Text Classification
Business Scenario Description
Text classification is the customized Text Understand capability provided by Laiye IDP, which can classify text into specified categories according to certain rules.
For example, business personnel has several news headlines from yesterday, hoping that AI can help to identify the class of news, and then distribute it to the corresponding section.
| News Title | Category |
|---|---|
| The central bank's trillions of funds landed, why did not arouse the "restless splash" of the property market | Finance |
| ST Baoqianli, which has broken the A-share record for 29 consecutive times, has been limit down, should I buy at the bottom? | Finance |
| If the Warriors win the championship this year, does it count as start a dynasty? | Sports |
| Who are the top ten in NBA history? | Sports |
The user can achieve the goal by using text classification capability.
Keywords Version VS Model Version
There are 2 classification methods: the keywords version uses user-defined keywords for classification, and the model version uses a pre-trained model to learn rules from samples uploaded by users for classification.
Keywords version
The keyword version uses user-defined keywords to strictly match the test text for text classification. It is suitable for the situation where there are significant keywords in the text, and has the following characteristics:
- Developers need to pre-set all categories that need to be identified.
- Each category can have multiple features, and the relationship between features is OR.
- Each feature can be defined by a keyword group consisting of several keywords, and the relationship between the keywords is AND.
- The model uses all the keyword groups under each category to perform strict matching. Once the matching is successful, the subsequent keyword groups will be skipped, that is, only one keyword group will be returned under one category at most.
For example, this user created 2 categories A and B, and added 4 keyword groups.
| Category | Feature | Keyword Group |
|---|---|---|
| A | Feature x | O1,O2,O3 |
| Feature y | O1,O2,O4 | |
| B | Feature i | O2,O3,O4 |
| Feature j | O2,O3,O5 |
When the classified text is "O1O2O3", all the keywords of the feature x are matched, so the category is A.
When the classified text is "O1O2O3O4", all keywords of features x and i are matched, so feature y will be skipped after feature x, the categories of the classified text are A and B.
Models version
Language expressions are diverse, different people will use different expressions for the same meaning. It is impossible to summarize all the features manually, so AI models are needed to learn the features in the samples. When users use similar expressions again, they can identify their meanings and classify them into the correct category.
