数据可用性
Mysql
info
来也科技作为一家 toB 的公司,在给客户做私有部署时,部署团队将为客户搭建三节点的 MGR 单主架构,作为底层存储。如果主库发生故障可自动切换;如果从库发生故障,可自动将其下线。
中间层采用多节点 proxysql 做路由。配置读写分离和故障检测,保证读写流量分发正确。
MGR 中,宕机一个 mysql 实例时,不影响业务正常使用;
MGR 中,宕机两个 mysql 实例时,不满足 paxos 投票,只可读,不可写。
proxysql 只要有一个节点存活,即可正常提供服务。(除非扛不住压力!)
MGR介绍
- MGR简介
MGR全称MySQL Group Replication(Mysql组复制),是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决方案。MGR提供了高可用、高扩展、高可靠的MySQL集群服务。在MGR出现之前,用户常见的MySQL高可用方式,无论怎么变化架构,本质就是Master-Slave架构。MySQL 5.7版本开始支持无损半同步复制(lossless semi-syncreplication),从而进一步提示数据复制的强一致性。
MySQL Group Replication(MGR)是MySQL官方在5.7.17版本引进的一个数据库高可用与高扩展的解决方案,以插件形式提供。MGR基于分布式paxos协议,实现组复制,保证数据一致性。内置故障检测和自动选主功能,只要不是集群中的大多数节点都宕机,就可以继续正常工作。提供单主模式与多主模式,多主模式支持多点写入。
- MGR原理
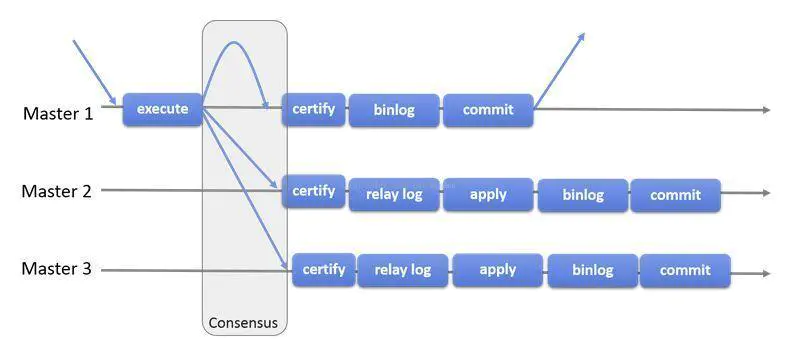
组复制是一种可用于实现容错系统的技术。复制组是一个通过消息传递相互交互的Server集群。复制组由多个Server成员组成,如下图的Master1、Master2、Master3,所有成员独立完成各自的事务。
当客户端发起一个更新事务时,该事务先在本地执行,执行完成之后就要发起对事务的提交操作。在还没有真正提交之前,需要将产生的复制写集广播出去,复制到其它成员。如果冲突检测成功,组内决定该事务可以提交,其它成员可以应用,否则就回滚。
最终,所有组内成员以相同的顺序接收同一组事务。因此组内成员以相同的顺序应用相同的修改,保证组内数据强一致性。
- MGR特点
高一致性。基于原生复制及paxos协议的组复制技术,并以插件的方式提供,提供一致数据安全保证;
高容错性。只要不是大多数节点坏掉就可以继续工作,有自动检测机制,当不同节点产生资源争用冲突时,不会出现错误,按照先到者优先原则进行处理,并且内置了自动化脑裂防护机制;
高扩展性。节点的新增和移除都是自动的,新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致,如果某节点被移除了,其他节点自动更新组信息,自动维护新的组信息;
高灵活性。有单主模式和多主模式,
单主模型: 从复制组中多个MySQL节点中自动选举一个master节点,只有master节点可以写,其他节点自动设置为read only。当master节点故障时,会自动选举一个新的master节点,选举成功后,它将设置为可写,其他slave将指向这个新的master。多主模型: 复制组中的任何一个节点都可以写,因此没有master和slave的概念,只要突然故障的节点数量不太多,这个多主模型就能继续可用。
服务可用性
可以使用命令在每台节点上检查mgr状态,或者通过部署监控可视化检查
// {mysql_user}: mysql用户
// {mysql_password}: mysql用户密码
// {mysql_host}: mysql地址
Input:
mysql -u{mysql_user} -p{mysql_password} -h{mysql_host} 'select * from performance_schema.replication_group_members;'
Output:
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
| group_replication_applier | 20fe9019-da90-11ec-80e7-00163e014012 | 172.18.86.20 | 3306 | ONLINE |
| group_replication_applier | 2b38a74a-da90-11ec-a1bb-00163e0169aa | 172.18.86.21 | 3306 | ONLINE |
| group_replication_applier | 34d1d458-da90-11ec-b0a9-00163e013f6a | 172.18.86.22 | 3306 | ONLINE |
+---------------------------+--------------------------------------+--------------+-------------+--------------+
- 正常: 当以上结果输出条数等于节点数时,表示mgr服务运行正常,允许宕机一台
- 警告: 当以上结果输出条数低于节点数并大于1个实例时,表示mgr运行正常,但不允许再宕机一台
- 异常: 当以上结果输出仅有1个实例时,表示mgr运行异常,服务不可用
数据备份
caution
部署完成后,将会在您的服务器中自动创建一个计划任务。如非必要,请不要删除它。
计划任务类似于下方(这条任务的含义是每天0点01分自动全量备份数据库)
01 00 * * * sudo docker run --rm -v /home/rpa/mysql/mysql-backup:/mysql-backup ......
