文档自训练抽取
简介
文档自训练抽取,适用于处理非结构化的多页文档,例如合同、招标公告、简历等。创建一个文档自训练抽取模型可以:
- 评测文档抽取中提供的预训练模型在真实业务数据上的效果
- 根据业务需求定义校验规则,实现文档的自动审核
业务场景描述
举例来说,某建筑施工公司的电话销售每天都需要从各个渠道筛选商机,并审核是否适合本公司进行投标。比如采集到一份招标公告,并期望得出如下结论:
北京市内的工程,投资额在250万以上,工期要求在30天以上,适合进一步跟踪。
说起来简单,但这里面的事情可不少,简单分析下大概需要以下4步:
- 在各个政府公开平台实时获取最新的招标公告,上传至企业知识库
- 业务人员A收到新的招标公告后,将招标公告的关键信息填入系统
- 业务人员B根据关键信息审核该项目是否适合进一步投入
- 将该信息推送给具体的销售人员,由销售人员去对接招标企业,完成后续的投标工作
我们可以使用RPA来完成第1、4步,使用文档理解完成第2、3步。在文档自训练抽取模型中配置抽取模型以及用于机器审核的校验规则,在人机协同中心或其他业务系统中实现人工二次审核。
特点
文档自训练抽取具有以下几个特点:
- 简单易用:每个步骤都配有引导,无代码完成『数据管理->标注->评测->校验配置->上线』的全流程,手把手的教你如何打造一个可用于生产环境的文档理解机器人。
- 配置灵活:支持预置、代码2种方式配置校验规则,用户可以根据业务需求配置个性化校验逻辑。
使用方法
下面将以业务场景描述中的招标公告筛选为例,创建一个招标公告智能审核模型。使用预训练AI能力文档抽取提供的招标公告预训练模型做抽取,并通过添加自定义规则来检查:
- 工程在北京市
- 投资额大于250万元
- 工期大于30天
如果业务人员确认招标公告满足以上三个条件,可以将招标公告标记为适合跟踪。
创建模型
1)登录平台后点击左侧导航栏的文档理解进入文档自训练抽取。
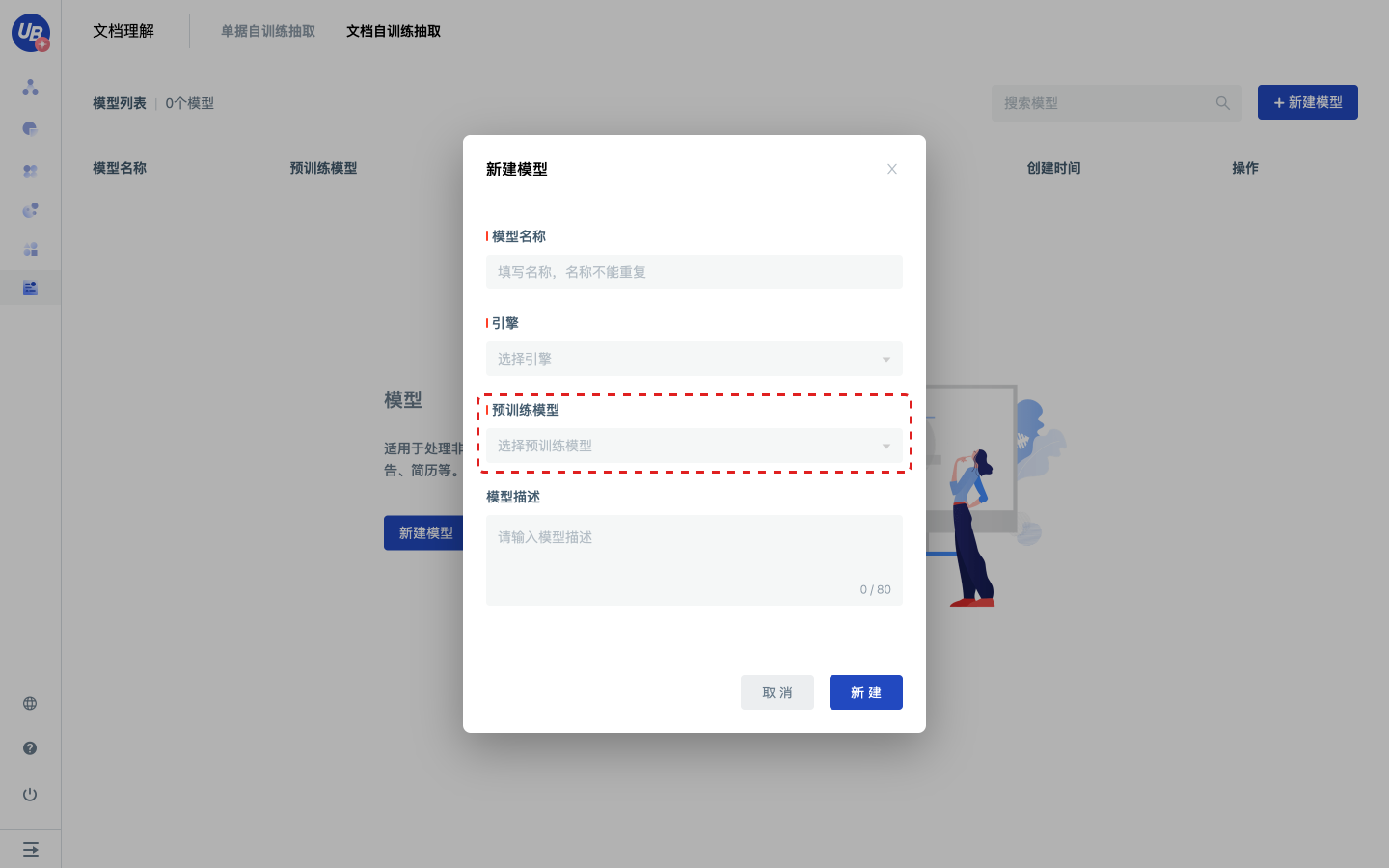
2)点击新建模型,创建一个预训练模型为招标公告的招标公告智能审核模型。
- OCR引擎:因为模型的输入为图片、pdf等非纯文本信息,需要用到OCR识别;OCR的效果将影响后续抽取的效果,请评估OCR识别效果后再选择
- 预训练模型:目前平台暂未支持用户训练模型,如果需要抽取,请选择对应的预训练模型