The model version provides a pre-trained model, which learns the rules from the samples uploaded by the user for classification.
The model version is suitable for scenarios that have complex classification requirements but difficult to generalize. It has the following characteristics:
- Developers need to pre-set all the categories that need to be identified and create at least two categories before training.
- The developer provides some training data to train a semantic understanding model.
- The model will give the confidence to indicate how well the test text matches each category.
- Add the misclassified test text to the training set to continuously optimize the performance of the model.
Instructions
Keywords Engine
1 After logging in to the platform, enter the text classification module from the following path: Customized AI Capabilities/Text Understand/Text Classification.
2 Click Create Classification Model to create a keyword text classification model.
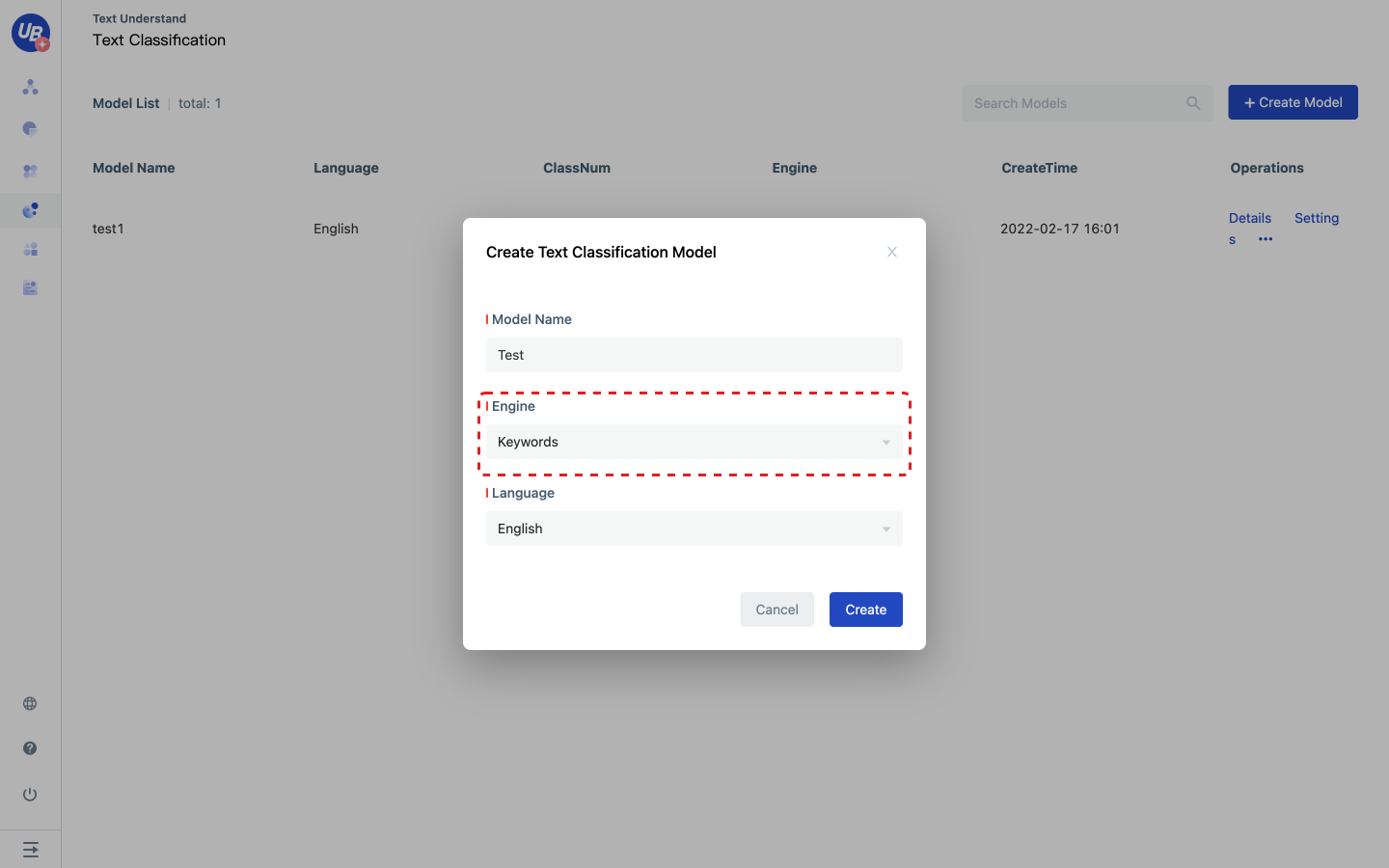
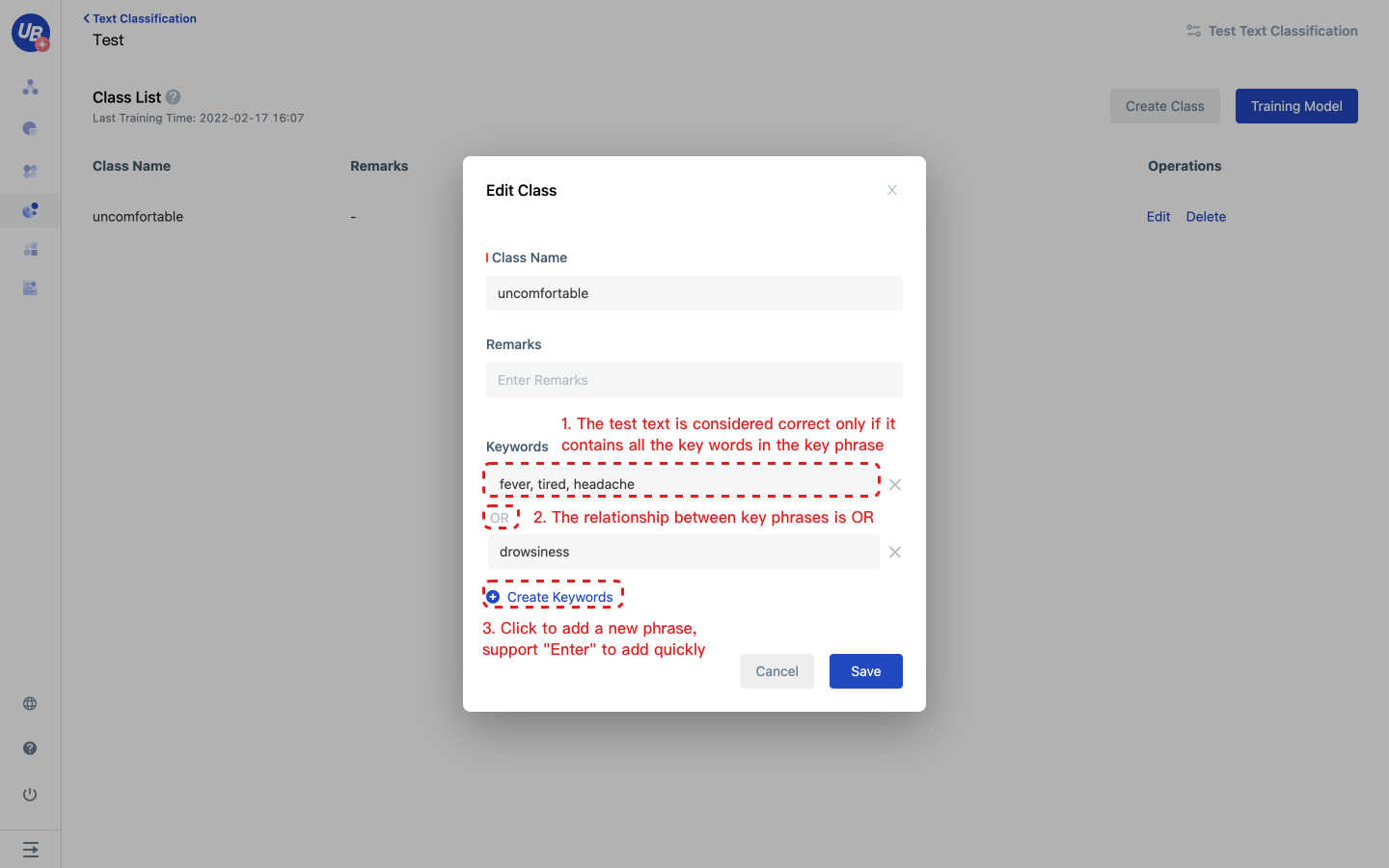
