Chapter II Intention Combing
2.1 Sorting And Building Of Knowledge Base
After clicking "dialogue building - FAQ dialogue", we will find that the platform provides two ways to build FAQ dialogue: FAQ based on keyword rules and FAQ based on semantic similarity matching.
- FAQ based on keyword rules—— Keyword matching rules
- You can configure keyword rules by manually adding and batch importing.
- After configuring the keyword rule, the platform will match the characters of the keyword in the user message. If the matching is successful, the agent response to the answer under this rule.
- FAQ based on semantic similarity matching—— knowledge base
- Knowledge points can be configured through manual addition, batch import and corpus clustering mining.
- After configuring the knowledge points, the platform performs semantic matching between the user message and the similarity question of the knowledge points. If the similarity score after matching reaches the threshold, the agent response to the configured answer of the knowledge points.
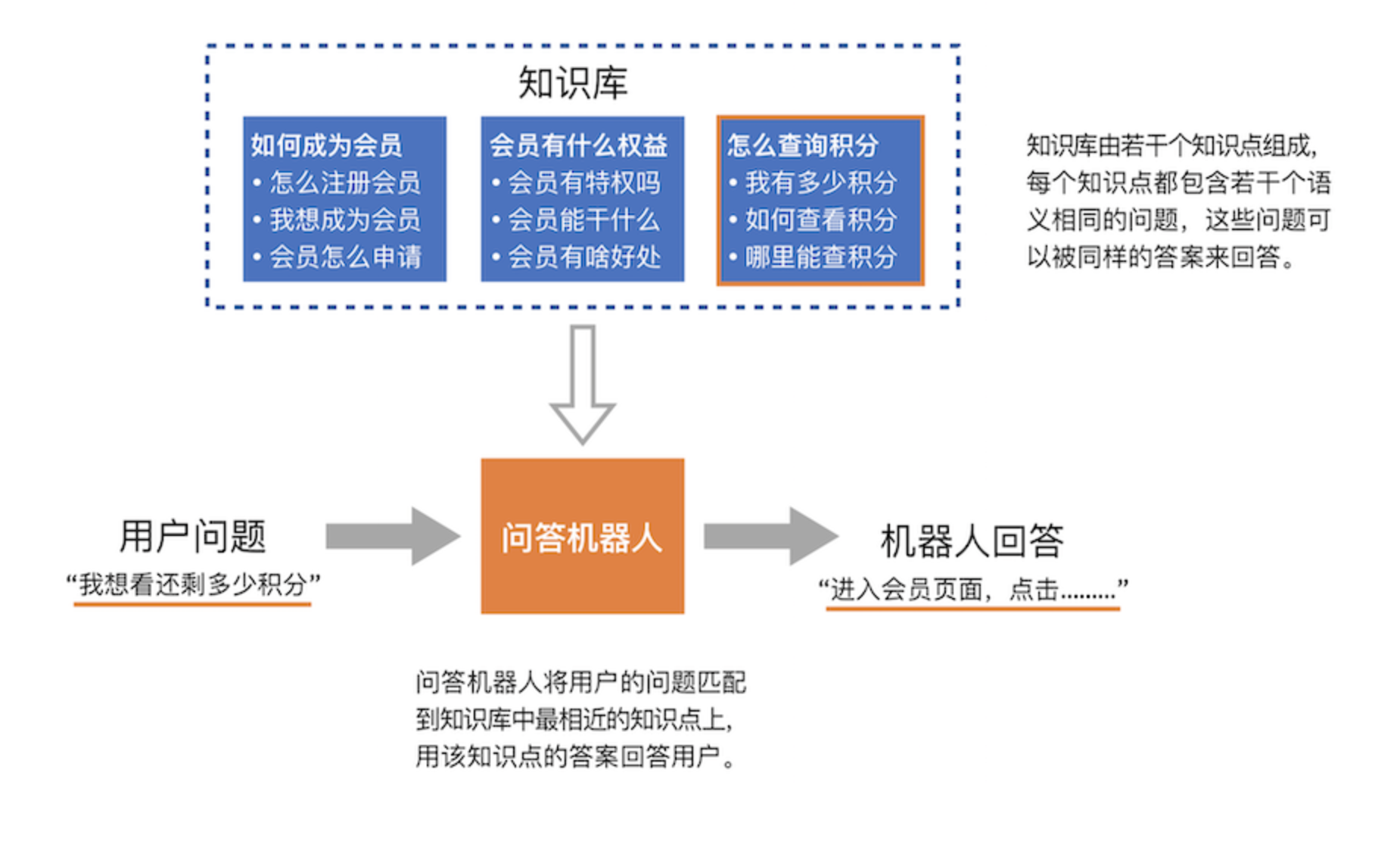
The knowledge base is more in line with the natural thinking habits of human beings, so here we first introduce the knowledge base, and then introduce the keyword matching rules.
The FAQ dialogue refers to the customized FAQ knowledge base. The user inputs the "question type" text request. The platform uses algorithms to search in the FAQ knowledge base, and uses the "answer" to answer the user's "question".
Create A New Knowledge Point From The Problem
Open the FAQ dialogue interface on the agent platform, where we can see the structure of the entire knowledge base, and can also easily perform various convenient operations on the agent. Click to add knowledge points, and we can quickly start to experience the capabilities of the agent.
.png)
You can click add knowledge point on the knowledge base page to create a new knowledge point. Standard questions and similar questions are required. You must select one Category. If you do not create a new Category, you can select the default Category first.
It is generally recommended to have more than 20 effective knowledge point similarity questions. At the initial stage of knowledge base construction, if the indicators meet the requirements, we can also accept more than 10 similar questions.
The answer can be added by selecting words, pictures, etc. if the answer is not added, it will response to the response set by fallback. After selecting "effective", you can simply add this knowledge point to the knowledge base.
Click the debugging agent in the lower right corner to quickly verify the response of the agent.
Reasons for not getting response to common debugging knowledge points:
- When the knowledge point is not effective, the default is when the knowledge point is not effective
- The knowledge points are lack of answers. When the knowledge points have no answers, they still return to the content set in fallback
.png)
New tips for standard problems of knowledge points
- To be representative, the quality of the title affects the recall
- Use standard Mandarin, easy to understand and avoid obvious dialects or personal idioms
- Avoid typos, network terms, unfamiliar vocabulary e.g. annealing (goods) validity
- The grammar is complete, concise and to the point. Don't just use words and avoid complex long sentences
- No useless special symbols, greetings, modal particles, etc
Feature Topic 1: Addition And Use Of Sentence Patterns
In many cases, the user may describe a sentence with a specific feature. You can see the following two examples.
Case 1: the knowledge point of "when to deliver" is likely to be "whether there is delivery information today", "can you deliver on Monday" and "can you deliver on the 18th day";
Case 2: for the knowledge point of "whether the product is genuine or licensed", the user may generally describe the specific product, "is the X series product genuine", "is the X model of X product true", "is the XX I bought licensed";
In this case, we can add a sentence pattern to solve the problem. We wonder if we can let the agent take "XX series" as a variable, so that when the user says any series of products, we can realize that the key information such as the time and product name, model, series, etc. that the user says is the entity.