3)点击 开始或配置 进入模型配置

4)进入模型配置后,会看到右上角的工作进度引导,请按照工作进度的引导完成后续步骤。
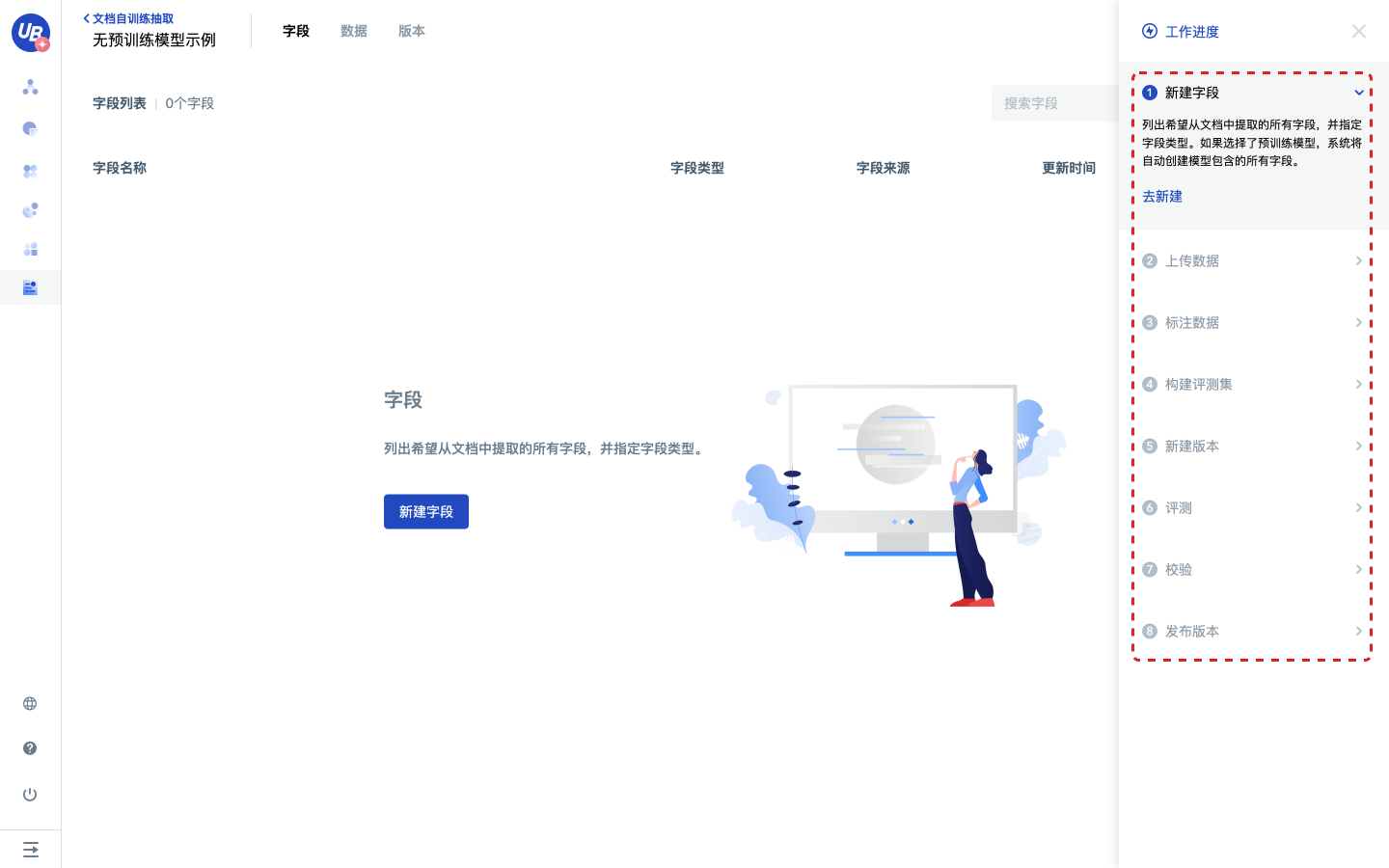
新建字段
1)点击工作进度中的第1步 新建字段,点击去新建,进入字段分页。
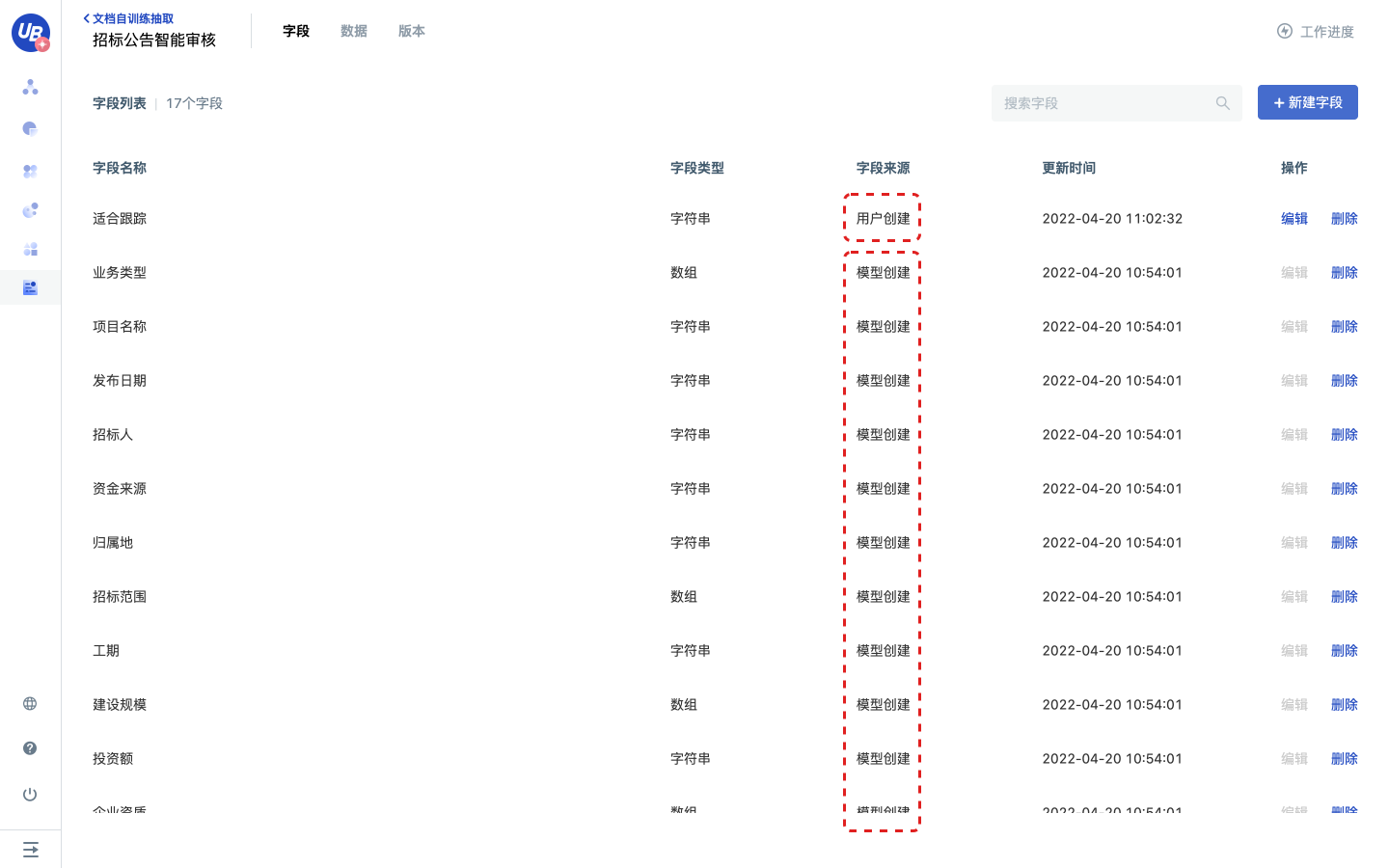
2)创建希望模型从文件中提取的字段,在这里,我们添加一个名称为适合跟踪的字段。
- 如果选择了预训练模型,模型将会自动创建预训练模型支持的所有字段。
- 字段名不得超过20个字
- 字段类型可以选择字符串、数组,字段创建后类型不支持修改
- 请谨慎删除字段来源为模型创建的字段,因为预训练模型将会通过字段名返回结果;如果不小心删除了模型创建的字段【项目名称】,可以新建一个名称相同的字段【项目名称】
