Tagging
This chapter will introduce: the role of tagging and how to use each function in it.
Basic Concept
Using the document function on the platform, we can tag documents saved in the document library, and then use these tags to improve the efficiency of document search, but in this basic operation, tag data needs to be created manually. In response to this, the platform provides tagging functions, users can use them to automatically generate tag data, and then realize automatic tagging operations.
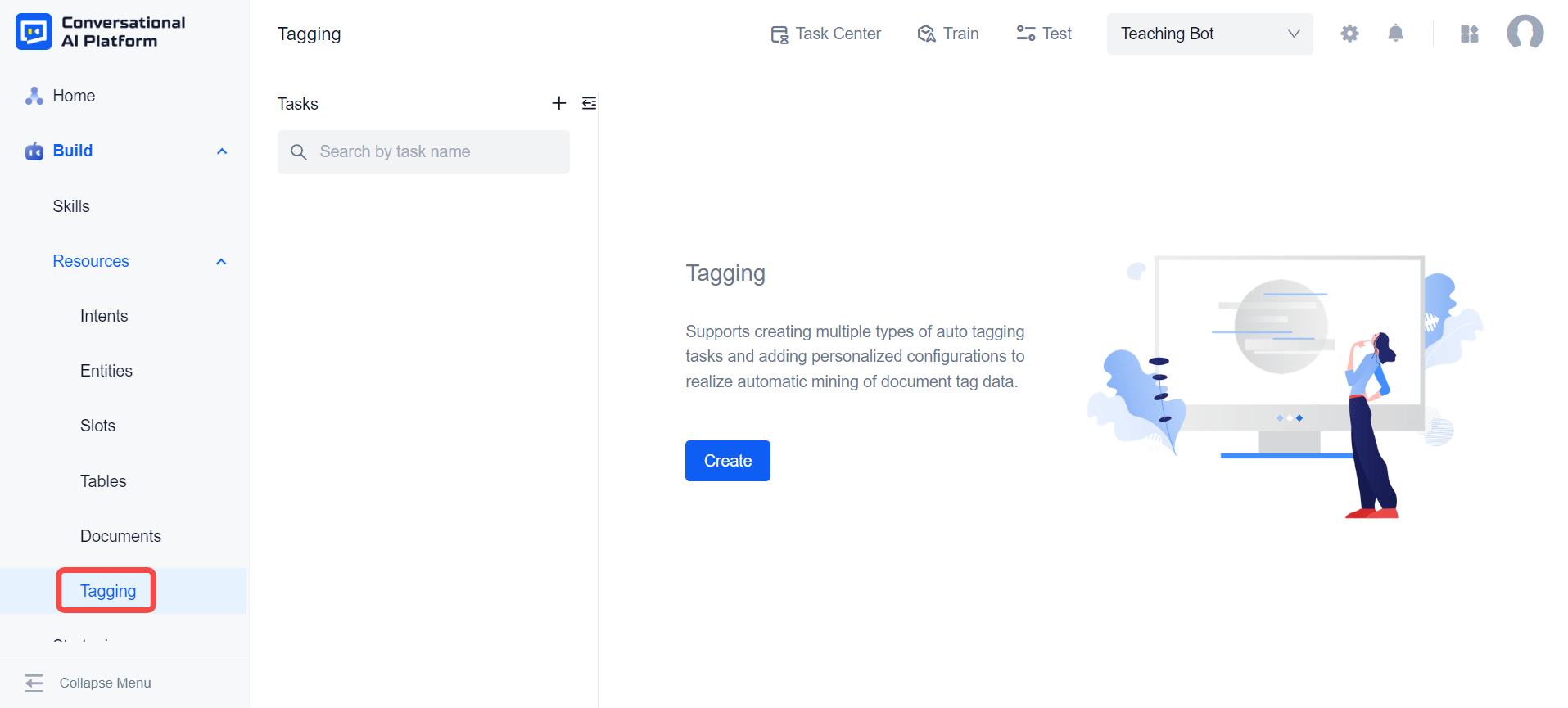
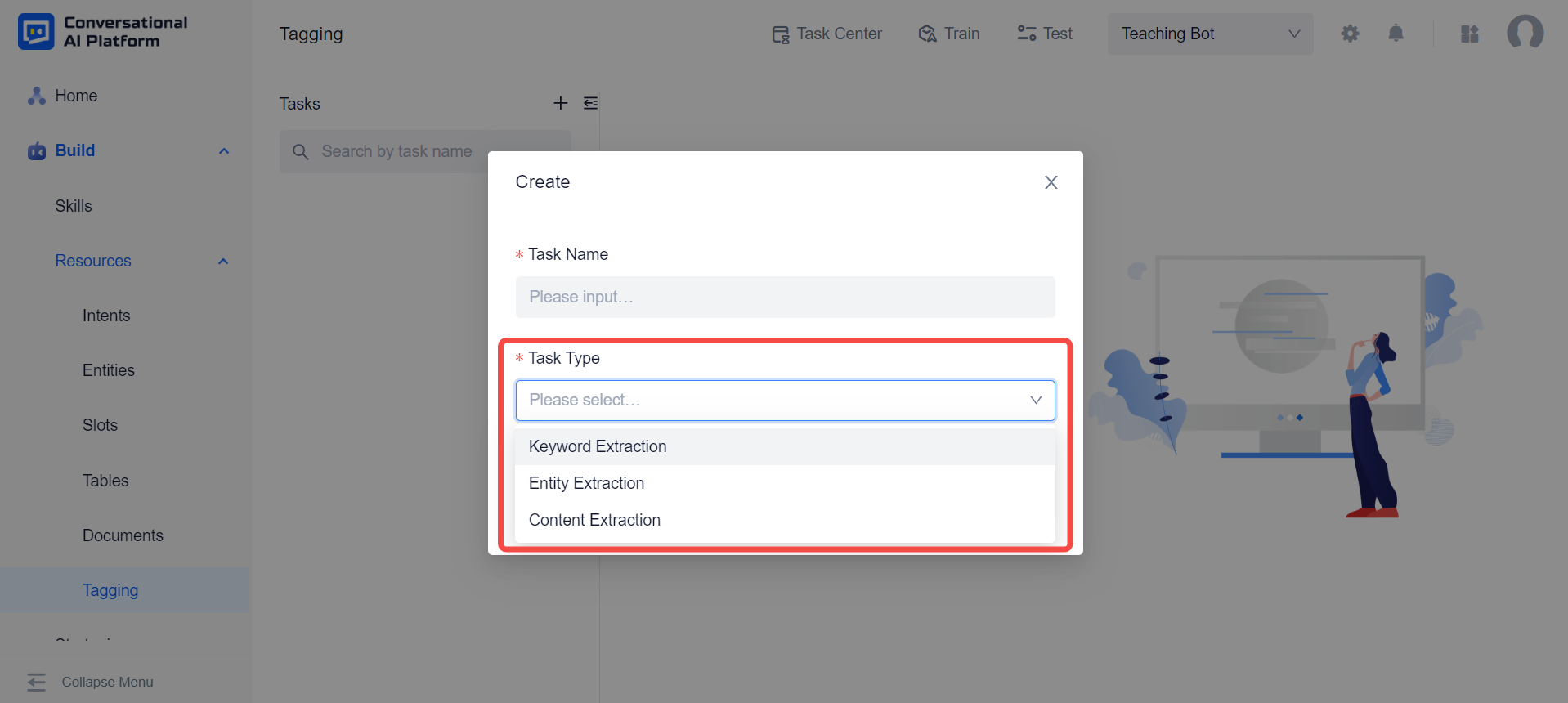
Using tagging functions requires us to manually create the task of tagging. On the tagging page, we can create different tasks as needed. Currently, the platform provides three tasks: content extraction, keyword extraction, and entity extraction.
note
Before performing the keyword extraction and entity extraction tasks on the content of the document, the content extraction task needs to be performed first.