In fact, for "XX series", "x model", "x color number" and "x rule", we also want agent to recognize any one. With the following question "is it genuine", we can All recognize this knowledge point? Then we can set that as long as we meet any of these rules, we can put it into this mode and let the agent recognize it. The tools that hold these different entity are called slot.
Then we need to add entity and slot to help us do this.
First, you need to summarize the key information said by the user in the thesaurus Add enumerate entity , The platform itself is also equipped with a system entity such as date, which can be used directly if necessary.
Step 2: create a new slot in the slot management and associate it with entity.
Step 3: click "add new sentence pattern", and enter "@" to call this slot where you need to use this information to replace the user's specific statement.
In this way, all sentences with the same pattern can be covered without exhausting all specific information. The sentence pattern function will restore the sentence pattern into specific similar questions when participating in the recall, and participate in the calculation of scores.
2.2 Knowledge Points
2.2.1 Knowledge Points And Knowledge Base
Knowledge points = standard questions + multiple statements with highly similar semantics (example) + one or more answers
Knowledge base: a structured, easy to operate, easy to use, comprehensive and organized knowledge cluster in knowledge engineering. It is an interconnected collection of knowledge points that are stored, organized, managed and used in computer memory by some (or several) knowledge representation according to the needs of problem solving in a certain field.
Feature Topic 2: Mining Knowledge Points From Corpus
If you have a cleaned user dialogue corpus (preferably 3-50 words, only the user's first session data), you can import the corpus first, and then import the corpus specified in the mining module.
Select mine now after import.
Note: the mining function and its dependent effect optimization are only available in the basic version and professional version.
.png)
Click the filter question after the corresponding representative question to view the single cluster results of machine clustering.
Cluster Small Theater
The teacher brought apples and pears and asked the children to divide them into two parts.
Xiao Ming puts the big apples and pears together and the small ones together
The teacher nodded, well, a sense of volume.
Xiao Fang picked out the red apples and put the rest together
The teacher nodded and felt the color.
Xiaowu's result? don't get it.
Xiao Wu took out his glasses: the latest smart glasses can see how many seeds are in the fruit. There are odd numbers on the left and even numbers on the right.
The teacher was very happy: a new clustering algorithm was born
The agent will cluster according to the characteristics of the sentence and the entity contained therein. The clustering results containing entity can click the upgrading sentence pattern for further processing, so as to get more accurate recommendations.
.png)
The above figure shows the clustering performance when sentence patterns carry entity. We can expand the corresponding similarity questions to select the similarity questions. Note that we should select sentences that retain a single intent, are not keyword, and are complete and do not coincide with the intent of other knowledge points.
Make necessary arrangement for the mined knowledge, and name the knowledge points according to the clustering results. For example, after adding similarity questions, selecting Category, transferring, and deleting the similarity questions that are not related to intent, we can store the knowledge points below.
If it is a example belonging to existing knowledge points, we can also click transfer to existing knowledge points to add. If we want to find more similar questions, we can try to click the recommended similar clusters and recommended similar questions buttons.
In order to ensure a good quality of knowledge points, the knowledge points stored at this time are not effective by default. You need to manually change the effective status and write appropriate response answers before you can experience them at the debugging agent.
.png)
If you want to mine a specific scene, you can use keyword mining. Under the search box, there are some keyword recommended by the machine that appear more frequently. Clicking more keyword can gradually narrow the scope of mining, or you can manually enter some specified words for mining. After clicking search, some recommended seed problems will appear. Add the seed problems you want to mine. A few seconds after clicking "start mining", there will be mining results.
The processing method of adding machine is consistent with that of filtering results.
2.2.2 Edit Knowledge Point Page
The knowledge point page is a page that we often use in the process of building and maintaining the knowledge base. Some properties of knowledge points can be maintained on this page. A group of answers can be set to 10 at most. You can reply to All in turn or one response at random. For the format of single answer, refer to the following requirements:
Text: input up to 2000 characters, about 666 Chinese characters
Pictures: support uploading pictures in JPG / jpeg / PNG / GIF format within 2m
Picture and text: up to 100000 bytes; Image support: jpg png. Gif format; Hyperlink: http: / / hppts\://
File size: within 10MB
Voice: within 2m, the playback length shall not exceed 60s, and only AMR format voice can be uploaded
Video: within 10m, only MP4 format is supported
Card: the title and description shall not exceed 100 words. The width and height of the preview is 900px * 500
Under the answers of knowledge points, you can add related knowledge points to emphasize the relevant questions you want users to understand. When users ask questions about this knowledge point, the standard questions will be displayed on it in the form of links. Therefore, this is the importance of the standard questions of knowledge points in the first section.
.png)
If we want to have automated recommendation questions, we can also use the similar knowledge points under the response strategy - agent strategy.
.png)
In addition, we can also use mining to enrich the similarity of existing knowledge points. There is a problem of mining similarity in the advanced settings of knowledge point editing card. The system will use the keyword corresponding to the knowledge points recommended by the machine to find the sentences that meet the requirements of keyword. We will select the appropriate similar questions when using them, and click the plus sign to add them to the corresponding knowledge points.
2.3 Category
2.3.1 Create A New Category
On the left side of the knowledge base interface is the Category page of agent knowledge points. Click the "+" symbol next to the Category name to create the next level Category of this Category. When the mouse hovers over the corresponding Category, the "Edit" and "delete" buttons will appear. When the mouse becomes a small hand“ ✋ "shape. You can drag the current Category to change its membership relationship. Note that it cannot be dragged to its next level.
.png)
Click the small triangle to the right to expand the next level of Category, and click the small triangle to the down to collapse all Category belonging to the Category.
To ensure that the Category can be exported and imported normally with the knowledge base, please do not use symbols such as "/" and "\" in the knowledge point Category. In addition, it is not allowed that any two Category names are the same.
Knowledge base Category divides knowledge into several categories according to the characteristics of knowledge points and the needs of business systems to solve problems, and each category is divided into several sub Category. The general sub Category is the basis of the parent Category, the parent Category is the generalization of the sub Category, and the sub Category are incompatible with each other.
.png)
Obviously, when there are more and more knowledge points, we need some reasonable ways to organize and manage the Category of knowledge points. Combing the structure of knowledge point organization is helpful to give the knowledge base a convenient induction methodology in the process of building the knowledge base.
If a good knowledge base Category construction system is not sorted out at the beginning, in the process of knowledge base construction, the actual operators will encounter problems such as unclear concept of knowledge points, similar questions about where to put them, and low efficiency of knowledge base construction.
2.3.2 Category Principles And Practical Experience
Agent knowledge base must have good Category to facilitate understanding, learning and later maintenance.
If the work is faced with a knowledge base with poor Category, it will be a terrible scene. After getting a user's question, it is assumed that human beings will answer the question according to the knowledge points in the knowledge base. He will find that there may be multiple knowledge points of the same question that contain similar questions at the same time, and the answers of each knowledge point are different. It is easy to find that the knowledge points are under different Category when comparing, and the overall Category logic is also confusing.
It is also not feasible to cancel Category. When the knowledge base has more than 20 knowledge points, it must be managed through Category to effectively sort it out. Otherwise, in the face of a large knowledge base, each sorting out is a long journey. It is inconceivable to distinguish the relationship between one knowledge point and thousands of other knowledge points in every work.
