Information Extraction
Business scenario description
80% of data in an enterprise is unstructured, and computers are good at reading and manipulating structured data. Therefore, for RPA developers, how to extract unstructured data from enterprises and form structured data is a problem to be solved.
Laiye IDP provides developers with the AI capability of "Information Extraction" to transform "unstructured data" into "structured data" when unstructured data exists in various types of text.
For example, there are five paragraphs of public company disclosure announcements.
Notice a
Xiao Baoyu, a senior management officer who holds 300,000 shares of the Company (0.0284% of the total share capital of the Company), has confirmed with the Supervisor that he intends to reduce his holdings of not more than 75,000 shares of the Company (0.0071% of the total share capital of the Company) by means of collective bidding within six months after the trading date of this announcement.
Notice b
Zhao Yi, the supervisor who holds 158,858 shares of the Company (accounting for 0.0150% of the company's total share capital), intends to reduce his holdings of the Company's shares not exceeding 39,715 shares (accounting for 0.0038% of the Company's total share capital) by means of collective bidding or block transaction within six months after the date of the fifteen trading days from this announcement.
Notice c
Ao Zhiqiang, a senior management officer who holds 1,208,035 shares of the Company (accounting for 0.1144% of the total share capital of the Company), intends to reduce his holdings of not more than 250,000 shares of the Company (accounting for 0.0237% of the total share capital of the Company) by means of collective bidding or block transaction within six months after the date of fifteen trading days from this Announcement.
Notice d
Weiping Huo, the controlling shareholder and one of the actual controlling people holding 130,162,360 shares of the Company (accounting for 12.3220% of the total share capital of the Company) intends to reduce his holdings of not more than 2,000,000 shares of the Company (accounting for 0.1893% of the total share capital of the Company) by means of collective bidding or block transaction within six months after the date of fifteen trading days from this Announcement.
Notice e
Chunxia Xiao, a senior management officer who holds 100,000 shares of the Company (0.0095% of the total share capital of the Company), has confirmed with the Supervisor that he intends to reduce his holdings of not more than 25,000 shares of the Company (0.0024% of the total share capital of the Company) by means of collective bidding within six months after the trading date of this announcement.
The developer hopes to extract the four data in bold from the above four similar formats and form the following table (this table is structured data).
| names | way | improve/reduce | shares |
|---|---|---|---|
| Xiao Baoyu | collective bidding | reduce | 75,000 |
| Zhao Yi | collective bidding or block transaction | reduce | 39,715 |
| Ao Zhiqiang | collective bidding or block transaction | reduce | 250,000 |
| Weiping Huo | collective bidding or block transaction | reduce | 2,000,000 |
| Chunxia Xiao | collective bidding | reduce | 25,000 |
Lai'ye provides "Information Extraction" services that can help you solve problems like those described in the example above.
Concept introduction
Field
Fields are variables that need to be output in Information Extraction tasks.
For a piece of text to be extracted, a field is the name of the information to be extracted.
For example, to extract "Beijing" and "Shanghai" from "I want to buy an air ticket from Beijing to Shanghai", I should create two fields "place of departure" and "destination".
Resources
To perform Information Extraction tasks more accurately, developers generally need to provide some information relevant to their business scenarios that can be used for text matching, or external knowledge from the developer, which is referred to as resources in Laiye IDP.
For example, if an RPA developer from a beauty e-commerce company wants to extract key information about the "price" of the lipstick number from the product description, the developer should provide the Laiye IDP with a word representing the lipstick number. These words are the external knowledge that developers provide to Laiye IDP. Laiye IDP uses this external knowledge to better locate the text fragments that need to be processed and extract key information from them.
Developers can provide this external knowledge in three ways: Custom Vocabulary, Preset Vocabulary, and Regular Expression. The following three methods are introduced respectively.
Custom Vocabulary
Custom Vocabulary is an information structure consisting of < Vocabulary name, Vocabulary value, and Various synonyms of Vocabulary value >. A glossary describes a relatively fixed class of external knowledge in the lexical form that is strongly related to the developer's domain.
Lipstick, for example, is external knowledge that is specific to the field of beauty and remains constant over time. And this knowledge exists in the form of words. Laiye IDP, in turn, uses a custom vocabulary to capture this external knowledge.
Specifically, a possible thesaurus is as follows:
| Vocabulary name | Vocabulary values | Various synonyms of Vocabulary value |
|---|---|---|
| color code of lipstick | ||
| Flame Blue Gold 999 | Legend Red lips matte, Legend Red, Legend Woman, 3 nines | |
| Flame Blue Gold 666 | matte Kiss, Matte Kiss, retro blues red, retro red | |
| Flame Blue Gold 740 | Coke, maple red, maple, tomato, tomato red |
Preset Vocabulary
The Preset Vocabulary is used in the same way as a Custom Vocabulary, except that the Preset Vocabulary is a pre-configured entity provided by the platform for handling the most common entities.
You can view all the Preset Vocabulary lists on the Resources page, and there's also a test function on the page, where you can enter test text to test the effect of the preset word lists.
Note: This is only a test Preset Vocabulary extraction, and when it happens in a real scenario, the entity extraction rules depend on multiple factors.
Regular Expression
Regular Expression is a logical formula for manipulating strings. You can learn in advance how to use generic Regular Expression.
To make better use of Regular Expression, there are more detailed rules need to specify. These rules include:
- Case sensitive/insensitive: Indicates whether the match is case sensitive.
- Single-line mode: matches any character symbol. Whether a newline character is matched. If a newline character is not matched, it means a symbol. The range of matched characters includes the newline character, that is, [\r\n].
- Multi-line mode: ^ and $match the start and end positions, respectively. In multi-line mode, the range of matches is extended by adding the beginning of the line (the position at the beginning of the string or after the previous line \n) and the end of the line (the position before \n), respectively.
- Global matching: A regular expression can match multiple fragments of text. The main match is output.
- Matching order: From left to right by default. The order of matches can also go from right to left, but generally, this applies mainly to Arabic.
Laiye IDP's "Information Extraction" provides the following rules for the above rules:
- Case insensitive by default.
- Default single-line mode, that is,
<*>can match any character, including [\r\n]. - Default non-multi-line mode. If
<*>is the last matching rule, it matches the end of the string. When a multi-line mode is required, it is recommended to add special characters such as ## at the end of the line and add matching rules for ## in the template. - Default global mode: If multiple matches are performed, the output is displayed for multiple matches and the start position is matched.