3 Click the model settings to view the pubkey and secret of the classifier. When using the extractor service in Laiye Creator, you need to input these two keys. 4 Click Open to enter the model configuration page 5 Click “Add Category” to set the category name, keyword group, remarks.
- Multiple keyword groups can be set, the relationship between keyword groups is OR
- The relationship between keywords contained in the same keyword group is AND
- Support to quickly add keyword groups through the shortcut key Enter
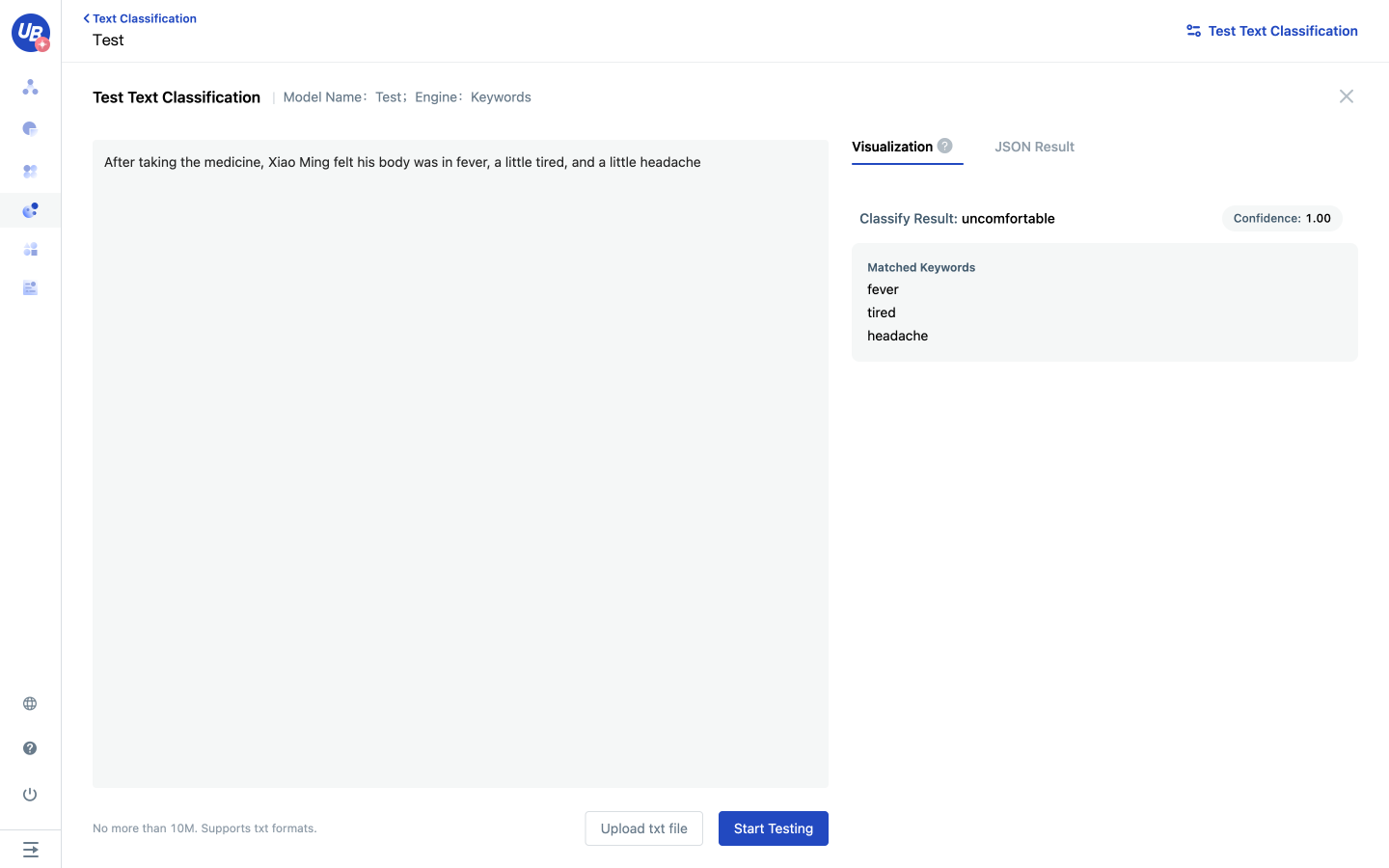
6 Click “Train Model”, the model will take effect automatically after training. 7 Click “Text Classification Test”, input the test text, and test whether the effect meets the expectations.
Models Engine
1 After logging in to the platform, enter the text classification module from the following path: Customized AI Capabilities/Text Understand/Text Classification. 2 Click “Create Classification Model” and choose “Models” to create a model version.
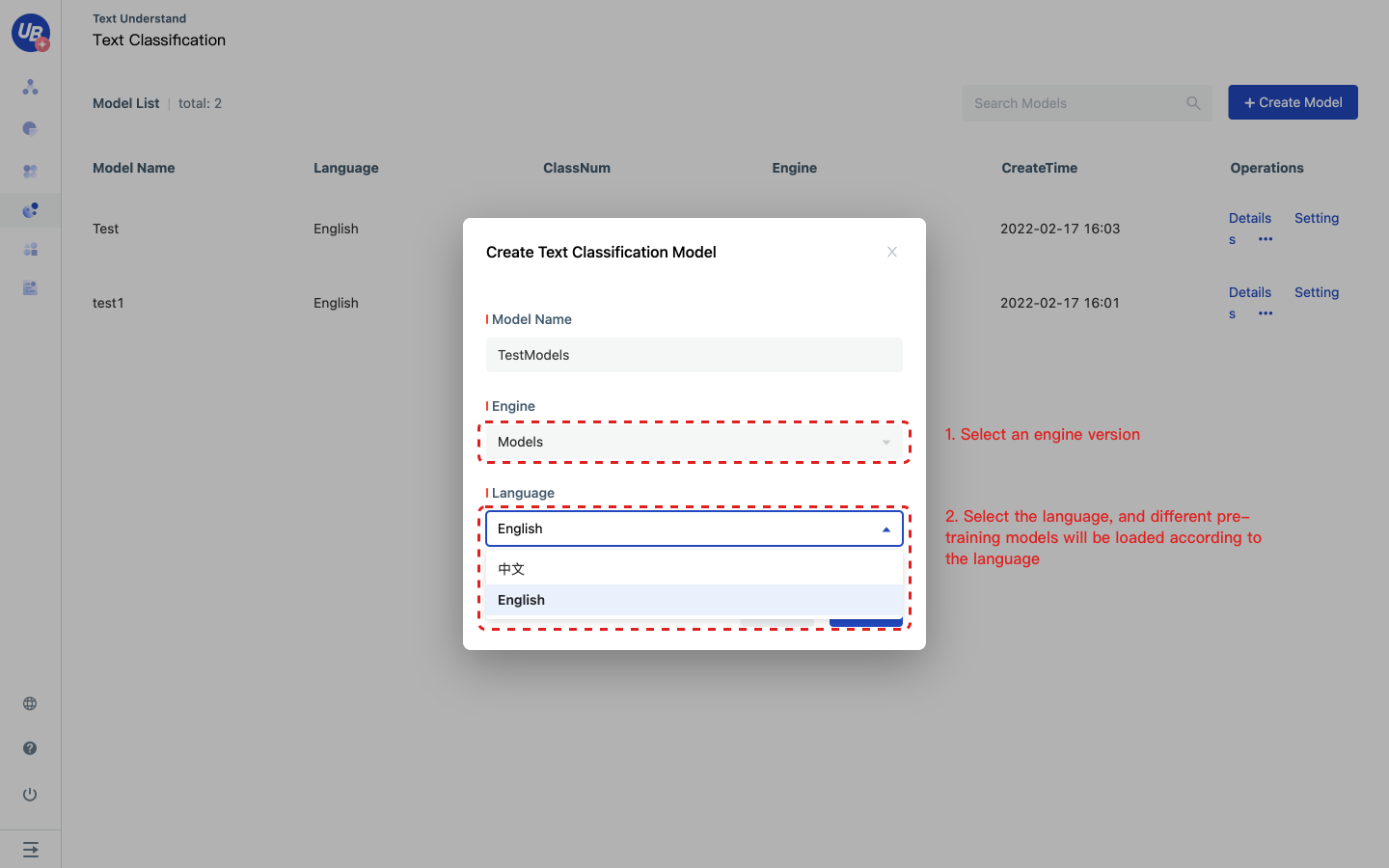
3 Click the model settings to view the pubkey and secret of the classifier. When using the extractor service in Laiye Creator, you need to input these two keys. 4 Click Open to enter the model configuration page.
- Familiarize yourself with the classification function with the downloaded sample files
- Subsequent actions will be guided based on the long text classification example in the example file