Therefore, when there are more and more knowledge points, we need some reasonable ways to organize and manage the Category of knowledge points. Combing the structure of knowledge point organization is helpful to give the knowledge points in the knowledge base a convenient induction methodology in the process of building the knowledge base.
1. Category principle and system operation
Knowledge base Category divides knowledge into several categories according to the characteristics of knowledge points and the needs of business systems to solve problems, and each category is divided into several sub Category. The general sub Category is the basis of the parent Category. The parent Category is the generalization of the sub Category. The sub Category are incompatible with each other. The division of Category in the knowledge base follows the principle of MECE.
Tips
MECE analysis method, fully known as mutually exclusive collectively exhaustive, means "mutually independent and completely exhaustive" in Chinese. That is to say, for a major issue, we can achieve Category without overlap and omission, and effectively grasp the core of the problem and become an effective method to solve the problem.
On the left side of the knowledge base interface is the Category page of agent knowledge points. Click the "+" symbol next to the Category name to create the next level Category of this Category. When the mouse hovers over the corresponding Category, the "Edit" and "delete" buttons will appear. When the mouse becomes a small hand“ 👆 ” Shape. You can drag the current Category to change its membership relationship. Note that you cannot drag it to its next level.
Click the small triangle to the right“ ▶ ” You can expand the next level of Category, and click the downward triangle "▼" to collapse all Category belonging to the Category.
PS: to ensure that the Category can be exported and imported normally with the knowledge base, please do not use symbols such as "/" and "\" in the knowledge point Category.
2. brief description of Category method
2.1. Category vertical division method
In the process of building knowledge base, the method of building Category mainly according to the time sequence of end-user participation is called the vertical division method of knowledge base.
At present, vertical division seems to be the main method for us to build a knowledge base. In terminal companies, when a single business line has been allocated, it is often divided according to the participation time of end users in a single knowledge base.
Consumer product companies generally distinguish knowledge bases according to pre-sales and after-sales. Pre-sales may also be subdivided into preferences, product information, logistics options, payment methods, etc. after-sales may be divided into logistics status, quality problems, packaging problems, etc. Of course, the logistics planning of different companies is not completely consistent, and some companies determine the pre-sales and after-sales according to whether the products reach the hands of users, which can be fine tuned according to the specific situation and reality.
Service items can also be distinguished by referring to the corresponding logic. For example, catering items can be distinguished according to the Process of employee induction, probation, job transfer and resignation.
2.2. Category horizontal division method
The horizontal division structure of the knowledge base is mainly used when there are many product business lines, and it is often divided according to the secondary Category. For example, different products sold by the company may belong to pregnancy - product Category - different products.
Usually, in the specific Category process, the vertical division and horizontal division will be combined to sort out in combination with the specific business conditions. Different companies have different business models and need to determine the knowledge base structure according to their actual situation.
2.3. Overview of Category experience
In practice, we have summarized the following Category formulas to help you remember:
One main line, the other side; If there is repetition, do Kung Fu early.
"One main line" means to first confirm whether the knowledge points are expanded in the scene of the user's life cycle. For such knowledge points, the only main line is generally the chronological order of end-user participation.
"Other side" means that if the knowledge points under the Category do not change with the user's life cycle, such as the location of the cell, the information around the cell will not change with time. At this time, such knowledge points can be used as the basic information of the project.
"If there is repetition, do Kung Fu early" if there is repetition at different stages, is there any obvious position that should be classified? We generally put the knowledge points at the place where we ask questions first in the scene.
If there is a parallel situation, such as credit card processing projects, offline processing as the main line, at the same time, APP, WeChat, small programs, Alipay and other channels as secondary lines, the need to clear the proportion of secondary lines. If there is a large difference in the opening of APP in the sub line, and there is little difference in wechat, applet and other channels, there are the following solutions:
App channels can be Category separately, and the second group of answers can be designed under the corresponding knowledge points. According to the property brought by the questioner, the same knowledge point can be designed to be divided into different answer groups according to attribute entity for personalized response.
The advantage of this scheme is that it can directly make the best answer according to the channel of the user's questions, but it requires the app channel to be accessed with attribute or the customer to provide entity information. Specific operations can be viewed Special Topic 3: Personalized Response 。
2.4. Practice of knowledge base classification
In practice, we have sorting methods of "from small to large" and "from large to small" according to whether the knowledge base is divided according to whether there is corpus.
What is from big to small? What is growing up? In fact, the core problem of the two is whether there is corpus. The former should be used in the scene without historical corpus, while the latter should be used in the case with historical corpus.
1 from large to small
Create conditions without conditions: business framework
In the absence of historical corpus, we generally rely on business framework. In the absence of business framework, the first thing to do is to sort out the business framework, sort out the business framework, constantly fill the business framework with knowledge points and their similarity questions, and constantly define the boundary of knowledge base with structured ideas. Therefore, from large (business framework) to small (knowledge points and similarity questions):
Step 1: user group analysis
First of all, it is necessary to confirm which types of user groups the agent faces and who they are respectively? Take the takeout scenario as an example:
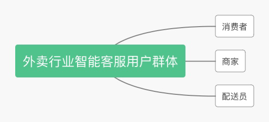
User groups of intelligent customer service in takeout industry
Step 2: user behavior analysis
Take user behavior as the foothold to analyze. For example, for consumers in the takeout industry, their user behavior can be divided into three categories: pre-sales, in-sales and after-sales; The merchant's user behavior can be divided into three categories: non settled merchants, settled merchants and merchant account cancellation; The rider should be: taking meals, in distribution and after distribution; The logical framework can then be extended.
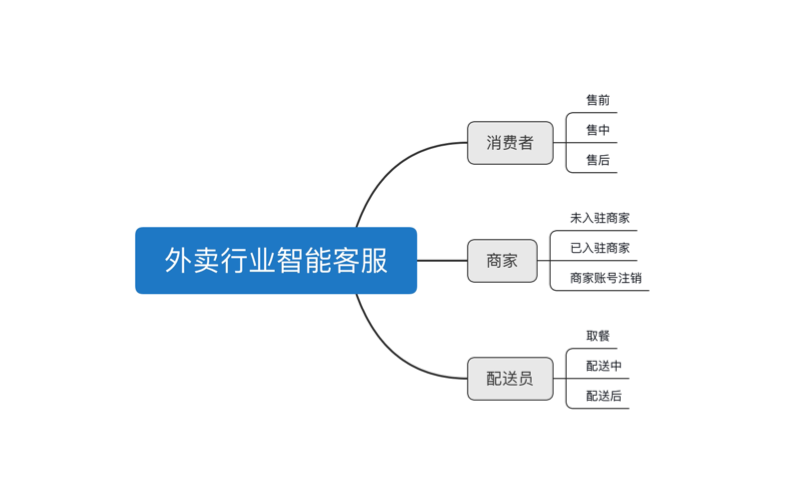
Business combing framework of intelligent customer service in takeout industry
But what should we do when there is no obvious logic between business scenarios?
Step 3: product function analysis
We can analyze the functions of the existing products as the foothold and take the business hall of Alipay civic center as an example.