- Default left-to-right matching mode.
Template
To extract the key information in the example above, the Information Extraction feature requires the developer to provide a text expression called a template. Use this expression to match several fragments of text and extract information. For the example at the beginning of this article, a written template is shown below:
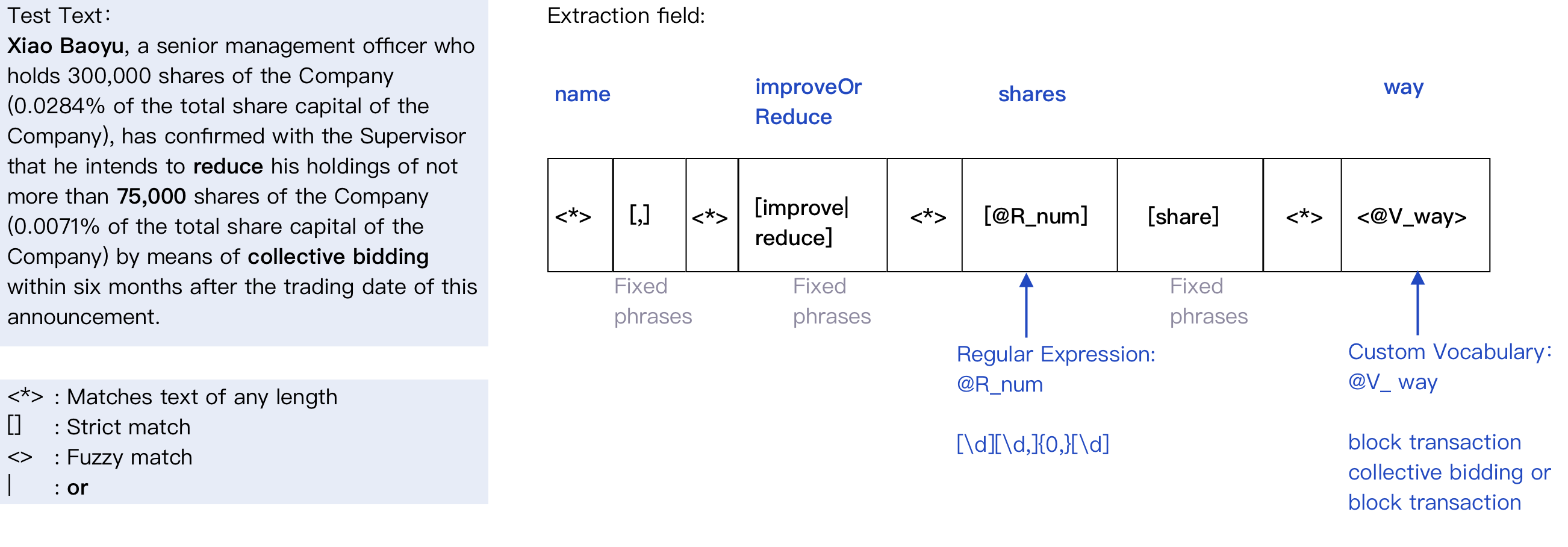
Developers must provide such a template to complete Information Extraction. To write a correct template, you need to know the following necessary syntax:
- Brackets
[]indicates a strict match.- Matches can be "Custom Vocabulary", "Regular Expression", or phrases that need to be matched.
- If the matched content is a "Resource", the result will be normalized (for example, "Flame Blue Gold 666" will be returned regardless of the "multiple terms" of "retro blues red", "retro red", etc.).
- multiple need to match the content can use | (half Angle of vertical lines) segmentation.
- Angle brackets
<\>represent fuzzy matching.- Fuzzy matching is the opposite of strict matching. The text to be matched must be the same as the specified matching content. Fuzzy matching is as long as the semantics of the two are close. For example, a strict match would not consider "press conference" and "press conference" to match; But fuzzy matching does.
- The things that can be specified in Angle brackets include the Custom Vocabulary in Resource and the "phrase" entered by the developer.
- Angle brackets cannot specify Regular Expression in Resources.
- multiple need to match the content can use | (half Angle of vertical lines) segmentation.
- Reference resources in Angle brackets are not normalized.
- the
<*\>symbol matches text fragments of any length. - in the template need to match
{,\},\ [,\], <,\ >, \|, \{,\}, \*, use "\" escape.
Version
