Chapter I Basic Knowledge of Conversational AI
1.1 Introduction to Conversational AI Platform
There are many types of agent. In addition to entity agent such as food delivery agent that you can see and touch, and manipulators used in industry, there are also many virtual agent, such as Siri, Alex or automated intelligent customer service, which are often used. More accurately, they belong to conversational AI like the dialogue services provided by the Laiye Conversational AI Platform.
Referring to theEvaluation method of intelligent dialogue platform development and service capabilities(January 2022 version) proposed by the Chinese Artificial Intelligence Industry Alliance, intelligent dialogue platform products refer to service-oriented platforms or systems that can open the development and construction capability, covering six core capabilities of providing dialogue understanding, dialogue construction, dialogue optimization, dialogue customization, docking deployment and management and operation. Their characteristics are that they can realize low code or zero code dialogue system customization that have the ability of rapid optimization and iteration of dialogue system.
Conversational AI and Chatbot
Generally speaking, Chatbot refers to a specific agent for a single actual dialogue facing end users, while Conversational AI usually refers to the conversational agent platform, also known as intelligent dialogue platform, etc. For example, the Conversational AI is equivalent to the industrial machine tool in the industrial system and is the cradle of the Chatbots.
Among them, the dialogue understanding ability does not involve specific product function operations, but mainly focuses on supporting multiple dialogue types, dialogue skill and strong algorithm skill, so there is often no specific product module to corresponding. In addition, the customization ability of dialogue is often highly combined with the product functions provided by the system.
For intelligent dialogue, Laiye Conversational AI Platform is mainly composed of four parts: dialogue Design module, effect optimization module, data monitoring module and channel deployment module. In addition, conversational AI platform can also assist existing human service personnel to prompt recommended response.
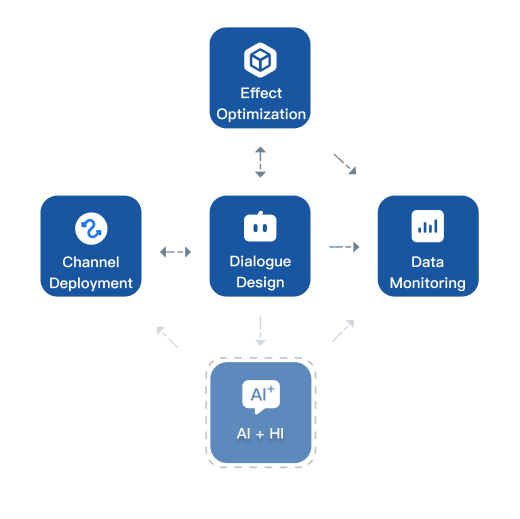
At present, there are Cloud Edition of online services for small and medium-sized enterprises and On-Premise Edition for individuals and private deployment and customization.
| Product Version | Version Introduction | Keyword | Recommended Scenario |
|---|---|---|---|
| On-Premise Edition | A privately deployed version of Conversational AI Platform. It uses the industry-leading deep learning algorithm and natural language processing(NLP) technology to provide a visual interface to build, train, optimize and deploy chatbot. Agent can have complex capabilities such as intelligent retrieval of document. It is applicable to complex business scenarios such as customer service, marketing and internal employee service of large and medium-sized enterprises. | - Industry leading low code text agent development platform - Applicable to large and medium-sized enterprises - Private deployment customization | Dialogue agent is applicable to the following scenarios: - There are many communication objects, but there are relatively ready channels of communication (such as internal communication platform, official account, small program, etc.). - The questions to be answered or the Task to be handled are relatively repetitive and high-frequency, and there are relatively clear scripts and unified processing Process - It involves relatively complex requirements such as intelligent document processing - High requirements for safety compliance |
| Cloud Edition | A SaaS version of Conversational AI Platform. It uses the industry-leading deep learning algorithm and natural language processing technology to provide a visual interface to build, train, optimize and deploy dialogue agent. The built agent can be directly connected to different channels (such as WeCom, Wechat Official Account, LARK, Dingtalk, etc.). It can quickly and flexibly meet the scenario needs of individuals and small and medium-sized enterprises. | -Industry leading low code text agent development platform - Applicable to small and medium-sized enterprises and individuals - High concurrency SaaS | Chatbot is applicable to the following scenarios: - There are many users, but there are relatively ready channels of communication. - The questions to be answered or the task to be handled are relatively repetitive and high-frequency, and there are relatively clear scripts and unified processing process |
For the On-Premise Edition, please contact the technology service hotline at 400-001-8136.
1.1.1 Overview of Typical Product Interface
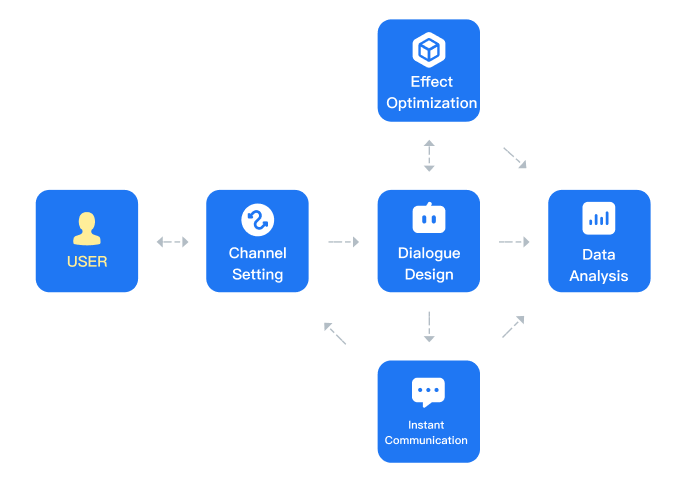
Laiye Conversational AI Platform (Cloud Edition) (hereinafter referred to as the platform, which refers to the online version unless otherwise specified in the later stage) mainly includes five modules: dialogue design (including FAQ building and task dialogue building), effect optimization, channel setting, data analysis and instant communication.
Users' messages enter the platform through Wechat official account and other channels, and then through the established dialogue agent, they directly response to users or provide reference for manual services. At the same time, the system records the messages of both parties and saves them for data analysis. The precipitated conversation data can be automatically processed by the effect optimization module and then can be optimized by the agent after simple manual review.
Click to open the agent and it will switch to the dialogue building - knowledge base page by default. Taking the knowledge base page as an example, the typical product interface of the platform has three levels:
- The first level is the leftmost row, from top to bottom, including agent management, data analysis, dialogue design, effect optimization, channel setting, and instant communication. In addition, there are enterprise management, message center, help center, user center, and account types. This level represents the main level of the platform.
- The second level includes FAQ(Frequently Asked Questions) dialogue, Task dialogue, chat dialogue, thesaurus, slot management, response strategy, personalized experience and debugging agent in the dialogue building module.
- The third level, such as knowledge base and keyword matching rules, is the specific function page after clicking. Click the button on the left of the title to retract the secondary menu and show a larger operation space.
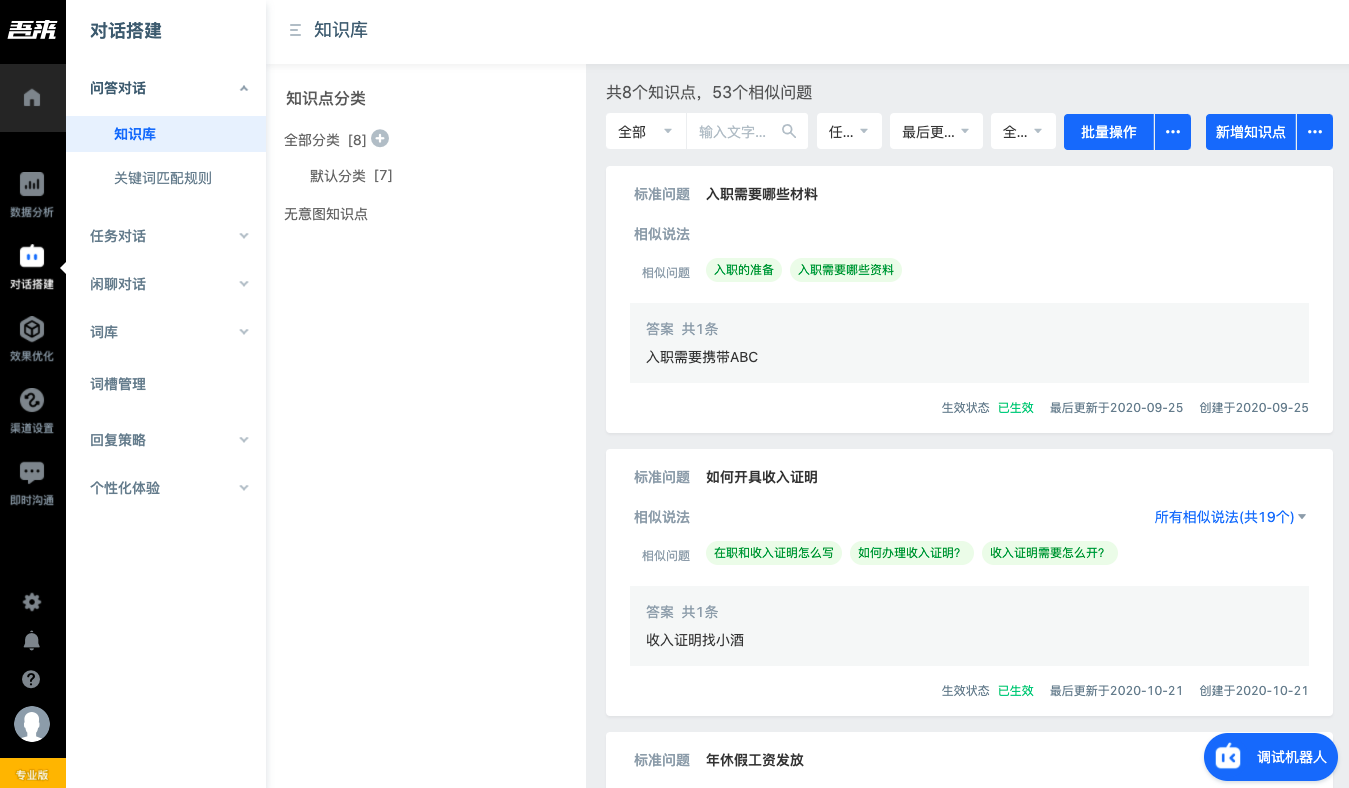
On the specific function page, the knowledge base page is divided into two columns, knowledge point Category and knowledge base management page. There are various filtering and operation buttons under the knowledge base management page. Note that there are often some operations that need to be used under the "···" button, such as "knowledge points under batch effective Category" and "batch upload knowledge points" under this page.