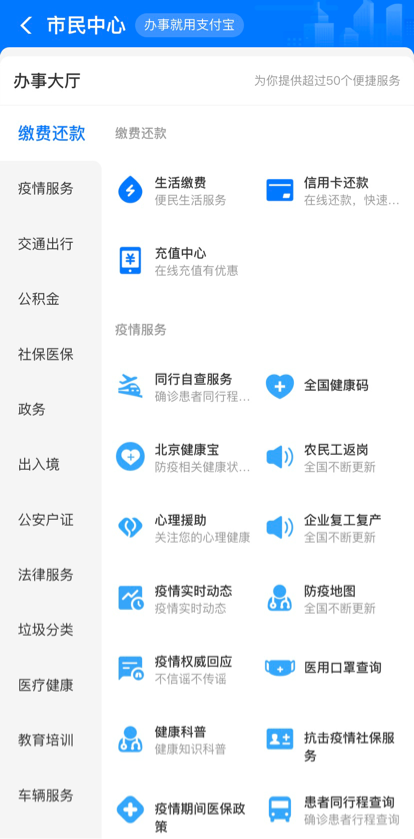
Alipay Civic Center - service hall page
The following business frameworks are sorted out according to the above product functions:
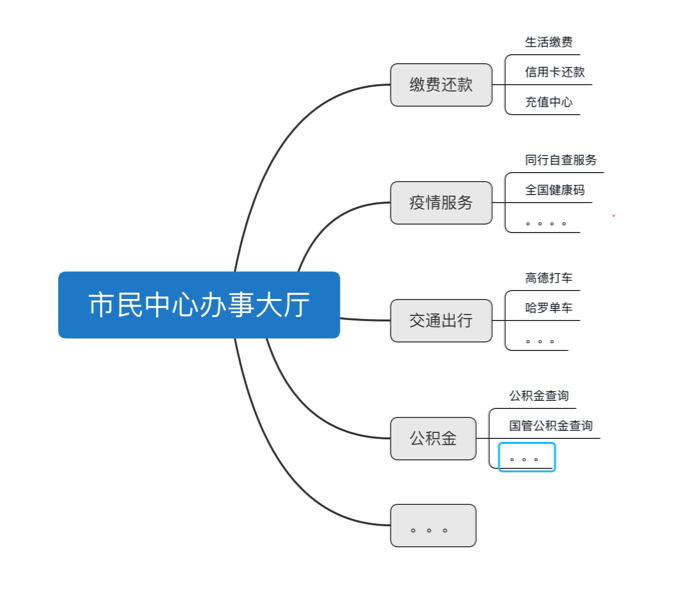
Business framework of Civic Center office hall
When we sort out the business framework and have such a tree, then we should constantly expand the knowledge points and their corresponding similarity questions into the corresponding business scenarios; For example, branches (knowledge points) grow on the trunk (business framework), and leaves continue to grow on the branches (similarity question).
2 from small to large
Making full use of Shangfang sword: historical corpus
When there is historical corpus, we can extract the core content through user query one by one, and deduce the business framework according to the core content, so it is from small (user query one by one) to large (business framework).
Such as the following user query:
1. What are the advantages of your honey products?
2. What effect does honey loquat dew have?
3. Which product can I eat for hypotension?
4. Dizziness after taking honey loquat dew?
5. Why does honey loquat dew have white sediment?
Extract the core content through user query:
1. What are the advantages of your honey products? - > Pre sales questions - brand advantages
2. What are the effects of honey loquat dew? - > Pre sales questions - product efficacy
3. Which product can I take for hypotension? - > Pre sales issues - symptom care
4. Dizziness after taking honey loquat lotion? - > After sales problems - Taking symptoms
5. Why does honey loquat dew have white sediment? - > After sales problems - product quality
When extracting the core content of a batch of user problems, we need to look at the granularity of knowledge points from an overall perspective, and whether the corresponding business scenarios and user groups are consistent. If they are inconsistent, they need to be adjusted; After the knowledge base is built and launched online, we need to pay close attention to the user interaction data to see if there are any missed fish.
Generally speaking, building a knowledge base needs to start from the business scenario and give priority to solving high-frequency problems; The knowledge base built in this way can better deal with risks and facilitate subsequent maintenance and optimization.
Tips Particle size
We call the size of the range of knowledge points as granularity. Knowledge points with large granularity can be properly split, mainly using the search similarity questions in the knowledge point editing card and adding them as new knowledge points. Accordingly, if the knowledge point particles are too small, few people ask, which is not helpful to users, and the meaning is similar and concentrated, they can be merged appropriately, and the application is to transfer the similar question to the existing knowledge point function.
Some principles of combing knowledge base
Starting from the business scenario, give priority to solving high-frequency knowledge points, followed by low-frequency knowledge points and knowledge points with strong timeliness; Even in the online stage, new knowledge points will be added continuously. Therefore, in the initial stage of construction, the knowledge points with the highest frequency and the most painful points should be considered first.
Clarify the boundary of knowledge base, not all user statements are suitable as knowledge points; In addition, some common types of problems may appear in different product knowledge bases. Whether such problems should be sorted out according to product Category or uniformly included in the common knowledge base should be comprehensively considered in combination with business scenarios and selected in an appropriate way. When sorting out knowledge points, it is best to formulate a unified naming standard to facilitate later management.
The larger the scale of the knowledge base, the more difficult it is to manage. Therefore, when the data increment reaches a certain degree, sampling inspection or regular inspection should be adopted to ensure the health of the database. For example, check whether there are failure knowledge points, whether there are fish that have escaped the net, and so on.
Although Category does not affect the effect, it is of great help to agent and operators during the construction process. Let's think about it. If the user's problem maintainers don't know which part of the knowledge base exists, can the agent?
Although Category does not affect the effect, it is of great help to the agent and operators during the construction process. Let's think about it. If the user's problem maintainers do not know which part of the knowledge base exists, can the agent?
2.4 Build Knowledge Base Process
.png)
After the knowledge base Category is completed, we need to classify the similar questions that can be clustered in the chat records into appropriate knowledge points in order to achieve better results.
The point to be explained here is that this construction Process is aimed at the construction of corpora, which means that we currently mean that there are chat records.
Step 1: Data Cleaning And Question Extraction
The information from each dialogue system is different, which requires us to do some processing for these data. The processing process of data is data cleaning.
For the contents mentioned in this step, you can also contact the business operation personnel to obtain the corresponding cleaning services or tools.
Through the observation of a large amount of data, we can find that the most important data in the session record is the user's first question, because the user's second question is likely to become targeted according to the previous question. At present, this ability to further understand needs the ability to apply the knowledge spectrum. We can also use the intelligent rewriting of FAQ messages in the response strategy. We won't tell more about it here.
Before cleaning the data, we need to read hundreds of chat records (200-1000 conversations recommended) and customers from the original corpus, find out the speaking characteristics of some users, the key scope of business, and understand the format given by the corpus.
Note that some test data shall be retained after cleaning.
It should be emphasized that due to different agent used and different data export methods, the format of chat records may be very different, but generally speaking, we all need the following requirements:
- Be able to distinguish the roles of each customer service and each customer
- If there is a agent, you can distinguish between agent and customer service
- You can know which contexts belong to a conversation (commonly represented by session, session, etc.)
- Time of the conversation message (to keep the first round of conversation)
Then we will keep the first round of meaningful response in the single round of dialogue. Before excluding the repeated statements of the user, we will keep the user's high-frequency questions for later testing.