上传数据
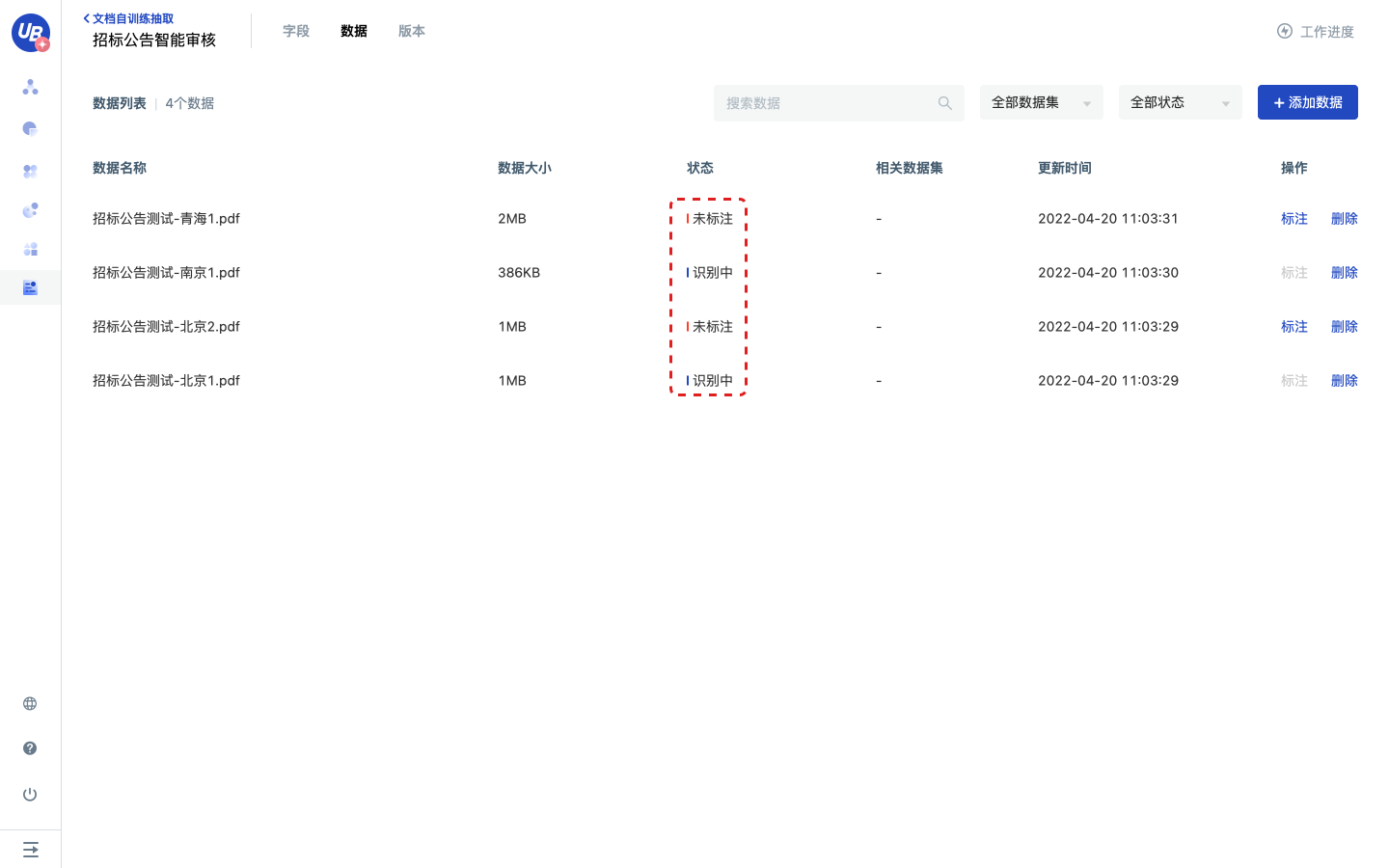
1)点击工作进度中的第2步 上传数据,点击去上传,进入数据分页。
2)上传相关业务数据到数据管理,数据上传后将自动进行OCR识别,识别完成后才能进行标注。
- 数据管理中的数据可以用于预训练模型的评测、校验规则的配置
- 如果想试用但是没有合适的文档,可以通过文档抽取->文档抽取测试->获取测试样本获取预训练模型的测试样本
标注数据,构建评测集
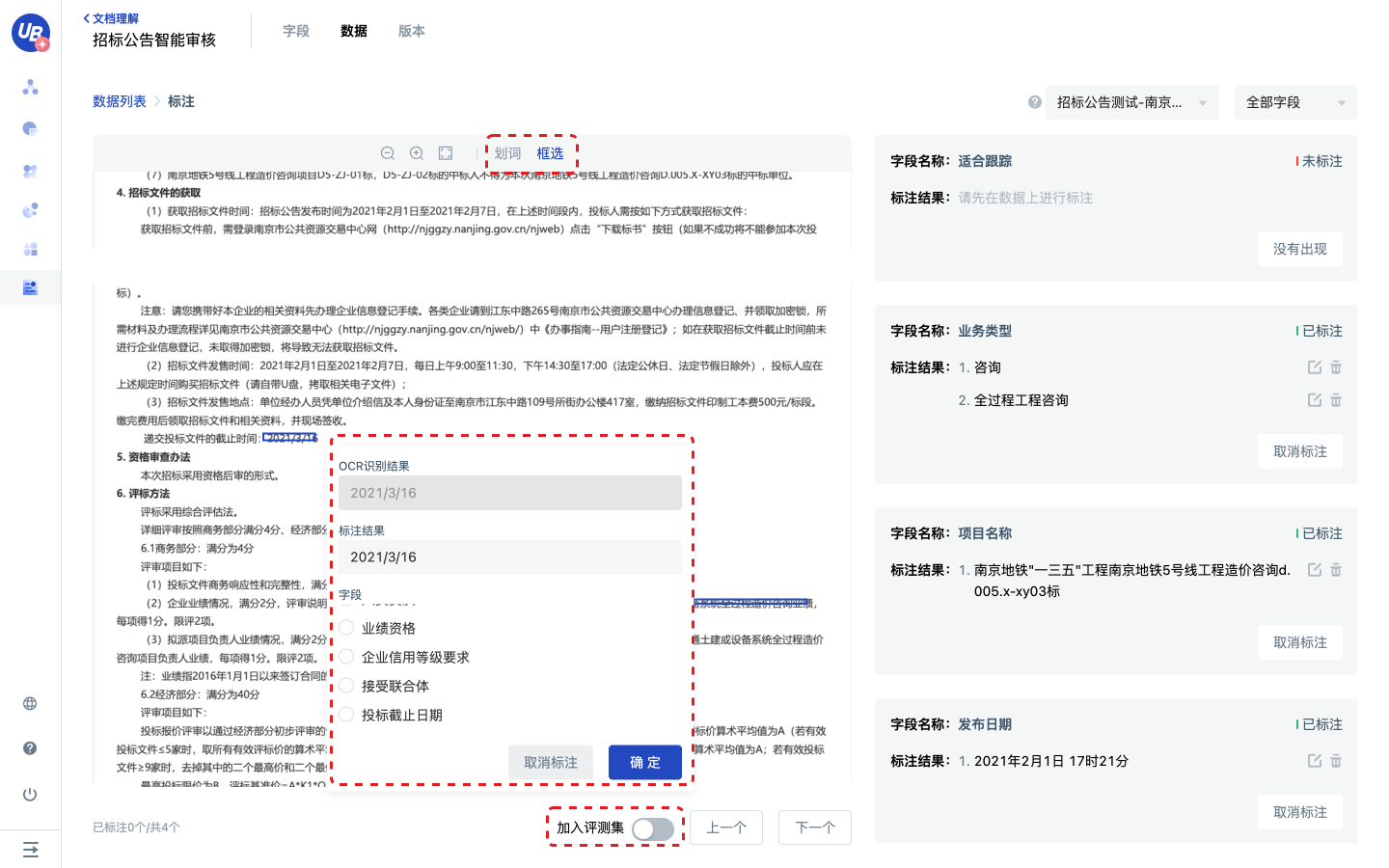
1)点击工作进度中的第3步 标注数据,点击去标注,进入数据分页。
2)点击任意一条数据的标注,进入标注页面。