Version is the collection of templates that can be used to measure the overall effect of different sets of templates.
Note: a maximum of five versions can be created under an Information Extraction model.
Basic operation
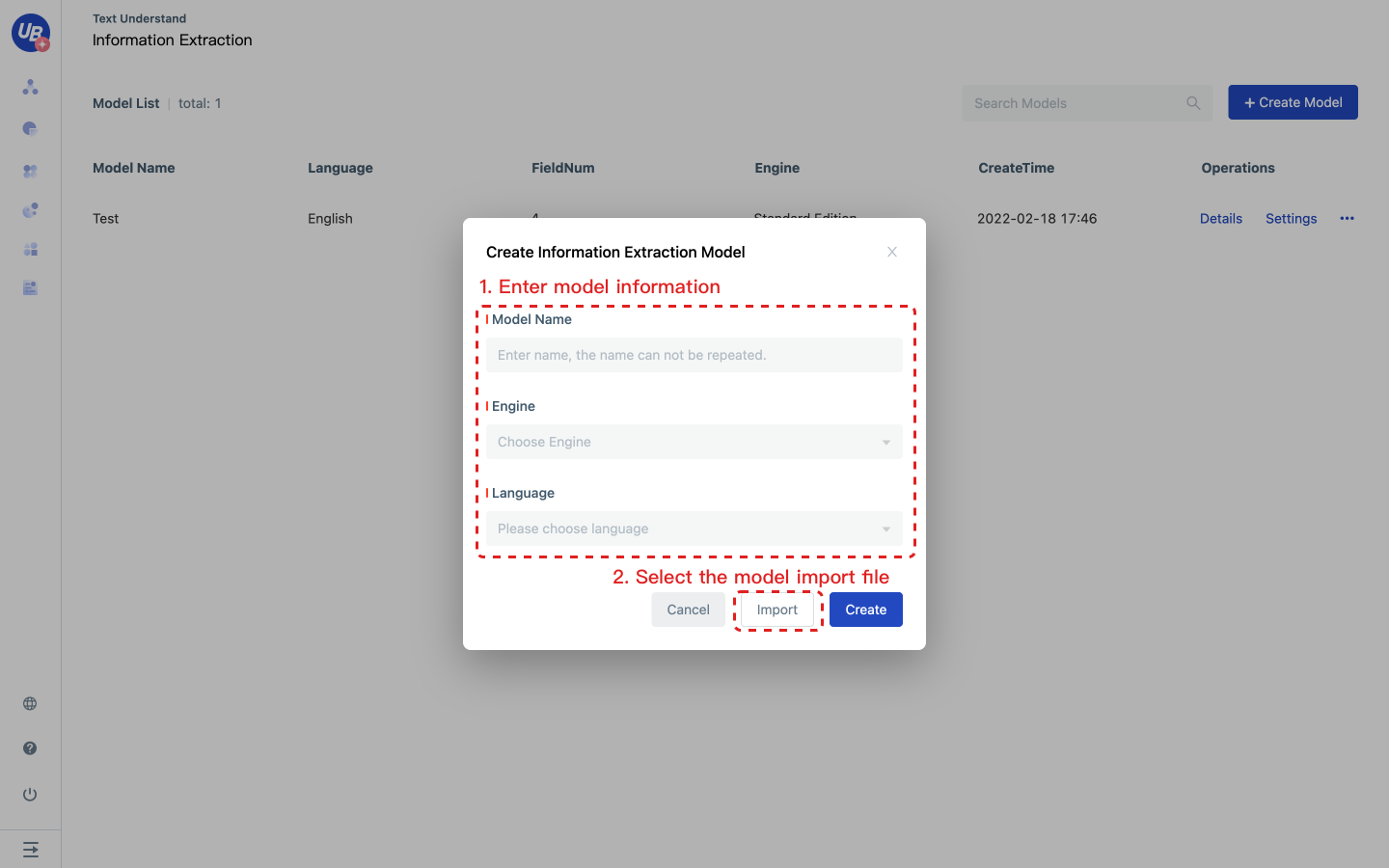
Create an Information Extraction model
1 Log in to the platform and enter the list of Information Extraction models from the following paths: Customize AI capabilities/Text Understand/Information Extraction
2 click Create Model, enter the model name in the pop-up window, select the engine version, and click Ok to generate a new model.
Note: When using the Information Extraction service in UiBot Creator, you need to configure the pubkey and secret of the Information Extraction model. The model's Pubkey and Secret are on the model's Settings page.
Create fields
1 Open the created Information Extraction model and click the Field on the navigation bar.
2 Click Create Field, open the Create popover, enter the field name, and click Save to complete the creation.
- The field name contains a maximum of 20 characters.
- The field names in a model cannot be the same.
3 Click dots next to Create Field to add fields in batches.
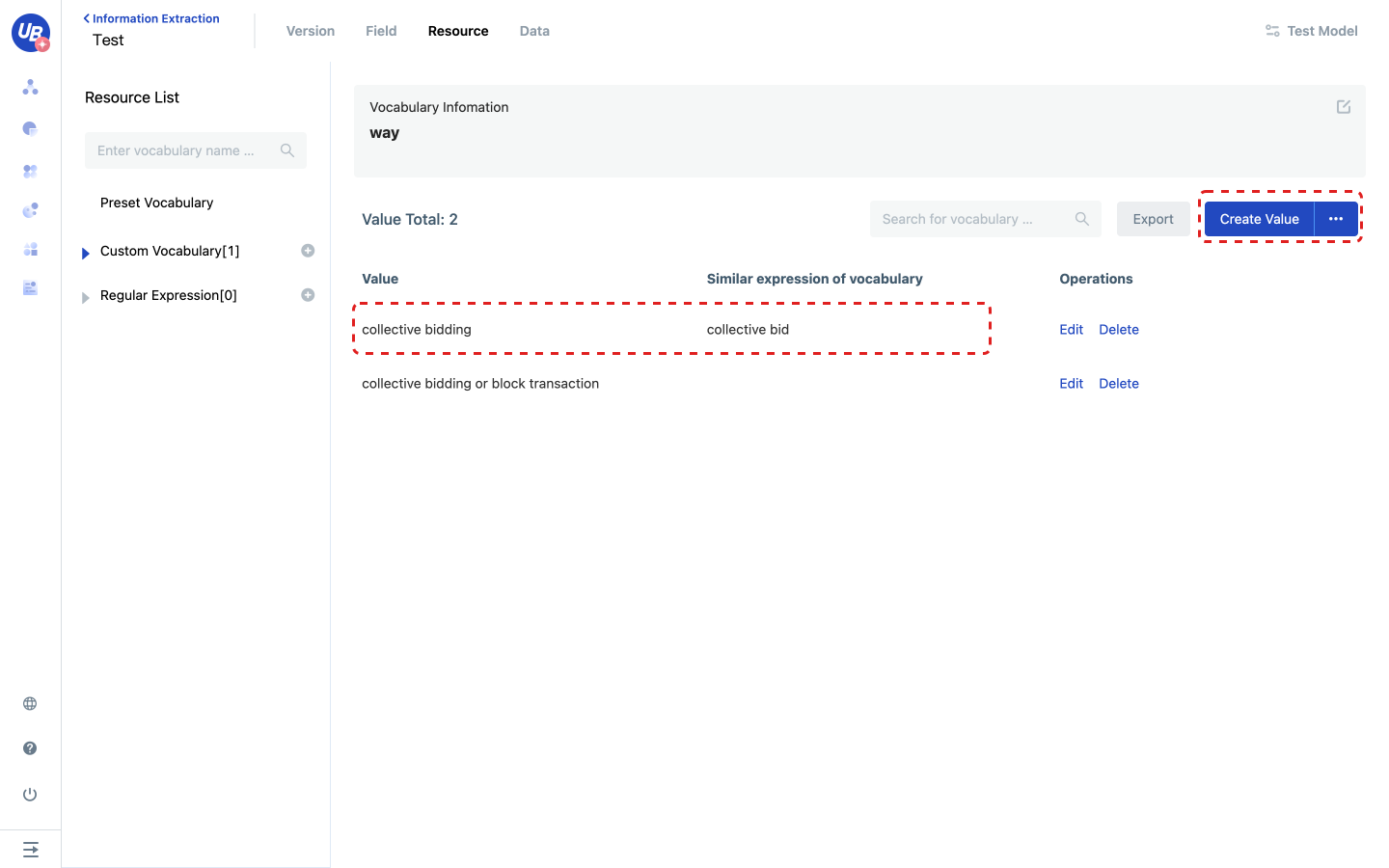
Configure resources - Create Custom Vocabulary
1 Open the created information extraction model and click Resource on the navigation bar.
2 Click the plus sign next to the Resource List/Custom Vocabulary to create a custom vocabulary.

3 Click Add Value, open the popup window, enter value and its various expressions.
Configure resources - Create Regular Expression
1 Open the created Information Extraction model and click Resource on the navigation bar .
2 Click the plus sign next to Resource List/Regular Expression to create a new regular expression.
3 Enter the regular expression content and replace rule in the regular expression input box.
What is replace rule? How to use it?