默认情况下,服务器会保留您最近21天的数据。这也就说明,如果您的数据量大,那么这个备份计划是完全没有必要的,而且对您的磁盘也会造成不必要的浪费。所以您可以根据您的数据量更改这个计划。
找到备份脚本
如果您在部署期间没有更改服务部署目录的话,那么您的备份脚本会保存在
/home/laiye/mysql/conf/backup.conf,否则你需要将/home/laiye替换为您实际的部署目录更改配置项
...
local_maintain=21
minio_maintain=21
...caution
您仅需要修改
local_maintain和minio_maintain参数为实际的天数,保存退出即可
数据恢复
若多节点中其中一台MGR节点短时中断,然后服务恢复了。可在故障节点下执行sql语句将其重新加入mgr集群:
set global group_replication_allow_local_disjoint_gtids_join=on;
START GROUP_REPLICATION;
select * from performance_schema.replication_group_members;
若多节点中所有MGR节点都中断,然后服务恢复了。可将其中一台节点以写节点,另外节点以读节点方式重新组建集群:
# 写节点执行
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
# 读节点执行
set global group_replication_allow_local_disjoint_gtids_join=on;
START GROUP_REPLICATION;
select * from performance_schema.replication_group_members;
Redis
Redis介绍
Redis 是完全开源免费的,遵守BSD 协议,是一个灵活的高性能key-value 数据结构存储,可以用来作为数据库、缓存和消息队列。 Redis 比其他key-value 缓存产品有以下三个特点: Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载到内存使用。
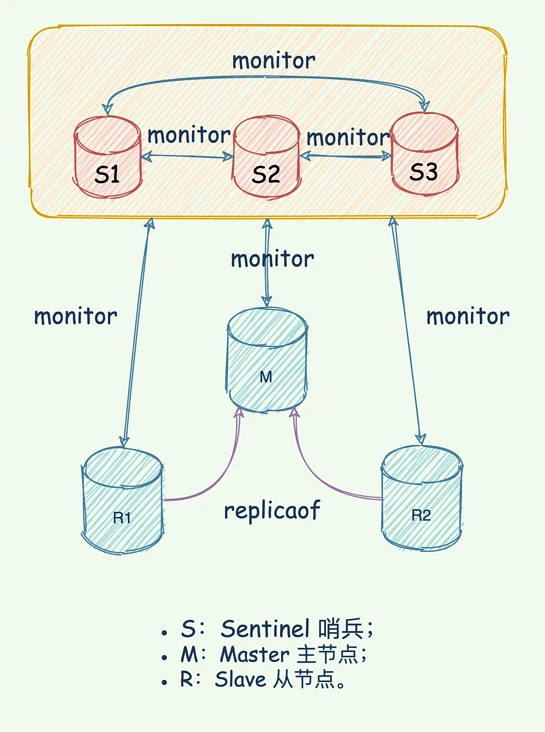
来也科技作为一家 toB 的公司,在给客户做私有部署时,如果客户不提供 Redis 高可用环境,那么部署团队将为客户搭建三节点的哨兵集群高可用架构,作为底层存储。如果主库发生故障可自动切换;如果从库发生故障,可自动将其下线。