Content Extraction
Using the content extraction function, we can extract the text content of the document in the document library and save it to the default label of Text, which is convenient for subsequent use.
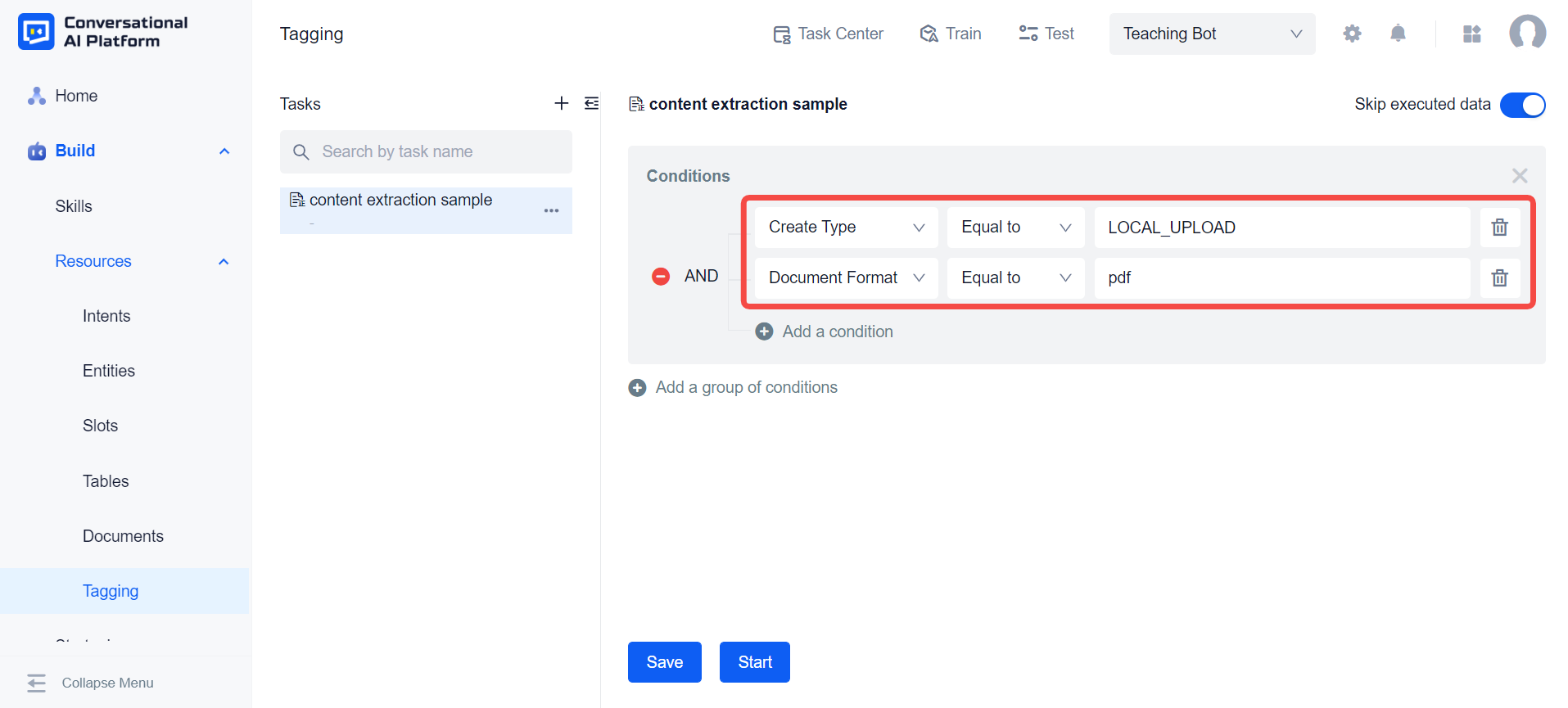
Create a content extraction task on the tagging page.
In this task configure the range of document data for which content extraction is to be performed. Currently, the content extraction task only supports documents whose Create Type is
LOCAL_UPLOADand whose Document Format ispdf, so the system will configure these two restrictions as default conditions. On this basis, users can add conditions to further filter documents and narrow the execution scope of the content extraction task.
note
At present, content extraction only takes effect for pdf documents with less than 500 words.
Using AND, and Add a condition, we can filter documents more precisely.