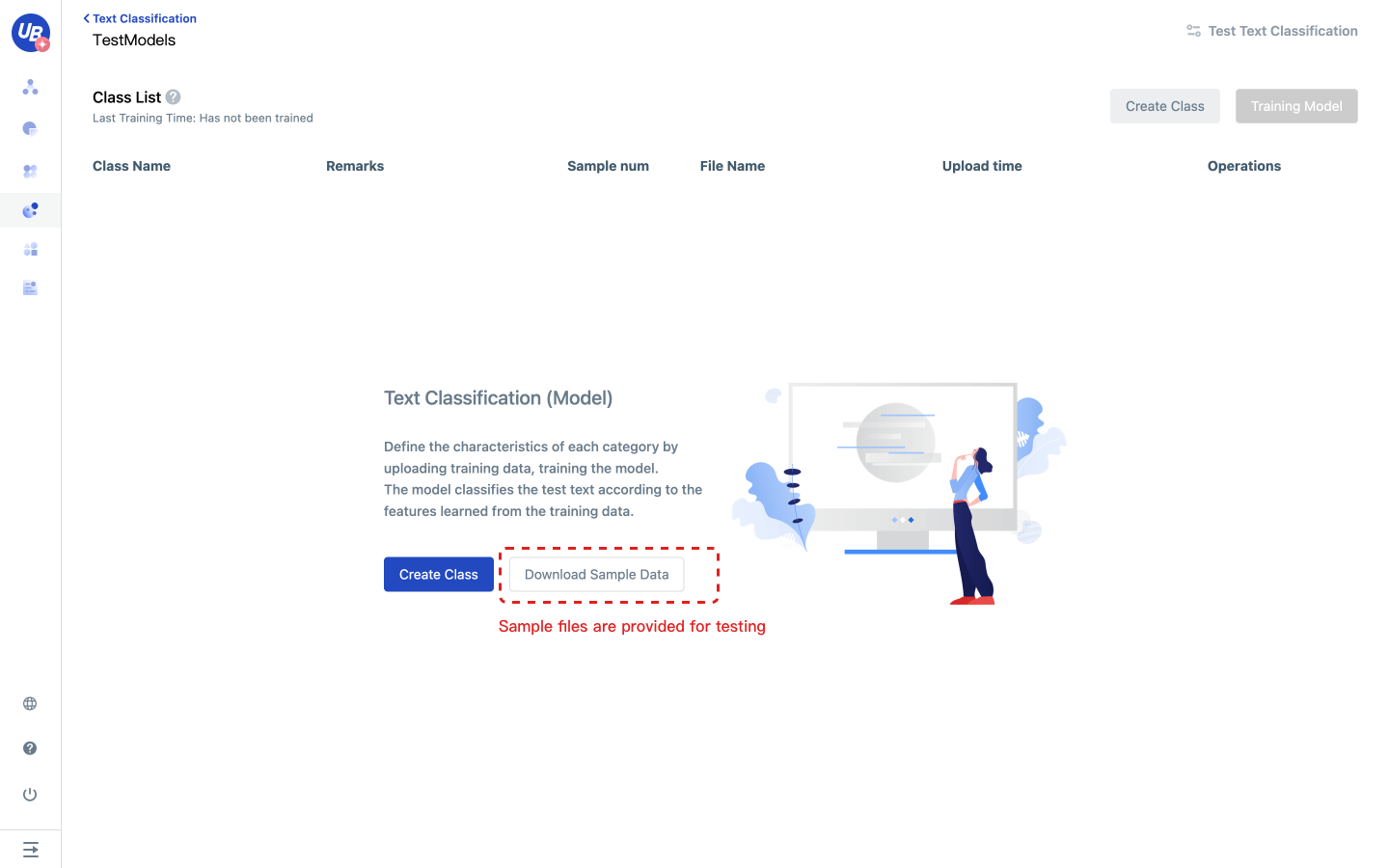
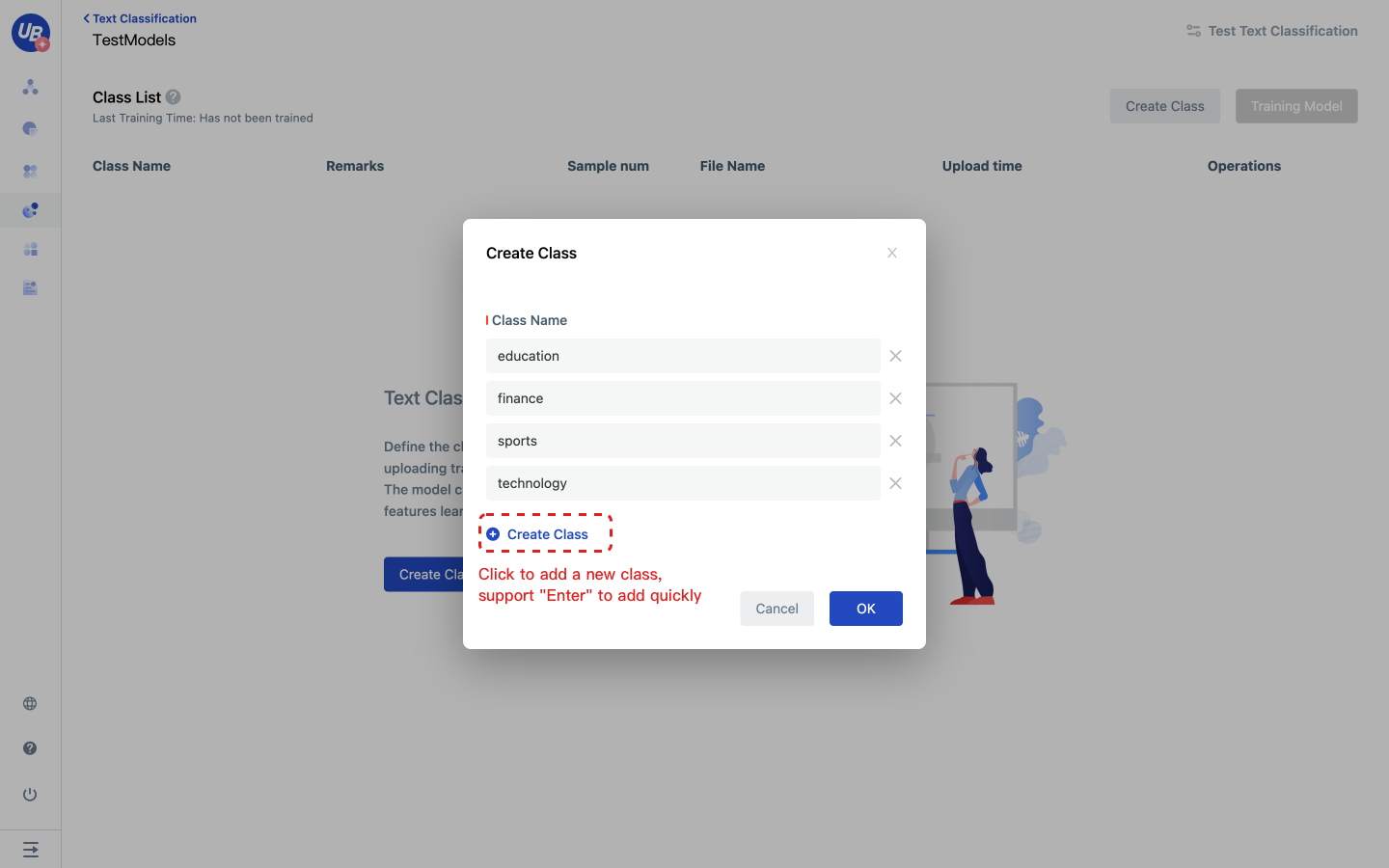
5 Click “Add Category” to create all the categories that need to be identified.
- Support quick addition by shortcut key Enter
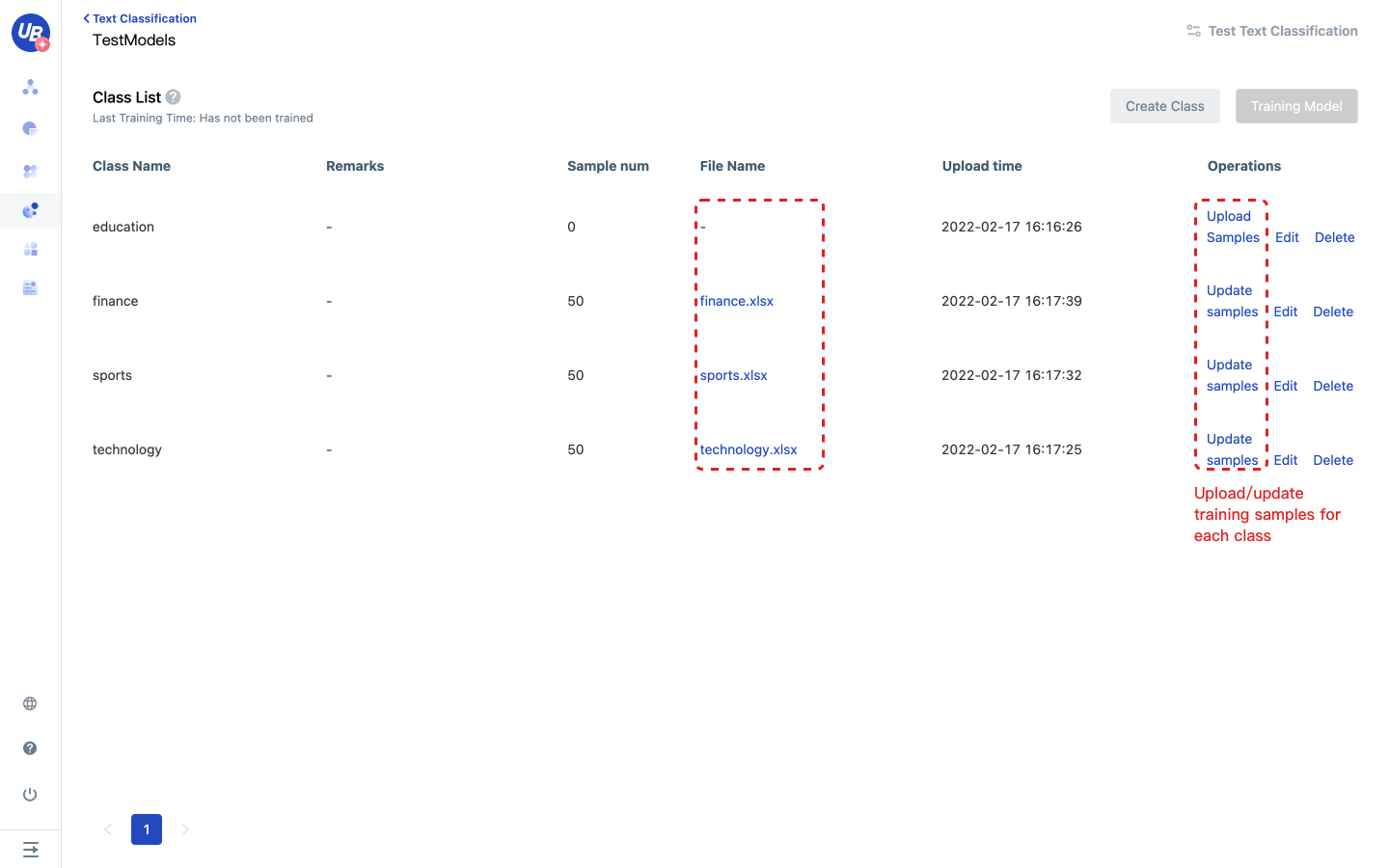