哨兵是 Redis 的一种运行模式,它专注于对 Redis 实例(主节点、从节点)运行状态的监控,并能够在主节点发生故障时通过一系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 系统的可用性
服务可用性
可以使用命令在每台节点上检查redis状态,或者通过部署监控可视化检查
// {redis_password}: redis用户密码
// {redis_host}: redis地址
Input:
redis-cli -a {redis_password} -h {redis_host} info replication
Output:
# Replication
role:master
connected_slaves:2
slave0:ip=172.18.86.21,port=6379,state=online,offset=373561574,lag=1
slave1:ip=172.18.86.22,port=6379,state=online,offset=373561574,lag=0
master_replid:ef5dd92edc2ea1e6579b546372d7d667c77ad6c5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:373562258
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:372513683
repl_backlog_histlen:1048576
- 正常: 当connected_slaves=2时,表示redis集群运行正常,允许宕机一台
- 警告: 当connected_slaves=1时,表示redis集群运行正常,但不允许再宕机一台
- 异常: 当connected_slaves=0时,表示redis集群运行异常,服务不可用
数据备份
我们都知道,Redis的读写性能俱佳,但由于是内存数据库,如果没有提前备份,Redis数据是掉电即失的。
好在Redis提供了两种方式进行持久化:1、RDB持久化 2、AOF持久化。为了保证您的数据安全,本产品采用了两种备份模式。
RDB持久化模式为:每1,5,15分钟内有1000个key被改变自动备份。
AOF备份模式为:appendfsync everysec每秒保存一次
RDB持久化备份
info
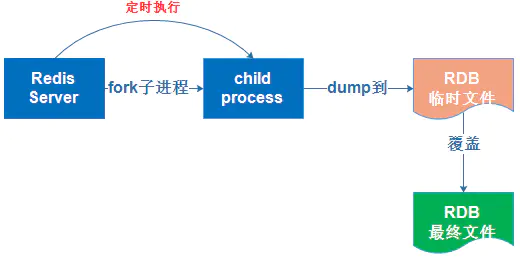
将Redis在内存中的数据定时dump到磁盘上,实际操作过程是fork一个子进程,先将数据写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储
- 自动开启RDB持久化
修改redis.conf配置文件