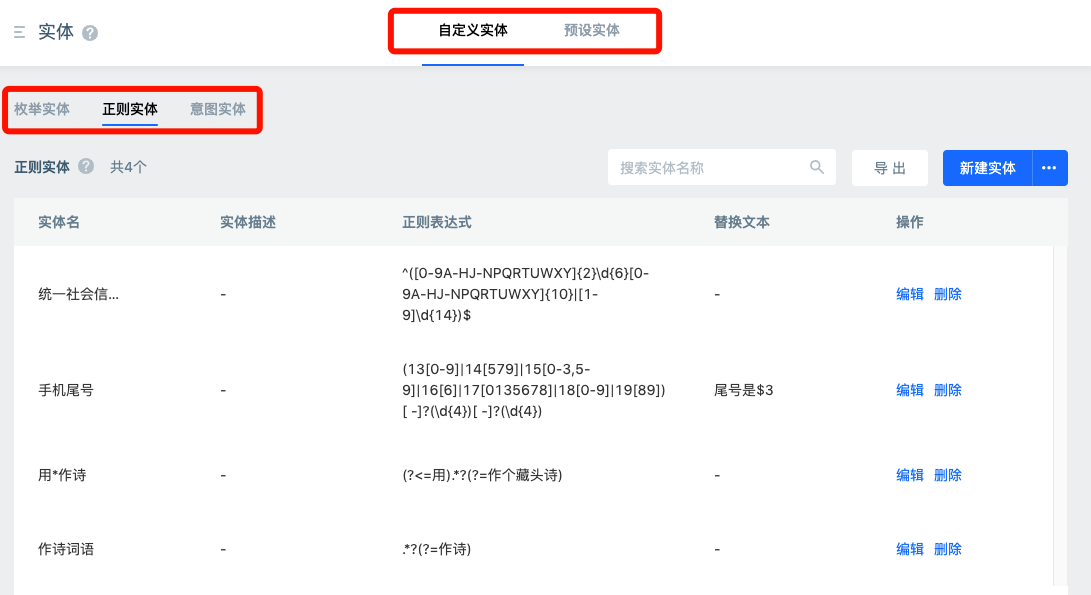
There are also some function pages with other structures. For example, under entity, there are user-defined entity and system entity. Under user-defined entity, there are enumerate entity, regex entity and intent entity.
1.1.2 Dialogue Design
Dialogue design module, input on the visual product page to realize the efficient building of dialogue agent, including
- Keyword matching rules Can response to messages containing or equal to a certain keyword;
- FAQ knowledge base Able to answer vague questions;
- Task dialogue Support the construction of structured product knowledge map and FAQ dialogue; Provide graphical design tools to drag and drop on the front-end page to complete multiple rounds of Task dialogue construction of business design; Provide a Task Process engine that can jump flexibly across scenarios;
- Debug agent Quickly verify FAQ ability, obtain and feed back system operation information, and facilitate test optimization;
- Custom chat A small talk library that can customize the content of response;
- Open chat Open chat trained by millions of chat corpus;
- Thesaurus Provide the ability to manage and define domain vocabulary, entity and various expressions;
- Response strategy Support the intelligent response of each module and the response policy of response with customized priority;
- Personalized experience Configure the welcome message and personalized response, view the preset attribute and configure the custom property attribute.
1.1.3 Effect Optimization
The agent effect optimization module has accumulated technology and products for many years, including the embodiment of the platform's artificial intelligence core capabilities, including:
- Corpus management Manage corpus data uploaded locally.
- Excavate Including phrase and sentence mining. Phrase mining can help to find professional words, entity, etc; Sentence mining helps cluster similar sentences to form knowledge points.
- Example learning Agent's uncertain example will be placed in example learning, where it can be merged into existing knowledge points intent or new knowledge points intent.
- Model optimization It has four functions: model training, online annotation, model evaluation and model release. Model training can train models that belong to this knowledge base (the default is a widely used general model); Online tagging can evaluate the right and wrong answers to a single question; In the model evaluation, we can compare the accuracy and recall of the agent's answer with the annotation results; By analyzing the results of model evaluation, the appropriate model and threshold can be selected in the model publishing module for publishing.
- Knowledge base optimization The health degree of the knowledge base based on the percentage system is used to measure the good degree of the construction of the FAQ knowledge base.
1.1.4 Data Analysis
The data analysis module counts the interactive data generated by the platform dialogue agent from the multi dimensions of dialogue type, agent, user and business, which provides a data decision-making basis for agent optimization and business development.
- Data overview Count the session data of agent interaction.
- FAQ dialogue analysis Including knowledge points and the use of keyword. The use of knowledge points counts the recall rate and accuracy rate of FAQ dialogue through daily data and hourly data; Keyword counts the trigger times and trends of each keyword rule by day.
- Task dialogue analysis It mainly analyzes the use of intent and the conversion rate, counts the number of trigger of the daily and hourly Task agent and the triggering of the dialogue unit, and can also customize the conversion rate path to share the conversion rate.
- Example learning statistics It reflects the operation records and statistics of the example learning module.
- Session log The message data generated by the interaction between all users and agent can be viewed and exported through sessions and message records. User feedback includes knowledge satisfaction and Task information collection. The knowledge point satisfaction interface counts users' satisfaction with knowledge points and can view the corresponding satisfaction context; It summarizes the information collected by the "slot collection unit" in the Task dialog, and can be exported in tabular form.
- User analysis View the user data that all agent have interacted with, manage user information, and maintain user attribute.
1.1.5 Instant Communication
Instant communication carries the ability of manual customer service to response to user messages, including:
- Conversation Access and quickly response to the customer's page with the help of agent.
- To be accessed Queued users enter the "to be accessed" and are accessed or closed manually.
1.1.6 Channel Setting
Channel refers to the medium through which agent interacts with end users.
Assuming that you have built a agent, if you want to make agent serve your end users in wechat official account, enterprise wechat, applet, official website or your enterprise app, you need to achieve it through channels.
The channels provided by the platform include: wechat official account, enterprise wechat self built applications, nailing internal agent, wechat applet plug-ins, web SDK and experience robot based on Web SDK.
In addition, more channels can be called and connected through the interface of the open platform.
1.1.7 Other Basic Configurations
In addition to the above main functions, the platform also includes the following modules:
- Agent management You can select, create agent, modify and delete agent, etc.
- Business management You can add administrative user permissions, view login logs and service availability.
- Message center Display new features and release messages.
- Help center Provide access to product manuals, interface document, novice guidance and offline notification.
- Account management You can set personal data, modify online and offline status, set prompt pop-up screen and prompt tone, and exit account.
- Account type You can view version information, maintain version upgrade information and view service support information here.
The platform has no installation package and can be run directly in the browser. The website is platform.wul.ai , Chrome 63 or above is recommended.
1.2 Types of Dialogue
Typical dialogues can be simply divided into single round dialogues and multi-round dialogue according to their forms.
Most of the single round conversations correspond to the situation of one question and one answer. The characteristic is that the answer does not need to depend on the user's scene.
A single round of dialogue is often completed by using keyword rules and FAQ knowledge base dialogue. In case of confusion, we often use Task dialogue reading such as tabular knowledge map to answer.
The keyword rule dialog is used to make a specific response or action to a user's specific vocabulary. For example, we often receive marketing activities from major manufacturers, and response "cash gift" to get preferential treatment.
The FAQ dialogue is used for a specific response to a complete question, which is similar to the high-frequency working scenario of traditional customer service. After the user indicates a intent, he finds a specific response from the common FAQ to the user.
The remarkable feature of multi-round dialogue is that the answer depends on the user's interaction. The user's answer has a great impact on the next round of agent response.
We mainly rely on the Task dialogue to complete the multi-round dialogue. By configuring the corresponding trigger, query and slot filling, and operation jump logic, users can handle a variety of things.
It should be noted that the construction of Task dialogue also requires clear logic and experience in building FAQ dialogue, because most of the two logics are consistent in intent recognition. Similarly, it is wrong to separate FAQ from Task. When facing users, FAQ and Task are a whole.
