Chapter V Launch And Optimization
4.1 Agent Optimization
4.1.1 Brief Analysis Of Intent Recall Logic
When the user asks a question, the agent needs to understand the semantics of the user's question, and find the corresponding answer response to the user from the knowledge base. Knowledge base can be regarded as the brain of dialogue, and the quality of knowledge base is very important to the effect of dialogue.
The knowledge base is composed of multiple knowledge points under different Category. When the similarity between the user's message and the problem in the database reaches a critical value - threshold (Y ù) value through a series of algorithm models, the knowledge point can be triggered. After processing the similarity, we get a value from 0 to 1, which is called confidence.
Through confidence, we can evaluate the degree of similarity. The higher the confidence, the more similar the user statement is to this knowledge point.
Let's think about it. The more similar the user's statements and knowledge points are, the higher the probability of feeling correct. On the other hand, if the confidence of user statements and all knowledge points is not high, it may be necessary to admit that the agent does not know the user's meaning for the time being, and the answer is No.
So at this time, the level of confidence can help us distinguish between response knowledge points or response don't know; If you want to response, you can sort it according to the confidence level. Which knowledge point do you want to response.
If response, we call it recall. Accordingly, the recall times / user questions are the recall rate; If the response is accurate, we will calculate the accuracy once. The accuracy rate is the number of accurate times / recall times.
Here is an example. Let's simulate it.
Suppose that in the past 10 years (we don't consider the problem that it hasn't been completed yet), a male ticket will be given a birthday gift every year. One day, she suddenly asked the male ticket: "remember what I gave to you on your birthday in the past 10 years?"
"Boyfriend agent" answered 8 answers, of which 6 were correct. Then our recall rate was (), and the accuracy rate was ()
A.100%,75%
B.80%,60%
C.80%,75%
D.100%,60%
Analysis: the recall rate is 8 / 10 = 80%, the accuracy rate is 6 / 8 = 75%, select C.
For the effect of the agent, in the system, we can control the threshold (Y ù) value to effectively avoid the response of the agent in the case of low confidence.
The threshold value is equivalent to the response control line drawn for the agent. If the confidence of all knowledge points asked by the corresponding user is lower than the threshold value, then the answer to the user's knowledge points will not be response at this time.
At this time, in order to make the agent have a response so that the user doesn't feel that the agent is broken, we need to add a fallback response. Fallback response usually replies response when the user asks a question and doesn't have the knowledge points that meet the threshold.
Fallback is equivalent to a state that the agent admits it doesn't know. It is set under the agent strategy. At this time, our scripts can also have various ways to play. For example, "I don't know this question yet, please ask xxx", "sorry, this question is transferred to the manual for you", "I haven't learned it yet, wait a minute, I'll consult the teacher".
4.1.2 Evaluation Of Admission Rate
.png)
On the agent platform model evaluation page, the model evaluation function can be used to quickly verify whether the results are correct.
.png)
You can choose to upload offline from the test set or extract data from the corpus for testing. Click upload test set to download the template, and its filling format is as follows:
| Test question (required) | Correct knowledge points that should be recalled (required) |
|---|---|
The test questions are the collected user questions. For the correct knowledge points that should be recalled, just fill in the standard questions of the corresponding knowledge points. If the knowledge points actually recalled by the user through the model are consistent with the filled knowledge points, the corresponding score is true. If not, it returns false.
Although it is said here that the threshold should be raised when there are more errors, and the threshold should be lowered when there are more fallback in the library, in fact, there are ways to determine the threshold, that is, after evaluation, to see what threshold the accuracy and recall of knowledge points can reach a balanced and acceptable state.
If several different agent modules are used, how to coordinate and cooperate among the modules should also be considered.
Tips: because it is slow to switch from the knowledge base to the document continuously, for the first annotation, you can refer to the three knowledge points given by the model evaluation for annotation, and the uncertain places will be unified into the knowledge base later to improve the annotation speed.
The verification method of model evaluation is to compare whether the recalled knowledge point standard problems are completely consistent with the filled knowledge point standard problems. Note that the marked results should be improved in time after the knowledge point standard problems are changed.
Note: Generally speaking, the accuracy increases with the increase of the threshold, but in terms of the accuracy of top2 and top3, this experience does not fully take effect. As the threshold rises, the originally correct second ranking knowledge evaluation score may not reach the threshold, so the corresponding number will be reduced on the numerator denominator.
We recommend that when calculating the recall rate, the numerator and denominator All should be removed and the unintentional recall should be carried out.
Customers often ask us why agent can't calculate the accuracy by itself. If a agent knows that it has made a mistake, it can theoretically make a 100% correct answer, which cannot be achieved at present.
To evaluate the accuracy of the agent, the real teacher has to approve the papers. On the one hand, you can use the online tagging function in the effect optimization. On the other hand, you can also download the message records in the session log for tagging.
4.1.3 Health Optimization Of Knowledge Base
If you have more than a few times of annotation adjustment experience, you will find that users often make false calls. False calls are mainly due to two problems: one is the lack of example, and the other is that similar problems are accidentally misplaced. However, there are often thousands of example in the mature knowledge base. How can so many example quickly find the wrong part of similar problems?
We have a knowledge base health to help us check and optimize the effect- Knowledge base optimization Under the menu.
Click "initiate detection" to detect the effective knowledge points. Note that the knowledge base is not allowed to be modified during the detection time~
After the test, if there is a big problem in health, it will generally lead to low scores. Some similar questions that need to be handled under the correctness of similar questions and the clarity of knowledge points can be clicked in for processing.