# 900秒(15分钟)内至少1个key值改变(则进行数据库保存--持久化)
# after 900 sec (15 min) if at least 1 key changed
# 300秒(5分钟)内至少10个key值改变(则进行数据库保存--持久化)
# after 300 sec (5 min) if at least 10 keys changed
# 60秒(1分钟)内至少10000个key值改变(则进行数据库保存--持久化)
# after 60 sec if at least 10000 keys changed
save 900 1
save 300 10
save 60 10000
dbfilename dump.rdb
dir ./bak
- 手动开启RDB持久化
# 需要登录进入redis库里操作
127.0.0.1:6379> save
OK
127.0.0.1:6379> bgsave
Background saving started
# SAVE和BGSAVE命令的区别在于:SAVE命令是阻塞主进程,save操作完成之后,主进程才开始工作,客户端可以连接;BGSAVE命令是fork一个专门save的子进程,此操作不会影响主进程
# 注:SAVE只是将当前的数据库备份,备份文件名默认为dump.rdb,可通过配置文件修改备份文件名 dbfilename xxx.rdb(发现一个问题:如果要对多个数据库进行备份,那么最终只能备份最后一个数据库,因为dump.rdb文件会相互覆盖)
AOF持久化备份
info
将Redis的操作日志以文件追加的方式写入文件,只记录写、删除操作,查询操作不会记录(类似于MySQL的Binlog日志)

Redis是一个字典结构的存储服务器,一个Redis实例提供了多个用来存储数据的容器, 客户端可以指定将数据存储在哪个容器中(类似于MySQL中的数据库)
Redis默认支持16个数据库,可以通redis.conf配置文件修改数据库个数,客户端与Redis建立连接之后默认选择0号数据库
开启
AOF功能# 此选项为aof功能的开关,默认为“no”,通过“yes”来开启aof功能
appendonly yes
# 指定aof文件名称
appendfilename appendonly.aof设置保存模式
AOF有3种方式将操作命令存入AOF文件
1. appendfsync no 不保存
只执行
WHRITE操作,SAVE操作会被略过,只有在Redis被关闭、AOF功能被关闭、系统的写缓存被刷新(如缓存已被写满)这三种情况,SAVE操作会被执行,但是这三种情况都会引起Redis主进程阻塞2. appendfsync everysec 每秒钟保存一次
这种模式中,