In the Regular Expression rule, ()represents the capture group. ()stores the matched values in each group and outputs the values in the order in which the opening parentheses appear.
such as Regular Expression (\d(\d(\d))), to replace the rules of "text$1-$2-$3xx", using test text "123" to test, what is the output? Try it on Laiye IDP
here https://www.runoob.com/regexp/regexp-syntax.html to learn more about the regular expression syntax.
4 Test whether their effect meets expectations.
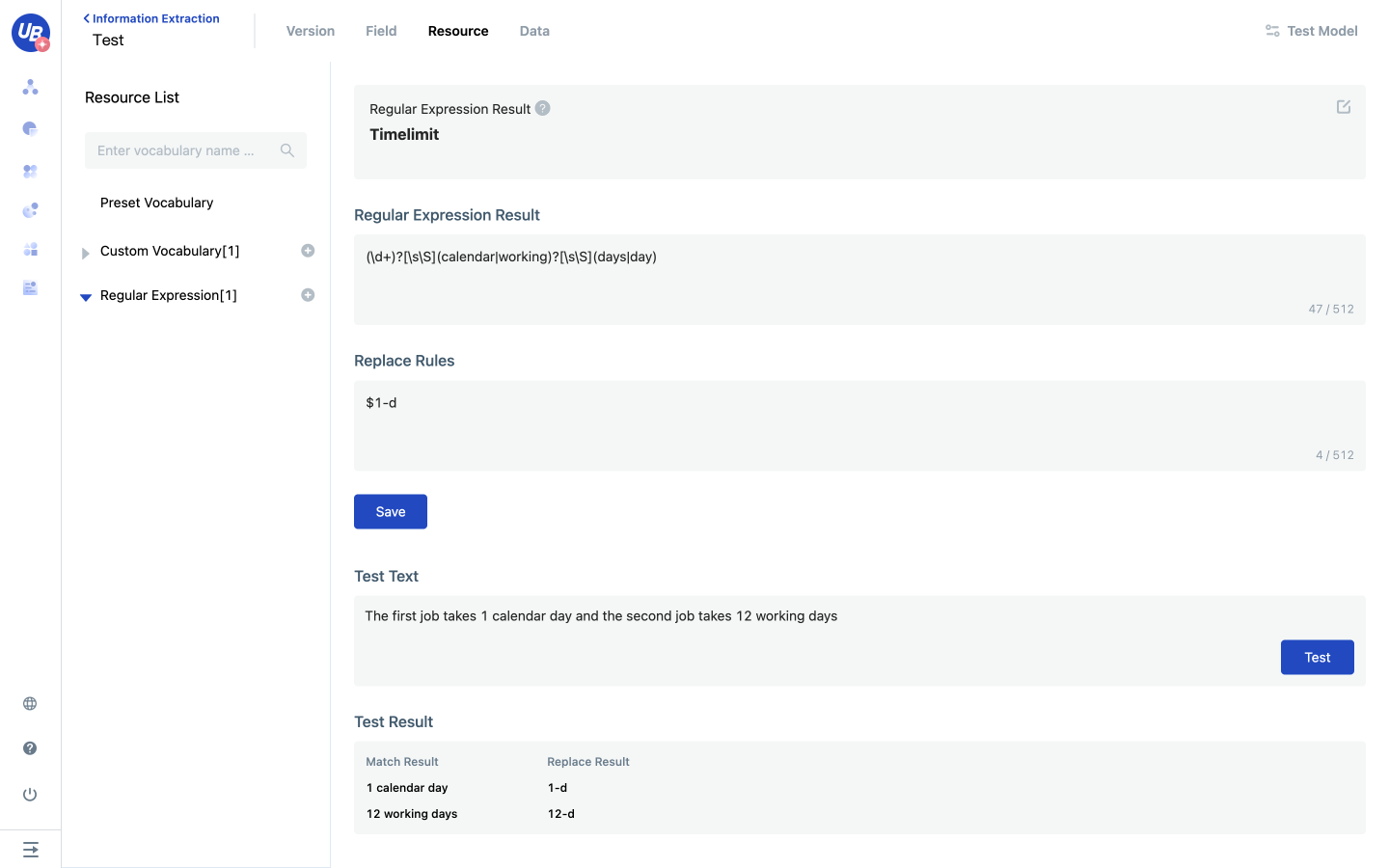
Try it yourself!
Regular Expression Content:(\d+)?\s\S?\s\S
Replace rule: $1-d
Text for Test: The first job takes 1 calendar day and the second job takes 12 working days
Create versions
1 Open the created Information Extraction model and click Version on the navigation bar.
2 Click Create Version button, enter version name in the pop-up window, and click OK to create a new version.

3 Version list Operation description
- Train: The system recommends the entry for template generation. For details, see advanced Operation/Train.
- Evaluate: you can evaluate the extraction effect of all templates under the current version, see Advanced Operations/evaluation.
- Publish: Publish all templates of the current version to an official environment. For details, see Basic Operations/Release version.
- Details: Entry for managing all templates in the current version.
- More/Download Evaluation results: Provides a download of the last evaluation results.
- More/Copy: Provides a one-click copy of the current version.
- More/Delete: Deletes the current version.

4 Currently, the platform supports Manual and Human-machine collaboration to configure templates.
- Manual: Click Details of the current version to go to the template list page. Click Create Template to manually configure the template. For details, see Basic Operations/Template Configuration - Manual.
- Human-machine collaboration: see Advanced Operation/Train for specific operation.