It can be handled in this way. If the user only has greetings such as "Hello, Hello, are you here or not" in the first round, the whole line of this problem will be deleted All (that is, the user's second round of conversation will be pulled into the first round of conversation).
If the number of words is too short, it should be considered separately. Three words or less may be more suitable for agent such as Task, keyword, or FAQ greetings.
Other processing methods that can be referred to are as follows:
(1) Clean the contents of the code class, and almost all the following information can be All cleared, and the links can be retained if necessary:
{"operator_hint": 0, "operator_hint_desc": "", "answer_type": 2, "CMD": 60, "answer_label": "do you want to ask?", "Answer_flag": 0, "answer_list": "[{" groupid ": 866504," question ":" XX loan limit "," answer_flag ": 0}, {" groupid ": 866524," question ":" no quota for XX installment "," answer_flag ": 0}, {" groupid ": 866490," question ":" XXX provident fund application limit "," answer_flag ": 0}]", "answer_cnt": 3}
(2) If you don't need the analysis and clustering of the customer service answer part, you need to remove the mixed customer service conversation in the user conversation, and even discuss the original script with the customer service department, such as "what can I do for you?".
(3) For professional fields, it is necessary to remove some unnecessary things in the process of building a professional knowledge base. For example, if the FAQ does not involve specific funds or stocks, all sentences containing Fund / stock codes, full names and abbreviations All can be extracted for separate processing; In the app scenario, there may be various fault codes and prompts.
(4) Meaningless English and numbers, such as pure English and pure numbers, can be removed in the Chinese context
(5) Remove emoticons and meaningless symbols
Step 2: Create A Category
This step can be carried out with reference to the theory described in the previous section.
Of course, if the people who build and use the knowledge base are not the same group, we need to sit down and spend one to two hours to sort out the framework logic we build. And write the agreed main lines and rules into meeting minutes for later reference and adjustment.
Optional Steps: New Words, Entity Discovery And Review
The neologisms here do not refer to new words, but words that are unfamiliar to the system and have no way to understand how to deal with them. The main neologisms refer to words that will not be involved in pure daily dialogue, such as Agricultural Bank of China, Peking University, Lyme disease, etc; For large-scale projects, this step is often needed to make the agent understand these professional words because of their professionalism.
For specific business, new words may be the name of a product line, the name of marketing activities, the name of business system, etc.
In specific business scenarios, the concept of synonyms may be a little broader than that in the general sense. In addition to the Common Agricultural Bank of China, it is often called Agricultural Bank of China, Agricultural Bank of China. Even when asking for the list of supporting bank cards, Agricultural Bank of China card is also a synonym; In the business scenario of Tianhong company, in fact, when users say Tianhong, Tianhong, Tianhong and Tianhong, they all mean Tianhong company. When there is no new misunderstanding here, in this scenario, these words can be regarded as synonyms.
In the platform system, we can use phrase mining (entity mining) to help us find these phrases quickly. Select the imported corpus by using the imported corpus. Click immediate mining, and a word delimitation interface will appear to mark the phrases. Click next, and it will be found that the agent is looking for phrases in similar patterns.
Note: the basic version and professional version of the platform have the function of phrase mining.
For the found phrases, we can filter them and put them into storage.
The phrases picked out by all tools must be finally confirmed by specific business personnel. For example, in the scenario of consumer credit to C-end users, borrowing is equivalent to lending; However, in the professional interbank operation scenario, borrowing and lending are opposite.
Why do we emphasize the role of domain vocabulary and entity here? Because the first step of the current Chinese knowledge base FAQ system is word segmentation. Only when the word segmentation of domain vocabulary and entity is correct, can the subsequent matching and other actions be correct.
Moreover, the upgrade sentence function of the platform also depends on the selected enumerate entity. With better entity maintenance, our mining effect will be better.
Therefore, although this step is not necessary, sharpening the knife will not miss the firewood cutting work. I hope you can still pay attention to and complete it.
Step 3: Clustering And Mining
After setting up domain vocabulary, entity, etc. in the system, we can build a knowledge base on a large scale. In the online system, we can save the data extraction part (usually 600-2000 pieces) as test data, import the rest of the corpus into mining, and refer to the relevant chapters on mining knowledge points from the corpus to create new knowledge points.
With the help of algorithm researchers, we can also find corresponding engineers to help us cluster in batches to form a batch of knowledge point import system.
The import files of knowledge points directly clustered by problems are generally as follows (similar to the clustering results of machine mining):
| Category | Standard Issues | Similar Problem | Answer |
|---|---|---|---|
| Not Category (generally named as not Category) | Standard question (choose the second or third from similar questions) | Similar question 1 | similar question 2 | similar question 3 | similar question 4 | Answer: standard question |
| Not Category | Why can't you see it | Why can't I see it now? Why can't I see it? Why can't I find it | Knowledge point: why can't you see it |
The format of the result file after clustering according to domain vocabulary is as follows (similar to keyword mining):
| Category | Standard Issues | Similar Problem | Answer |
|---|---|---|---|
| Not Category (generally named as not Category) | Professional vocabulary 1, professional vocabulary 2 | Similar question 1 | similar question 2 | similar question 3 | similar question 4 | Answer: standard question |
| Not Category | How, can't see | Why can't I see it now? Why can't I see it? Why can't I find it | Knowledge point: how can't you see |
All machine clustering results and mining results need to be reviewed manually. The judgment standard can refer to the precautions for creating new knowledge points and building knowledge base.
Step 4: Improve The Knowledge Base
In a narrow sense, improving the knowledge base is to add and maintain answers. In a broad sense, it also includes the adjustment and addition of Category and knowledge points.
After basically building the knowledge base, we should check whether there are steps such as knowledge points with less than 10 similar questions. If they are not perfect, we can supplement similar questions through generalization tools.
Step 5: Model Optimization And Corpus Evaluation
When building a stage every day, we can use the model effect verification method and knowledge base optimization method to verify and optimize the effect of the knowledge base (see model effect verification and optimization knowledge base for operation).
The main operations are:
Use effect optimization - knowledge base optimization to check whether similar questions have misplaced knowledge points, and use example to learn and supplement similar questions that are missing in the well structured knowledge base.
.png)
Use model evaluation and online annotation to check whether the structure of knowledge points is missing and the recall rate is low; If the recall rate is judged to be low and the number of similar questions recognized is relatively small, we can use the introduction of example learning to expand the similar questions of existing knowledge points.
The source of model evaluation is the original retained corpus test set or the first meaningful question of the newly generated user question.
Until it is judged that the online requirements can be met, the access channel will be online. If the requirements of the project are high, you can also check all similar questions and answers before going online to avoid some problems that agent can't find by itself.
2.5 Precautions For Building Knowledge Base
Although it is undeniable that with the deepening of academic theoretical research, many concepts in life have gradually been explained in detail, if you want to quickly build a knowledge base, the practical significance of a intent can be more effective in specific business scenarios.
Let's take an example. In the financial industry, borrowing is borrowing money, from the perspective of the debtor; Loans are loans, from the perspective of creditors. Specifically, for a consumer credit company, it can only be a loan for the role of ordinary users. Therefore, in this scenario, the actual meaning of the loan asked by the user is actually only a loan. There is no need to emphasize the difference between loan and loan with the user here.