SAVE原则上每隔一秒钟就会执行一次,具体的执行周期和文件写入、保存时,Redis所处的状态有关,此模式下SAVE操作由后台子线程调用,不会引起服务器主进程的阻塞3. appendfsync always 每执行一个命令保存一次
在这种模式下,每执行一个命令,
WRITE和SAVE都会被执行,且SAVE操作会阻塞主进程模式 WRITE阻塞 SAVE阻塞 停机时丢失的数据量 appendfsync no 阻塞 阻塞 操作系统最后一次对 AOF 文件触发 SAVE 操作之后的数据 appendfsync everysec 阻塞 不阻塞 一般情况下不超过 2 秒钟的数据 appendfsync always 阻塞 阻塞 最多只丢失一个命令的数据
设置好AOF写入的模式之后,只要达到写入条件(比如一秒钟、执行一个命令),就会自动在指定路径下生成AOF文件,并往里面记录操作命令
数据恢复
由于我们是将宿主机目录挂载到redis容器中,所以两种恢复方式一样。将备份的RDB或AOF文件,放在指定目录,重启Redis即可恢复数据
tip
当指定目录同时有RDB文件和AOF文件时,还原数据时AOF文件的优先级是高于RDB文件的,所以优先通过AOF文件还原数据
Rabbitmq
Rabbitmq介绍
RabbitMQ这款消息队列中间件产品本身是基于Erlang编写,Erlang语言天生具备分布式特性(通过同步Erlang集群各节点的magic cookie来实现)。因此,RabbitMQ天然支持Clustering。这使得RabbitMQ本身不需要像ActiveMQ、Kafka那样通过ZooKeeper分别来实现HA方案和保存集群的元数据。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐量能力的目的
集群模式
非常经典的 mirror 镜像模式,保证 100% 数据不丢失。在实际工作中也是用得最多的,并且实现非常的简单,一般互联网大厂都会构建这种镜像集群模式。
把需要的队列做成镜像队列,存在与多个节点属于 RabbitMQ 的 HA 方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
镜像队列基本上就是一个特殊的BackingQueue,它内部包裹了一个普通的BackingQueue做本地消息持久化处理,在此基础上增加了将消息和ack复制到所有镜像的功能。所有对mirror_queue_master的操作,会通过组播GM(下面会讲到)的方式同步到各slave节点。GM负责消息的广播,mirror_queue_slave负责回调处理,而master上的回调处理是由coordinator负责完成。mirror_queue_slave中包含了普通的BackingQueue进行消息的存储,master节点中BackingQueue包含在mirror_queue_master中由AMQQueue进行调用。