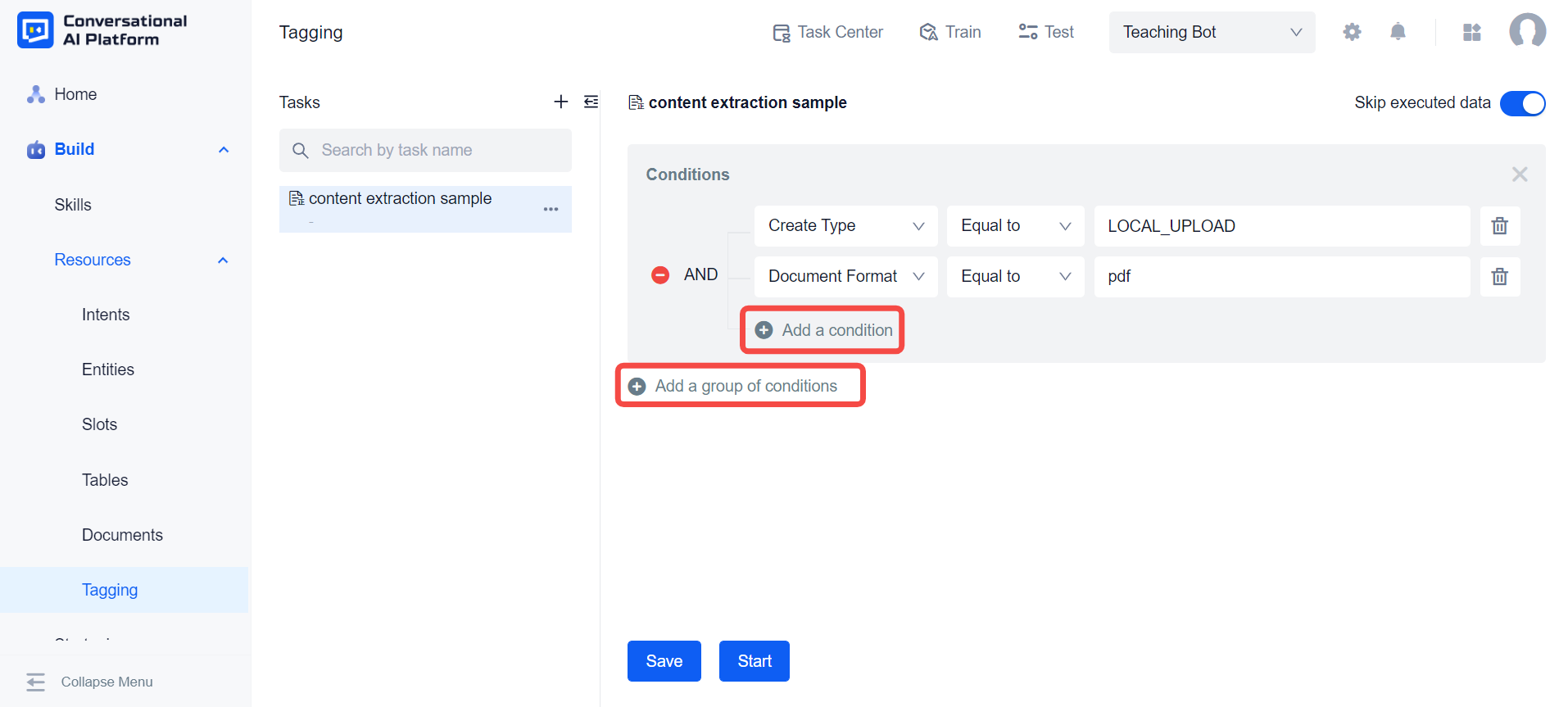
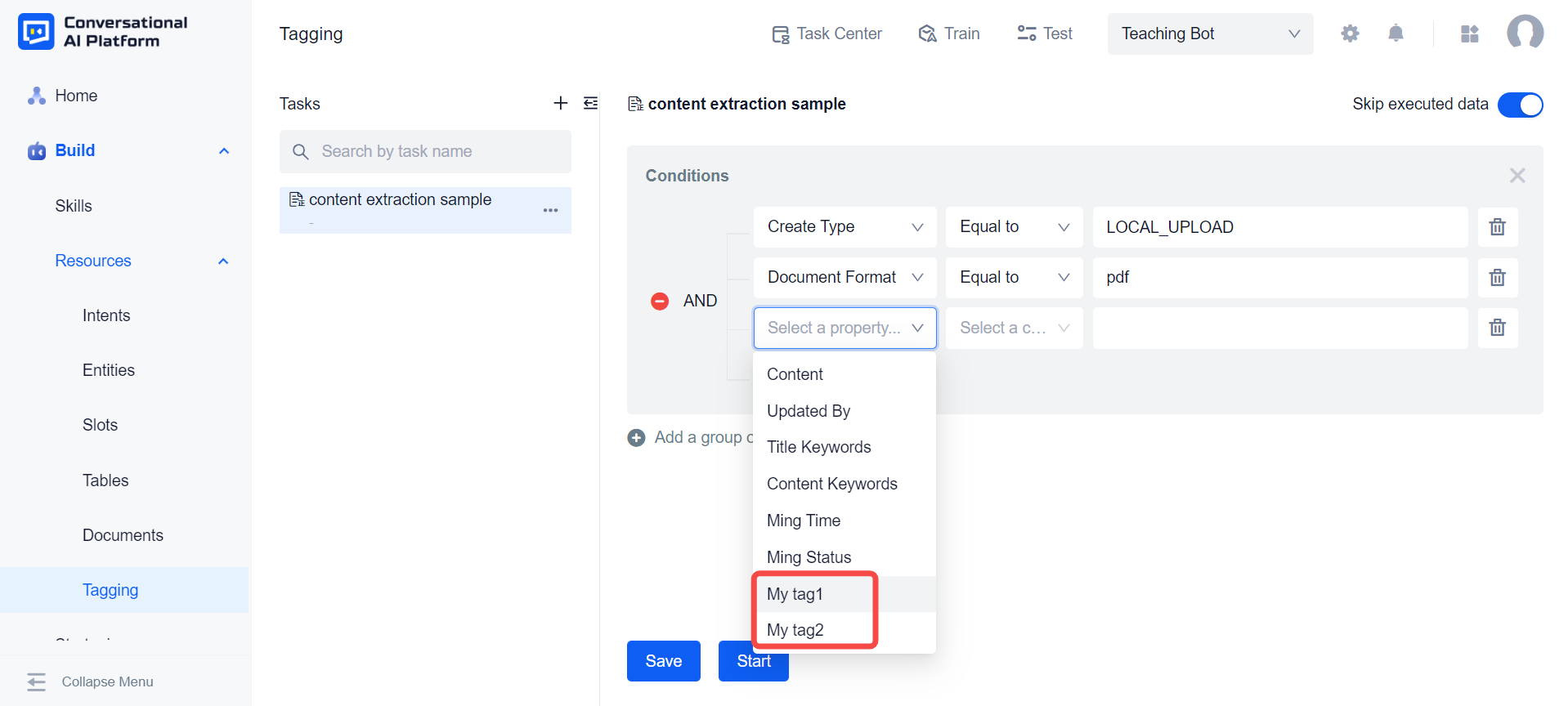
If we create custom tags inside the document library. These custom tags will also appear in the drop-down list provided by the system for us to set filter criteria.