In addition, in many cases, we also need to clarify some vague questions of users. At this time, the main reference standard is what we will do when the actual business occurs.
In addition, we have the following suggestions:
Clarify the scope of knowledge base and knowledge points, reduce semantic intersection, do not guess the user's intent, and properly sort out when warehousing.
Clarifying the scope of the knowledge base means that the FAQ dialogue solves a large number of common, common and similar head problems. The judgment criterion is whether the knowledge base can cover business scenarios; The scope of knowledge points is similar, the coverage should be reasonable, and the answer can answer similar questions;
Reducing semantic intersection means that the similarity between knowledge points should be small, similarity questions should not be misplaced, and similarity questions should not contain multiple intent;
Do not guess the user's intent means that the meaning behind the sentence is not artificially understood and guessed according to the actual content of the sentence. For example, "I tried and found that the clothes are big". When you do not understand the business or do not clearly classify, do not try to guess that you may want to return or change. Instead, you should classify according to the actual business. If the question is incomplete and the clear meaning cannot be resolved, you cannot directly put it in the knowledge point;
Proper sorting during warehousing means that it is necessary to judge whether it can be put into storage, with more intent to split and less to complete;
Due to the needs of model training, the best number of corpus in the scene is 30, and the questions are as rich as possible; One of the evaluation criteria for the quality of a knowledge point is whether it can respond to the questions of customers in most cases in this scenario; The overall distribution of similar questions is best consistent with the actual questions of users; At the initial stage, we can also accept more than 10.
The length of the similarity question should not exceed 100 characters or 25 words. A Chinese character, a letter and a space are all counted as one character, which will be truncated when imported into the system, affecting the similarity calculation; (similar questions in Task triggering are the same logic)
Keyword and phrases can be handled using keyword.
Actual case:
In the consumer credit scenario, a customer's review may occur in the card application stage, activation stage and withdrawal stage, and the user does not distinguish between loan and loan. In this case, the "how long will the audit take" asked by the user may contain the following intent:
How long does it take to approve the loan;
How long will it take to review the loan;
How long does it take to activate the audit;
How long will it take to review the withdrawal;
How long will it take to approve;
At this time, we can adopt the following methods:
- Group answers according to different life cycles of users, and automatically recommend appropriate answers according to different life cycles and states of users.
- Put all the above questions in the same knowledge point: how long does the audit take
- Separate all knowledge points separately. There are 5 small-scale knowledge points + 1 large-scale knowledge point = 6 different knowledge points. Different knowledge points are interrelated to guide users to ask further questions.
- Make a Task dialogue, and the user will give the answer after asking how long the audit will take.
The final division method of actual customers combines the actual business scenarios. Loans and loans actually mean the same thing to users, so they can be combined; In business, every withdrawal requires approval, so withdrawal and approval can be combined into one knowledge point; The activation approval form is listed; How long will it take for the audit to give a more comprehensive answer, and recommended related questions in terms of related questions.
2.6 Preparation Of Intent Response
Building a agent is always a system engineering, so the customer-oriented display, that is, the agent's response, is a very important factor affecting the user experience, and it is not the end of the agent's answer to the knowledge points.
Sometimes the user thinks that the agent fails to solve the problem, not necessarily because the agent does not recall the correct knowledge point, but because the answer of the knowledge point fails to solve the user's problem.
Through our long-term practice, we have found that for agent with high coverage, accuracy and recall rate of historical projects (all above 90%), at least 40% of them are transferred to manual work because the answer can not solve the user's problems.
The following will focus on five principles to ensure the basic experience of users' FAQ:
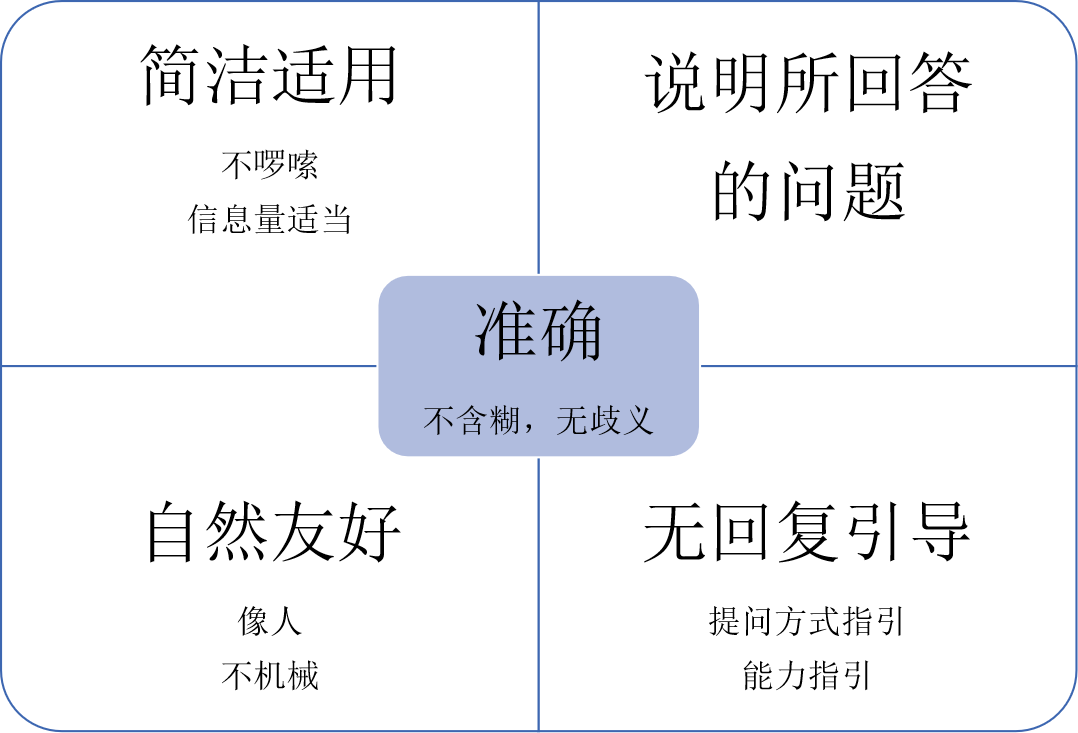
1. Accuracy
It refers to accurately answering the user's questions without typos and wrong words; Speaking unambiguously and unambiguously means avoiding general ambiguity and causing other questions or misunderstandings, which is the most fundamental requirement for the answer.
2. Concise and applicable
Able to respond to the current situation, not wordy, simple and clear, with appropriate amount of information. Users don't like it if it's too long.
If the answer is too long, you need to refine the key points and improve the presentation form when response.
3. Explain the questions answered
To clarify what question you are currently answering, simply speaking, it means to response with questions and give a response to the user, so that the user can know that the agent has recognized his question.
X error example
Q: What content needs to be uploaded in the maternity leave Process?
A: Upload the XXX attachment. For details, please consult the personnel specialist of the Department and other relevant personnel.
The answer does not indicate that it is the answer for maternity leave.
In the real scene, we find that this problem is often because the user repeats the problem several times, and the agent repeatedly answers his answer.
For agent trainers, this answer corresponds to the knowledge points of uploading attachments during maternity leave, but users do not know it.
〇 Correct example
Q: What content needs to be uploaded in the maternity leave Process?
A: XXX attachment needs to be uploaded in the maternity leave Process. For details, please consult the Department HR specialist and other relevant personnel.