- 如果模型选择了预训练模型,数据上传后会通过预训练模型进行预标注
3)标注页面提供划词、框选2种标注方法,选中字段值区域后,系统会自动弹出标注弹窗,可以在这个弹窗里修改标注结果、选择字段,最后点击确认,保存标注内容。
- 如果字段类型为数组,可以标注多个值
- 如果字段类型为字符串,第二次标注结果将会覆盖上次标注结果
- 如果一个字段在文档中没有出现,请将该字段标记为没有出现
- 标注完一条数据的所有字段后,数据的状态才会变成已标注
4)在标注页面将已标注的数据加入到评测集,用来评估模型的效果。
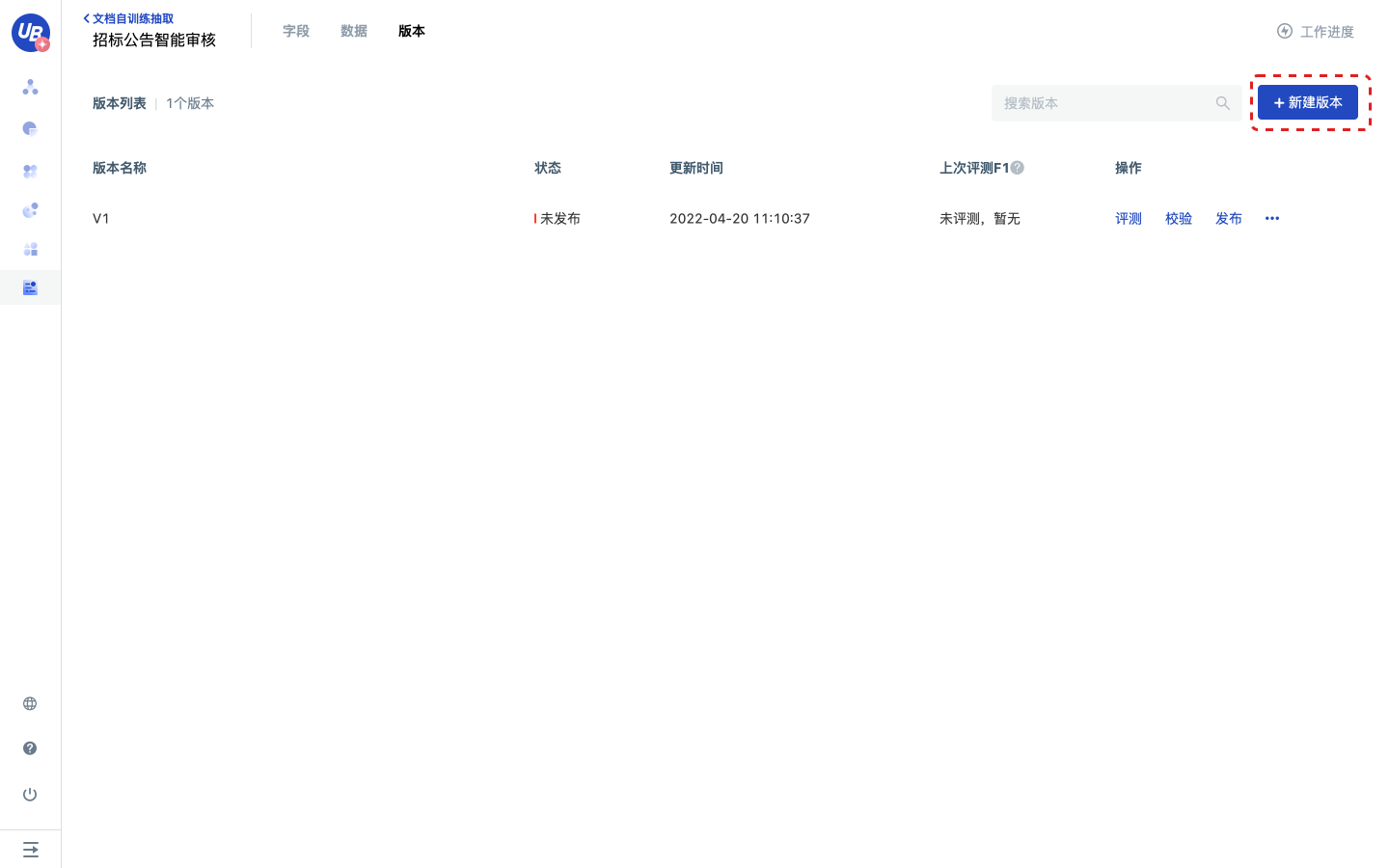
新建版本
1)点击工作进度中的第5步 新建版本,点击去新建,进入版本分页。