There are several situations in which these problems arise;
| Serial number | Possible situation | Problem performance | Solution |
|---|---|---|---|
| one | Similar problems are incorrectly classified to other knowledge points | A problem is supposed to be a similar problem of B knowledge point. As a result, it is wrongly placed in a knowledge point when building or maintaining the knowledge base. After this problem is extracted, the algorithm in the base recalls the correct knowledge point | Transfer this question to the correct knowledge point (or if this similar question should belong to a new knowledge point, create a new knowledge point) |
| two | Too few similar questions | That is, the a problem itself is relatively rare in the knowledge base, so we can't find a statement similar to it in the corresponding knowledge points | Ignore this situation or add relevant similar questions in the knowledge points |
| three | The quality of knowledge points is not high | A problem contains a large number of typos and other errors, because these typos lead to high word similarity with other knowledge points | Correct typos in similar questions |
| four | Similarity questions contain ambiguity | That is, the question a itself contains more than one intent, and the other intent contained in it causes the wrong call of knowledge points | Split this similar question into two different knowledge points |
| five | The knowledge points contain ambiguity or the granularity of knowledge points is too small | Because other knowledge points mistakenly contain a similarity question that originally belongs to a, which is particularly similar to a, a is called by mistake | Transfer the wrong problems in other knowledge points to A. if the two knowledge points can be merged from a business perspective, they can be considered to be merged |
| six | System word segmentation error | Because the system can't segment words correctly, the algorithm can't calculate the corresponding knowledge points correctly | Maintain domain vocabulary and its synonyms |
Optimize small cases
The user asked what the "agent response strategy" is. The knowledge points are correct, but the returned answer is not very correct, because we can judge that the answer is old and needs to be modified according to the name in the response. The second is that when the debugging agent is used to check, it is found that two knowledge points can be answered.
If there are two knowledge points with the same semantics, the corresponding similarity questions in one intent should be transferred in batch to the other intent by merging, and then the corresponding unnecessary intent should be deleted. When optimizing the answers of knowledge points, you need to add the answers again.
In addition, after the manual response, the user asked a new question, "what is intelligent response?" we found another question. What is the wrong call of intelligent response? The reason is that at that time, intelligent response was a new product function, and the knowledge points and answers had not been added, so there was a high probability of recalling other existing knowledge points. This knowledge point can be added and generalized in the later stage.
.png)
4.1.4 Example Learning
We talked about data statistics and calculation two days ago. If you have experience, you will find that many agent 'wrong answers are likely to recall the correct knowledge points in top2 or top3. Generally speaking, the confidence of this part of the problems will be relatively low in the evaluation of agent.
To sum up, if the score is not too low or too high, it is likely to find the correct knowledge points in top 3, and it is a lack of knowledge points / knowledge base.
To collect and deal with these user problems is to learn example.
One of the new knowledge learning ways of the FAQ dialogue is through example learning. After connecting to the online environment, when a new user problem comes, the agent cannot confirm that the similar problem will be put into example learning, and the machine automatically recommends 1-3 closest knowledge points.
Tips: if there is a big gap between the problem warehousing time and the knowledge base structure in the official marking period, you can click the refresh button, and the system will re recommend the closest knowledge point.
Click "merge with this knowledge point" to enter the knowledge base as a similar question of the corresponding knowledge point. If you want to modify the question, you can click the Modify button above.
.png)
If you know which other knowledge points this problem belongs to, you can "merge it into the existing knowledge points".
.png)
If there is no corresponding knowledge point in the existing knowledge base, you can click "new knowledge point" to add it. If the question is not available, you can directly "delete"; For questions that cannot be answered, select the unintended graph knowledge points that are merged into the existing knowledge points. Similar questions in the unintentional diagram knowledge points will not appear again in the example learning list. If it is determined that all similar questions are of little value, you can also click the "empty questions to be reviewed" button and operate carefully. Note that it cannot be recovered after clicking.
.png)
When building the knowledge base, we can also import the previous corpus to be reviewed, so as to quickly cover other questions with existing knowledge points. You can also filter the corresponding similar questions according to the time of adding similar questions, similarity scores and knowledge points.
.png)
You can also use view by knowledge point and view by intent to quickly add users in batches. The operable parts are the same.
4.1.5 Proper Nouns
.png) If it is found that the recognition effect of agent on a certain word is not good enough, proper nouns can be added to teach agent how to correctly recognize such words. For example, in the professional field, we can add Bordeaux to improve the recognition effect of agent on Bordeaux wine.
If it is found that the recognition effect of agent on a certain word is not good enough, proper nouns can be added to teach agent how to correctly recognize such words. For example, in the professional field, we can add Bordeaux to improve the recognition effect of agent on Bordeaux wine.
If a word has a known synonym, it can also be added. For example, in the banking scenario, the Agricultural Bank of China will also be called Agricultural Bank of China, Agricultural Bank of China, etc. You can click "add proper noun" or click the triangle below the right of the new synonym to upload synonyms in batch.
4.2 Agent Configuration Guide
In the actual construction process, we should pay attention not only to the actual effect of the knowledge base, but also to some aspects of customer experience to configure We also need to understand that we can configure this part in Dialogue building - response strategy Find;
4.2.1 Experience Version Web Page
Experience page It is a real and formal channel for experience, which can support all our capabilities. The focus is to give customers an out of the box and complete experience without showing the details of agent operation.
The test conditions of all experience agent are included in the message statistics, Task collection and other statistical indicators, which conveniently gives us a way to experience the capabilities of all agent.
.png)
In some simple scenarios, using the experience page can achieve the results we want. Even if you want users to scan the code or click the link to enter the dialogue, you can share the experience page directly to users as a channel.
The experience version web page supports modifying "agent name", theme color, customized agent avatar, user avatar, portal icon, portal icon size, avatar shape, dialog bubble style, session window height, etc.
.png)
The experience version web page supports the ability to collect satisfaction, display answers in various forms such as text, card, video, audio, text, etc., and give users corresponding response as soon as the event message is entered.
If it is other requirements, you need to customize the display and ability of the front-end page.
Experience Optimization Configuration
1. welcome message configuration. In fact, official account pays attention to response, and the automatic welcome message of customer service is similar.
