Document Extraction
Business scenario description
Document extraction is an out-of-the-box intelligent document understanding capability provided by Laiye IDP, which can assist users to complete the intelligent extraction of key document information and realize the transformation of unstructured long text into structured data.
We know that RPA robots can simulate mechanical and repetitive tasks in human processes according to pre-designed rules, and assist in completing a large number of "fixed rules, high repeatability, and low added value" tasks. For some processes that involve document processing, there is still a lot of human involvement. Take the following two business scenarios as examples:
In the red-headed file archiving scenario of the government or state-owned enterprise, the archivists need to scan the files into electronic versions and enter the information about red-headed files (such as file title, issuing number, and issuing authority) into the archival system according to the archiving requirements.
in some equipment sales enterprise bidding monitoring scenario, the business development specialist need to browse a variety of different bidding website every day, get the latest tender announcement, preliminary screening was carried out on the bidding information, will tender announcement information recorded in the CRM system, if the enterprise qualifications meet the requirements of the tender announcement by the sales staff to further contact with the customer, bidding for subsequent operations.
In the corporate recruitment scenario, the HR/ HR specialist needs to input the employee information into the talent pool after receiving the resume.
In the above three business scenarios, THE RPA can handle the mechanical, repetitive tasks of the process, but it cannot intelligently extract key information from the document. Take the tender announcement as an example. RPA robot can capture the tender announcement from different websites, but without the assistance of AI, business personnel still need to read all the tender announcement captured and manually extract the information of the announcement into the CRM system.
The addition of document extraction AI capability to the process can help business personnel quickly process business documents, improve work efficiency, and free business personnel from repetitive mechanical reading and typing work, and put them into more high-leverage work.
Characteristics
Document extraction has the following characteristics:
- Intelligent extraction : The result of document extraction is not entirely from the original document, and the model has different treatments for different fields. For example, the model structured the address of the extraction result of the attribution place, and the business type in the bidding announcement came from the classification model.
- Easy to use : extract results through different colors of the annotation, if the extraction results from the original text, support to click the extraction results quickly positioning.
- Multiple formats : supports jpeg, jpg, png, bmp, tiff, pdf, docx/doc formats.
Instructions
Text version
Create a new model
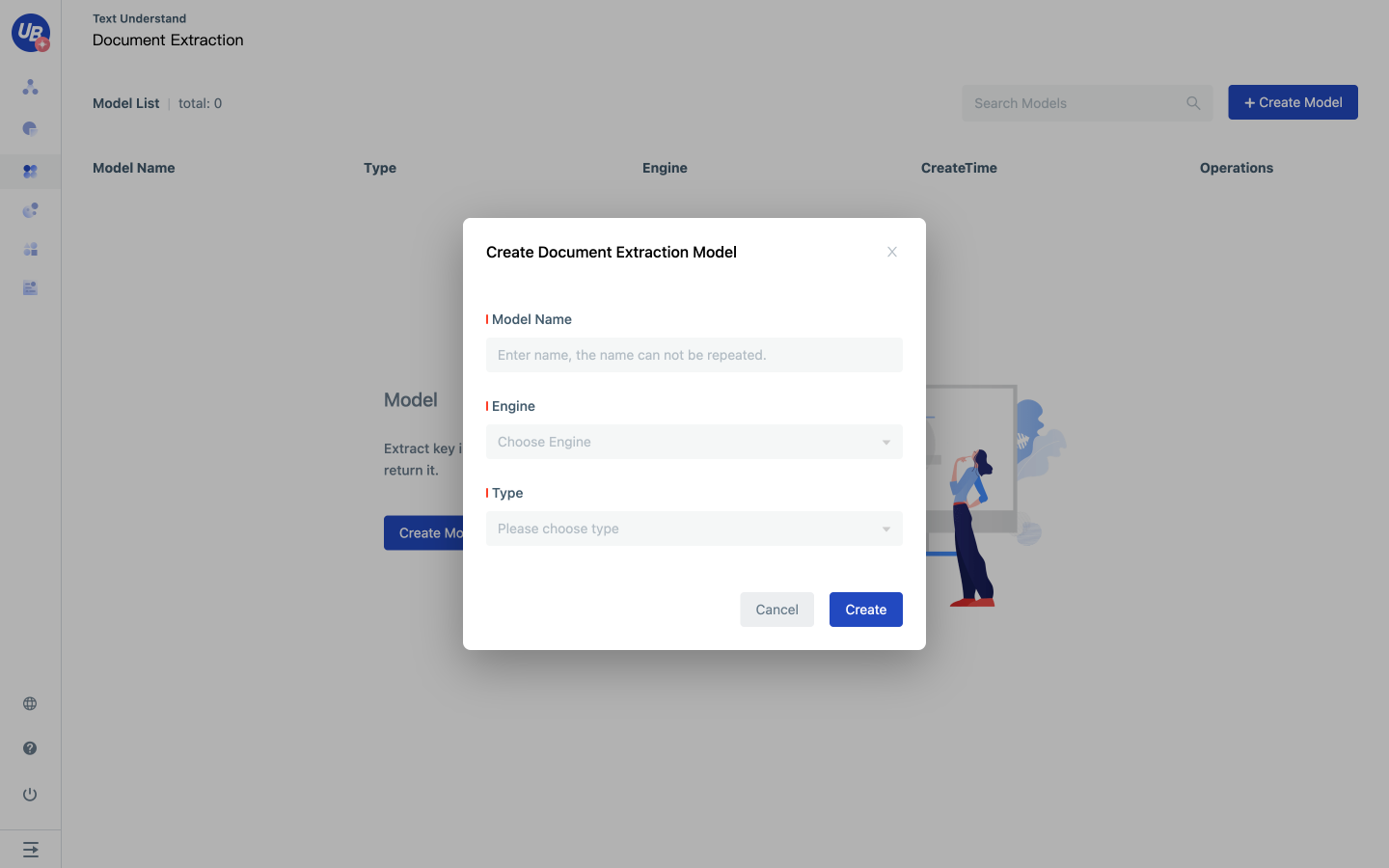
1 Log in to the Laiye IDP platform and go to the document extraction model page by Pretrained Capability/Text Understand/Document Extraction.