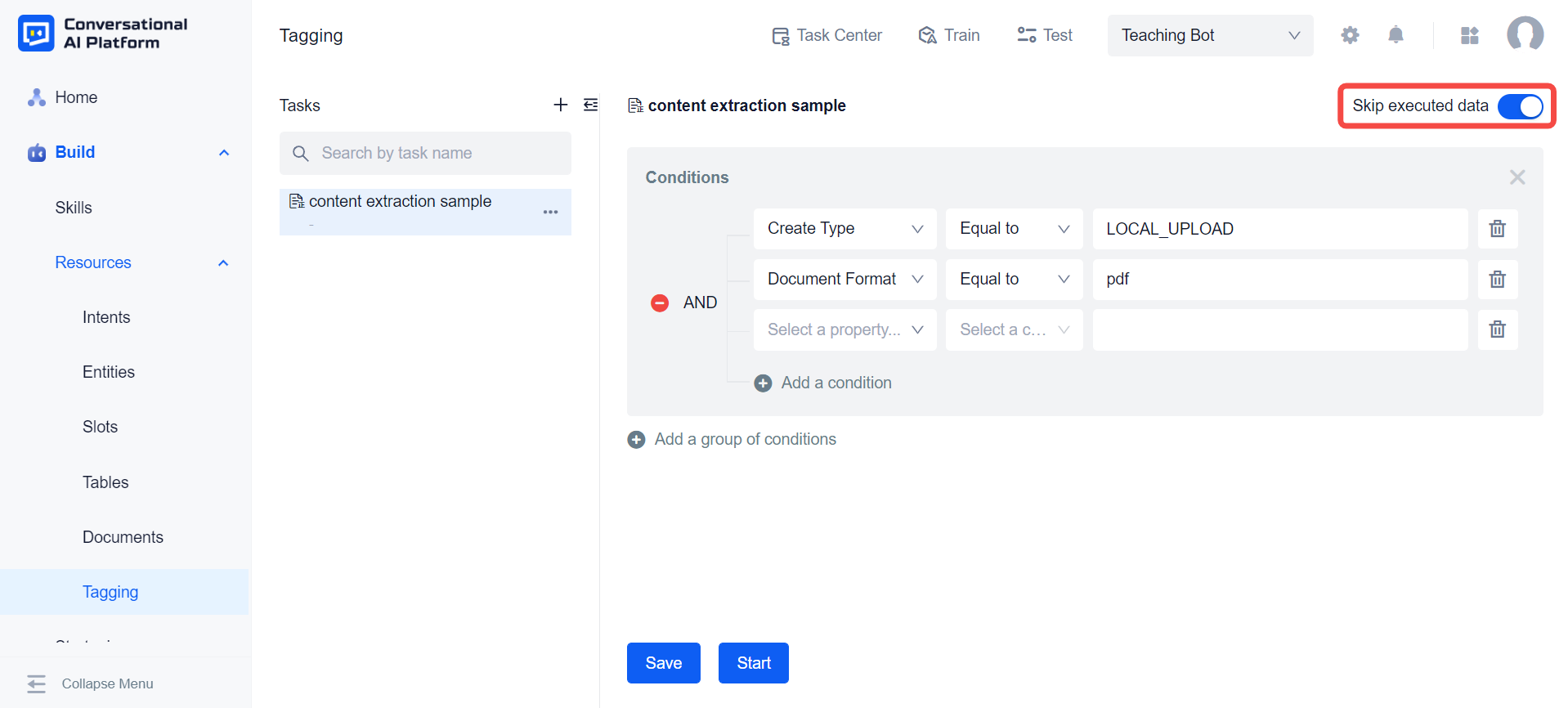
The Skip executed data switch at the top right is on by default, which means that if the task is executed multiple times, the documents that have already been executed will be ignored.
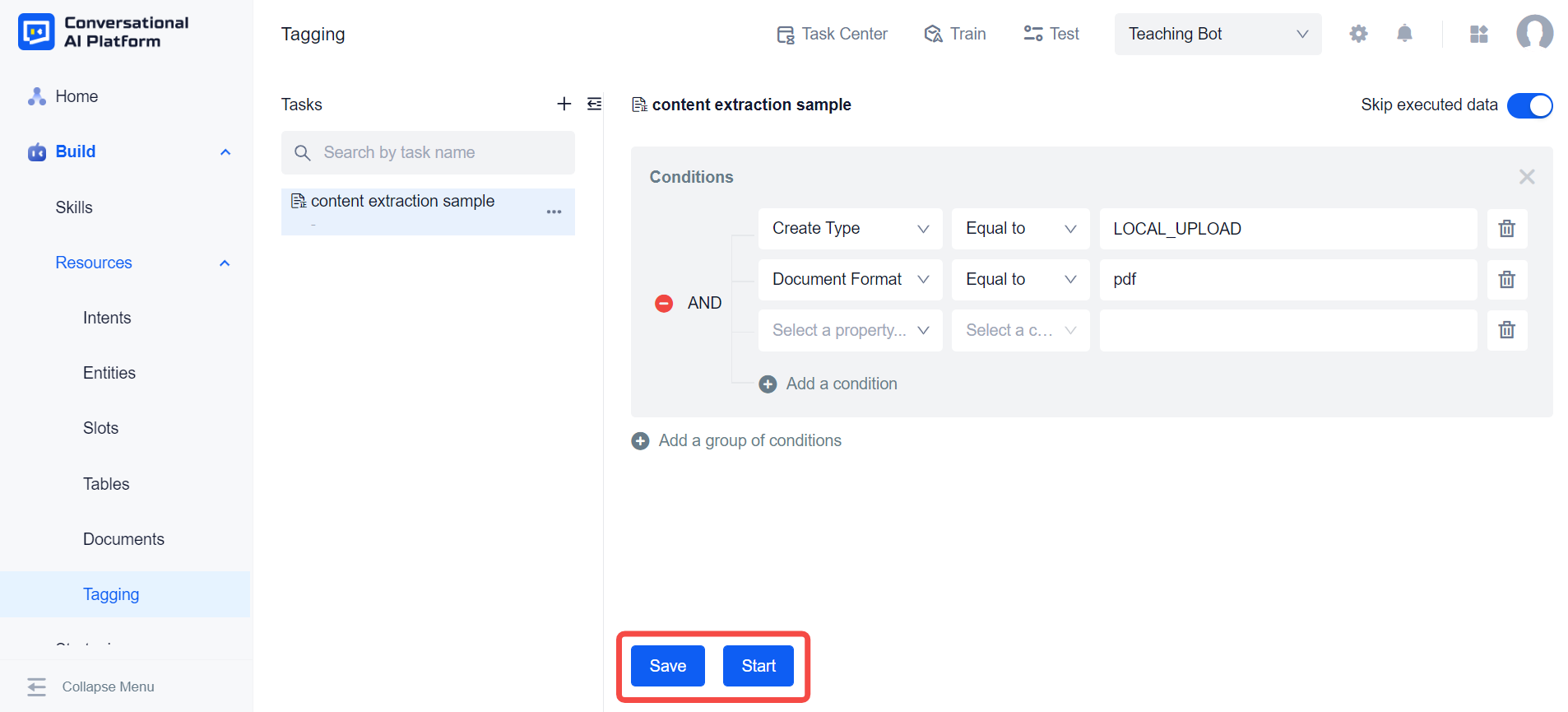
We can save the configuration to add more conditions next time, or click Start, the system will automatically save these configurations and start the content extraction task.
Keyword Extraction
The keyword extraction task supports automatic extraction of multiple keywords from the title or content of a document, and saves the extracted keyword results to the tags in the document library according to the rule configuration.
Create a keyword extraction task on the tagging page.
In this task, configure the range of document data to perform keyword extraction. The default tags and custom tags of the document library will appear in the drop-down list provided by the system, and we can configure it according to our needs. The keyword extraction task will only perform extraction operations on documents that meet these configuration conditions.