.png)
We create a welcome language knowledge point and put it under the greetings Category, which can be configured through dialogue building - personalized experience - user event - entry event;
.png)
2. Input Lenovo to make it easier for users to ask questions. Go to [channel settings - websdk - function settings] to find and input Lenovo for setting;
.png)
.png)
3. set similar knowledge points to let the agent give more relevant questions to ask, which can be found in [dialogue building - response strategy - agent strategy];
.png)
Some knowledge points don't want to be recommended. Just don't configure them as recommended Category.
4. To answer whether human-computer cooperation is needed, you can turn to the manual scheme in the next section;
5. it is inevitable that the agent cannot answer. How can we properly express that the agent cannot give an accurate response? At this time, we need a fallback response (supporting response) to deal with this situation;
.png)
The following points are generally considered in fallback scripts:
Agent at night, manual during the day: I don't know yet. There is manual customer service from 08:00 to 18:00. Please ask again at that time~
The agent response that the manual personnel would deal with the fallback regularly every day: I have written this down. Would you like to leave your contact information, and the staff will response to you later.
All All agent are on duty, and there are no human beings: I don't know this problem yet. Why don't you ask me again in a few days? If you are in a hurry, please call our manual service hotline 400-xxx-xxxx.
5. Enable the setting of similar knowledge points, which will recommend some matching knowledge points to the answer, increase the probability of hitting the correct knowledge points and improve user satisfaction;
.png)
6. add necessary greetings and response to take care of the user experience.
Of course, the agent has many other configurations, such as delayed sending, which can appropriately slow down the message sending speed of the agent. We can choose as needed.
4.2.3 Transfer To Labor Scheme
Obviously, the current agent is still in the stage of catching up with the manual. In order to better user experience, sometimes we need to switch to manual processing at the right time. At this time, we need to arrange the appropriate Switch to manual strategy (it may also be day and night cooperation, manual work during the day and agent at night);
Most projects are likely to have the cooperation of human and agent, so we must pay attention to how the human and agent cooperate and what the overall business guidance idea looks like in the process of building.
- All use agent
Pure agent response is the default configuration of agent (intelligent response / designated priority / full response, automatic to manual shutdown). Generally, remember to configure fallback response; Of course, at this time, we need to consider how users of agent problems feed back and whether they need to cooperate with a problem to collect Task dialogue scenarios.
- Agent + Manual
Do you prefer the customer to say that only when you transfer labor can you transfer labor, or take the initiative to transfer labor when the confidence is low?
How to realize the transfer of labor, and whether the test of transfer of labor is passed?
If we use the real-time communication module, the agent will be switched to manual work when it is fallback. It needs to turn on the response strategy to automatically switch to manual work. At this time, users can access fallback through the real-time communication page. It is necessary to consider whether agent response is required when switching to manual work.
- Agent assisted manual answer
How to recommend answers?
Does it support the customer service side to input questions and call up answers?
If you use the Wulai instant communication module to All manual response, and the agent only reminds you, you need to select the custom mode in the response strategy and select no response for the response method.
.png)
It should be noted that if manual response is required, we need to configure the personnel settings in the lower left corner, online and prompt, so as to successfully access the user. If it is used by the customer service post, you need to open and keep it on the instant communication page, so that you can hear the prompt tone in time and receive users.
.png)
According to different stages after construction and different application requirements, we can choose different labor transfer schemes, such as:
In the mother baby scenario, the accuracy of the response is required to be high, and the service itself also focuses on manual services. At this time, it is usually appropriate to use the agent assisted manual scheme.
If you want to start the intelligent service with a small amount of setup, you can also use the agent assisted manual mode to go online first, which has some advantages. For example, in the process of setup, the service personnel can click and send the answer automatically prompted by the agent, which reduces the process of manual search, back translation and input of the answer, and the efficiency will be greatly improved; If the agent response incorrectly, it should use other knowledge points for response. You can enter the corresponding knowledge point name, and the agent will automatically bring out the answer. You can also click the answer to edit the answer and then send it. In this case, we can compare the difference between the built-in answer of the agent and the manually edited answer, so as to better optimize the response effect of the agent.
More projects choose the time of fallback, some knowledge points, and the transfer of Task to manual work, which is a typical mode of agent + manual common service. Sometimes, some other conditions will be added to improve the user experience. For example, the user needs to transfer the same knowledge point to labor three times in a row.
Some projects without customer service posts at all, or those without customer service reception at night, will use the pure agent reception mode, and some will choose the next day to optimize the response of the previous day to ensure the relative timeliness of the answer online.
.png)
4.2.4 Practical Experience Of Special Message Types
If pictures, articles, videos and other types of response messages are configured, it is also necessary to test the sending order of pictures and words under the channel. Can the expected effect be achieved? There are the following points to note:
Sending order of pictures and words;
Whether the picture can be enlarged or reduced, and whether the experience is qualified;
Whether the video, article and other response forms can be played normally;
4.2.5 Targeted Optimization Of Online Channels
There may be many ways to launch agent online, such as cutting traffic proportionally or launching separately by channel. Of course, some manufacturers adopt the strategy of launching by region. For this launch strategy with channel characteristics, we can do some more checks for better results.
1. whether there are differences in channel knowledge points. If the customer service personnel of the corresponding channel can specially ask them to ask some questions about users' common problems and take the original corpus of the corresponding channel in the early stage for a small-scale FAQ test, some knowledge points of channel characteristics may be covered up;
2. test the impact of some dialects on the agent. In some scenarios, the user's statements may have an impact on the recognition effect of the agent. For example, the new house without decoration is called rough house in the north and Qingshui house in some cities in the south.