Configure template - Manual
1 Open the created Information Extraction model and click Version on the navigation bar.
2 Click Details of the version to go to the template list.
3 Click the Create Template button to enter the template editing page.
4 Enter template name, template description, and basic information about the template.
5 Edit the template and create each node based on the five matching rules.
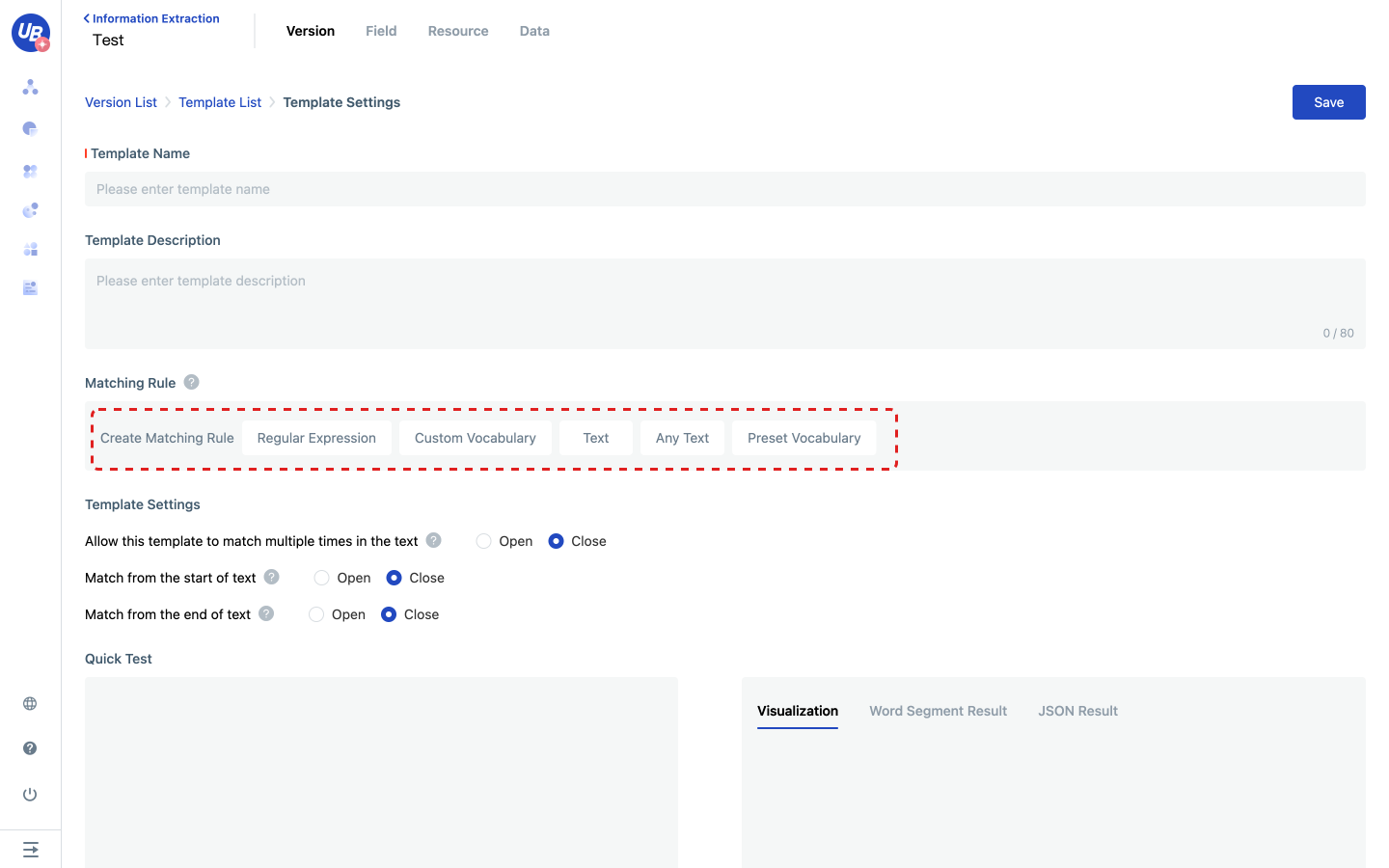
- Regular Expression: matches a text that can be described by a regular expression. Matches that reference the regular expression in template syntax.
- Select the created regular expression to match.
- Select whether to output to a field.
- Custom Vocabulary: Represents matches a piece of text described by a Custom Vocabulary, corresponding to matches in template syntax that need to reference a Custom Vocabulary.
- Select the created Custom Vocabulary that you want to match.
- Select whether to output to a field.
- Check fuzzy matching and adopt near-sense matching based on semantic similarity; If not checked, strict matching will be used.
- Text: matches a piece of text that does not need to reference resources in template syntax.
- Enter the text to be matched.
- Select whether to output to a field.
- Check fuzzy matching and adopt near-sense matching based on semantic similarity; If not checked, strict matching will be used.
- Any text: matches a text of any length and content, corresponding to
<*>in template syntax.- Enter the length of the text to match. It can be empty.
- Select whether to output to a field.
- Preset Vocabulary: represents a strict match or fuzzy match of a piece of text described by the word list.
- Select the Preset Vocabulary to match.
- Select whether to output to a field.
6 After editing the template, click Save template.
Publish
After editing all templates, go back to the Version List page and publish the corresponding version.
- All templates in the published version will take effect in the official environment.
- Only one version can be released to the official environment at a time.
Test
1 Open the created information extraction model and click Test Information Extraction in the upper right corner.
2 Input or upload the test text and test the extraction effect of the current Information Extraction model.
Note: If there is no published version under the Information Extraction model, it means that the current Information Extraction model has no effective template, and the extraction effect cannot be tested.
Advanced operation
Configure Information Extraction model
1 Click the Settings of Information Extraction model to open the popup window of model configuration.
2 Configure a conflict detection policy
- We believe there are two kinds of conflicts:
- the fragments matched by two templates are crossed, and the corresponding conflict detection policy Text is not allowed to match templates twice;
- the fields to be output by two templates are in the same position, and the corresponding conflict detection policy Text is not allowed to extract fields repeatedly.
When two templates are detected to conflict, the conflict resolution policy is
- If two templates match fragments of different lengths, the fragment length template is reserved.
- If two templates match fragments of the same length, select the template with the earlier matching information.
- If two templates match the same fragment, select the one with more output fields; If the output field is the same, select the template containing more matching rule nodes. If there are the same number of template nodes, do not conflict.
3 Default line feed end match
If the text contains the newline character \n, the model will slice the text through \n before extracting, and then match it. That is, if you need to extract something that has a line break, do not check the default end of the line break match.
Upload data
Data is the text to be extracted, and annotated data is the data marked with expected extraction results. Currently, the platform only supports offline annotation, and the annotation format is as follows: 【【【field name === content to be extracted】】】, neither field name nor content to be extracted can be empty.