6 Click Upload Samples under each class to add training samples.
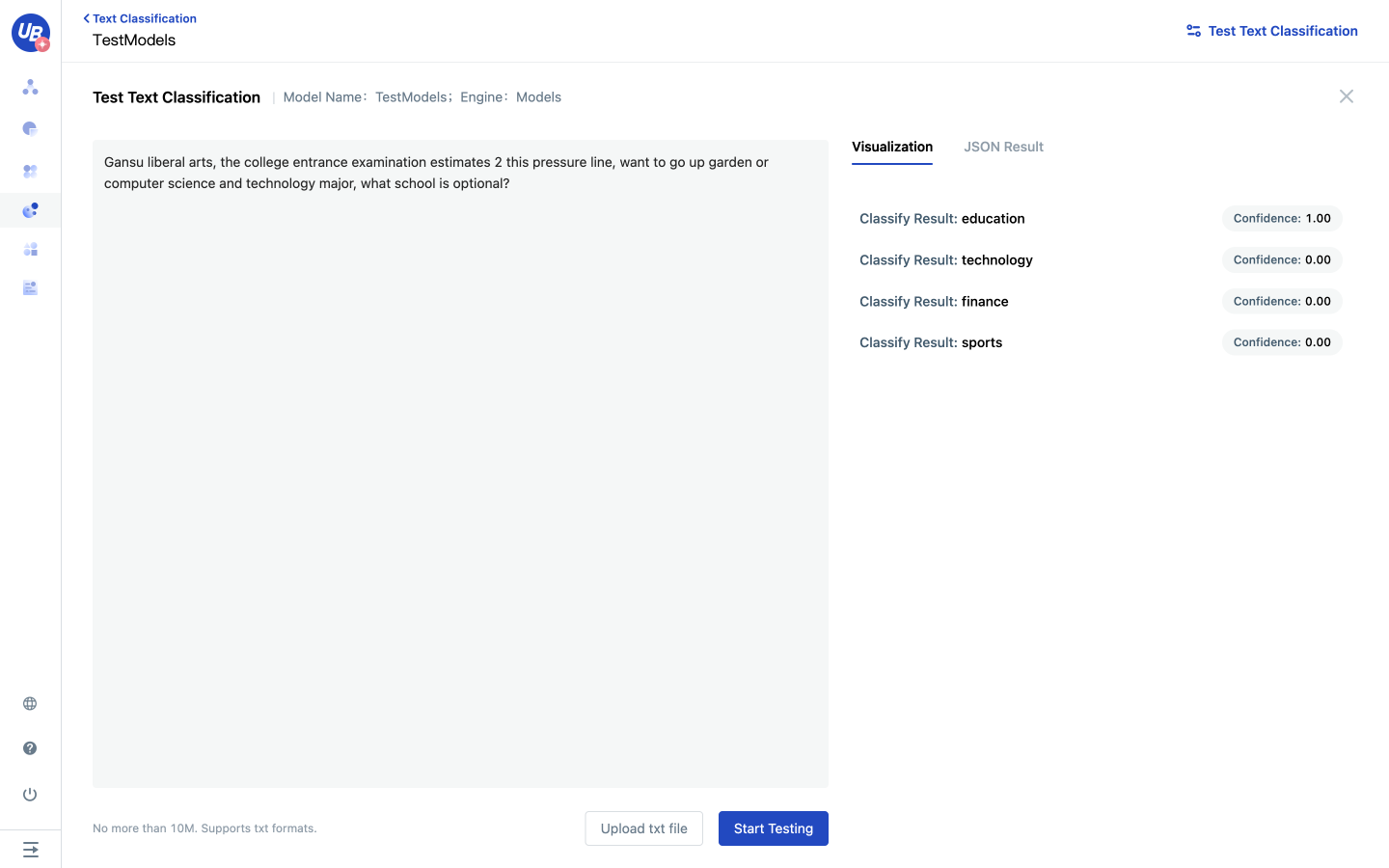
7 Click “Train Model”, the model will take effect automatically after training.
- At least two classes need to be created for training 8 Click “Text Classification Test”, input the test text, and test whether the effect meets the expectations.
Q&A
How to improve the performance of your model?
- Provide high-quality training samples: avoid the same sample appearing in multiple categories at the same time.
- A single training sample is recommended not to exceed 1000 words.
- The number of training samples for all categories is as balanced as possible
- Add the misclassified samples to the training set and retrain the model.