Feature Topic 4: Custom Answer Template
In the dialogue message, in addition to sending text, pictures and other message types preset by the platform, the agent may also need more rich responses, such as small cards and other components supported in different channels:
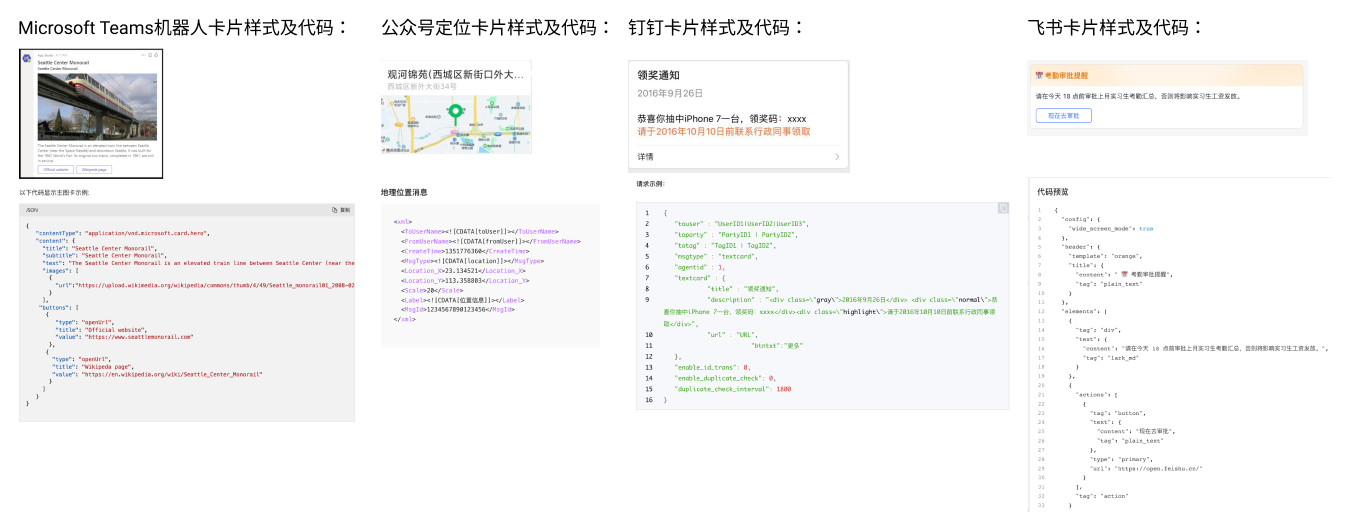
In the private deployment version, in order to provide more personalized customized content, the answer template function can be used. In the process of use, it also supports the reference of the slot attribute.
Custom answer Similar to the above components, when the agent needs to response to a special message (non text, picture and other preset message types) in the dialogue, the trainer can configure the response content by using the self-defined answer type edited in JSON format provided by the platform. The agent will directly send the content of the customized answer.
Response template Each type of customized answer has a unified template. The platform provides the ability to maintain and edit customized answer template. After maintaining the customized response template of various components, the trainer only needs to reference the template and change the key fields to complete the customized answer configuration.
4.2.6 Agent Human Setup And Greetings
Before the agent goes online, we should properly take care of the user experience in the case of testing functions, and add some greetings, such as Hello, who are you? Thank you for your knowledge. If there is a strong demand, it can be further enriched. This piece of content is also very rich. The required knowledge needs to be configured in combination with the brand image. It will not be described separately here.
4.3 Agent Online
4.3.1 Functional Integrity Test
Functional integrity test actually refers to the joint commissioning test before the launch, which is not called UAT test. During the joint commissioning, you need to ask all channels, all user roles and all operations to see whether the return meets the expectations.
After the test is completed and signed for confirmation, it can be officially launched.
4.3.2 Solutions To Some Common Problems During Launch
Here we would like to emphasize some problems that you may find after you go online again. When are these problems still very common? Of course, in the previous talk, we have All talked about them. Here is a concentrated lecture.
- Welcome message: manually set recommendation related questions, automatically recommend similar questions, transfer to manual, fallback response, input prompt, satisfaction, etc. if there are problems, please adjust them in the corresponding configuration section in time;
- Timely observe whether the user's response and feedback are consistent at the initial stage of launch and adjust them in time, mainly in the following aspects:
- High frequency questions are not covered → new knowledge points or similar questions are fully tested with historical corpus before going online
- Users like to ask questions with keyword → add keyword or knowledge points
- Question coverage of specific channels → new knowledge points or similar questions
- High error probability of confusion between user related problems → check the homing of similar questions. If there are still problems, solve them through sentence patterns or related entity
In addition, after the launch, it is necessary to study similar problems, FAQ and Task evaluation in a timely manner, and deal with the problems found in a timely manner. For more operation problems, please pay attention to the operation guide of Wulai agent.
4.3.3 Transfer Of Knowledge Base
The basic version and professional version of Wulai support one click Copy of agent. Administrators can copy with one click when agent is managed and set up agent. This function is very useful when creating a test environment. We can easily use this function to create a usable test environment agent.
.png)
When the knowledge base needs to be migrated when it is transferred to private deployment, it can be exported from the drop-down triangle of the new knowledge point.
You also need to refer to the following list for transfer.
| project | matters needing attention |
|---|---|
| knowledge base | Note that the length of standard questions and similar questions of knowledge points shall not exceed 100 characters. Special characters such as "\" shall not be included in standard questions. Repeated similar questions inside knowledge points will be automatically removed during import. (also note the answer picture, effective status, associated entity, associated similar question, to be reviewed, no intention) |
| Category | Any two cannot be repeated. The text cannot contain "/". The spaces before and after the Category will be removed |
| Keyword rule | Trigger word, time period, response statement, trigger priority |
| set up | Self set entity information, proper nouns |
Precautions during transfer:
First, the maximum export limit is 4000 similar questions for a single knowledge point in a knowledge base, but there is a limit on the number of words when exporting excel, that is, excel itself does not support a single cell exceeding a certain number of words, so similar questions exceeding the limit of words will be truncated. It is recommended that similar questions not exceed 1000 similar questions.