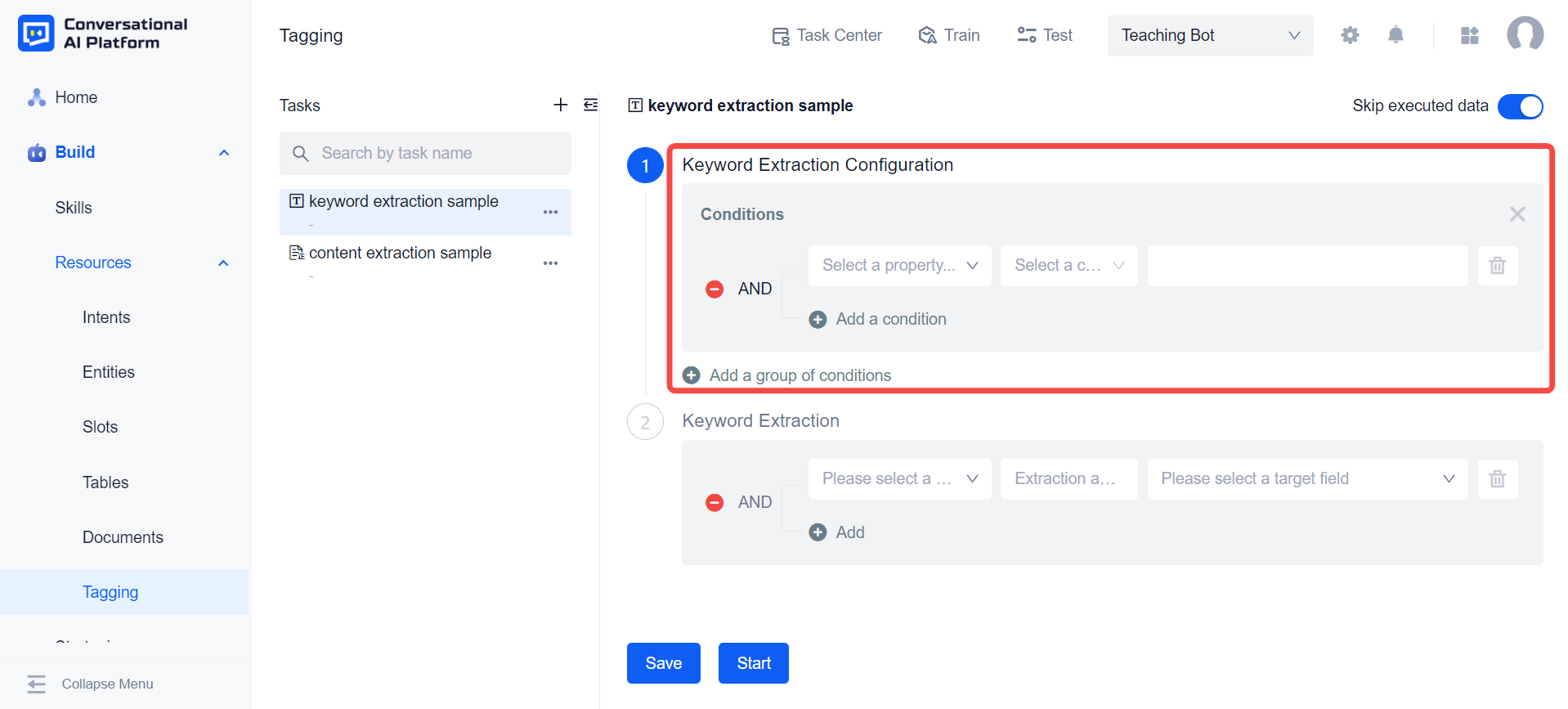
Configure the rules for keyword extraction. Currently, the system supports keyword extraction from the title or content of the document, and we can customize the maximum number of keywords to be extracted. If the engine layer's extraction result exceeds the user-defined number, it will rank all the results and return the topN keywords.
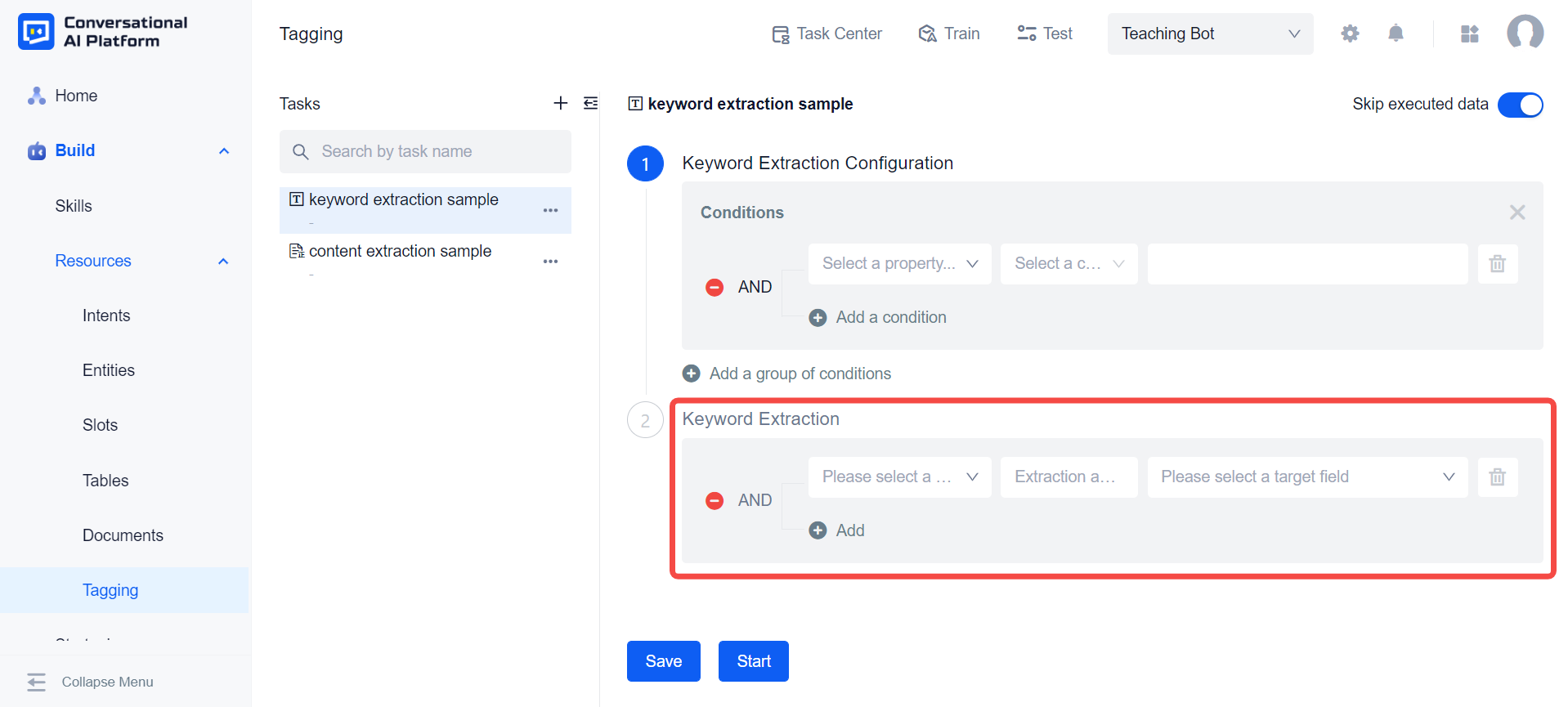
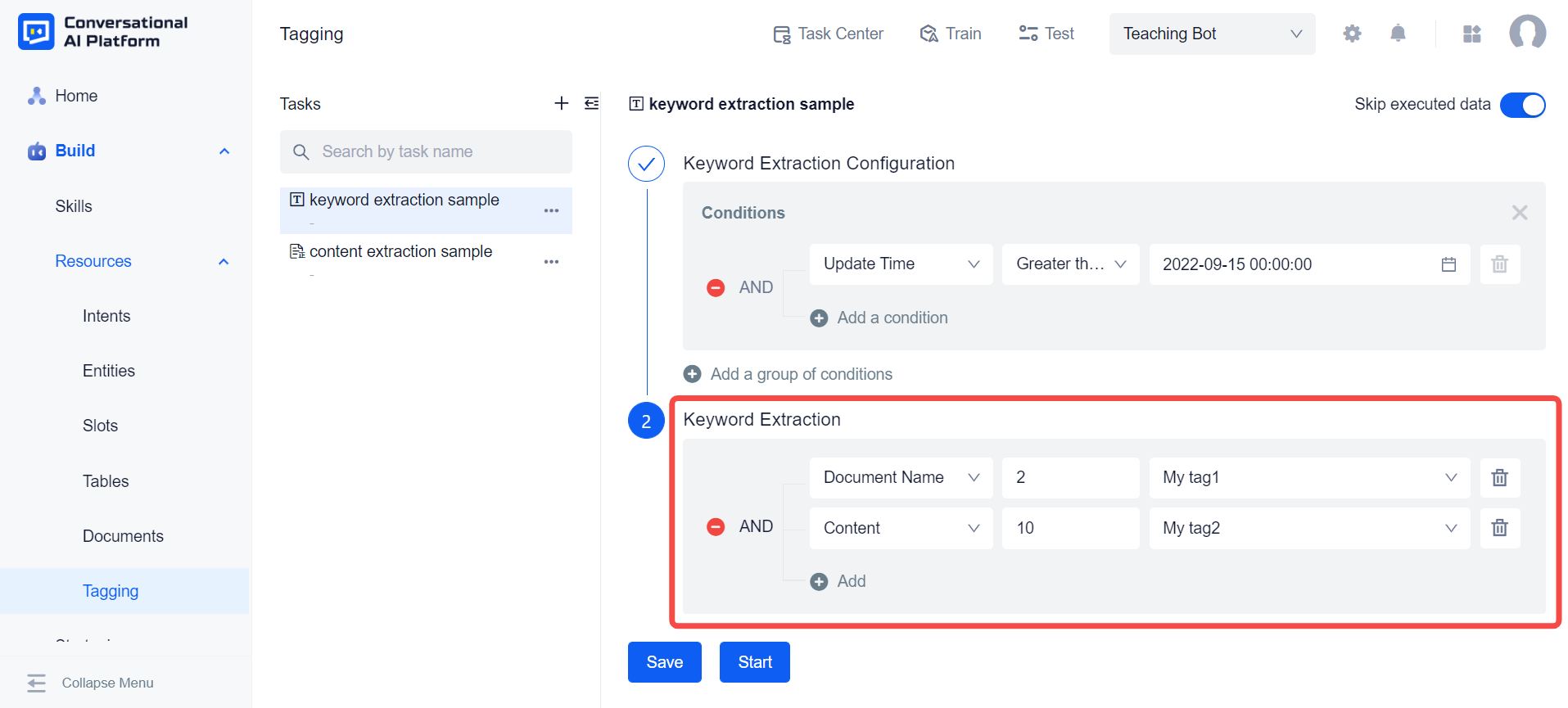
We can save the results of keyword extraction to the default tags Title Keywords or Content keywords provided by the system. Of course, we can also save the extraction results to our custom tags.
note
