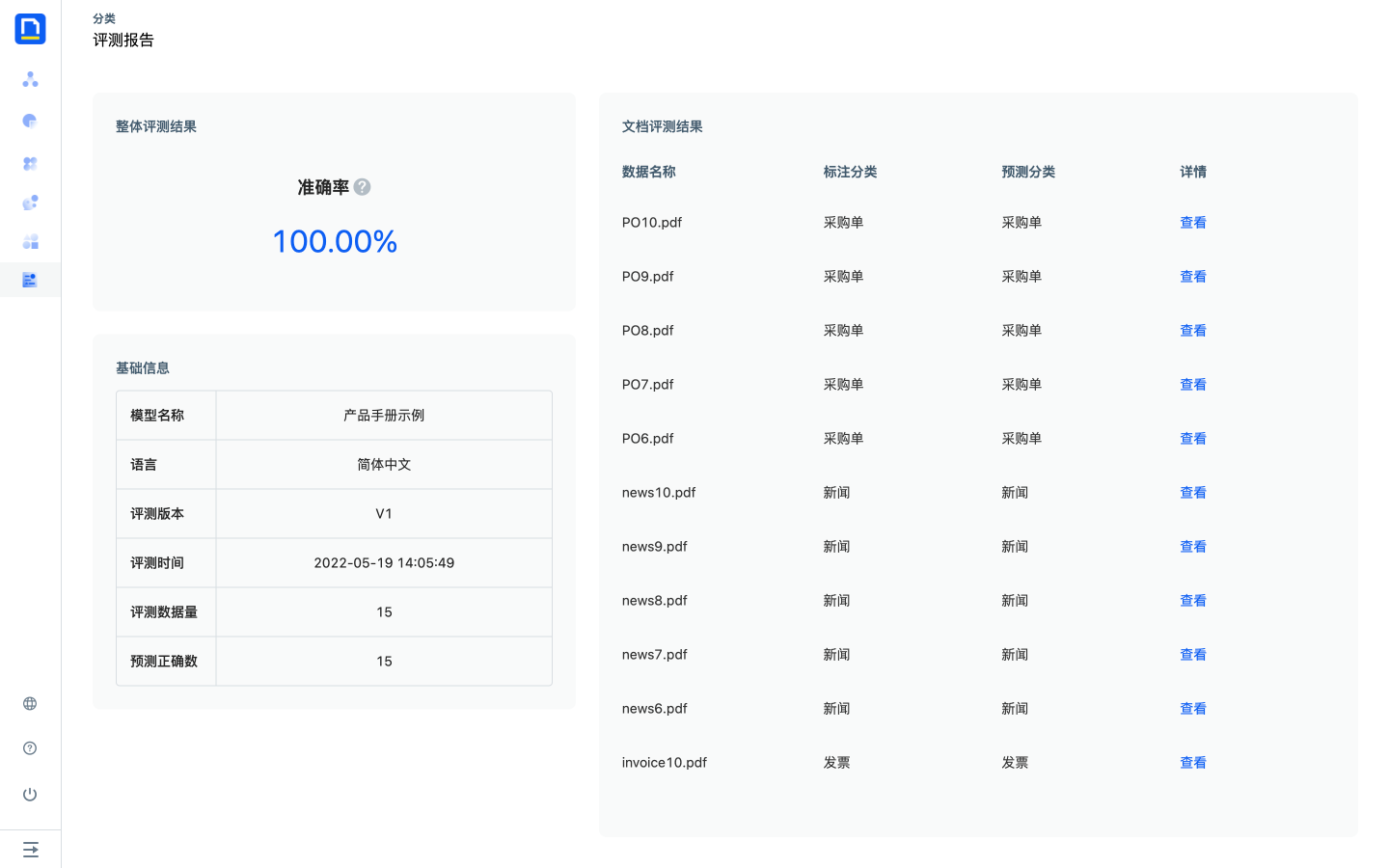
3)等待评测完成后,点击版本的上次评测准确率,可以查看本次评测报告。
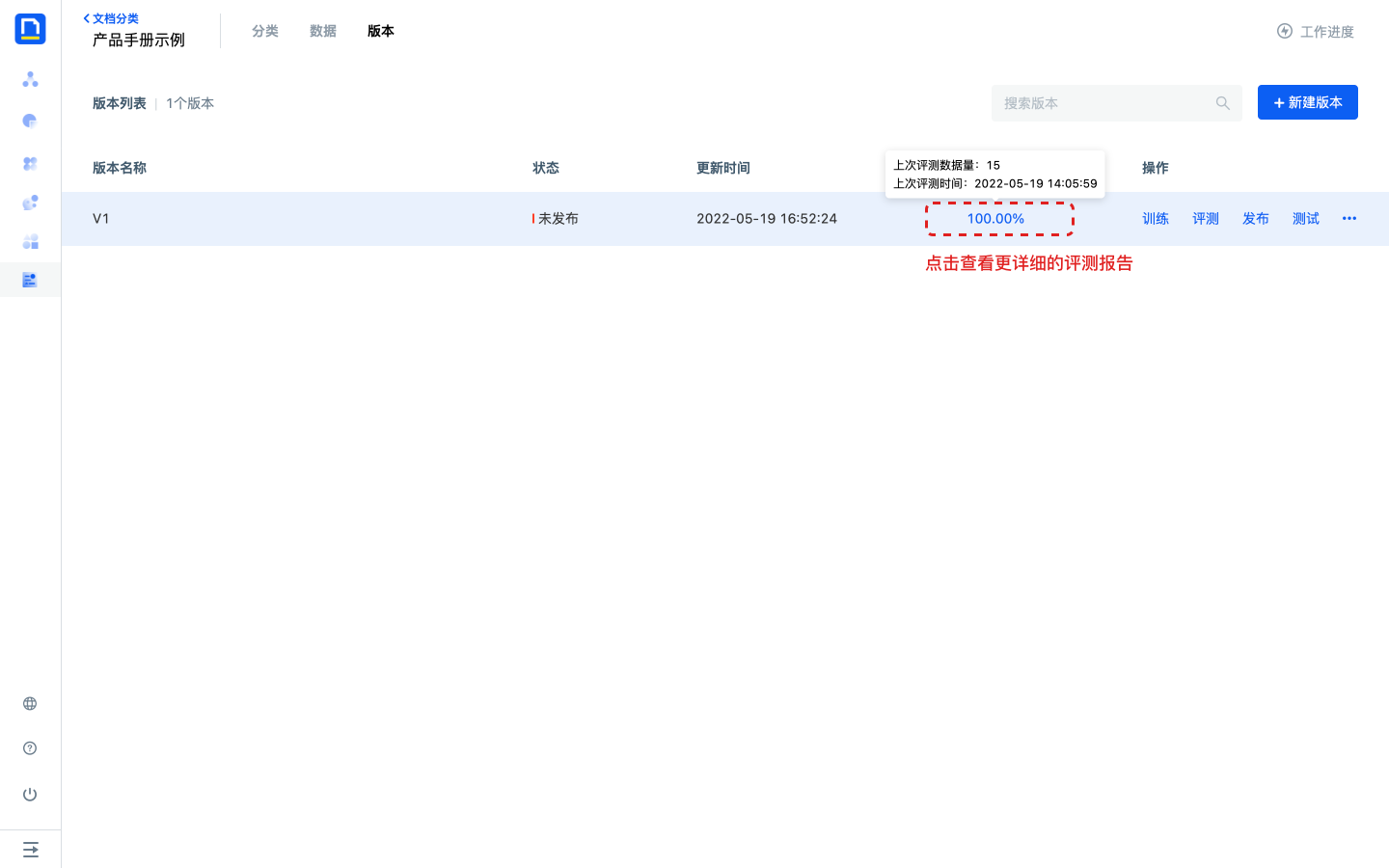
4)评测报告包含整体评测结果、基础信息以及每份文档的评测结果。
发布版本
1)点击工作进度中的第8步 发布,点击去发布,进入版本分页。
2)点击需要发布版本操作下的发布,将当前版本发布。
3)发布之后回到模型列表页面,点击模型的测试,测试效果是否满足预期。
- 也可以在发布之前,通过版本操作中的测试,直接测试模型效果
模型测试
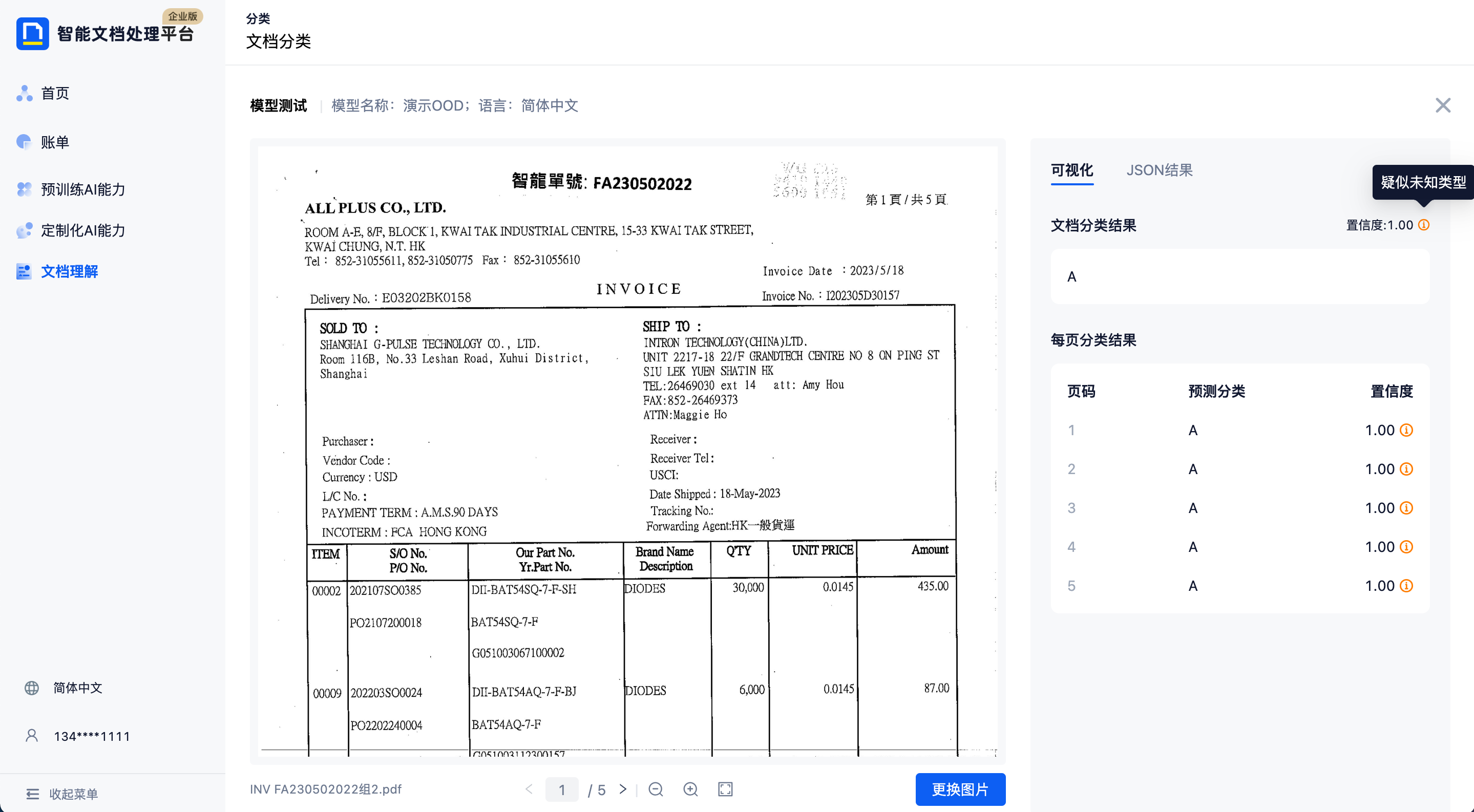