This answer directly reflects the title of the knowledge points, so that users can know that the response is indeed correct.
Some agent choose to send the title of knowledge points together with the response when configuring, but this obviously does not conform to the following natural friendly principle.
4. Nature friendly
Naturally, it is consistent with the customer service response. Like a person, it should not be too mechanical and blunt. It can be appropriately worded and diversified.
Friendly means that there is temperature, care about users' feelings, and we must not abuse, insult and intimidate users. This requirement is lower, as long as it is smooth, but a good answer can make customers feel like spring breeze and feel happy.
5. No answer guidance
This refers to the way to guide users to obtain information when there is no answer or fallback.
Because the services we provide may be completely unfamiliar to users. Users will not know our service scope or capabilities, so we need to tell users the operational scope or steps.
〇 Service scope guidance example
Q: Hello
A: Hello, I'm agent Xiaowu. I can answer questions about five insurances and one fund and individual income tax withholding. You can try to ask me where to query the social security payment records.
This guide can also be applied to welcome messages and other links after users open it. (the channels supported by the platform can be experienced after "dialogue building - personalized experience - user event - entry event" is configured.)
〇 Guide example of fallback response
Q:*……%¥#@¥%…
A: Sorry, I don't know the question you asked. Why don't you ask me another way~~
You can also click the "switch to manual" button in the lower right corner of the window to get the help of manual customer service.
When necessary, you can guide the user to operate (generally implemented with Task dialog) or give a jump link. It should be noted that this operation is also very common in keyword dialog building.
〇 Keyword response guidance example
Q: Social security
A: What questions do you want to ask about social security?
Test experience
The test run can test the answer in such a way that the user can ask questions according to the given knowledge base range, and try to answer by using the instant communication agent to assist the manual response.
Tips: instant communication is the platform's own lightweight customer service system, which can access user questions on its own channels and simulate customer service to response. When response is entered, the answer recommended by agent will pop up automatically.
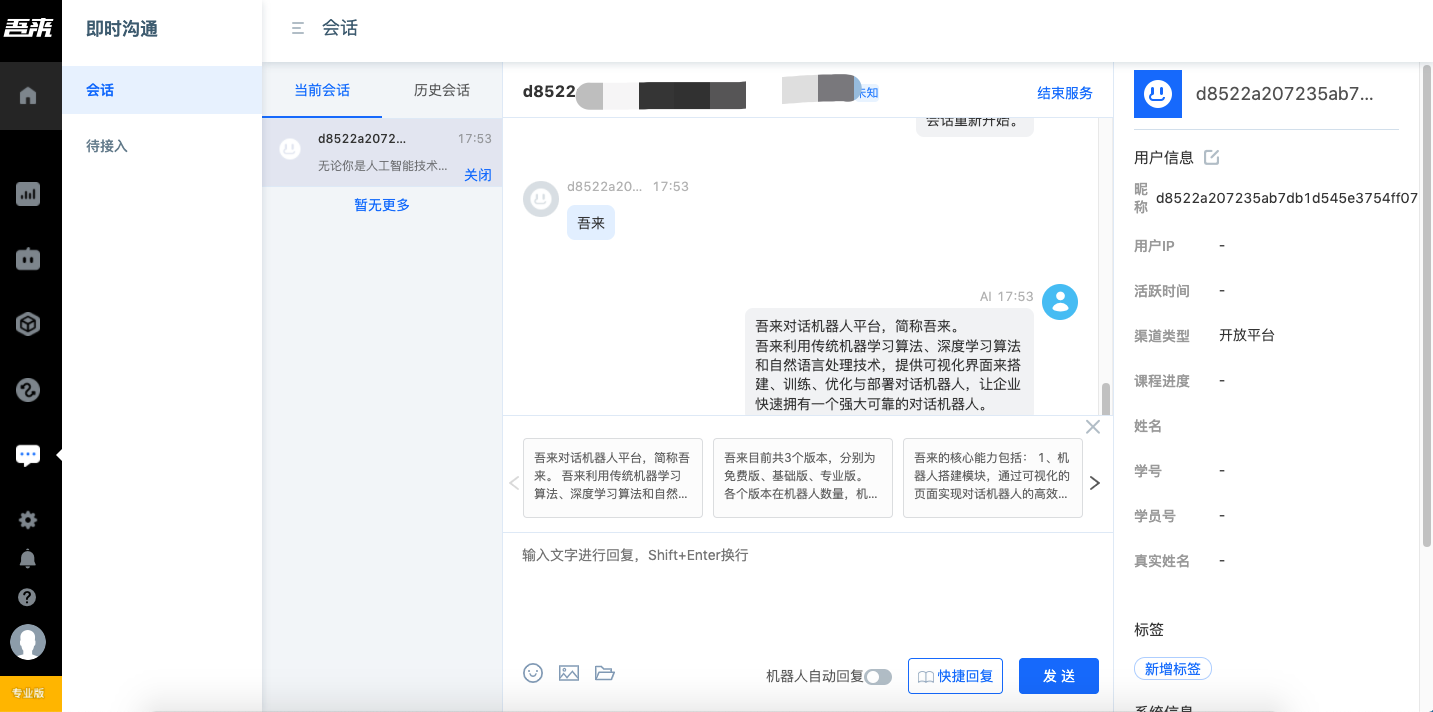
When you want to adjust your answers for response, it means that the original answers and handling methods may not be appropriate.
The wisdom of agent is taught by human and agent, especially from the perspective of answer writing. The key to optimizing agent is to be like people and then like people.
Notes for answer writing
Use standard Mandarin, easy to understand and avoid obvious dialects or personal idioms
Avoid typos, network terms, unfamiliar vocabulary e.g. annealing (goods) validity
The grammar is complete, concise and to the point. Don't just use words and avoid complex long sentences
No useless special symbols, greetings, modal particles, etc
Long Answer Sorting Paradigm
The description part of the standard question + what is the answer (concise version, except that the title is no more than 10 words).
There are the following solutions for situation 1:
Solution 1; You can enter the XX-XX page (click the link directly) for XX operation.
Solution 2;
There are the following solutions to the situation 2 encountered:
Solution 1;
……
If you insist on XXX, you can XXX (add again in extreme cases)
If it cannot be solved, consider XXX. An example of an attachment screenshot is as follows:
Picture 1
Recommend knowledge points related to the answer.
Special Topic 3: Personalized Response
Generally speaking, the more similar questions in knowledge points, the better the effect. However, blindly increasing will lead to the redundancy of similar questions under knowledge points.
In many cases, users may describe a sentence with a very specific feature. See the following two examples.
Case 1: the knowledge point of "when to deliver" is likely to be "whether there is delivery information today", "can you deliver on Monday" and "can you deliver on the 18th day";
Case 2: for the knowledge point of "whether the product is genuine or licensed", the user may generally describe the specific product, "is the X series product genuine", "is the X model of X product true", "is the XX I bought licensed";
Then we wonder if we can let agent regard "XX series" as a feature, and these features appear repeatedly in our knowledge and can be maintained separately, so that the user can recognize any series of products, and the agent can also understand this knowledge point.
Generation of sentence patterns
For similar problems with "XX series", "x model", "x color number" and "x condition", we can add sentences to solve them. The key information such as the user's time and product name, model and series is the entity.