In addition to the FAQ type dialogue and Task type dialogue, there are also chat type dialogues. The greetings knowledge is often invalidated by using FAQ dialogue. There are also a variety of ways to implement chat dialogue in a broader sense, but it is rarely involved in business oriented scenarios, so I will not discuss it here.
Let's start with a simple example of a FAQ and a Task conversation.
In order to facilitate your use and experience, we began to explain mainly with the dialogue AI platform (online version). In the subsequent chapters, we will add the features of other agent products. We hope that you will not stick to specific products, but have a strong knowledge transfer ability.
1.3 New Agent
After logging into the platform, the first thing you see is the agent management page. The agent management page is divided into "my agent" and "new agent".
Click the agent card to switch it to the agent in use.
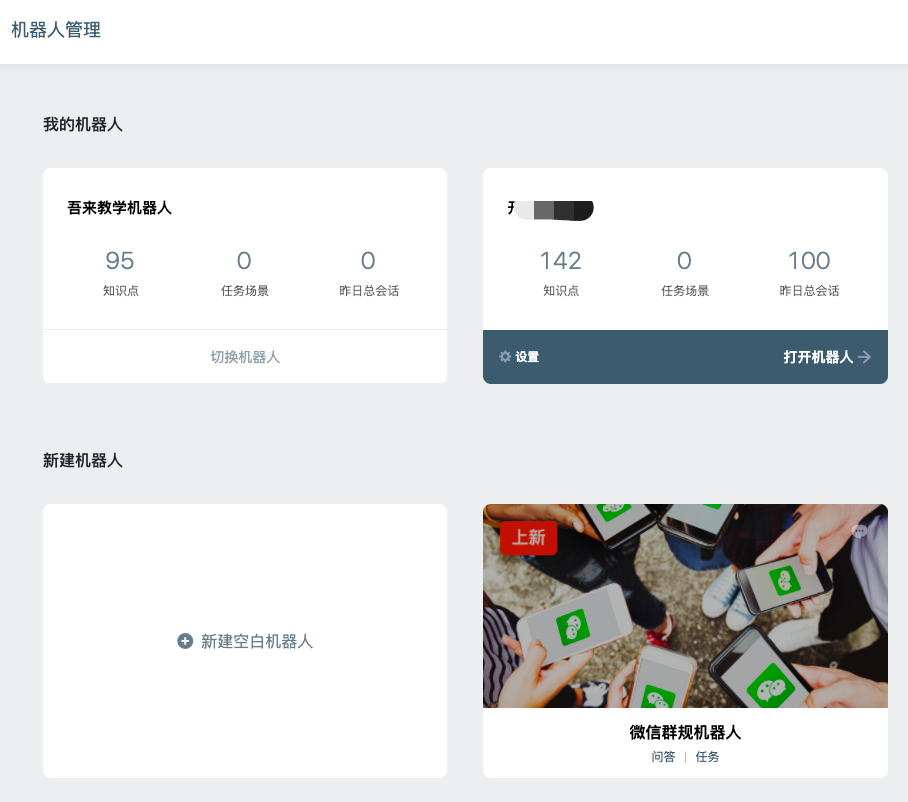
In the new agent interface, you can select "new blank agent" or "new agent with template".
1.3.1 Create a New Blank Agent
Click new blank agent. Enter the name of the agent, select the required language and type of agent and click OK.
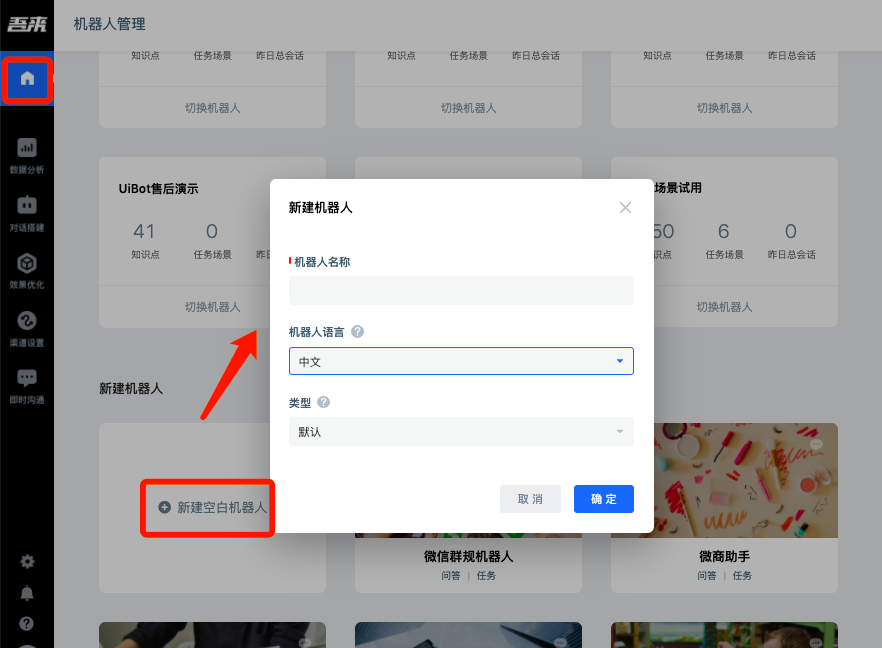
The new blank agent has no business data. It needs to build a agent from scratch. All configurations are default. There are many switches that need to be configured according to the project requirements.
1.3.2 New Agent With Template
Click the template agent you want to use and select "create a new agent with template".
Typical knowledge of the scene is preset in the template agent. The typical Task dialogue or FAQ dialogue of the scene has been built. The corresponding threshold and channel settings have been configured. It is a good material for reference and learning.
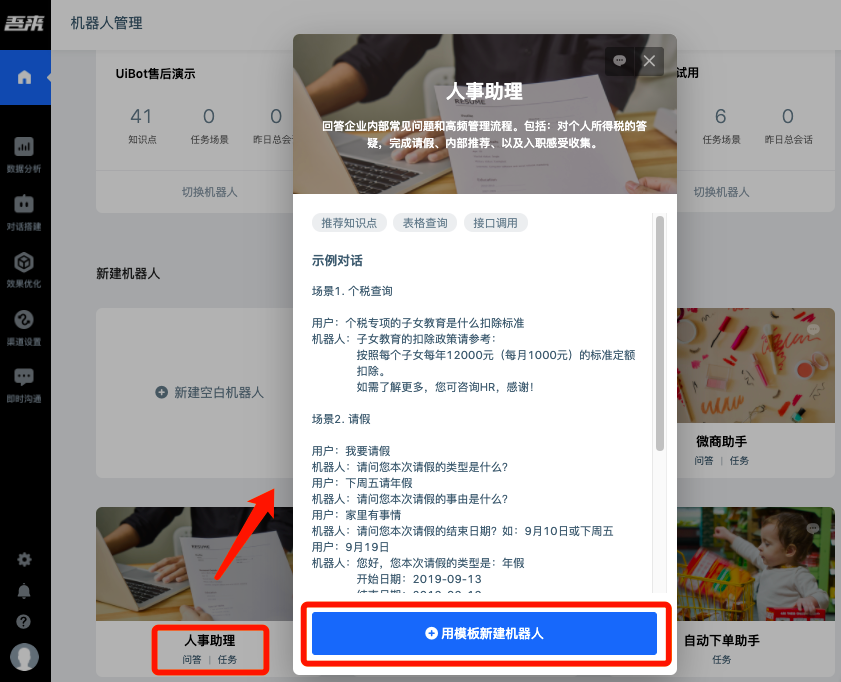
Note: the template agent card has a brief introduction, key points of function use and example dialogue, which can be experienced by clicking the dialogue button in the upper right corner.
1.3.3 Modify Agent
Click the setting button on the agent card to enter the agent setting, modify the agent name, copy or delete the agent.
1.4 Brief Example of FAQ Dialog Configuration
Example scenario: answer user's questions about issuing income certificate.
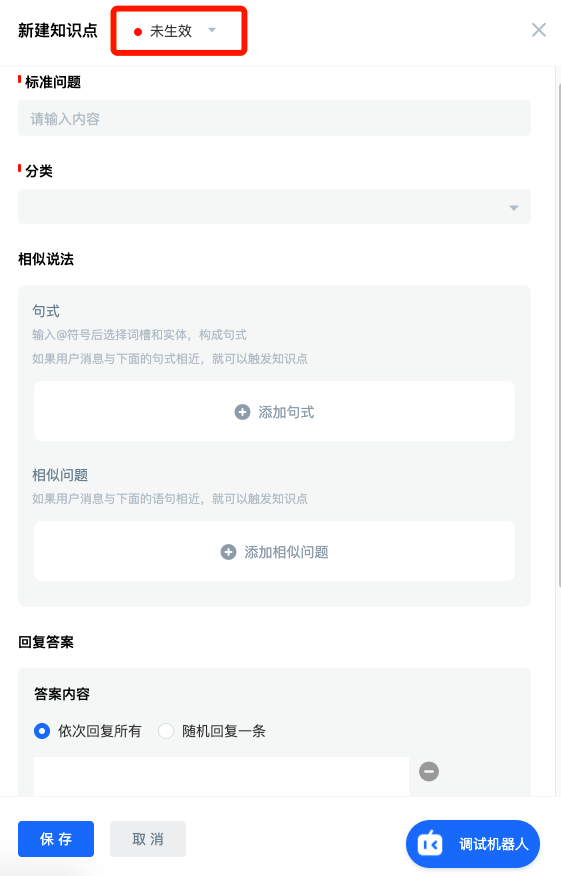
This scenario first needs to name the knowledge asked by the user, that is, the standard question, and simulate an answer. It should be configured in the knowledge base as follows:
- The effective status of knowledge points is switched from "not effective" to "effective".