Keyword extraction only supports assignment operations on text-type tags. At the same time, if the tag is already associated with entities, keyword extraction should not be used for it. It is recommended to use entity extraction.
- After completing the condition configuration and rule configuration, we can save the configuration to continue adding more conditions or rules next time, or click Start, the system will automatically save these configurations and start executing this keywords Extract task.
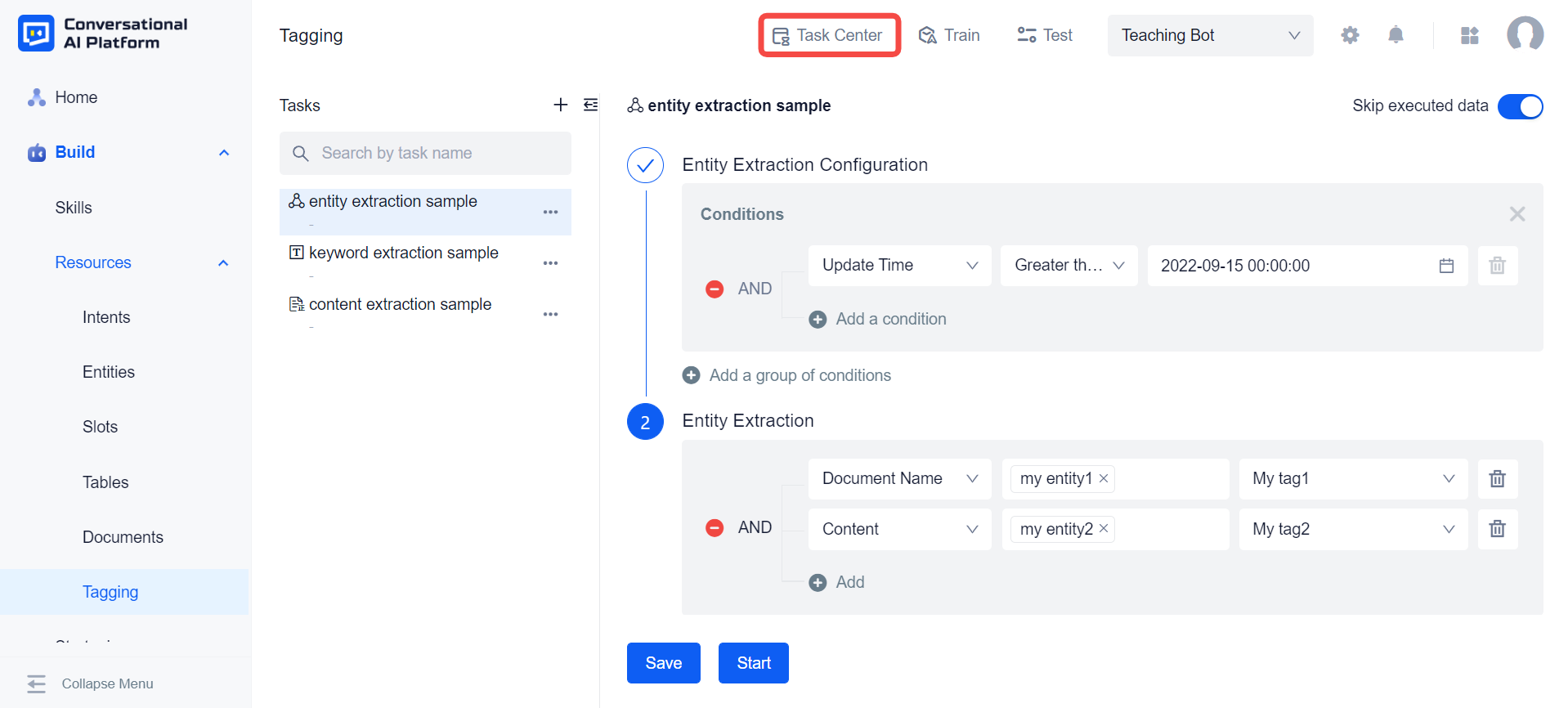
Entity Extraction
The entity extraction task can use the entity data in the thesaurus to filter the document, and then extract the entity from the document, and save the extracted entity result to the tag in the document library according to the rule configuration.