Second, for the transfer of online projects from a knowledge base to B knowledge base, refer to the following steps:
The first step is to clear the original knowledge base in project B. some non business knowledge base contents may be left due to pressure measurement and other conditions, which need to be cleared and checked with reference to the above transfer matters;
Step 2: export the ineffective part of project a knowledge base to project B knowledge base, and set the ineffective status of the imported knowledge base according to Category;
The third step is to export the effective part of a knowledge base and import it into B project knowledge base;
The fourth step is to transfer other parts with reference to the transfer items;
4.4 Brief Description Of Test Statistics
4.4.1 Overall Indicators
When customers need data, we are often asked what is the meaning of the conversation? Why are sessions and messages inconsistent?
A session is a conversation record of a complete context between the user and the service personnel (manual or agent). If the user does not speak for 15 minutes, it will be regarded as a session.
Therefore, sessions are user messages counted according to this period of time. Naturally, the conversation volume is not consistent because the statistical period is inconsistent with the message. In addition, in the field of conversational agent, a round of dialogue usually refers to the user saying a word to the agent.
What's the difference between total conversation and effective conversation?
Usually, we don't need to analyze the conversation in which the user doesn't speak. This kind of conversation is a non effective conversation, and the part excluding the total number of conversations is a valid conversation. But what conversation is it when the user doesn't speak?
When browsing the website, we will find that some web pages have pop-up windows. When the pop-up window opens the dialogue, it gives the agent an entry event. When the agent receives the action of entering the event, it begins to prepare for response. However, only twoorthree of 100 people will talk with the agent. Then these two or three are effective conversations, and the others are included in the total conversation, but they are not included in the effective conversation.
If the statistical data is abnormal, we should pay attention to it in time. Generally speaking, it may be that the operation has made activities and promotions.
Conversation we can Session log Check. The operation is very simple. You should use the search in the message record.
4.4.2 FAQ Indicators
From Use of knowledge points In, we can see the recall of statements in the simplest way~~
In general, we will set the FAQ dialogue as the last part of all other dialogues. If the FAQ can't response, the whole agent will fallback. At this time, for FAQ, if other agent are not recalled or other agent quote FAQ, the number of messages received by FAQ is counted. This number of received messages is the number of user conversations in the message record, excluding event messages.
Let's take a look at the description of the indicators:
Number of recall knowledge points: the number of times the FAQ agent is requested and response is given.
Times of triggering unintentional graph: the times of triggering unintentional graph knowledge points in the knowledge base.
Recall rate = Times of recalling knowledge points / number of messages received - times of triggering unintentional map.
Therefore, in the calculation of recall rate, the numerator and denominator all remove the number of unintentional images triggered.
Here, we focus on the recall rate index of knowledge points, and pay attention to it in time when the recall rate fluctuates greatly. This is likely to be due to the recall fluctuation caused by new activities, so we should intervene in time.
Secondly, pay attention to the situation of popular knowledge points, especially the answers to these knowledge points.
Keyword usage is similar to our concerns.
4.4.3 Task Indicators
Task indicators mainly include intent triggering, unit status and conversion rate analysis. Here we focus on conversion rate analysis. Through the conversion rate analysis, we timely find the nodes that have a great impact on the user's response, and timely intervene in the Task conversion.
Evaluation Indicators Of Task
Task evaluation in our business, we will also refine different directions and specify various indicators according to different concerns, such as Task completion rate, intent recognition accuracy rate, and the rate of reaching the specified Process.
After integrating various indicators, it is consistent with the in-depth evaluation method of FAQ. It can be divided into two parts: one is the accuracy of the agent's own identification of the flow, and the other is that the logical speaking level of the Task is perfect enough to guide users to independently complete business goals.
Here, at the initial stage, the accuracy of identification and flow is mainly considered. The perfection of Task logic script is mainly formulated in the early intent planning. Of course, it can be further optimized and launched in the later stage according to the problems found in the operation.
The accuracy evaluation of identification flow can divide intent into one round of one round dialogue, and then evaluate it in combination with the characteristics of Task.
The first is triggering, which means whether the user can correctly identify the Task rather than FAQ that he wants to enter. The evaluation strategy is consistent with the accuracy evaluation of intent of FAQ. If we encounter a triggering error, it is the same to check whether the example has the wrong intent, whether the statement is so special that it is not recognized, or if we do not want a statement to trigger the intent. We can adjust the intent or knowledge points of the example in the Trigger, and add example or domain vocabulary.
After entering the Task, first evaluate whether the slot is filled correctly. The logic of filling the slot is consistent with the FAQ recognition. You can refer to it for testing and tuning.
The particularity of the Task is that the last conversation may have an impact on the flow process of this time, so it will cause different scripts after different branches.
Test Logic Of Task
When testing a Task, for the Task logic, the first thing is to go through the main Process. Simple and high-frequency Process should be tested to every branch. You can even consider going through Task through batch testing.
Secondly, we should try our best to simulate the real scene, formal environment, test independently, and find out whether there is any unreasonable place in the Task Process through our own experience.
Common Task Process problems in our event process include whether to allow users to exit, whether to allow FAQ in Task, whether to allow users to ask questions many times, etc.
Ways To Automate Test Task
In the long-term practice, we have also accumulated the ability to quickly test Task in batches. We can automatically generate use cases for testing according to Process branches. The following figure shows the Process test results in a test environment. If you need to use relevant capabilities, you can also consult the staff.
Specifically, different branches can be tested, and different statements can be used in each round to see whether they can run normally. It also supports automatic timing or manual running of early-stage test Task, so that the test can be automated.
.png)
Feature Topic 5: General Knowledge Base
The general knowledge base function, such as the company's public information, can be built into a general base for unified maintenance. In the later stage, it can be synchronized to all associated agent with one key. For example, the product knowledge of wuliai and the enterprise knowledge of laiye may need to be used in the corresponding agent of different departments such as pre-sales, after-sales and operation, and these knowledge can be maintained in the general library. The answers can use the general library, your own, or personalized similar questions.