- Enter "how to issue income certificate" in the column of standard questions.
- Category we have not yet created another Category, so we choose "default Category".
- In the similar questions of example, it is better to enter more than 10 questions to express how to issue the income certificate. If it is in typing status, you can click "enter/return" after entering a sentence to quickly add and switch to the next line.
- Finally, enter the answer "income certificate processing needs...".
- Click save.
After completing the above steps, you can "debug the machine" in the lower right corner of the window to experience the effect of the dialogue, and try to ask "help me get an income certificate".
You can see the results understood by the agent in the background on the right. In semantic understanding, we can see that the word segmentation is "help me get an income certificate", and the entity is not extracted, but the "FAQ dialogue" is triggered.
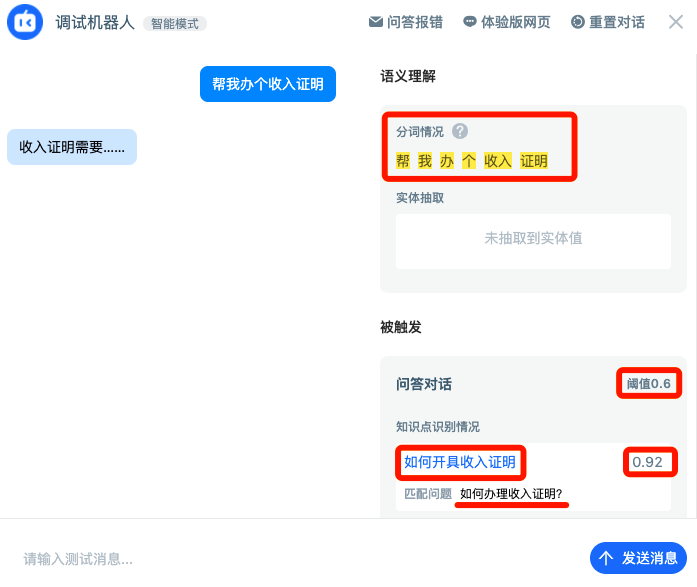
The knowledge point triggered is "how to issue income certificate", and the closest matching question is "how to handle income certificate". After comprehensive scoring of several models, the results show that the confidence of "help me do an income certificate" and "how to handle income certificate" is 0.92, exceeding the current threshold of 0.6, so we can directly deduce the answer "income certificate needs...".
It is easy to find that when answering, the agent does not require that the user's questions must be exactly the same as the entered similar questions. It has certain judgment ability.
Like this, when the user asks a question, the agent response to the knowledge points, which is a recall. If the agent response to the knowledge points is still correct, it is an accurate recall.
1.5 Brief Example of Task Dialog Configuration
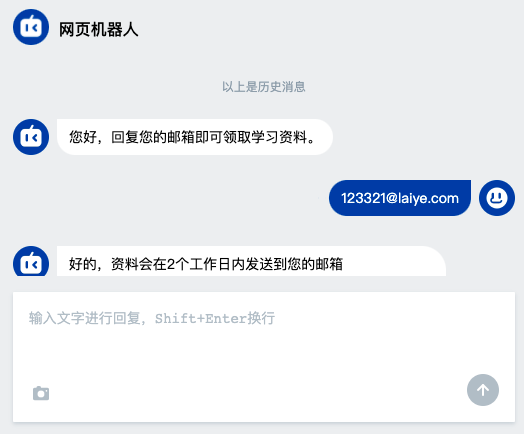
Example scenario: take a scenario of distribution of learning materials as an example. You need to ask the user's email as a reference for later distribution of materials.
Customer service: Hello, you can get the learning materials by response to your email. User: Yes 13812344321@laiye.com Customer service: OK, the information will be sent to your email within 2 working days 13812344321@laiye.com 。
Here, we focus on getting the user's email. It's better to sort out these user feedback mailboxes for later use.
To build such a dialogue, we need to use 任务对话 modular. Step 1: if there is no scene, you need to create a new scene first.
1. Create a New Scene
In the dialog setup - Task dialog - scenario list, click new scenario, and set the name and specific description in the scenario settings. If there are no special requirements for the "general session", "idle waiting time" and "intelligent slot filling threshold" modules, they can not be modified first.

Scroll down and select "auto add preset response" and "close" (because this scenario is inappropriate for user email recommendation, it cannot be ruled out that a person fills in multiple email addresses and cannot recommend email addresses written by others).
After setting, click OK to create a scenario. It is recommended that all the newly created intent be placed under one scenario.
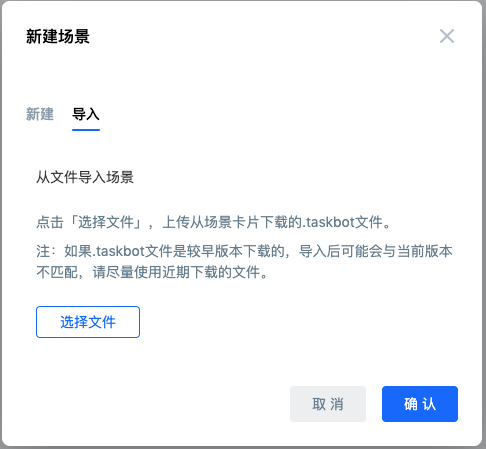
In addition to creating a new scene, we can also import the scene if it is an existing scene. The scene file needs to be exported from the platform Taskbot file.
2. New and Effective Intent
Click the scenario card to enter, click "create intent", the name of the intent is "send data", and click OK to create a new one. In addition, you can use import intent to import.
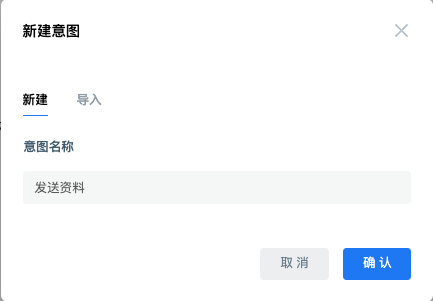
Next, change the intent of "sending data" from "not effective" to "effective".
3. Add Trigger Method
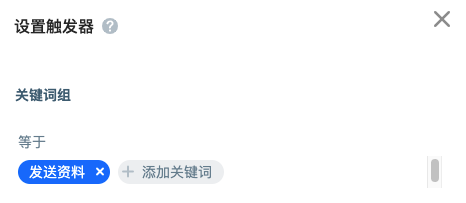
With the trigger mode, the agent can be started smoothly. Click "set Trigger" and add "send data" under the key phrase - equal to. In this way, the Task can also be started when debugging the agent or sending "sending data" through other channels.
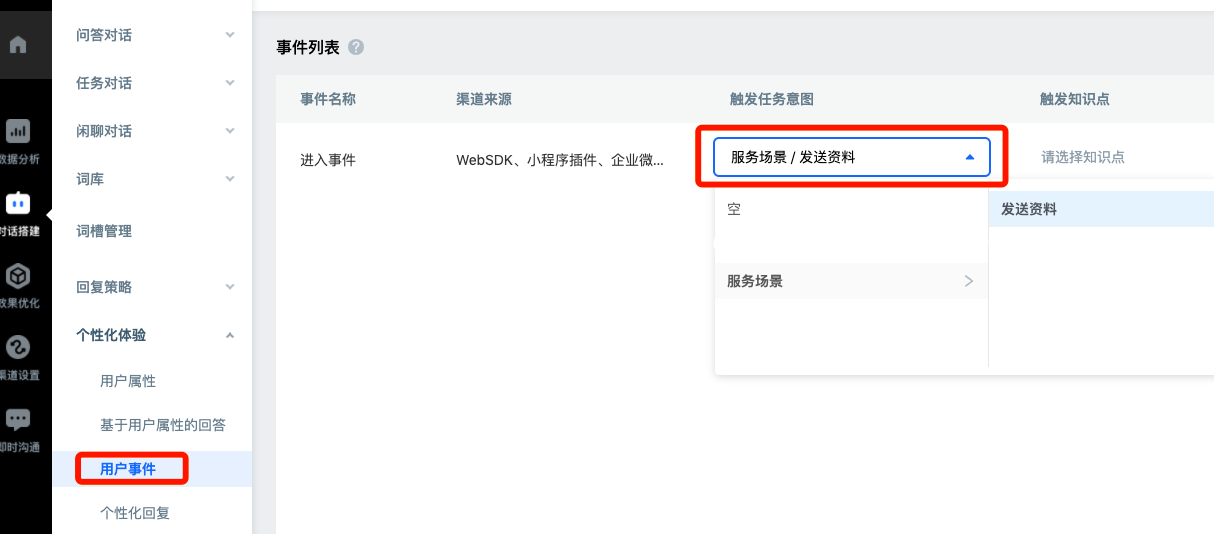
In order to facilitate users' use, you can also configure the trigger mode in dialog building - personalized experience - user events. In this way, once channels such as the experience version web page are opened, the agent can start working to collect mailbox information.