For example, a bulletin in a service scenario is in the following format:
Notice a
【【【【name===Xiao Baoyu】】】, a senior management officer who holds 300,000 shares of the Company (0.0284% of the total share capital of the Company), has confirmed with the Supervisor that he intends to 【【【【improveOrReduce ===reduce】】】 his holdings of not more than 【【【【shares===75,000】】】 shares of the Company (0.0071% of the total share capital of the Company) by means of 【【【【way===collective bidding】】】 within six months after the trading date of this announcement.
1 Open the created Information Extraction model and click Data/All data .
2 Click Upload Data, select the file to be uploaded and click OK to open the upload confirmation pop-up window.
3 Click upload.
Requirements for uploading files:
- Currently, the platform supports uploading only UTF-8 TXT files of up to 30,000 characters.
- One Information Extraction model supports up to 200 data uploads.
Failure msg when uploading files and possible causes:
- [Upload failed, content exceeds limit] The content of the file cannot exceed 30,000 words.
- [Upload failed, encoding error] The encoding of the document is not UTF-8.
- [Failed to upload, failed to replace] Unmarked files cannot be replaced with marked files. If you need to replace the marked file, delete it first and upload it again.
- [Upload failed, quantity exceeds limit] A maximum of 200 pieces of data can be uploaded under an Information Extraction model.
- [Upload failed, network error] The upload failed due to network problems.
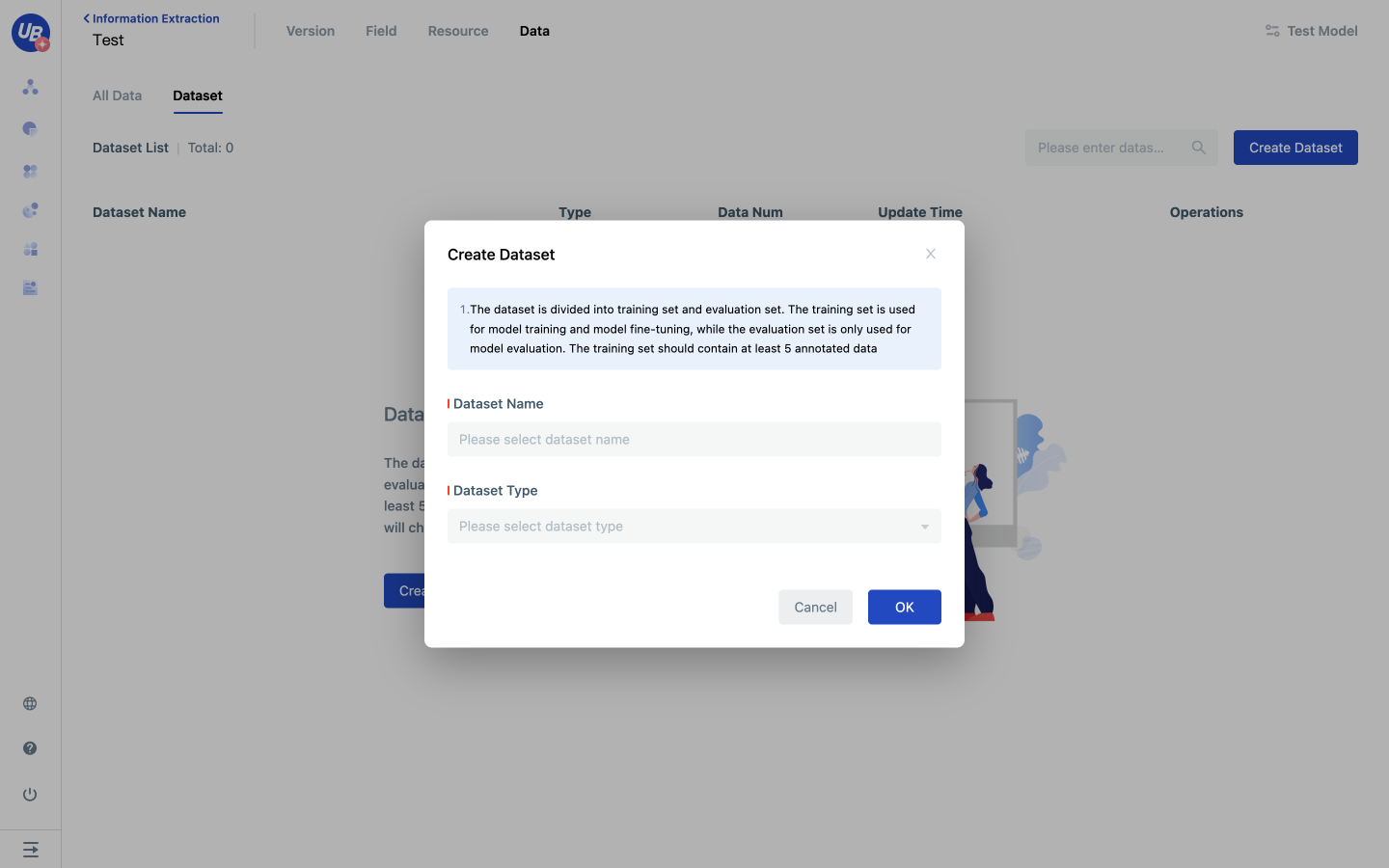
Configure dataset
The dataset is divided into the training dataset and evaluation dataset, which is the input of version training and evaluation. The training dataset is used for model training and fine-tuning, while the evaluation dataset is only used for version evaluation.