There are three main steps:
1. select "general" when creating a new agent;
2. agent settings are associated with the corresponding agent to be synchronized;
3. Enter the top right corner of the general knowledge base and click "push knowledge base";
.png)
Optional steps: turn off the general library synchronization in the response answer and keep the customized answer
After pushing, the content of the general knowledge base can be added to the sub base. It is very convenient to modify the answers and supplement similar questions.
.png)
Matters needing attention:
- Standard questions, Category, and common similar questions change with the common database. Each synchronization will be updated accordingly. Except for the synchronization of common database answers, other configurable parts are consistent with common knowledge points.
- During the initial synchronization, when the push agent is accepted, the corresponding push knowledge points will be in the ineffective state, and their effective state will not be changed during the second synchronization.
- For the knowledge base that accepts push, you can add sentence patterns and similar questions that only take effect in this knowledge base.
- If you want to keep your edited answer, you need to turn off the general library synchronization button in the response answer.
After the launch, we officially entered the agent operation stage. As a agent, like other tools, we need to conduct timely inspection and maintenance to ensure that the agent can operate safely, accurately and meet business needs.
How do we check it? Like the common methods in our business process, it needs regular observation and evaluation. From this point of view, you can regard agent as your subordinate.
4.6 Long Term Operation Of Agent
By Timeline Category
Similar to our common downward management, we set the minimum frequency of agent inspection as weekly, followed by monthly, weekly, quarterly, semi annual and annual inspections. If there is a special person in charge, the inspection frequency can be appropriately increased and optimized in time.
The corresponding operation strategy is divided into annual operation strategy, semi annual operation strategy, quarterly operation strategy, etc.
People's entry stage often requires us to pay more attention to newcomers. Before entry, newcomers can only understand the company's requirements and make preparations before entry according to the company's job introduction and some limited answers; After entry, it is necessary to observe the entry performance of new employees and solve their problems in time.
Like human induction, we also need to focus on the agent and observe the performance of the agent when the agent is just launched; The difference from humans is that we need to tell agent what to do with the problems they encounter, because agent can not really understand the reasons behind the development of things and take the initiative to think about solutions like humans. The wisdom of agent is only what human beings teach agent.
Supplementary Understanding:
Wisdom Pyramid
Data is the most original material, which is not processed and interpreted, does not answer specific questions, and has no meaning; Information is data that has been processed and has logical relationship; Knowledge is useful information obtained by filtering, refining and processing relevant information; Wisdom is the ability to use knowledge to achieve a goal.
In fact, the process of building a agent is to sort the data into information and extract knowledge from the information. Then combine human wisdom to answer and work.
So what agent has is the wisdom we teach. If you want to make your agent smarter and have more "wisdom", you have to teach it well!
.png)
So how to check the situation of agent? We can have such an analysis framework:
Category By Purpose
Running effect angle of agent
Agent application results statistics FAQ agent effect: recall rate, accuracy rate, etc
According to the requirements for the agent during the construction period, the recall rate and accuracy rate are still the indicators that need attention. Let's review how these two indicators are calculated:
Recall rate = recall times / user questions * 100%
Accuracy = accuracy times / recall times * 100%
- Statistics of Task agent effects and solutions: Task trigger rate, etc
Task triggering rate = the number of times this Task is actually triggered / (the number of times that the user statement wants to enter the Task + the number of times that it is triggered by mistake) *100%
- From the perspective of agent application achievements
Satisfaction
Satisfaction is the user's evaluation of the service of agent customer service, but the subjective evaluation of users may not be enough. We also need to consider the external performance of agent customer service, and the first thing to ask is whether the user's problem is recognized correctly, that is, the recall rate and accuracy rate. If the recall is accurate, the rest of the interaction with customers is to mention the answer content, page layout, interactive experience and so on. Here we should pay attention to recall, accuracy and answer content.
Labor conversion rate
Transfer labor rate = number of users transferred to labor / total number of calls * 100%
There may be a variety of situations when transferring to manual work. The user actively transfers to manual work, and the customer actively or passively transfers to manual work after the user's question has been fallback for one or more times, and the customer's problem is not suitable for agent to solve, so it needs to be solved manually.
There are several situations in which the user actively transfers to labor. After entering the customer service system, the user directly expresses the transfer to labor. The user clicks the transfer to labor button on the interface. After the user tries to ask a question about the agent, he does not get the desired response, so he is not satisfied with the transfer to labor.
Resolution rate
Usually, the solution rate is calculated as follows:
Solution rate = 1-labor rate
Therefore, reducing the labor conversion rate can improve the solution rate.
Therefore, after disassembling these indicators, we will find that our agent can be optimized from three aspects: one is the accuracy and recall rate of the agent, the other is our settings for agent response, and the third is the settings for human-computer interaction, such as interface, manual conversion, response guidance, etc.
4.7 FAQ Marking And Optimization
We can simply think that the initial step of NLP is to identify the user's intent. If the user's intent is not identified correctly, it is likely to occur. The answer in the response is wrong, and the direction of the answer deviates from the user's needs. Therefore, first of all, we need to evaluate the recall and accuracy of the agent. The evaluation method is called tagging.
During the annotation process, we will Category the different situations of agent response according to the annotation rules, and then analyze the causes of response errors respectively. This will help us understand the existing problems of the knowledge base and optimize it more pertinently.
In laiye, we call the standard and formal labeling as gold labeling, because this labeling is as valuable as gold. For formal labeling, we require at least two people to label without reference to each other at the same time. If there are differences in labeling, a third person will be introduced for joint evaluation.
FAQ is slightly different from Task annotation. The annotation in this chapter is mainly aimed at FAQ annotation methods and experience.
4.7.1 Marking Method
The first step is to distinguish whether the agent is recalled. Whether the agent is recalled is easy to evaluate, that is, whether the user statement can give the corresponding response after matching the knowledge points in the knowledge base. As long as the confidence calculated exceeds the set threshold, we can get the response of the agent, which is a recall.