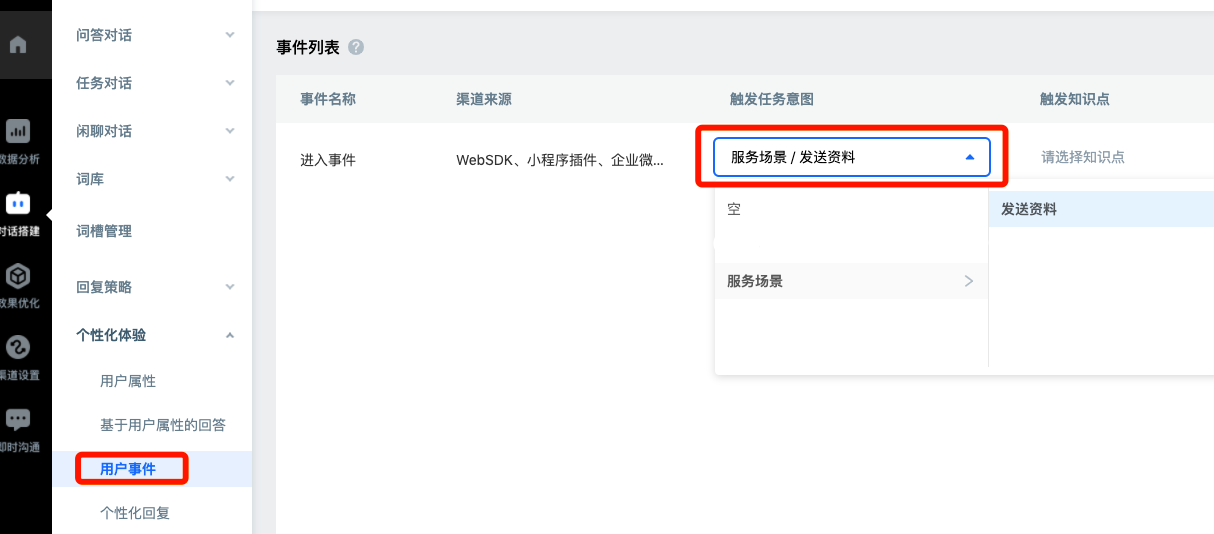
4. Canvas Operation
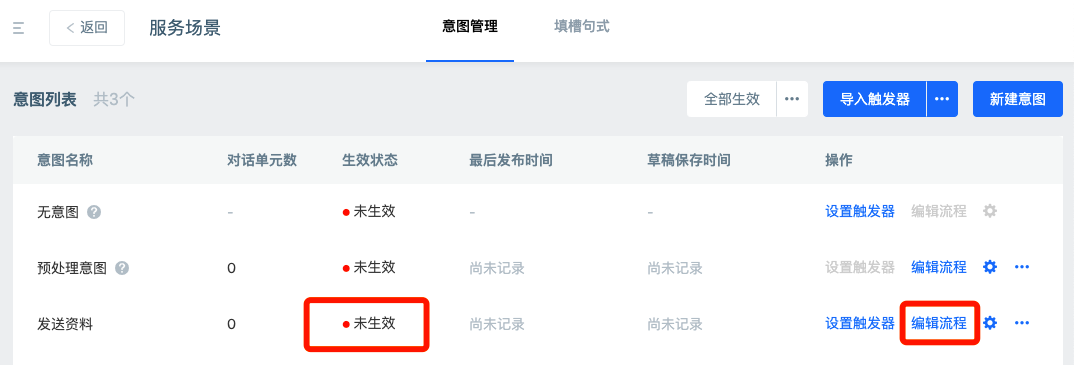
Go back to the dialogue setup - Task dialogue - scene list, find the intent and click the corresponding "edit Process" to enter the agent canvas.
On the left side of the canvas is a list of dialogue units. The upper menu bar is the "back" button, scene name, intent selection, last release time, intent setting, restore the previous release and release intent.
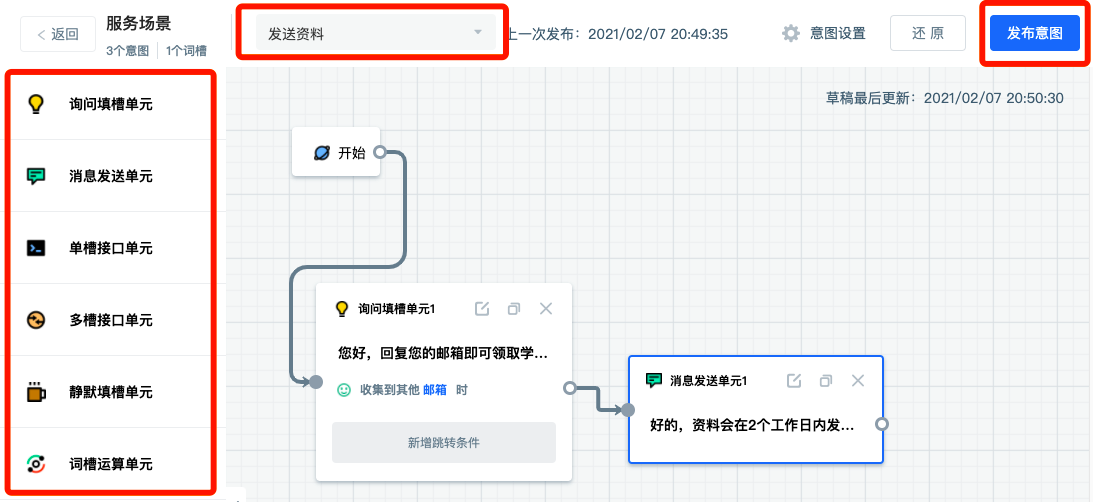
According to the dialogue example, we start from the question of the agent. At this time, we use the Request Block. We can click or drag to add a unit.
The buttons in the upper right corner of Request Block are "Edit", "copy" and "delete".
Click the "Edit" button to enter the inquiry unit, and fill in "Hello, response to your email to receive the learning materials" in the "inquiry statement" The preset response button can be used to place input prompts such as "confirm", "previous" and "exit". Here we try to fill in "exit".

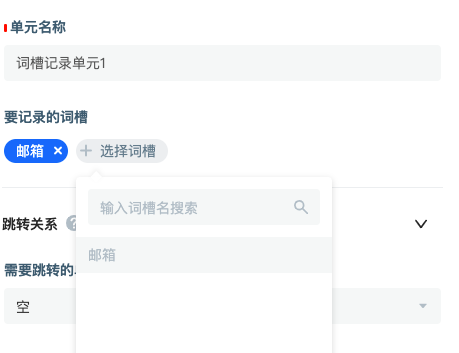
After the user's mailbox is collected, a slot is needed to store it, which can be used later. Like this, you need to click the associated slot to create a new slot. The name of the slot is "mailbox", and the referenced entity is also "mailbox". If the slot is used to store, the entity is used to filter the information that can be put into the slot.
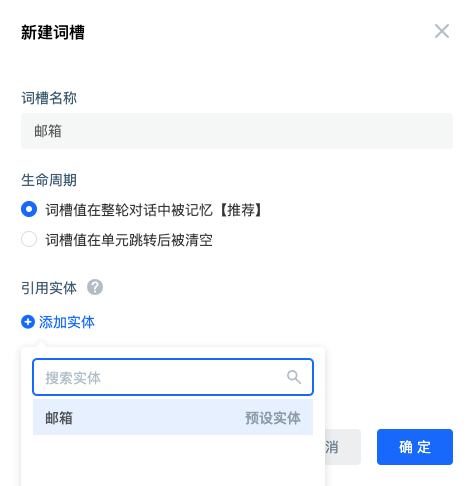
After configuration, this is usually the case. The interface is like this, and then select save. "Dialogue strategy" and "jump condition" are not involved this time. The default configuration is adopted. If there are other policy requirements such as questioning, you can choose to configure them.
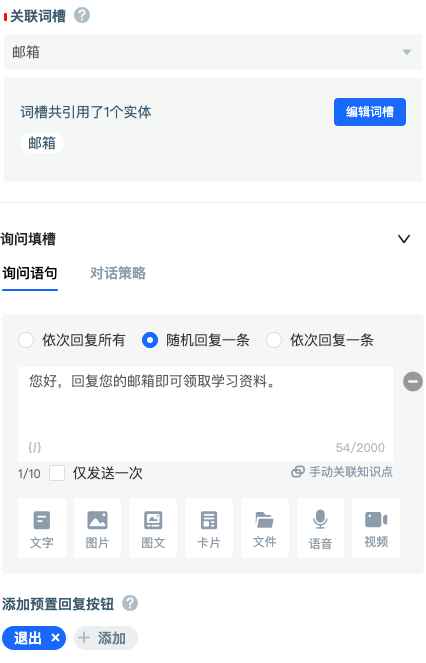
By dragging a line from the right side of the "start" to the left side of the "Request Block", it tells the agent that it needs to flow to the "Request Block 1" after starting.
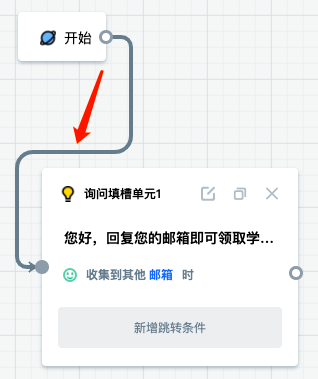
After asking the user's mailbox, we need to send a message to the user. Here, we use the "Inform Block" to send messages. Note here that the mailbox in the example is replaced by our slot "mailbox" so that the information that the user just used to fill in the slot can be displayed.