2)点击新建版本,创建一个名称为V1的版本。
评测预训练模型效果
1)点击工作进度中的第6步 评测,点击去评测,进入版本分页。
2)点击V1版本的评测,发起模型评测。
- 这里评测的是文档抽取提供的预训练模型的效果
3)等待评测完成后,点击版本的上次评测F1值,可以下载本次评测报告。
- 评测报告有结果概览、字段抽取统计、全部抽取结果、文档抽取详情4个sheet,可以从不同维度查看模型的效果。

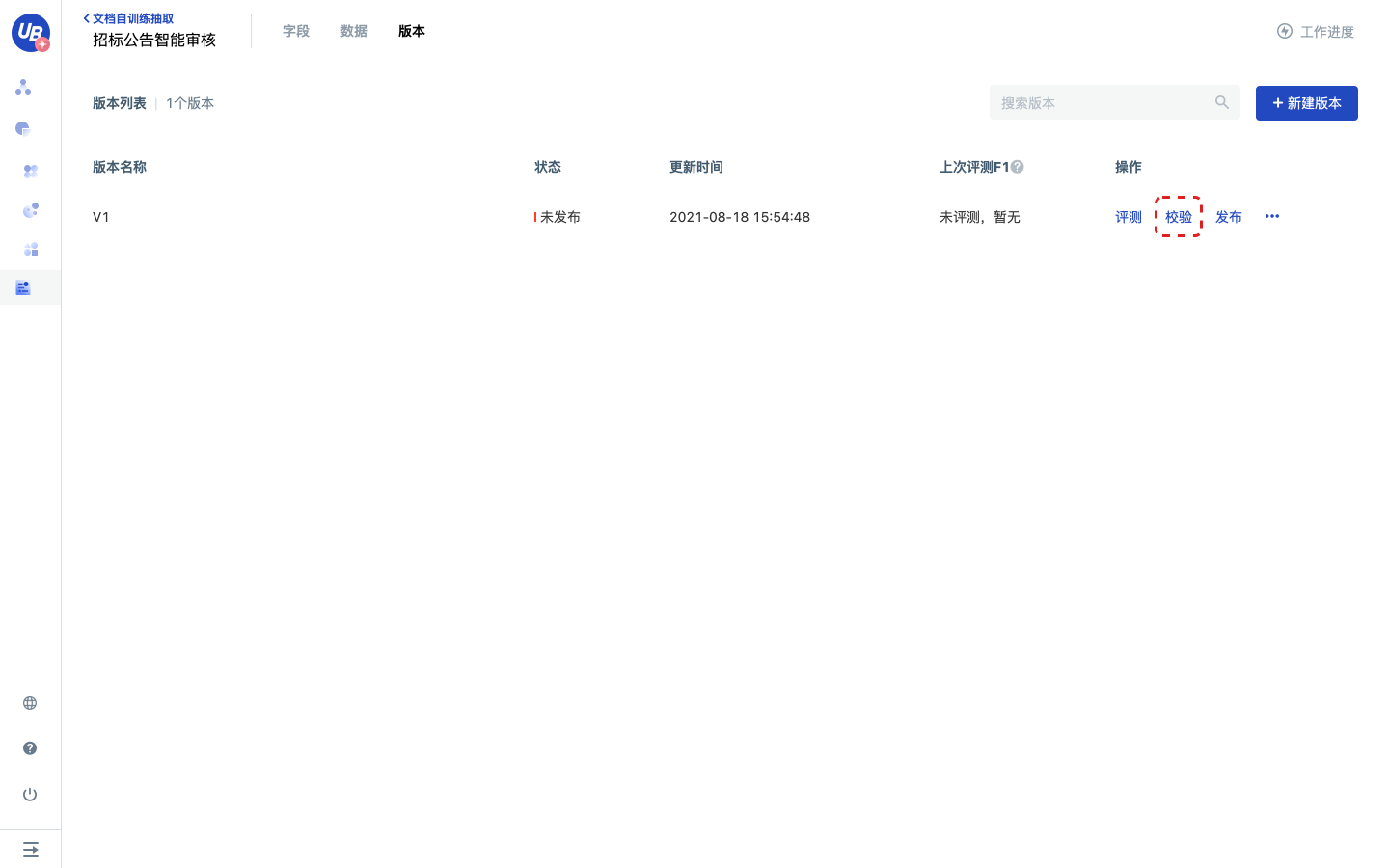
配置校验规则
1)点击工作进度中的第7步 校验,点击去配置,进入版本分页。
2)点击V1版本的校验,进入校验规则配置页面。
3)进入校验规则配置页面后,左侧为文档预览区域,右侧有三个标签页。