The second step is to distinguish between accurate and inaccurate after recall. We mainly include the following situations:
1. Correct recall: the agent response with the correct answer to the knowledge points. If the recall is not intended to recall the knowledge points, response with fallback;
2. Wrong calling or wrong fallback within the knowledge base: the user message has corresponding knowledge points in the knowledge base, but the agent response to the answers or fallback of other knowledge points;
3. Outside the knowledge base: the user message belongs to the business scope, but there is no corresponding knowledge point in the knowledge base, and the agent response to the answer or fallback of a knowledge point;
4. Semantic ambiguity: the user sends a message with semantic ambiguity, but the agent response to the answer or fallback of a certain knowledge point;
We can easily understand what is the recall of correct knowledge points, that is, the semantics of the user's questions are consistent with the recalled knowledge points, but we have put forward two new concepts here: the scope and semantics of the knowledge base are unknown;
Knowledge base scope:
User messages have corresponding knowledge points in the knowledge base, that is, they are within the scope of the knowledge base;
Messages related to business scenarios but without corresponding knowledge points in the knowledge base are considered outside the scope of the knowledge base;
Here we need to identify the relationship between the scope of the knowledge base and the scope of the business. The two are not the same. One is whether the customer service personnel should answer, and the other is whether the relevant knowledge points have been maintained in the agent.
Semantic ambiguity:
Pure numbers, letters, expressions, symbols, sentences that cannot understand the meaning of words and messages unrelated to business;
Unintended graph v.s. semantic ambiguity
The unintentional figure is a question that we don't want the agent to response. In short, the unintentional figure is a blacklist; If the semantics are not clear, it does not necessarily mean that the agent does not need to response. We can use certain guidance to guide the user's partially unrecognized semantic intent into a complete question, so as to response to the user.
Generally speaking, users ask keyword in the business field. If there is no corresponding configuration, then the semantics are unknown. If we have the corresponding configuration, then this question can be answered by the agent.
For example, in the personnel scenario, "five insurances and one fund" is asked. If the keyword "five insurances and one fund" is configured, we should response to the answer to the keyword "five insurances and one fund". Generally speaking, the answer can be the answer to the "five insurances and one fund" and the tips on related knowledge points.
However, in this example, it is inappropriate to maintain the "five insurances and one fund" as an unintentional plan.
In combination with the response of the agent, we can divide the semantics of the user message into the following types in combination with the agent response:
Agent recall:
1. Correct recall: the agent response with the correct answer of knowledge points;
2. False recall - within the knowledge base: the user message has corresponding knowledge points in the knowledge base, but the agent response to the answers of other knowledge points;
3. False recall - outside the knowledge base: the user message belongs to the business scope, but there is no corresponding knowledge point in the knowledge base, and the agent response to the answer of a knowledge point;
4. False recall - semantic ambiguity: the user sends a message with semantic ambiguity, but the agent response to the answer of a certain knowledge point;
Agent fallback:
5. Not recalled - within the scope of the knowledge base: the user message has corresponding knowledge points in the knowledge base, but the agent response with fallback;
6. Not recalled - outside the scope of the knowledge base: the user message belongs to the business scope, but there is no corresponding knowledge point in the knowledge base, and the agent response with fallback;
7. Not recalled - semantic ambiguity: the user sent a message with semantic ambiguity, and the agent response with fallback;
8. Unintentional map: the agent can response to the fallback by setting unintentional map knowledge points artificially;
The number of annotation results of various categories sorted out according to the above Category standards can be represented by N1, N2... N8 respectively.
4.7.2 FAQ Effect Indicators
Number of messages marked: the number of All messages marked this time (i.e. n1+n2+... +n8)
Number of messages in the knowledge base: the number of user messages with corresponding knowledge points in the knowledge base (i.e. N1 + N2 + N5)
Number of recalls in the database: the number of messages that can be recalled by the agent within the knowledge base (i.e. n1+n2)
Accurate number in the knowledge base: the number of correct knowledge point answers response in the messages that agent can recall within the knowledge base (i.e. N1)
Coverage: the proportion of messages within the knowledge base in the number of All meaningful messages
That is, the number of messages in the library / (number of marked messages - semantic ambiguity - unintentional diagram)
\= (N1+N2+N5)/(N1+N2+N3+N5+N6)
Recall rate in the Library: the number of messages that agent can recall within the knowledge base, and its proportion in the number of messages in the library
That is, the number of recalls in the library / the number of messages in the library
\= (N1+N2)/(N1+N2+N5)
In database accuracy: the number of messages that agent can correctly answer within the knowledge base, and its proportion in the number of recall messages
That is, the number of quasi confirmations in the library / the number of recalls in the library
\= (N1)/(N1+N2)
4.7.3 Practical Operation Guidance
1. Export real user messages on the line in a certain time period. Path: data analysis - session log - message log
.png)
2. Calculate whether to recall the exported data through the formula template, and then judge manually. It is necessary to judge:
- Normal recall / unintentional diagram
- Knowledge base scope but error
- Outside the scope of knowledge base
- Semantic ambiguity
Based on these, we can make a labeling template, which can automatically calculate whether to recall or not after labeling.
3. According to the marked data, repair the missing recall and recall errors within the coverage.
4. According to the marked data, find the missing knowledge points under the business scenario in the knowledge base. Add the knowledge points to sort out the answers, and then supplement and enter into the warehouse to take effect.
We suggest that at least 200 pieces of data should be annotated each time. If conditions permit, we should try to achieve the annotation amount of about 400-500, because when the annotation amount is too small, too many correct answers by the agent will cover up the problems existing in the agent. When there are only a few errors, it is easy to ignore these problems and think that they are not important and do not need to be improved.
In the message data, historical message records can be exported, and the corresponding messages can be found online through time, content and other information. It is worth mentioning that our message record search supports a certain fuzzy query ability.
In the export message record, we record the details of the user's message, the knowledge points recalled at that time, scores and other information in detail, so as to facilitate us to check whether the user's message and answer correspond and how to improve.