模型测试结果包含可视化结果和JSON结果:
- 可视化结果
- 分类结果
- 文档级别:对于任务文档的预测分类结果及对应的置信度
- 页面级别:当文档页数大于 1 时,模型还将提供文档中每页的预测分类结果,格式为:每页页码 - 预测分类 - 对应置信度。
- “疑似未知类型”提示
- 模型在除已设定的分类模型以外,会单独训练区分“已知样本”“未知样本”的模型,并在此模型的置信度>0.5时为分类结果打上“疑似未知类型”的提示标签
- 举例说明:图片数据中含有多种动物、难以枚举分类,通过“猫”和“狗”的分类模型,所有图片都会被分类到“猫”和“狗”类别中,但非“猫”和“狗”的图片将被打上“疑似未知类型”的提示标签,可利用这个标签作后置业务判断过滤,或增加其他类型图片的分类和训练集。
- 分类结果
- JSON结果
- 可通过JSON结果查看API调用返回的格式、结果,及分类模型测试的全部细节。
常见问题
文档分类与文本分类有什么不同?
1)输入不同
文本分类的输入是文本,如果要完成一个文档的分类,需要用户使用RPA自己搭建分类流程,先调用OCR识别,获取OCR识别结果,调用文本分类模型。如果遇到文档页数较多时,可能会超出文本分类的3万字调用限制,需要考虑的细节非常多。
文档分类作为一个文档的端到端AI能力,训练、评测、模型调用都是以文档为最小力度。
2)模型学习的特征不同
文本分类的智能模型学习的仅仅是文本语义特征,文档分类模型学习的是文档的语义特征和位置特征。