1 Open the created Information Extraction model and click Data/Dataset .
2 Click Create Dataset, enter the name of the dataset, select the dataset type, and click OK to create the dataset.
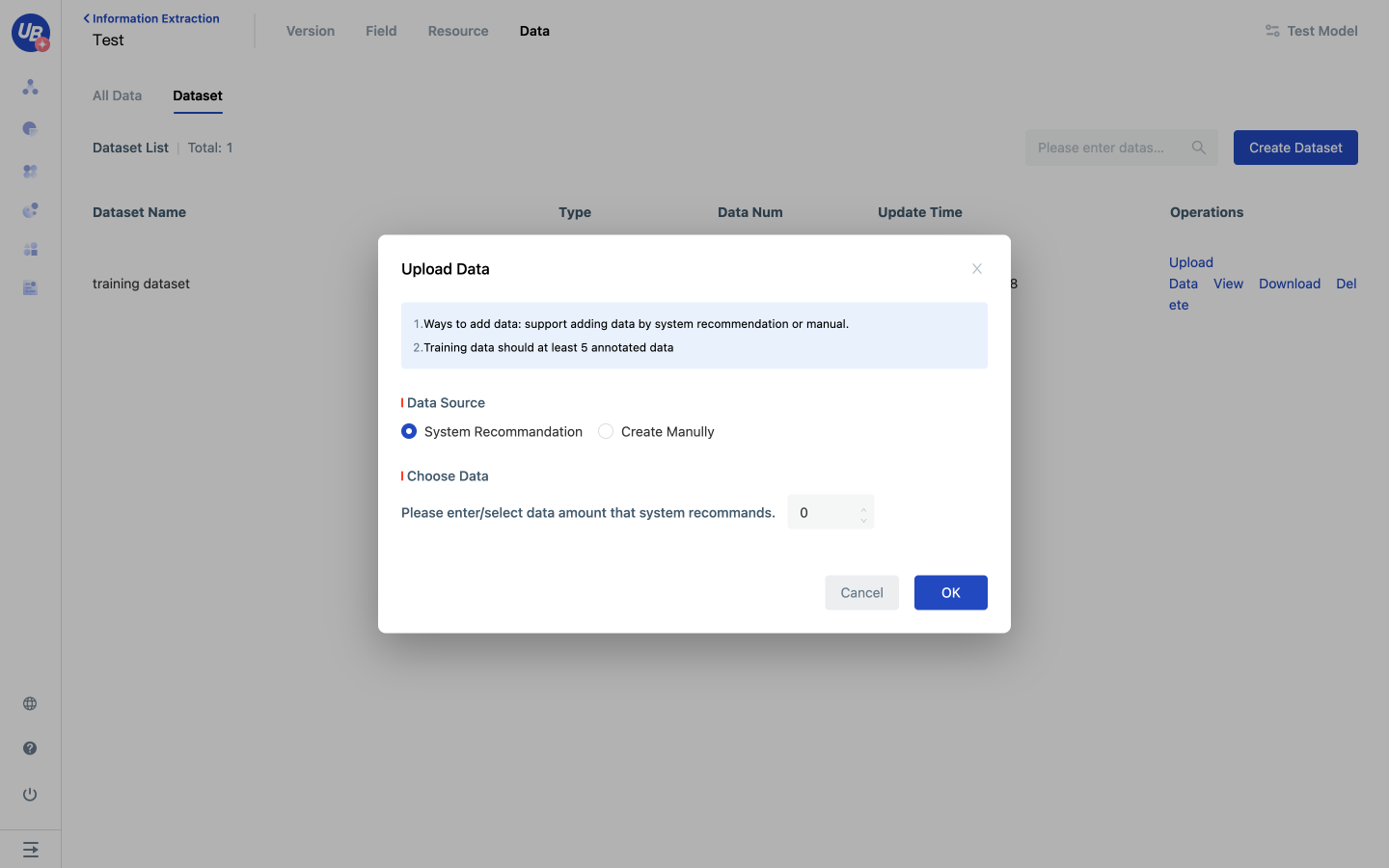
3 Find the newly created dataset in the dataset list and click Upload Data to open the Add Data popup window.
Data can be added either manually or recommended by the system. Datasets of a specified size can be randomly generated by the system. Data can be added manually by users.
Note: Unlabeled data will not appear in the Add Data popup.
Train
When the template is generated by the system recommendation in machine-assisted manual mode, the system will use the training set associated with the current version to train the model and generate the recommendation template. Training will result in a set of templates of type "overwritable" that will collectively cover all of the "overwritable" type templates in the current version "before training."

1 Open the created Information Extraction model and click Version on the navigation bar.
2 click the corresponding version of Train, open the training popup, select the training set and the field that needs to be recommended by the machine, and click OK to start training. At this point, the version enters the training state.
3 After the training, the version will return to the unreleased state. Click the version of Details, enter the template list, you can view the template generated by this training.
Evaluate
Evaluation enables the evaluation of the overall extraction effect of all templates under the version. The system will use all templates in the version to extract the data of the evaluation set and check it with the annotated data to generate evaluation results.