Create an entity extraction task on the tagging page.
In this task configure the range of document data to perform entity extraction. The default tags and custom tags of the document library will appear in the drop-down list provided by the system, and we can configure it according to our needs. The entity extraction task will only perform extraction operations on documents that meet these configuration conditions.
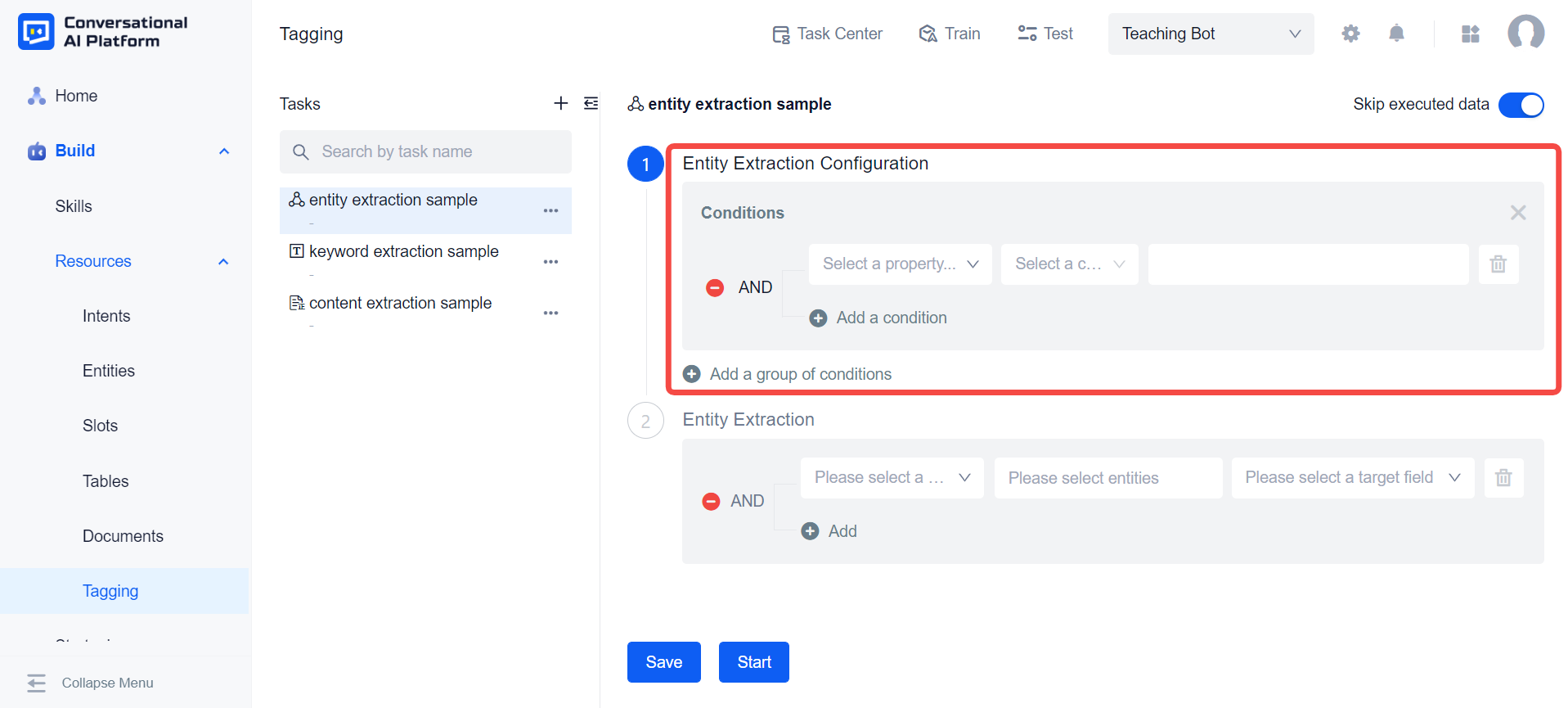
Configure the rules for entity extraction. First, you need to configure the object of entity extraction. The system can extract entities from the title and content of the document respectively. In addition, it can also extract entities from the results of keyword extraction.