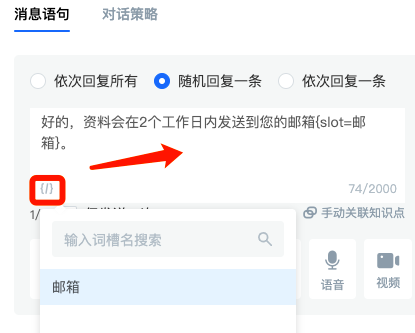
Connect the inquiry unit and the message unit.
5. Release Intent
After saving, click publish intent in the upper right corner. After release, you can debug the agent and experience version web pages for rapid testing.
From debugging the agent, we can see that after we triggered the agent through the phrase "send data", we entered the intent of "service scenario - send data". The email address obtained by the agent is“ 123123@laiye.com ”。
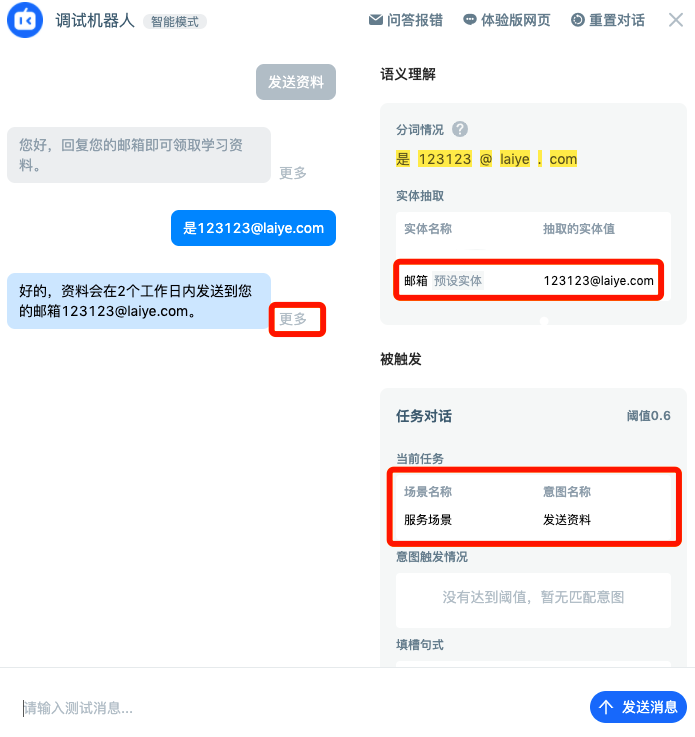
Down you can see that after two units, use“ 123123@laiye.com ” Filled the "mailbox" slot. Click more to view the details of agent operation.

- If we need real use, we also need to enter the experience version web page for testing, and click the "experience version web page" button in the upper right corner of the debugging agent to enter. After configuring the entry event, there is no need to input and send data when opening the web page.
- If you want to record the mailbox, you can follow it with a slot collection unit.
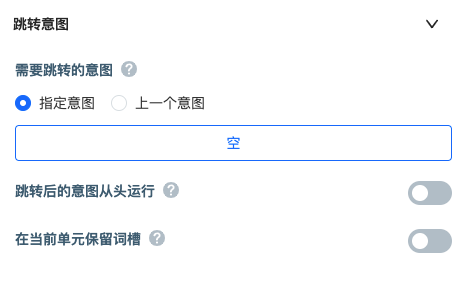
- If the user needs to be able to enter repeatedly, it is OK to follow a intent endpoint unit.
1.6 Configuration Example of Dialog Style
According to different channels, agent displays different degrees of freedom. Some functions can only be supported by channels. In the following explanation, if the channel configuration is different, if it is not explained, take the web SDK channel and its generated experience version web page as an example.
1.6.1 Welcome
The user oriented welcome message is configured in the dialogue setup - personalized experience - user event, and can start with a Task or knowledge point.
1.6.2 Name, Portrait and Color of Agent
In the channel settings web SDK page style, you can customize the name, avatar and color of the agent.
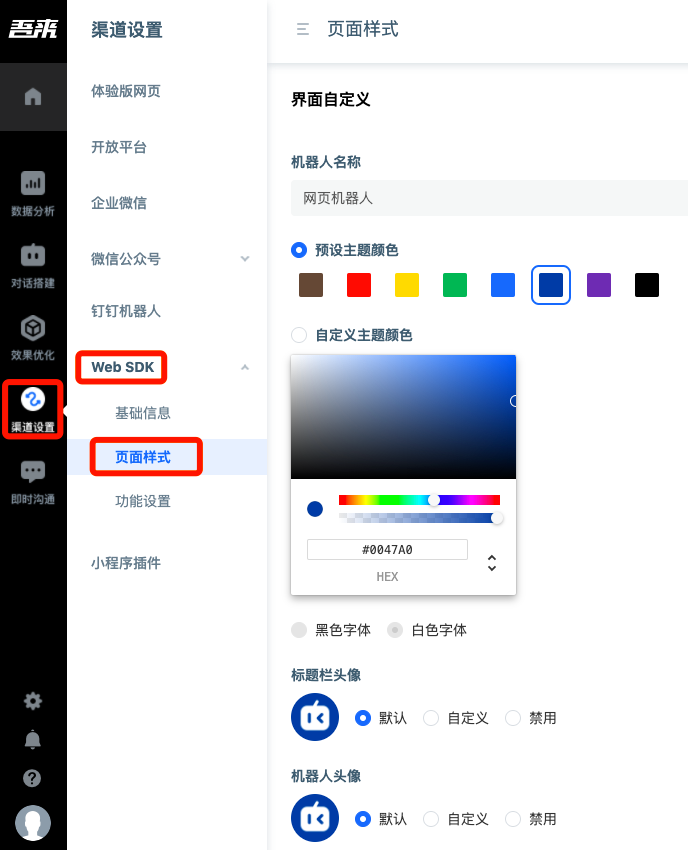
1.6.3 Historical Session Record, Automatic Pop-up Invitation, User input Association, FAQ Satisfaction Collection
In channel settings web SDK function settings, you can set functions such as displaying historical session records to users, automatic pop-up invitations, user input associations, and FAQ satisfaction collection.
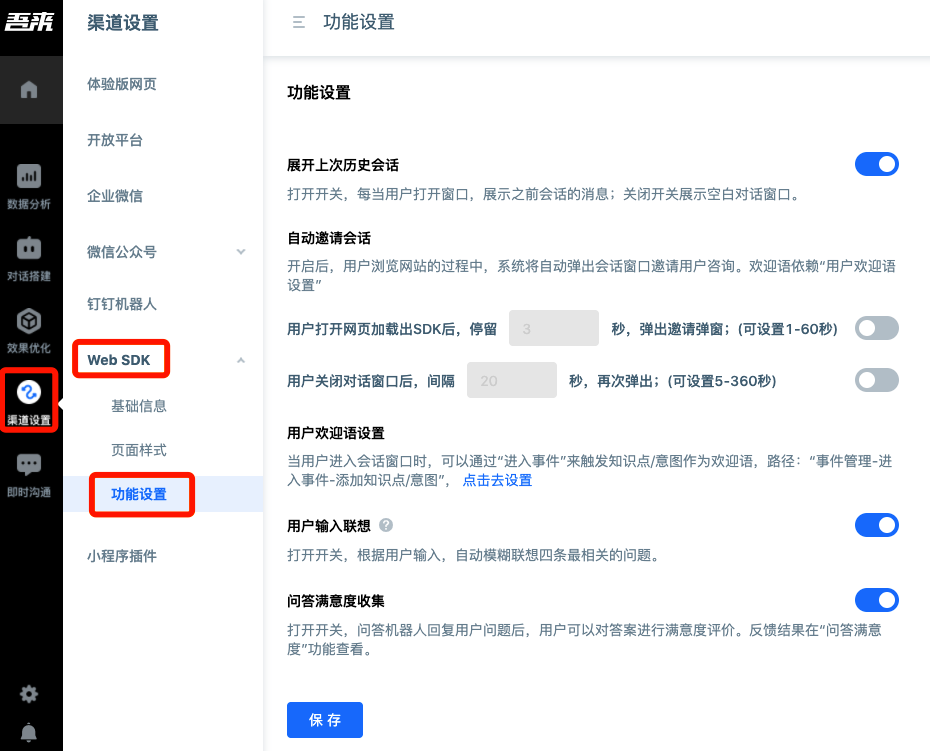
1.6.4 Fallback Response
From the dialogue setup - response strategy - agent strategy, you can find the fallback response settings. Fallback response is a response provided to the user when the agent thinks that it cannot accurately answer the user.