2 Create a document understanding model and select the OCR engine and document type based on service requirements.
Test
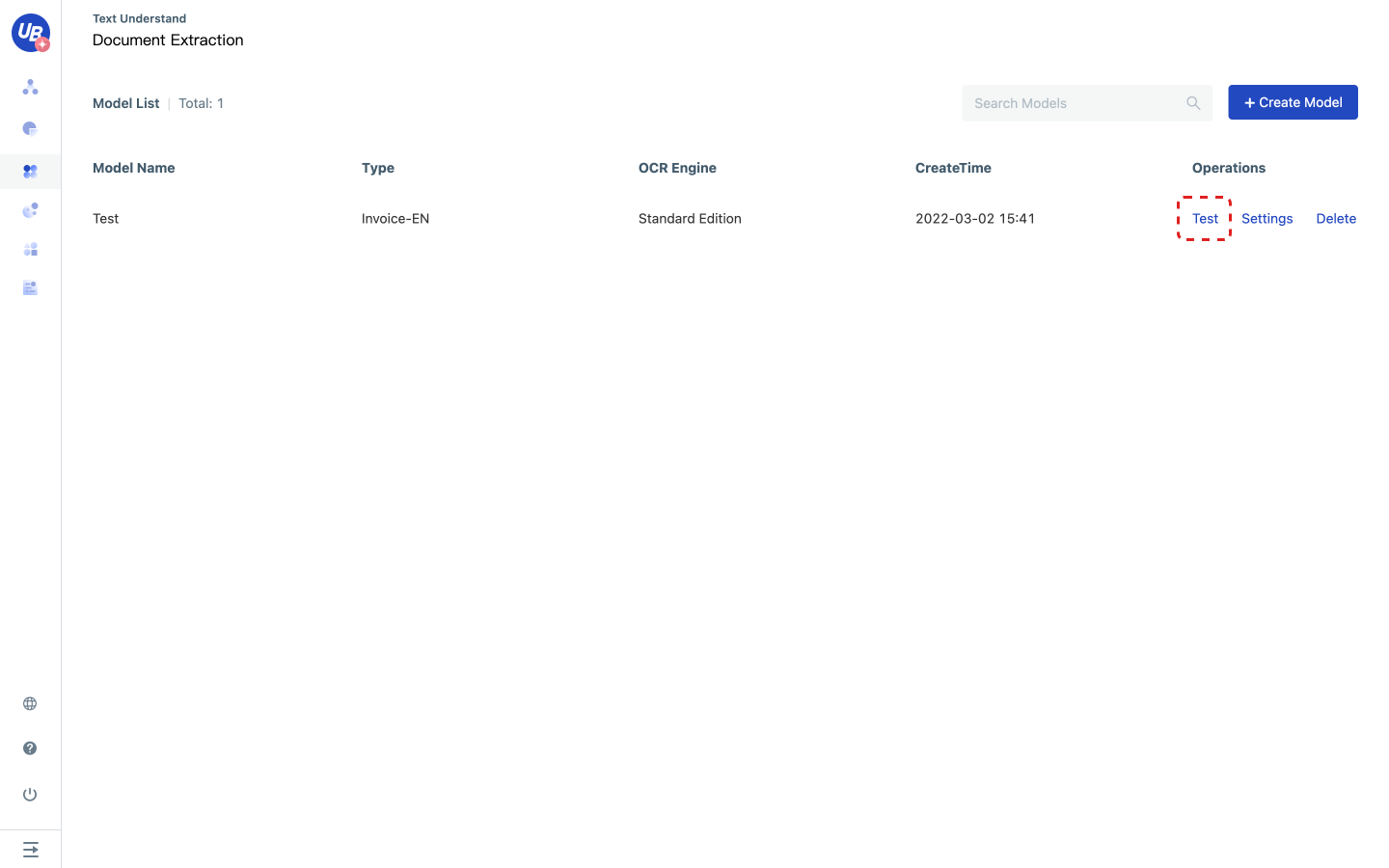
1 Click Test of document extraction model to enter the test page of the model.
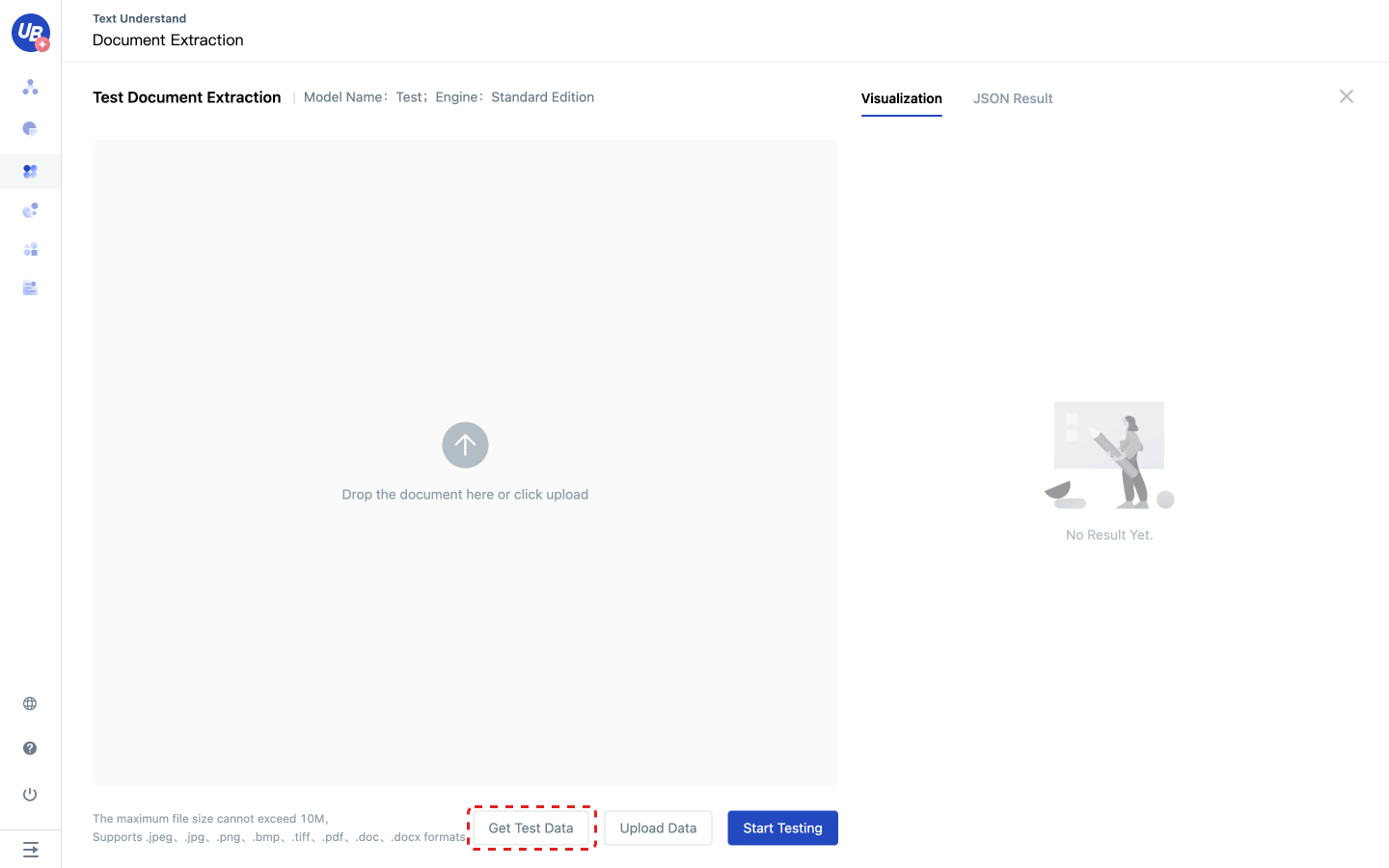
2 If you need the test sample, you can click obtain the test sample; If no, skip this step.
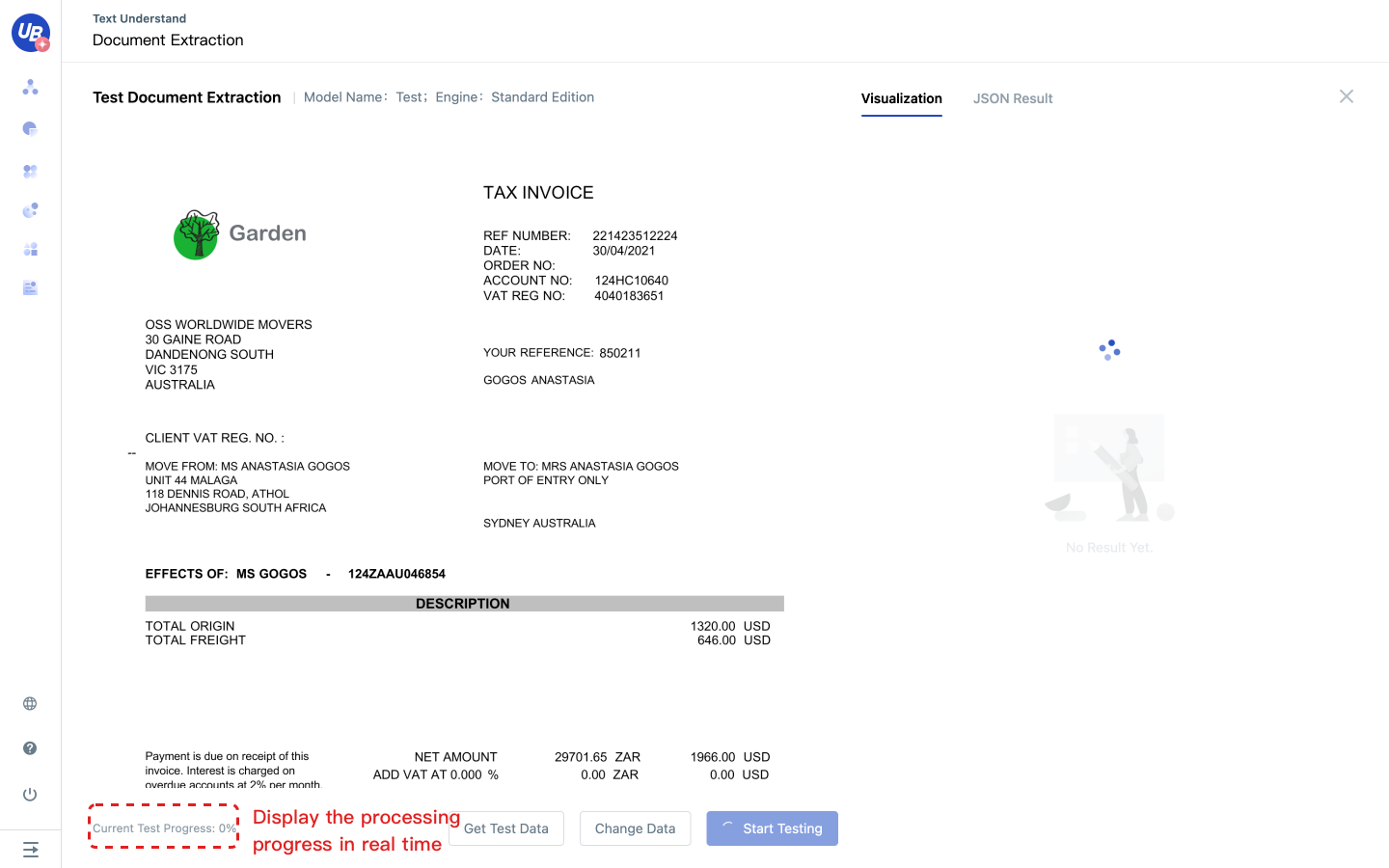
3 Upload a document, click Start testing, and obtain the extraction results.
Note: When the number of pages is too large, please wait patiently, the page will display the extraction progress in real-time.
Extract results
Different document types correspond to different document extraction models. After the test, the extraction results of all fields supported by the current model will be displayed on the visual page.

There are three main results:
- Extraction of the original text