服务可用性
可以使用命令在每台节点上检查rabbitmq状态,或者通过部署监控可视化检查
Input:
docker exec -it rabbitmq rabbitmqctl cluster_status|grep "Running Nodes" -A5
Output:
Running Nodes
rabbit@saas-rabbitmq-01
rabbit@saas-rabbitmq-02
rabbit@saas-rabbitmq-03
- 正常: 当Running Nodes = 3时,表示rabbitmq集群运行正常,允许宕机一台
- 警告: 当Running Nodes = 2时,表示rabbitmq集群运行正常,但不允许再宕机一台
- 异常: 当Running Nodes = 1时,表示rabbitmq集群运行异常,服务不可用
数据备份
rabbitmq仅需要备份部署目录下的{/home/laiye}/rabbitmq/docker-compose.yaml文件和{/home/laiye}/rabbitmq/config目录即可
提醒:{/home/laiye}需要替换为实际的部署目录
数据恢复
将备份的文件copy到新目录,使用docker-compose up -d启动即可
MinIO
MinIO介绍
MinIO 是在 GNU Affero 通用公共许可证 v3.0 下发布的高性能对象存储。 它是与 Amazon S3 云存储服务兼容的 API。 使用 MinIO 为机器学习、分析和应用程序数据工作负载构建高性能基础架构。
248 / 5000 翻译结果 此自述文件提供了在裸机硬件上运行 MinIO 的快速入门说明,包括基于容器的安装。
数据保护
分布式 Minio 采用纠删码来防范多个节点宕机和位衰减。 分布式 Minio 至少需要 4 个节点(4台服务器),使用分布式 Minio 就 自动引入了纠删码功能。 纠删码是一种恢复丢失和损坏数据的数学算法, Minio 采用 Reed-Solomon code 将对象拆分成 N/2 数据和 N/2 奇偶校验块。 这就意味着如果是 12 块盘,一个对象会被分成 6 个数据块、6 个奇偶校验块,你可以丢失任意 6 块盘(不管其是存放的数据块还是奇偶校验块),你仍可以从剩下的盘中的数据进行恢复。 纠删码的工作原理和 RAID 或者复制不同,像 RAID6 可以在损失两块盘的情况下不丢数据,而 Minio 纠删码可以在丢失一半的盘的情况下,仍可以保证数据安全。 