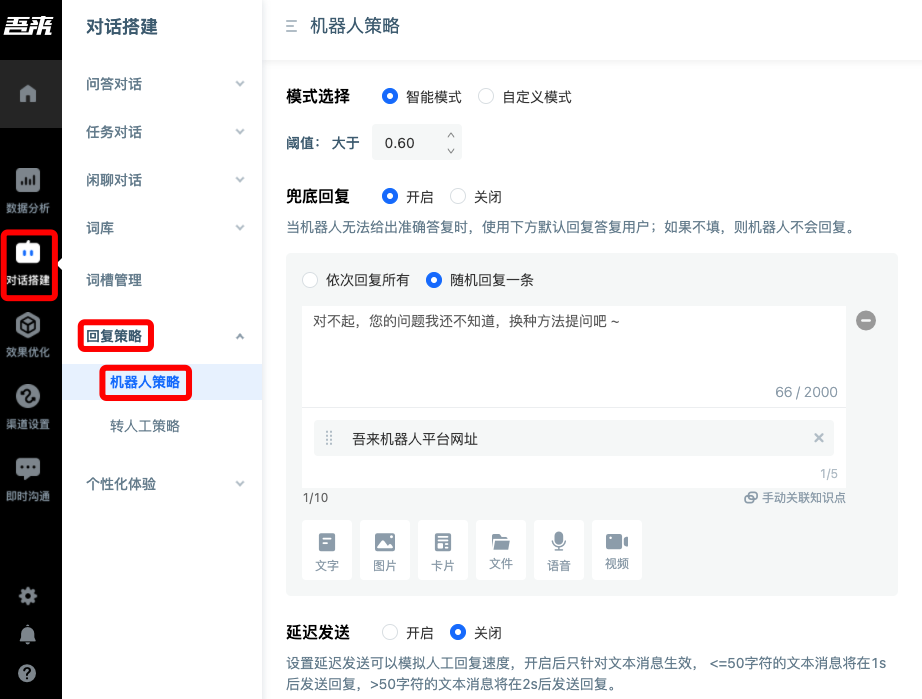
1.6.5 Setting of Similar Knowledge Points
In addition to giving the answer directly, you can also recommend several questions related to questions for users to click, so as to improve the efficiency of serving users and improve the user experience.

1.7 Project Process Introduction
1.7.1 FAQ Construction Project Case
In the case of simple scenarios and one person's operation, a main line should be made clear at the beginning of knowledge base construction. Knowing the logic of knowledge point Category can basically clarify how to build the knowledge base.
However, when the business line of the company becomes wider, the product line becomes longer, the Process becomes more complex, and there are more corpora (corpora, usually referring to historical chat records, work orders, etc.), it is difficult for one person to build the entire knowledge base in case of time urgency.
Work Precautions
When building the knowledge base, it is recommended that the staff build it together and sit together for communication.
In terms of experience, things that can be solved in half a minute face-to-face often take 3-5 minutes for remote communication, and even the accuracy of face-to-face communication will be higher. It is best for two people to build together to clarify the content of the knowledge base.
During the construction, pay attention to the clear division of labor according to the Category. The personnel responsibilities under the division of labor of each part can be clear according to the Category logic. When there are more than 3 people, someone needs to be responsible for inspection and guidance to control the quality and progress of knowledge base construction.
In the later stage, changes in the level of knowledge points (adding, merging, deleting knowledge points, moving and modifying Category, etc.) should also be synchronized to all joint participants so that they can understand the changes in time and avoid unnecessary communication costs.
During the construction process, it is necessary to clarify the construction stage, switch the construction strategy in time, and cooperate with each other in mining, testing and optimization.
Let's take a practical case of consumer credit scenario:
In the early stage of the project, we can properly sort out the Gantt chart of the project, supplemented by the description of the responsibilities of both parties, and explain the work to be done by both parties in advance.
In this way, we and our customers will know what implementation resources we should have and what manpower we need to allocate. The above knowledge base is planned according to 20 person days for one person.
From experience, using SaaS historical corpus to build a knowledge base can achieve an average of 20 knowledge points a day in the whole Process. The number of knowledge points will be less in the early and late stages of the project, and more in the period of centralized construction.
Private deployment projects are about 1 / 3 slower because of communication, remote, or other influencing factors. On average, one person can complete 15 knowledge points a day.
For policy projects, due to the lack of relevant corpus and other influencing factors, the expected knowledge points and answers often deviate from the actual questions of users, and there are relatively many that need to be repeatedly communicated and modified in the later stage, with an average of about 10 knowledge points per person per day.
Preliminary Preparation Corpus Preparation And Cleaning
Before the work officially starts, we need to make some preparations to sort out the chat records of users in the early stage into a format that can be imported into the system.
Before the start of the project, we received 4 g conversation data from users. Because of the large amount of data, we confirmed that we need to solve the basic cleaning problems through database and other technologies.
The purpose of cleaning is to retain valid user questions.
Generally speaking, when the number of corpus is relatively large, we can keep the user's valid first sentence. In recent years, there are also corresponding corpus cleaning tools that can be used, If the amount of data is less than 300000 lines, it is also very convenient to use Excel for processing.
Note that the test set is retained after cleaning and before excavation.
1. Construction Training
Because customers or outsourcing personnel do not know much about the knowledge of building a system knowledge base, we must first carry out training so that the builders can understand the working logic of the agent and the method of dividing knowledge points.
The training of knowledge base construction should be attended by all students who participate in knowledge point mining.
2. Category Quick Confirmation
After the training, we invited business leaders to sort out the Category structure of the entire knowledge base.
The knowledge base Category confirmation will take about 1.5-2 hours. It can also be communicated in advance. After the training, it will take another half an hour to confirm.
Category is basically based on the formula“ One main line, the other side; If there is repetition, do Kung Fu early ” To divide and define.
First of all, the core thread we determined is the user life cycle. In the user life cycle, the main line of the whole life cycle is from the first intent of the user to the last intent of the user.
The customer's main business is to issue loans, so the main Category of the user is to fill in the data, review, loan application, then repay the loan, and finally cancel the user.
For this main line business, there are many other businesses to support this business, such as APP, micro signal, Alipay, small program and other channel applications, and thus produce other side branches. There are some knowledge points, for example, how to register in WeChat binding, APP registration, APP operation, such as modifying mobile phone numbers, etc.
"Repetition, early effort" means that sometimes a Category or knowledge point will appear in each part of the main line. If there is no obvious logic, it should be placed under a Category. At this time, we will put it in the place where it first appears.
Generally, it is suggested that there are 5-20 knowledge points under one Category. If it exceeds the Category of detachable molecules, less than 5 can be combined appropriately according to the situation.
Why A Good Category
The Category of knowledge points is like the skeleton of a agent. After the skeleton is determined, we can confirm where our knowledge points should be placed. A chaotic Category will cause the business personnel to not understand the Category to which the knowledge points should belong. Of course, the agent cannot be built well.
Only with clear Category can we find out how similar questions and knowledge points should be placed when building the knowledge base.
3. Excavation
Mining: extracting a set of similar problems with the same intent from the disordered corpus.
(↑ that is, gather the questions of users with the same meaning into a pile from the chat record)
After the Category is confirmed, we gradually assign Task to the business personnel participating in the mining according to the main line of Category
Note that it is not necessary to divide all the Category All tasks for the first time. According to the speed of the work progress, we can divide the work content into several parts and distribute them step by step.
After the corresponding Category work is completed, the Category work can be accepted. The main acceptance items are as follows:
Ask the main questions under the Category to see if they can be answered normally;
Enter the keyword mining to check whether the corresponding Category has been completely mined (when a new mining corpus is not added for one mining);
Check whether necessary domain vocabulary and its synonyms are added;
Check whether the similarity questions are clean and include the knowledge under other Category (the knowledge base optimization function can be used first);
When all the work is completed, we need to supplement the knowledge points that are excavated but the number of similar questions is not enough. Generally speaking, 10-30 similar questions are enough.
The functions used in the process of excavation and construction mainly include the following four functions:
Corpus management It is mainly to put the cleaned corpus into the corpus.
Sentence mining Use sentence mining to cluster the uploaded corpus. Mining by Category mainly uses keyword mining (clustering according to key words); If a single person fully excavates, the machine mining (automatic clustering according to the similarity between sentences) function is generally used.
Advanced functions of knowledge point configuration - Mining Based on the existing similarity questions in this knowledge point, calculate the important keyword, find the possible related problems in the corpus to be mined according to the keyword, and add them to this knowledge point as similarity questions after selection.
Example learning Example learning function: in order to check and fill gaps, existing knowledge points can be used to automatically identify user questions (Corpus) to form a pending review, which is convenient to add. PS: the example learning function is also very useful during the operation period.
The usual application strategy is: after the corpus is uploaded, the mining function is mainly used in the early stage of the construction, the mining function is used in the middle stage to supplement similar problems in the configuration of knowledge points, and the example is used in the later stage to learn to check and fill gaps.
Tips
After the initial construction is completed, before and just after the launch, we can run the knowledge base health evaluation to see whether the score is above 90, and check whether there are similar questions and misplaces, or there are problems in the classification of knowledge points.
It is recommended to regularly review whether the correspondence between all similar questions and knowledge points in the knowledge base is correct before going online, after a large number of changes are made to the knowledge base, and half a year after the operation of the knowledge base.
Review refers to expanding the similar questions of each knowledge point and manually rechecking whether there are errors or non-conforming ones.
4. Real Corpus Inspection
The corpus of the test set we reserved in the early stage is now in use. 200-500 pieces are extracted from it for model evaluation and annotation accuracy (online annotation function can be used. Note that there is no semantics and choose to ignore or delete).
Generally speaking, customers often make some small problems in the process of building for the first time, resulting in low initial call accuracy, generally between 70-80%, and 80-90% for mature trainers.
Then we optimize according to the evaluation results and pay attention to summarizing the main problems. After one or two rounds of optimization, we can reach the level of more than 90%.
Optimization can use supplementary corpus to import example to learn and form functions to be reviewed and supplemented.
Tips
During the evaluation of the knowledge base, the answers should also be checked by business students to find and modify the questions in the answers. For the relevant precautions of response, please refer to the experience of adding agent response.
5. Launch And Optimization
After reaching the online standard, we can start docking (pay attention to manual logic, welcome words, related problems, and fallback response when the agent doesn't know). After docking, we need to do necessary tests (SAT, UAT tests); After the test meets the standard, we can consider going online.