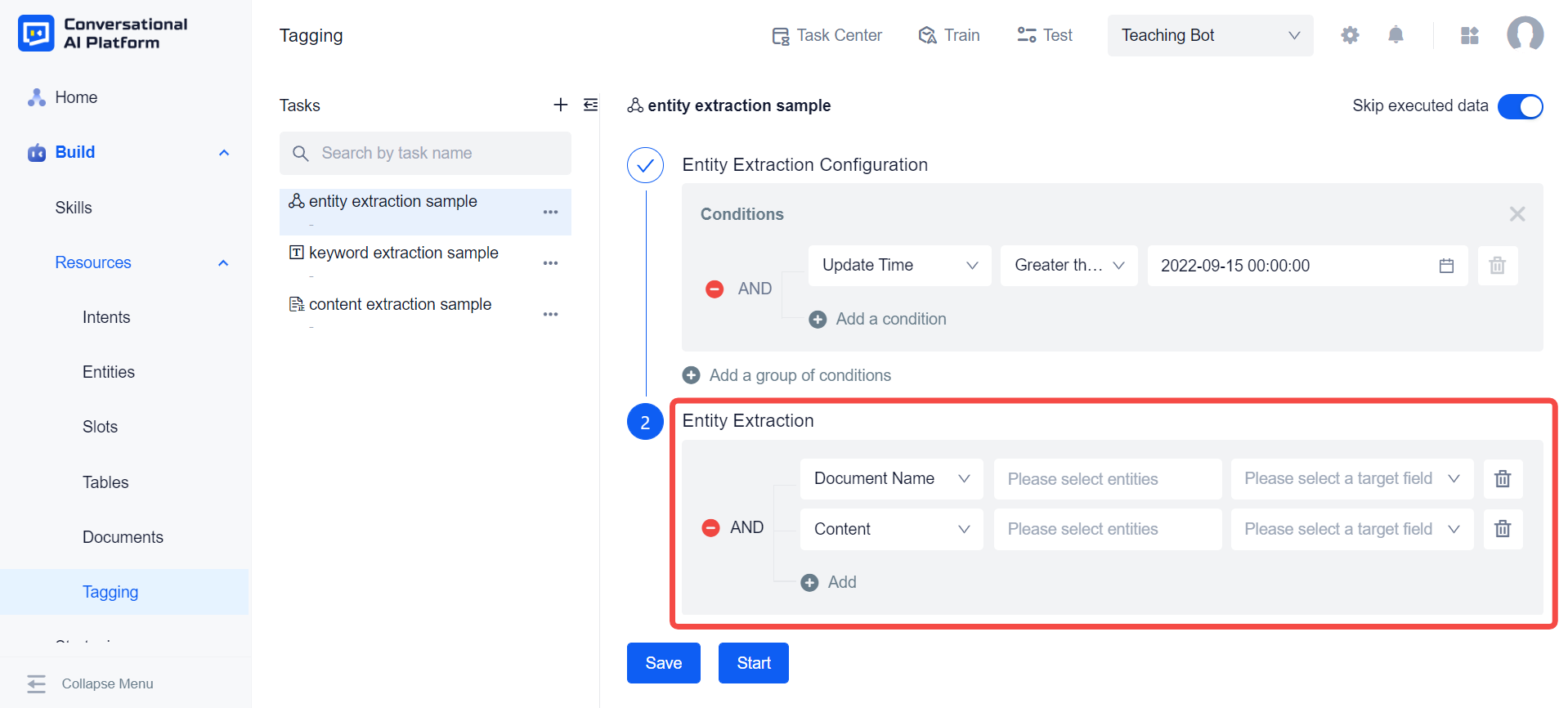
Then configure the storage location of the entity extraction result, where the location refers to the tag in the document library. If the tag as the target location has entities associated with it, those entities will automatically appear in the entity selection box to the left of the tag when the tag is selected. In addition, we can also manually select entities using the input association function in the entity selection box. The entity extraction task will use the entity data in the entity selection box (including the entity value and the synonyms) to match the document. If the match is successful, the corresponding entity value will be filled in the tag.
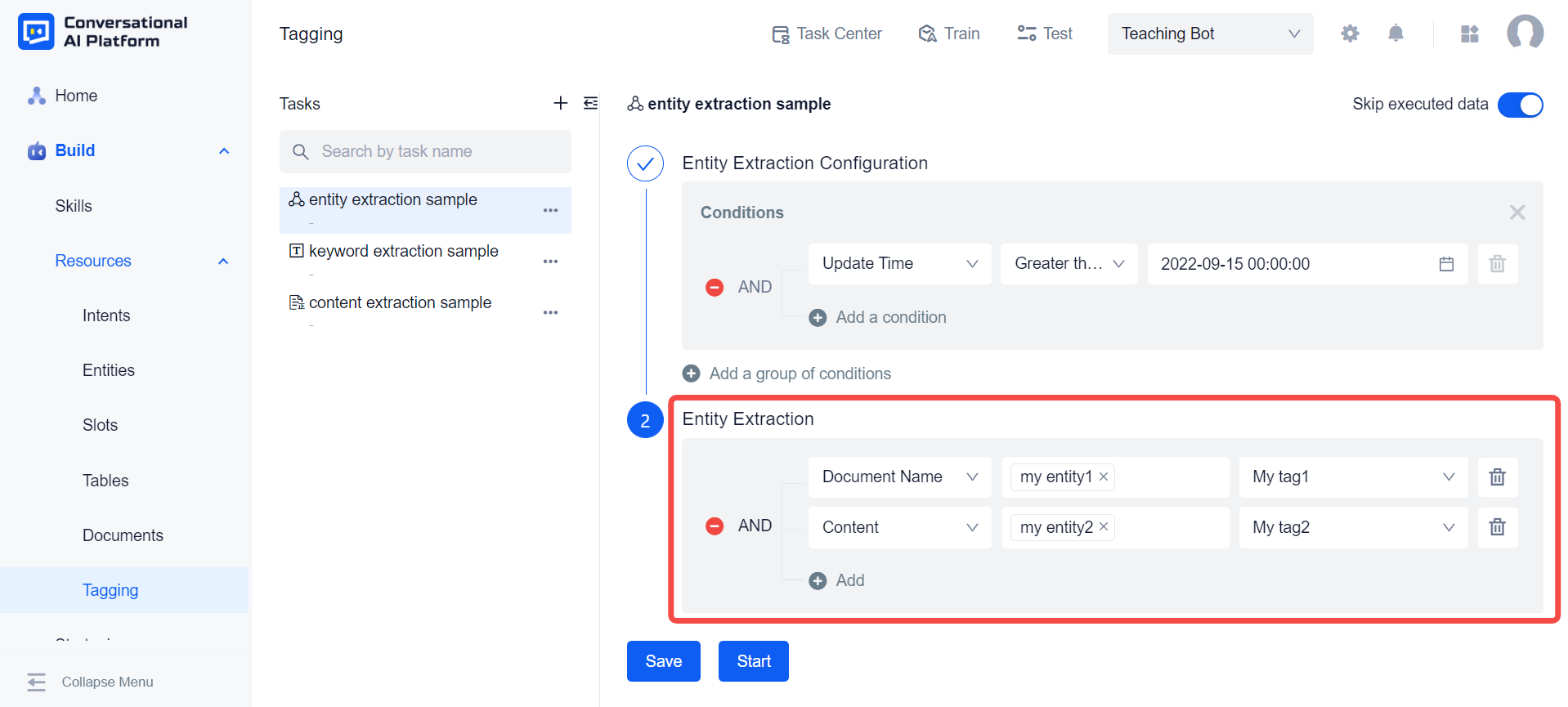
After completing the condition configuration and rule configuration, we can save the configuration to continue adding more conditions or rules next time, or we can directly click Start, the system will automatically save these configurations and start to perform this entity extraction task.
Task Execution
After clicking Start, we can view the execution status of the task in the task center. After the task is completed, the result data of each task will be filled in the tags in the document library according to the custom configuration. We can go into the document library to view, and conduct manual review or optimization.