而且 Minio 纠删码是作用在对象级别,可以一次恢复一个对象,而RAID 是作用在卷级别,数据恢复时间很长。 Minio 对每个对象单独编码,存储服务一经部署,通常情况下是不需要更换硬盘或者修复。Minio 纠删码的设计目标是为了性能和尽可能的使用硬件加速。 位衰减又被称为数据腐化 Data Rot、无声数据损坏 Silent Data Corruption ,是目前硬盘数据的一种严重数据丢失问题。硬盘上的数据可能会神不知鬼不觉就损坏了,也没有什么错误日志。正所谓明枪易躲,暗箭难防,这种背地里犯的错比硬盘直接故障还危险。 所以 Minio 纠删码采用了高速 HighwayHash 基于哈希的校验和来防范位衰减。
高可用
单机 Minio 服务存在单点故障,相反,如果是一个 N 节点的分布式 Minio ,只要有 N/2 节点在线,你的数据就是安全的。不过你需要至少有 N/2+1 个节点来创建新的对象。 例如,一个 8 节点的 Minio 集群,每个节点一块盘,就算 4 个节点宕机,这个集群仍然是可读的,不过你需要 5 个节点才能写数据。
限制
分布式 Minio 单租户存在最少 4 个盘最多 16 个盘的限制(受限于纠删码)。这种限制确保了 Minio 的简洁,同时仍拥有伸缩性。如果你需要搭建一个多租户环境,你可以轻松的使用编排工具(Kubernetes)来管理多个Minio实例。 注意,只要遵守分布式 Minio 的限制,你可以组合不同的节点和每个节点几块盘。比如,你可以使用 2 个节点,每个节点 4 块盘,也可以使用 4 个节点,每个节点两块盘,诸如此类。
一致性
Minio 在分布式和单机模式下,所有读写操作都严格遵守 read-after-write 一致性模型。
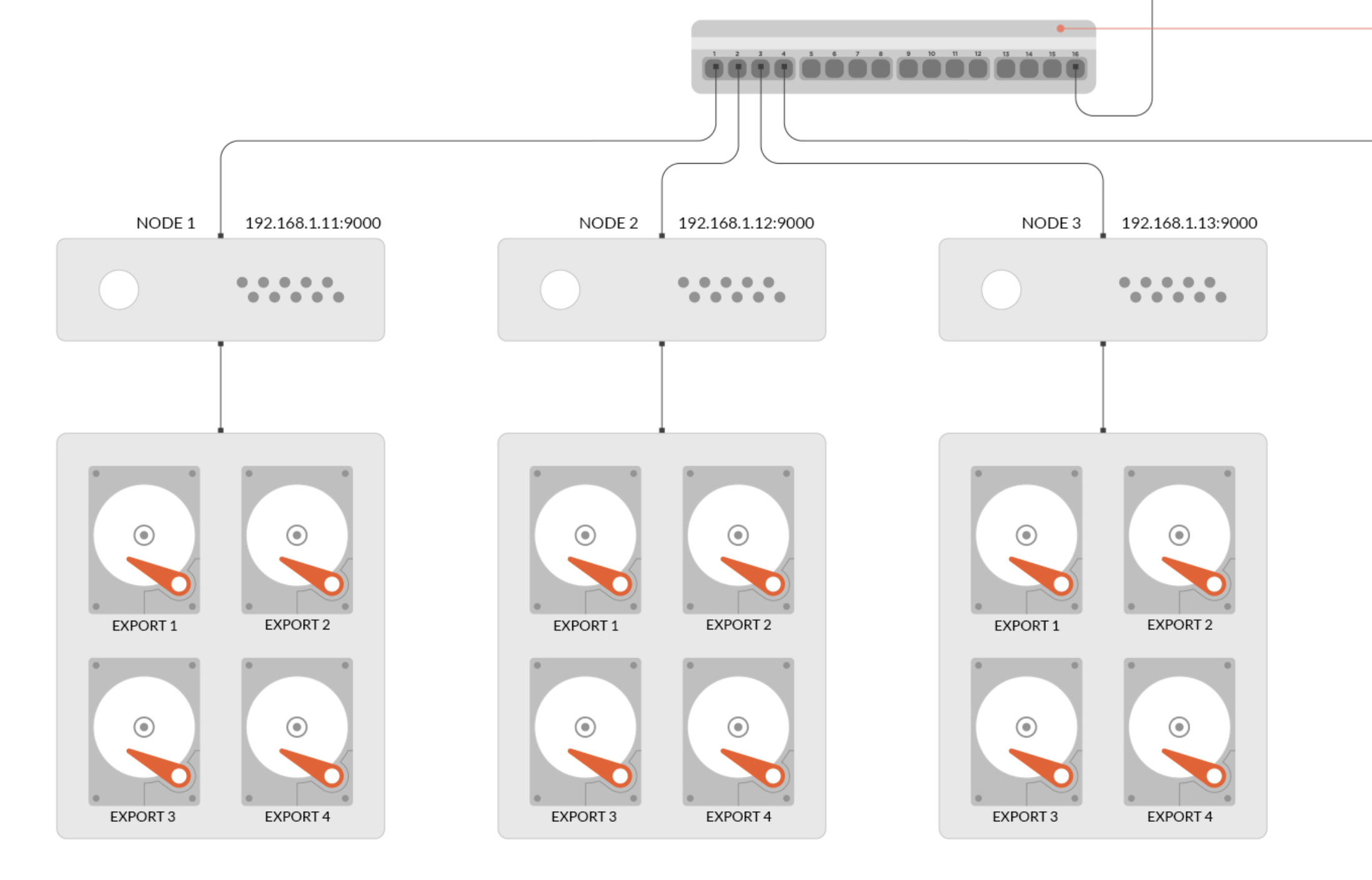
服务可用性
- 正常: 当minio实例数=节点数时,表示minio集群运行正常,允许宕机一台
- 警告: 当minio实例数小于节点数并大于1时,表示minio集群运行正常,但不允许再宕机一台
- 异常: 当minio实例数小于1时,表示minio集群运行异常,服务不可用
数据备份
minio仅需要备份{/home/laiye}/minio/docker-compose.yaml文件和{/home/laiye}/minio/data目录即可
提醒:{/home/laiye}需要替换为实际的部署目录
数据恢复
如果仅是一台节点数据宕机,那么只需要备份{/home/laiye}/minio/docker-compose.yaml文件重新创建一个minio容器,那么minio会自动同步集群中数据
如果是全部节点宕机,那么将备份文件copy到新的目录执行docker-compose up -d即可