At this time, the user said that xx series is true? It can be upgraded to the sentence "@ is the product series true?".
Sentence pattern is the template of example. When you need to add a large number of example with similar sentence structures to a knowledge point, you can use sentence patterns to reduce the number of example.
In fact, "XX series", "x model", "x color number" and "x rule" we also want to make agent recognize any one. With the following question "is it genuine", we can All recognize this knowledge point?
The platform can now be set to be put into this mode for agent to recognize as long as it meets any of these rules.
The tool that holds the values of these different entity is called slot, which can be simply understood as a basket.
After adding the slot, the sentence pattern becomes "@ product: is the product series, product model and product color number true?".
Among them, the product is a slot containing values of different entity, which conforms to the values or texts specified by the rules of entity such as product series, product model and product color number. It is similar to Jinzhuang (milk powder series), 3600x (CPU model) and 999 (mouth red number). We call it entity value.
.png)
Product series, product models, and product color numbers are different entity. They are filtering tools to determine whether user statements contain or conform to specific rules.
The role of entity and slot
Then we need to add entity and slot to help us do this.
First, you need to summarize the user's characteristic information. First, you need to add enumerate entity in the thesaurus menu built by the dialogue. The platform itself is also equipped with system entity such as date and number, which can be used directly if necessary.
The second step is to create a new FAQ slot in the slot management and associate it with the entity.
Step 3: create a new knowledge point or click the new sentence pattern in the existing knowledge point to add, and enter "@" to call the corresponding slot where you need to use this information to replace the user's specific statement.
.png)
In this way, all sentences with the same pattern can be covered without exhausting all specific information.
The agent will restore the sentence pattern to a specific similar problem when participating in the recall, and participate in the calculation of the score. After doing so, the scores of sentence patterns and similar questions can be compared.
After the scores of sentence patterns and similar questions can be compared, the recall logic of the platform is very simple to understand.
The platform also supports the use of more slot to describe a specific problem, such as "@ product family: product model of product family: product model introduction?", This avoids the problem that only one important feature is not accurate enough to describe a problem, and it is easy to recall without recall or false recall.
Through the method of entity rather than synonyms, we can distinguish different entity values, and even give users personalized response according to different entity values, such as product models, without adding more investment in generalization of similar problems.
Personalized response settings
The corresponding answers of different product models and series can be placed in a table to facilitate sorting, so as to accurately find the questions that should be response to users.
| Item number | series | stage | answer |
|---|---|---|---|
| one hundred thousand and one | Apocalypse | Second paragraph | Apocalypse II milk powder |
| one hundred thousand and two | Apocalypse | Three sections | Apocalypse III milk powder |
| one hundred thousand and three | Meifu | Three sections | Meifu third stage milk powder |
In fact, a lot of knowledge is stored in forms in business, so it is very efficient for agent construction if the contents in the forms can be organized and response directly.
Answer to personalized response we can create a form and add it in dialogue building - personalized experience - Personalized response.
At present, the platform supports the creation of multiple tables. Each table can have 10000 rows. You can add 10 groups of attribute columns used to locate conditions and 20 groups of answer columns; The answers in the answer column can be added by clicking, and support text, picture, graphic, card, file, voice and video formats; The answers can also be imported in batch. The answers imported in batch only support text.
The associated table is also very simple. You only need to open the personalized response, select the table, configure the query criteria, and the column of the returned answer.
.png)
After saving, we can see the effect in debugging agent, experience version web page or other official channels.
.png)
You can see the corresponding sentence pattern at the debugging agent and know which knowledge point this problem is, or even which sentence pattern is responsible for sending the response, which can support us to conduct rapid and accurate tuning.
The query conditions now support the use of user query statements in combination with the user's own attribute. Users in different regions, identities and channels can response to different answers when asking questions.
Now, the platform agent dialogue platform can accurately response users' questions such as "help me find the store address of X city" and "Does X series products have X function" after configuring knowledge points of this structure, and can reduce many low-level repeated similar questions.
Multiple knowledge points can use the same table to save the workload of configuration.
Therefore, the scheme of querying the form and response the answer by using the sentence pattern through the knowledge point association table is very accurate, avoiding the recall of the ability to only use the word vector, sentence vector and natural language to query the table and database, and the effect is difficult to intervene and repair the problem.
Simple knowledge map requirements can be converted into FAQ call forms for response, greatly reducing the cost of building and maintaining knowledge maps.
Other tips for personalized response
We have also made a lot of optimization for sentence patterns and table reading to make this process more practical and landing.
When building, we don't need English words, code or any interface at all. As long as we prepare the form, we can create such a knowledge point.
During the configuration process, you can also upgrade the entered similar questions to sentence patterns with a simple click.
.png)
The original knowledge base can be easily upgraded to a knowledge base with sentence patterns and personalized response.
The knowledge base also supports the import and export of portable sentence patterns, which is convenient to reuse the knowledge base in other apps.
In the Task dialogue, sentence patterns can also be used to fill in slots and trigger, so that when triggered, we can also accurately collect the key information said by the user.
After adding the slot, the use of sentence patterns can accurately collect information such as the place of departure and the place of arrival.
For example, "help me buy a @ departure: city to @ arrival: city's @ travel type: transportation mode ticket", we can identify the needs such as helping me buy a high-speed rail ticket from Shanghai to Beijing, and accurately fill the departure in Shanghai, the arrival in Beijing and the travel type in high-speed rail.
If a new category is added or used by another product line, we only need to replace or add entity values to perfectly reuse the original knowledge points. The universality and professionalism of the knowledge base can be guaranteed.
In addition, we have also made a lot of optimization for the mining ability of example of such knowledge points.
If you have cleaned conversation records with users, you can import the corpus first, and then import the corpus specified in the mining database from the mining agent.
Select mine now after import.
.png)
Note: at present, the mining function and some effect optimization functions are only available in the basic version and professional version.
The agent will cluster according to the characteristics of the sentence and the entity contained therein. The clustering results of the entity can click the automatic upgrading sentence pattern to get more accurate recommendations for further processing.
Click the screening question after the corresponding representative question to view the single cluster results of machine independent clustering.
.png)
The above figure shows the clustering performance of sentence patterns when carrying entity. We can expand the corresponding similarity questions and select the similarity questions. We can see that agent has summarized sentences such as "normal weight of x-month-old baby" and "whether x-kilogram of x-month-old baby is normal".
After clicking on the cluster, you can find that some sentences have been preselected by the agent, while others have not. The sentences in the preselected sentences are recommended by the agent. The rest of the sentences are very close to the sentences that have been preselected, and you can response correctly without adding the agent repeatedly.
Fewer but more representative sentences also reduce the difficulty of maintaining the knowledge base in the later stage.
When screening, you should still pay attention to the selection of sentences that retain a single intent, are not keyword, and are complete and do not coincide with the intent of other knowledge points.
Make necessary arrangement for the mined knowledge, and name the knowledge points according to the clustering results. For example, after adding similarity questions, selecting Category, transferring, and deleting the similarity questions that are not related to intent, we can store the knowledge points below.
If it is a example belonging to existing knowledge points, we can also click transfer to existing knowledge points to add. If we want to find more similar questions, we can try to click the recommended similar clusters and recommended similar questions buttons.