- Extract results from the original text of the test document
- Support to update the document preview view and highlight the corresponding annotation area after clicking the content of the field in the list
- Non-textual extraction
- Extraction results are derived from the model's understanding of the test documents, possibly using classification models, normalized processing, etc
- There is no mark in the document preview area. The document preview view will not be updated after clicking the field content in the list
- Not extracted
- The extraction result is -
- The model did not extract the current field in the test document
Extraction fields of different type
Type:Invoice
| Index | Field name | key |
|---|---|---|
| 1 | Invoice Number | invoice_number |
| 2 | Vendor Name | vendor_name |
| 3 | Vendor Address | vendor_address |
| 4 | Invoice Issued Date | invoice_issued_date |
| 5 | Invoice Due Date | invoice_due_date |
| 6 | Payment Terms | payment_terms |
| 7 | Description | description |
| 8 | Quantity | quantity |
| 9 | Unit Price | unit_price |
| 10 | Subtotal | subtotal |
| 11 | Currency | currency |
| 12 | Tax Amount | tax_amount |
| 13 | Total Amount Due | total_amount_due |
Type:Purchase Order
| Index | Field name | Key |
|---|---|---|
| 1 | PO Num | po_num |
| 2 | PO Date | po_date |
| 3 | Delivery Date | delivery_date |
| 4 | Vendor Code | vendor_code |
| 5 | Vendor Name | vendor_name |
| 6 | Vendor Address | vendor_address |
| 7 | Vendor E-mail | vendor_email |
| 8 | Vendor Phone | vendor_phone |
| 9 | Customer Code | customer_code |
| 10 | Customer Name | customer_name |
| 11 | Customer Address | customer_address |
| 12 | Customer Buyer Name | customer_buyer_name |
| 13 | Customer Delivery Name | customer_delivery_name |
| 14 | Customer Delivery Address | customer_delivery_address |
| 15 | Customer Delivery E-mail | customer_delivery_email |
| 16 | Customer Delivery Phone | customer_delivery_phone |
| 17 | Customer Billing Name | customer_billing_name |
| 18 | Customer Billing Address | customer_billing_address |
| 19 | Customer Billing E-mail | customer_billing_email |
| 20 | Customer Billing Phone | customer_billing_phone |
| 21 | Currency | currency |
| 22 | Term of Payment | payment_term |
| 23 | Line Number | line_number |
| 24 | item Name | item_name |
| 25 | item Code | item_code |
| 26 | item type | item_type |
| 27 | item description | item_description |
| 28 | item Unit | item_unit |
| 29 | item Quantity | item_quantity |
| 30 | item Unit Price | item_unit_price |
| 31 | item Discount | item_discount |
| 32 | item Amount | item_amount |
| 33 | item Delivery Date | item_delivery_date |
| 34 | Total | total |