For some large-scale integration projects, we will also do development docking while building, and agree on the form of response and other project considerations in advance.
In the first week after the launch, we should pay attention to the user's questions, select 200 pieces of data every day, mark and optimize, and pay special attention to high-frequency questions and errors.
In this case, after we launched the knowledge base to the corresponding channel, we soon found that the common questions of users in a specific channel were not covered, and some errors occurred in the recall a few days ago. After timely adjustment, this problem will be solved.
Only after the agent finds the problem and makes timely adjustment can we give users a better experience.
1.7.2 Brief Description of Task Planning
Briefly, we need to confirm the following aspects and clarify the work of both parties during the docking period:
First of all, most customers don't know how to distinguish the details of Task. This requires us to work with customers to sort out what links need to be divided between Task and Task, what Task of each small link need to be completed, what are the priorities of these links, and when a user will complete Task?
The second point is to sort out the elements of the Task. What information do we need to get from users? Will users' browsing paths affect their FAQ performance and the services we provide?
Whether we have summarized the information that users need to provide in advance, and whether it can be directly used as a entity, domain vocabulary, etc. in the later stage, whether there is a ready-made Process system, or even a Process diagram.
The third and fourth points are respectively sorting out dialogue cases and refining Task Process.
Dialogue cases should reflect typical Task scenarios. What can users do? What should we pay attention to at the beginning and end of the service, how to complete this closed loop, and some key Task function effect diagrams.
To refine the Task Process, we need to sort out the scenarios, intent, slot and entity, define Process rules, master the limitations of Task, and agree on the exception handling methods for goodwill sorting. Here are some simple illustrations:
Sample dialogue writing
| role | User / agent response | note |
|---|---|---|
| user | I want to [charge] | Remember the answer |
| AI | OK, do you want to charge 10 yuan, 30 yuan or 50 yuan? | Show option groups |
Query logic design
| number | Interrogation script | Name of collected information | Is it necessary | Slot filling information allowed |
|---|---|---|---|---|
| one | Which fund would you like to check? | That is, the slot to be collected, such as the fund name | yes | Fund name (the agreed client provides specific business information) |
Definition and arrangement of entity
| Entity name | Entity description | Entity value | Multiple statements |
|---|---|---|---|
| Fund name | Fund a | A base | Ax base |
If the relationship between each link is complex, we need to use the Process chart to represent the overall logical relationship. The following figure is a schematic diagram of an order query scenario.
If you need to show the logic of cross system cooperation clearly, you need to go further and use swimlane diagram to show relevant pictures. The swimlane chart is characterized by clear division of labor and clear objects, which is suitable for multi business cooperation.
Common handling of Task dialogues
The following are the logic that laiye technology has done in the project practice.
- Will the previous answer affect subsequent Task
Confirmation logic: in many information collection projects, we need to confirm the user's selection and input. According to the confirmation results, there may be options such as pass, fail, modify the filling content, etc; The logic of skipping questions, and the pre order answers cause the post order questions to need no answers, or different information needs to be collected according to different situations.
- What to do under special circumstances, such as the absence of mobile phone number
Whether it is necessary to input special prompts such as digit error. In some more detailed projects, it will even prompt various situations of mobile phone number, such as foreign mobile phone number, whether the digit of mobile phone number is correct, etc.
- What is the collection logic
How to record the user's answers during the collection process.
If the information of this user is only retained once, the slot recording unit can be used;
If the user needs to carry this property attribute for a long time later, write the unit record with the attribute;
If the user's response not only needs to be visible to himself at any time, but also wants to be visible to others, we use the table to write the cell.
In addition, in some marketing scenarios, users have realized what they are interested in. Although they do not ask questions, they need to record the needs of the property attribute; Moreover, if the user provides the mobile phone number in advance, it should also be recorded.
- Whether to configure description, previous step, exit and other steps
Explanation logic refers to how the user interacts with the agent to get the corresponding answers and explanations when in doubt.
Generally speaking, we can enable the intent to allow the user to ask questions and the agent to answer when the user intent fails to fill the slot, or we can configure the jump branch separately to explain.
Some users may want to go back to the previous step for selection. This can also be easily configured through the new functions of the platform.
In the communication process, it is basically necessary to consider whether the user can directly exit the Task. At present, personalized exit configuration can also be carried out at the scene setting.
- Permission control logic
Through the combination of table reading, attribute and other units, we can efficiently realize the configuration of white list, different answers by permissions and items.
Using the platform to build the Task dialogue part is often very fast, but we often need to spend time on debugging and other work.
1.8 No Corpus Construction Experience
Many of the projects and cases we talked about in the early stage build knowledge bases in scenes with historical chat records (with corpus). However, there is often a lack of relevant corpus in projects that have not applied the customer service system in history. How should such projects (projects without corpus) be built?
This paper will focus on the method of building a corpus free knowledge base project.
1. Specify application scenarios
Before the start of the project, it is necessary to clarify the positioning, nature and application channels of the project, and estimate the number of customers visiting and asking questions every day. Build a user portrait and find the user's concerns. In this step, you can also consult the user's existing service personnel or marketing personnel.
Before the implementation of the project, everyone's expectations should be clear. The application of agent can not directly bring traffic. What's more, it can serve existing users well, improve the transformation of existing users, and form a good reputation.
2. Split to form knowledge points
If there is no clear knowledge point in the project, you need to get the list of questions answered by customers, which can be used as the basic knowledge point of construction. If the customer does not have a list of questions, you can ask the customer to summarize some common questions and answers. In many cases, customers will directly build a knowledge base for a policy notice, handling manual, etc. at this time, it is necessary to disassemble the knowledge base manually.
Accordingly, when non business personnel disassemble the knowledge base and split the knowledge points from the text, they are prone to problems such as inaccurate grasp of business points and ignorance of the key points of customers' questions. So check with the salesperson after disassembly. Empirically, the time spent on dismantling knowledge points is 50 knowledge points / person day, which will change in case of special circumstances.
3. Generalize similar problems
With the corpus project, we find the user's questions from the chat records through clustering mining and other methods to form the similar problems of the corresponding knowledge points in the agent knowledge base, that is, the agent learning materials.
If there is no corpus for building the knowledge base, we need to first pick out the questions asked by users according to the existing situation or data, and then add similar questions through manual writing, crawling questions and other methods.
Manual writing is to simulate the questions of real users to add similar questions (after adding one on the platform, click "enter" to add the next one).
Empirically, the estimated time for adding similar problems is 200 pieces / person day, which will change in case of special circumstances.
In the process of long-term practice, laiye technology has also accumulated many methods to collect similar problems, such as laiye generalization platform and laiye technology R & D common internal tools to collect similar problems.
Its function is to input a sentence or a batch of sentences, generalize through different sources, and output other sentences with similar meaning to the target sentence.
Sources include:
Synonym replacement: use synonym Vocabulary for word replacement
Crawler: crawl multiple knowledge websites according to the input standard questions, and sort the similar questions after filtering
Whole network search: take the given web address as the object to search the required data, including the FAQ website by default
Make a long story short: shorten a long sentence into a short one
The test set of test bot can also be collected by these methods.
Analysis Of Items With And Without Corpus
From the background of the project with corpus (with chat records) and without corpus (without chat records), we can make this summary:
Difference Corpus Items Corpus Free Items Application Scenario Mature and long-term dialogue service Immature, new dialogue service Number Of Users Generally, there is a stable flow Not online, unknown Knowledge points Have common knowledge points Usually there are document, etc., but no chat records corpus There are chat records Not online, unknown
1.9 Concept Summary
| concept | Interpretation |
|---|---|
| FAQ dialogue | The FAQ dialogue is mainly to find and provide the information required by the user, that is, to find the answer to the user's question and response. |
| Task dialogue | Task dialogue is to help users complete a Task or operation. In this process, we also collect necessary operations that can help complete this information. |
| Chat conversation | Chatting dialogue is to meet emotional demands and maintain relationships through greetings or chatting. |
| Agent | A agent can complete a dialogue in a specific field; One platform account can create multiple agent; Among different machines, the data on the ⌈ platform ⌋ are independent of each other. |
| Confidence | The relevance of agent recall knowledge points or intent to user problems. |
| Threshold | The boundary of confidence interval; The thresholds for automatic response of all dialog types can be freely configured. |
| Fallback response | When the user's question cannot be understood by the agent, the agent response to the default content. |
| Knowledge points | Knowledge points = standard questions + multiple questions with highly similar semantics (similar questions) + one or more answers |
| FAQ recall rate | FAQ recall rate = number of messages of agent recalling knowledge points / total number of messages response by agent |
| FAQ accuracy | FAQ accuracy = number of messages that agent correctly recalls knowledge points / number of messages that agent recalls knowledge points |
| Intent | The Task that the user wants to complete; e. G. in the scene of querying train tickets, there are "query train tickets", "return train tickets" and other intent. |
| Slot | Key information to be collected in the intent; e. G. in the intent of querying the train ticket, the departure and arrival cities should be kept in the slot respectively. |
| Entity | Objects or key information that can be distinguished from other objects; e. G. "city" entity, the entity value includes "Beijing", "Shanghai" and other city names. When the user sends a message, the platform agent can extract the entity value from the message. |
| Dialogue unit | Define the minimum key nodes required by the intent; The intent is composed by organizing the dialogue units according to the business process. |