Harbor
Harbor介绍
Harbor正是一个用于存储Docker镜像的企业级Registry服务。
Registry是Dcoker官方的一个私有仓库镜像,可以将本地的镜像打标签进行标记然后push到以Registry起的容器的私有仓库中。 企业可以根据自己的需求,使用Dokcerfile生成自己的镜像,并推到私有仓库中,这样可以大大提高拉取镜像的效率
简而言之,Harbor就是一个docker镜像仓库,后续我们所有的容器镜像都会存储在这个服务中
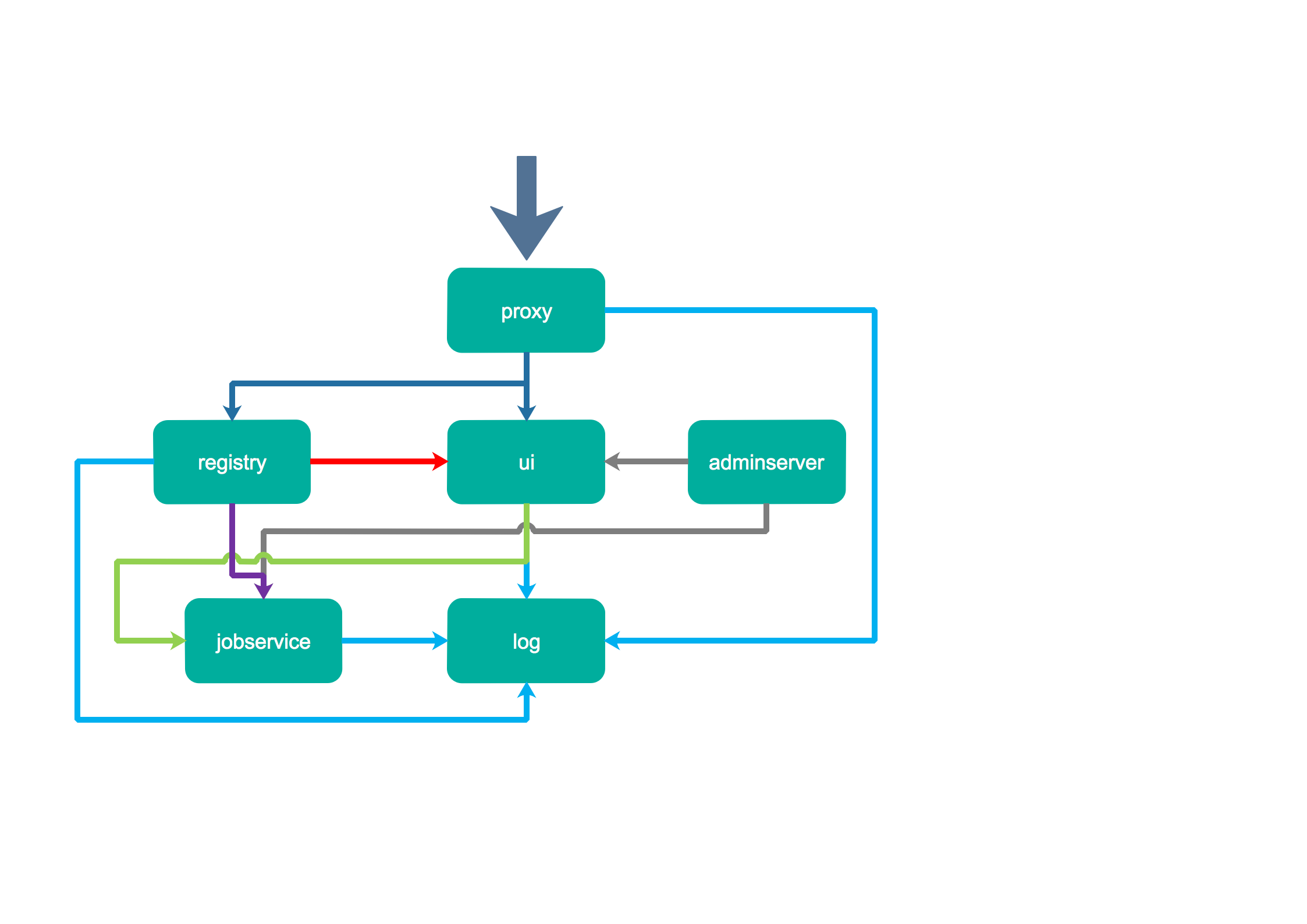
1、Proxy:
Harbor的registry, UI, token等服务,通过一个前置的反向代理统一接收浏览器、Docker客户端的请求,并将请求转发给后端不同的服务。
2、Registry:
负责储存Docker镜像,并处理docker push/pull 命令。由于我们要对用户进行访问控制,即不同用户对Docker image有不同的读写权限,Registry会指向一个token服务,强制用户的每次docker pull/push请求都要携带一个合法的token, Registry会通过公钥对token 进行解密验证。
3、Core services:
这是Harbor的核心功能,主要提供以下服务:
1)UI:提供图形化界面,帮助用户管理registry上的镜像(image), 并对用户进行授权。
2)webhook:为了及时获取registry 上image状态变化的情况, 在Registry上配置webhook,把状态变化传递给UI模块。
3)token 服务:负责根据用户权限给每个docker push/pull命令签发token. Docker 客户端向Regiøstry服务发起的请求,如果不包含token,会被重定向到这里,获得token后再重新向Registry进行请求。
4)Database:
为core services提供数据库服务,负责储存用户权限、审计日志、Docker image分组信息等数据。
5)Log collector:
为了帮助监控Harbor运行,负责收集其他组件的log,供日后进行分析。
服务可用性
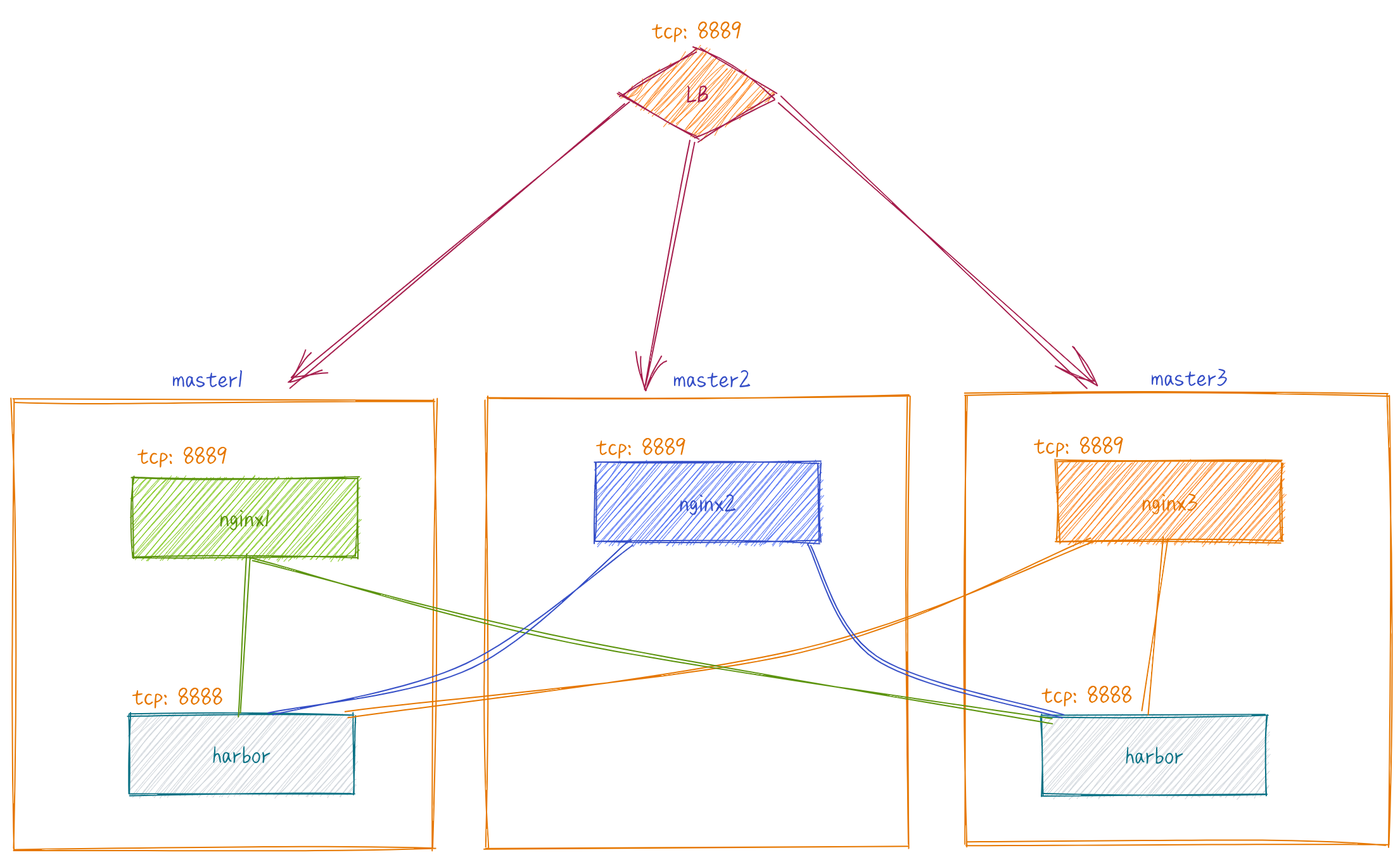
由于harbor属于低频使用,所以仅在master1和master3安装。仅允许其中一台harbor实例宕机
数据备份
harbor仅需要备份{/home/laiye}/harbor目录即可
提醒:{/home/laiye}需要替换为实际的部署目录
数据恢复
如果是全部节点宕机,那么将备份文件copy到新的目录执行docker-compose up -d即可