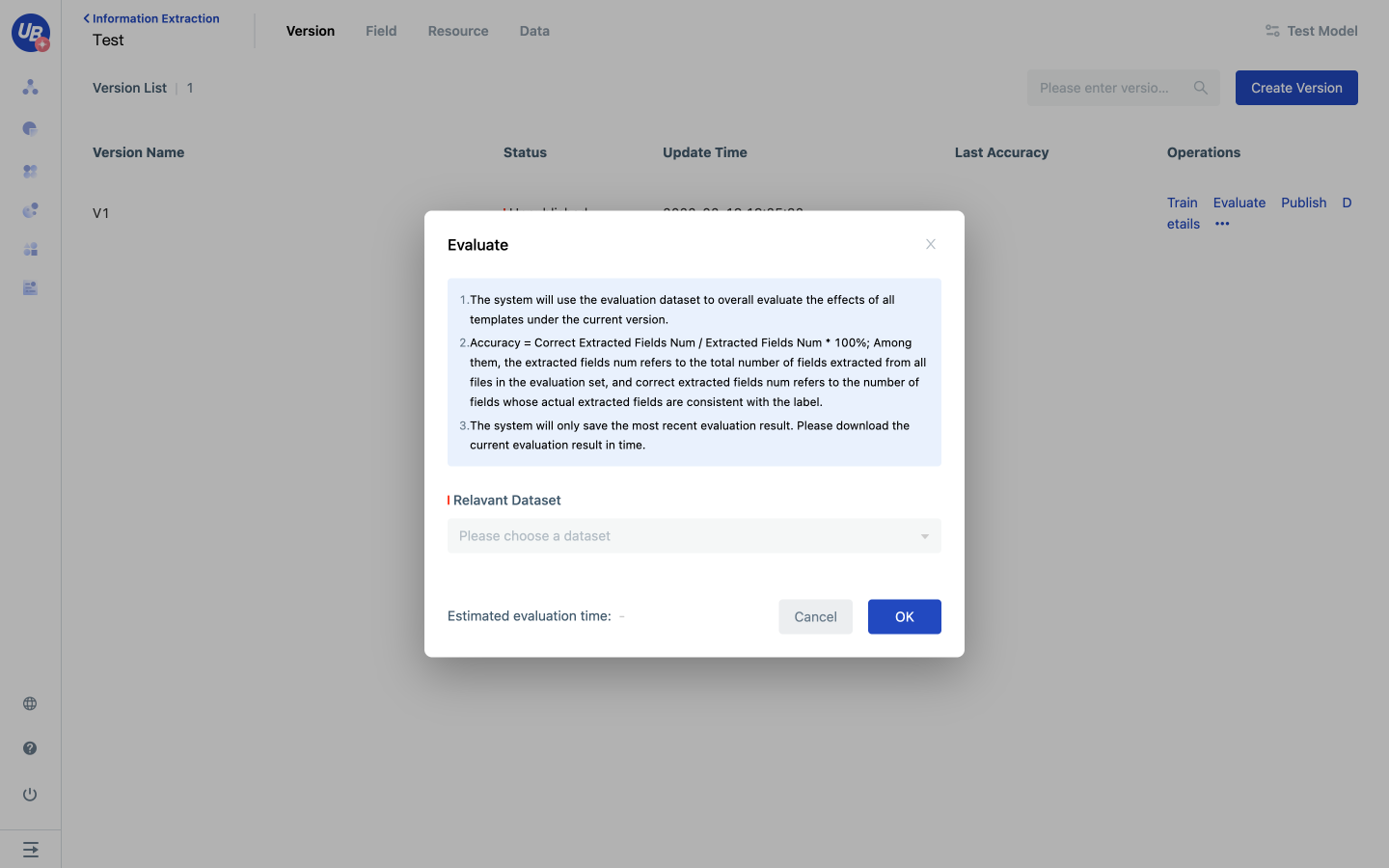
1 Open the created Information Extraction model and click Version on the navigation bar.
2 Click the corresponding version of Evaluate, open the evaluation popup, associate the evaluation dataset, and click OK to start the evaluation. At this point, the version enters the evaluation state.
3 after the evaluation is completed, the version will be updated with the accuracy of the last evaluation and the evaluation results, and the version will return to the unreleased status. Click Download evaluation results in version operation to download the results of this evaluation.
Model export
Click the export button of the model, open the export configuration page, configure the export Settings according to requirements, and click OK to complete the export.
- Full Export: Exports all resources in the current model, including fields, resources, data, and versions.
- Do not export data or data sets: Export all resources in the current model except data and data sets, including fields, resources, and versions.
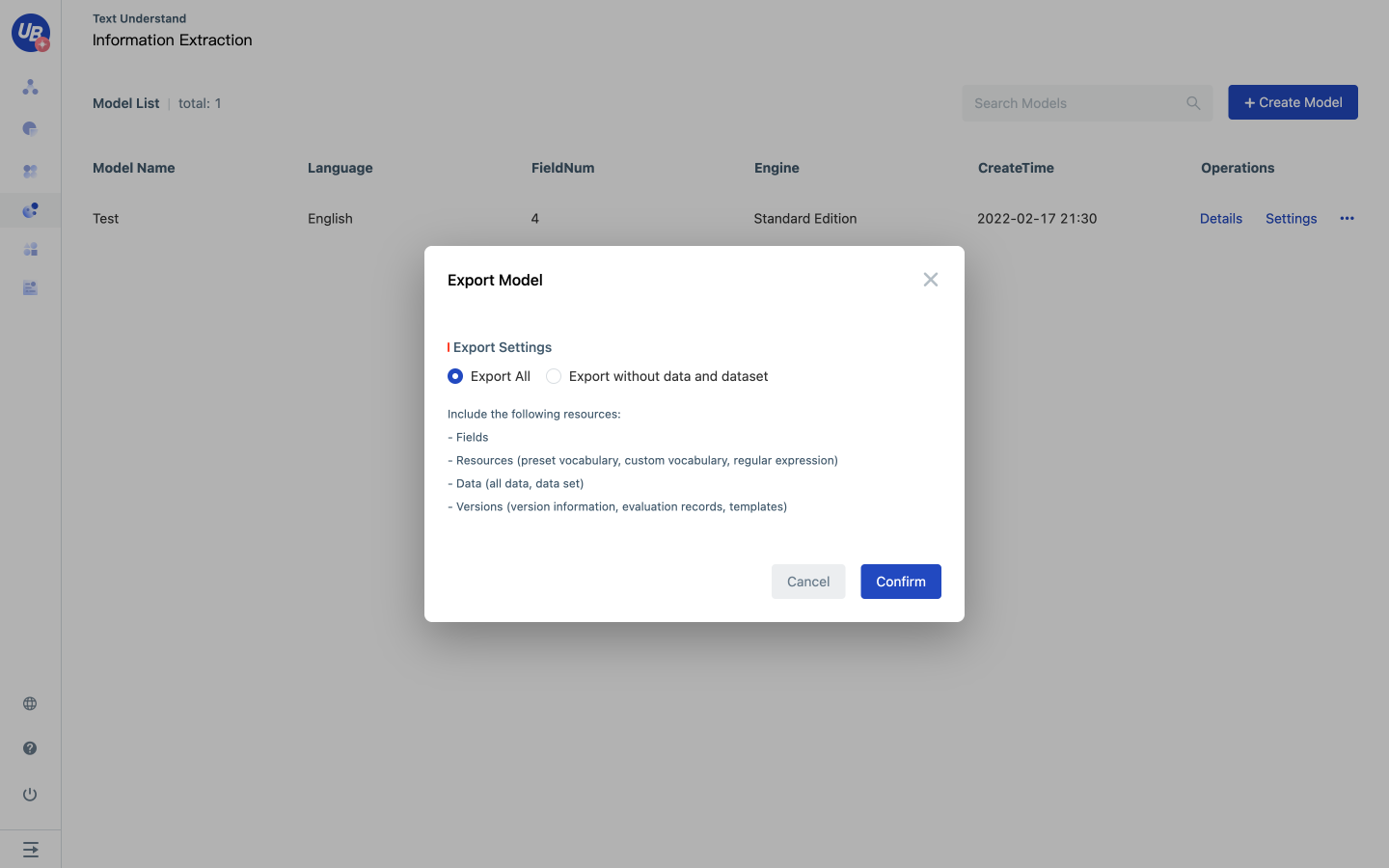
Model import
Click Create Information Extraction model, enter the model name in the pop-up window, select the engine version, and click Import to select the corresponding model data package to complete the import.
- Model packet: a file exported from the Laiye IDP platform ending in. Extractor
- Full import is required only in an Internet environment