However, as we said earlier, the higher the confidence, the greater the probability that the agent will answer correctly, and the lower the confidence, the less similar the semantics that users say to the knowledge points in the knowledge base.
From this, we can infer that the parts with very high confidence in the agent assessment have a high probability of being correct. After we have an empirical value, we can confirm that we try to supplement the sentences with low scores into the knowledge base, which can effectively improve the accuracy of the agent's answer. How to quickly add these sentences to the knowledge base? It is to use the new knowledge point audit function introduced earlier. The score of new knowledge point audit is currently set at 0.5-0.75.
When the user's sentence is different from the knowledge base, it is often a new knowledge point that does not exist in the current knowledge base. We can give priority to the use to be mined. When the score of this part is relatively low, but the user's expression can be classified into clusters with similar idiom meaning, this part of new knowledge points can be stored through to be mined.
4.7.4 Faq Call Optimization
Agent operation is undoubtedly divided into many stages, but we still need to raise the call rate to at least a relatively high stage before we can talk about other experiences. We suggest that at least the coverage, recall and accuracy should reach more than 90%. Of course, this does not mean that other obvious questions, such as answers, do not need to be optimized together.
1. Correct recall
Ideal state, without optimization;
2. False recall - within the knowledge base
It may be caused by the misplacement of similar questions, the semantic intersection of different knowledge points, or the unreasonable granularity of knowledge points;
It is necessary to sort out the similar problems in the corresponding knowledge points, or add domain vocabulary for tuning;
3. False recall - outside the scope of knowledge base
Check whether there is semantic intersection between the knowledge points of false recall and the problem, and adjust it;
The problem is added to the knowledge base as a new knowledge point, and the semantics of the problem is different from the existing knowledge point;
4. False recall - semantic ambiguity
Check whether there is semantic intersection between the knowledge points of false recall and the problem, which can also be solved by adjusting the threshold;
If the problem has nothing to do with the knowledge base, it can be added to the unintentional diagram knowledge points;
5. Missed recall - within the scope of knowledge base
There may be a lack of similar questions in the corresponding knowledge points, so similar questions need to be added;
6. Knowledge base not recalled
This problem needs to be added to the knowledge base as a new knowledge point, and pay attention to the semantic difference between it and the existing knowledge point;
7. Not recalled - semantic unknown
If the message is related to the content of the knowledge base, the user can be guided to ask questions through the welcome words and fallback scripts, or by setting the keyword agent;
If the message has nothing to do with the knowledge base, it can not be processed;
8. Unintentional diagram
Normal effect, no adjustment is required;
It can be seen that we do not use the general indicators of accuracy and recall. Concepts such as unintended graph, semantic ambiguity, and knowledge base range are introduced here. The increase of unintended graph is mainly the processing measures for blacklist statements. Semantic ambiguity and knowledge base range are the concepts we have summarized in our actual business work. We need to correctly balance what is effective user questioning, Try to give users effective guidance and balance the current situation and ideal situation of the knowledge base.
Supplementary knowledge
We talked about the general indicators of accuracy and recall. This indicator is mainly used to evaluate the accuracy and recall in engineering. Under the assumption of this indicator, all samples or test sets can be divided very clearly. However, for business scenarios, this indicator can not fully reflect the actual business, and the help for optimization is very vague, Through the concept supplement of semantic ambiguity and knowledge base scope, this situation can be effectively balanced, and the current situation of knowledge base can be correctly evaluated when there are ideal indicators as the goal.
Refer to the following links for details:
4.7.5 Health Evaluation Of Knowledge Base
What does a good knowledge base look like?
- Similar problems are not misplaced
- Don't be redundant in saying similar problems
- Similar problems are natural and close to the expression of users
- Knowledge point similarity problem distribution equilibrium
- The particle size of knowledge points is moderately salty (Note 1), neither coarse nor fine
- The degree of abstraction of knowledge points is consistent
- Comprehensive coverage of domain vocabulary
Correspondingly, we can disassemble it into the following indicators:
Correctness of similarity question
Similarity and refinement
Similarity and naturalness
Knowledge point balance
Clarity of knowledge points
Knowledge point abstraction
Conceptual integrity
At present, the health of the knowledge base in our system has two evaluation indexes: the correctness of similarity questions and the health of knowledge points.
The correctness of similarity questions mainly solves the common mistake of placing the similarity questions originally belonging to knowledge point a into knowledge point B when building the knowledge base. This indicator is used to measure the degree to which all similar questions under the whole knowledge base are placed under the correct knowledge points. It is a score between 0 and 100. Intuitively, the higher the accuracy score of similar questions, the less the number of similar questions that represent misplacement.
The definition of knowledge points mainly solves another kind of mistake that developers often make when building the knowledge base, which is that the boundary between multiple knowledge points in the knowledge base is not clear, resulting in "you have me, I have you" between knowledge points. This intersection of knowledge points often leads to poor results after the agent goes online.
The definition of knowledge points is used to measure whether the boundary between all knowledge points in the whole knowledge base is "clear", which is a score between 0-100. Similarly, the higher the definition score of knowledge points, the clearer the boundary of two knowledge points.
The health score of knowledge points is the average of the correctness of similarity questions and the clarity of knowledge points.
In the corresponding below, we also give the corresponding key cases that need attention. You can check and make corresponding changes.
In addition, the knowledge base inspection should also check the following aspects:
(1) Check whether the Category is clear and understandable. If the Category rules are not clear, the maintenance personnel will not know the similar questions or where the new knowledge points need to be added.
(2) Look at the proportion of knowledge points with a small number of similar questions (less than 10-20). If the knowledge points of the user's questions are less than 10 similar questions, it is likely that this knowledge point will not be recalled.
(3) The private deployment version before 3.28 can also check the loo results to see whether there are a large number of problems and false calls.
Note 1: the particle size is moderate and salty. In the original text, it means sweet, sour and