- 识别结果:展示文档的OCR识别结果
- 规则配置:配置校验规则
- 测试结果:展示校验规则测试结果
- 此处预览的文档来自于模型数据分页,且数据状态为已标注/未标注的数据
4)识别结果用于展示OCR识别的结果。
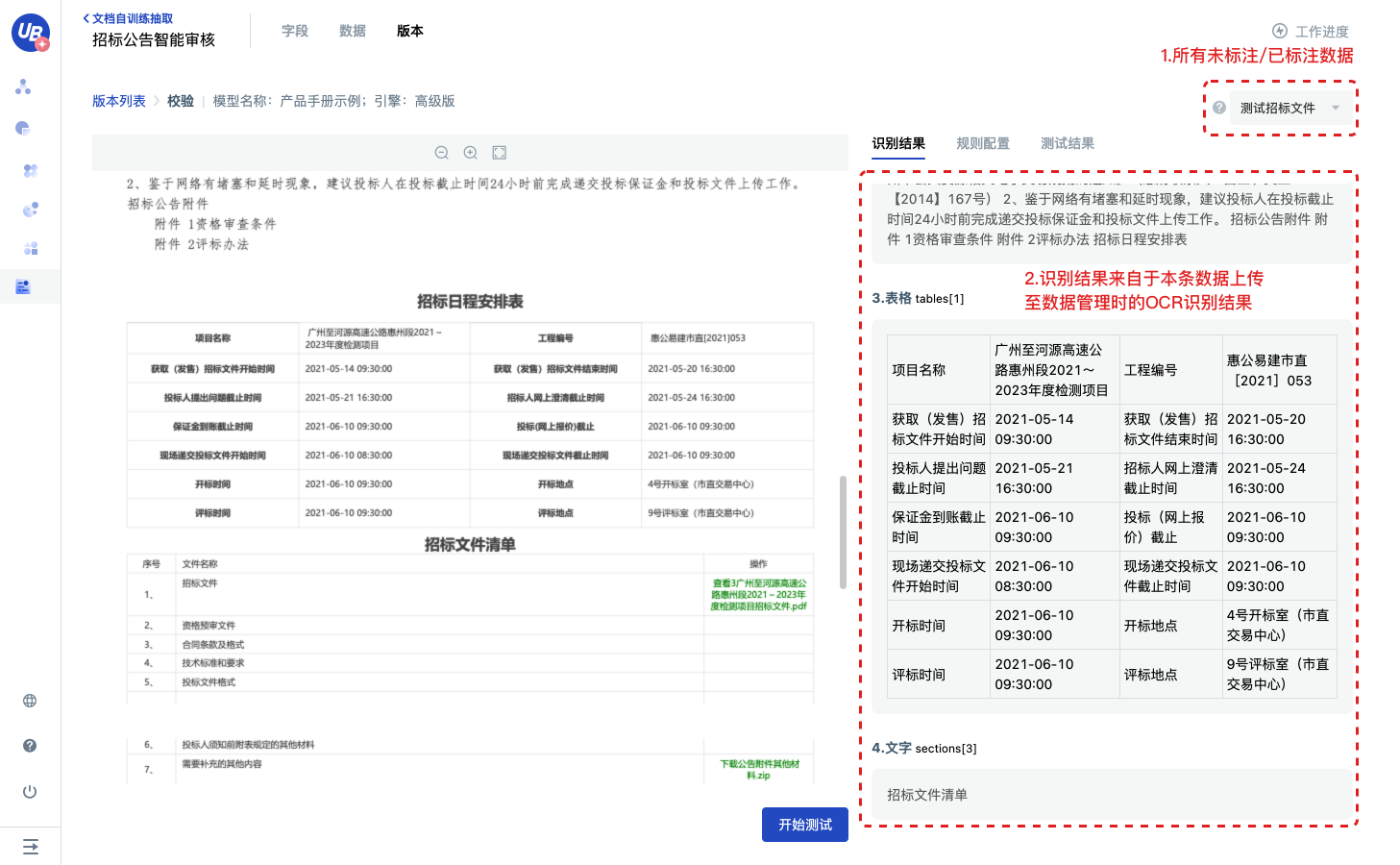
5)规则配置中的字段测试结果来自于数据上传时调用预训练模型的抽取结果。
- 如果没有选择预训练模型,字段的测试结果都为无
- 你可以通过页面标注或直接修改已有结果,填入字段测试结果,用于校验规则的调试
- 此处的修改不会影响数据的标注
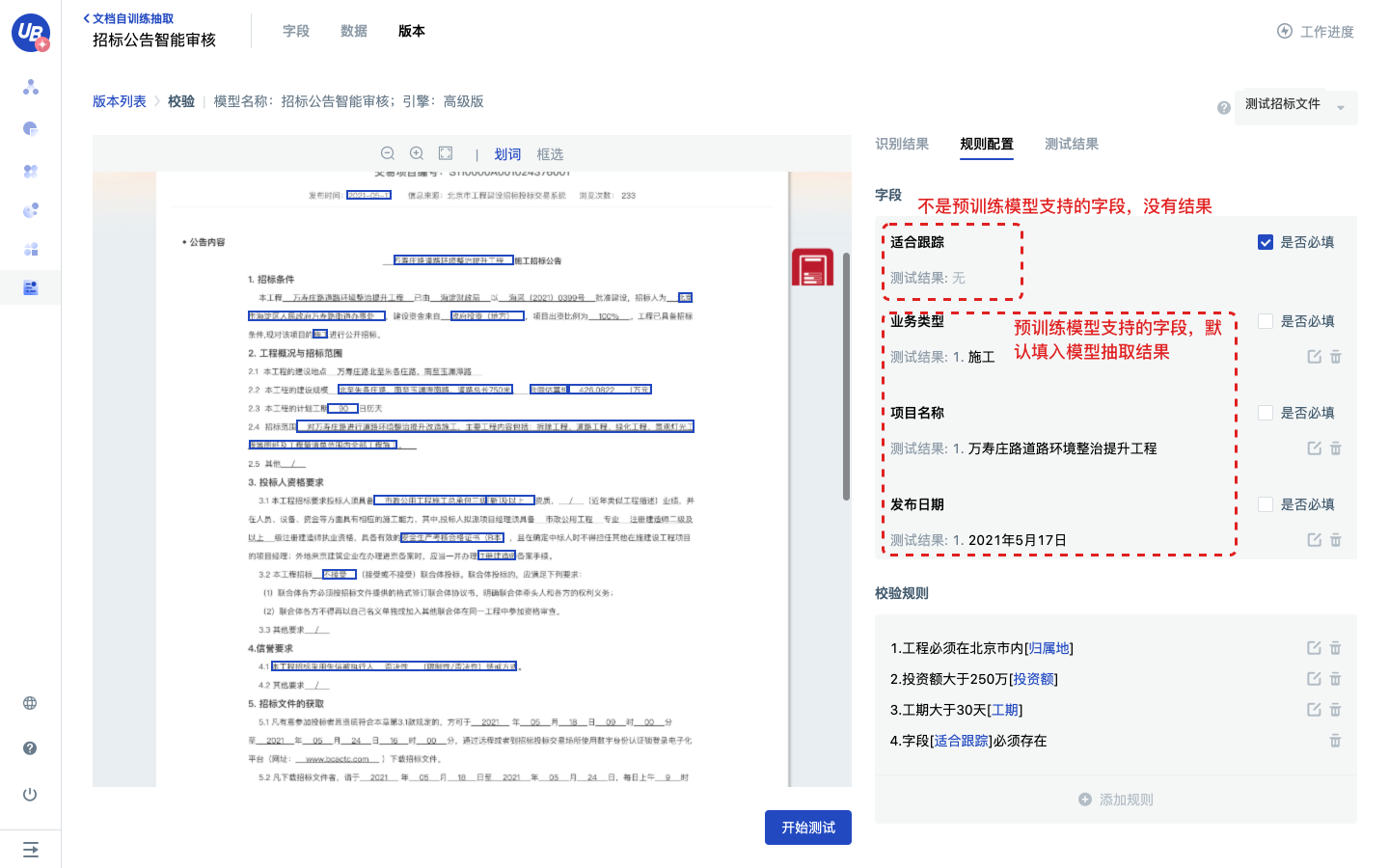
6)创建预置规则。
- 勾选字段是否必填,将会自动生成一条校验规则
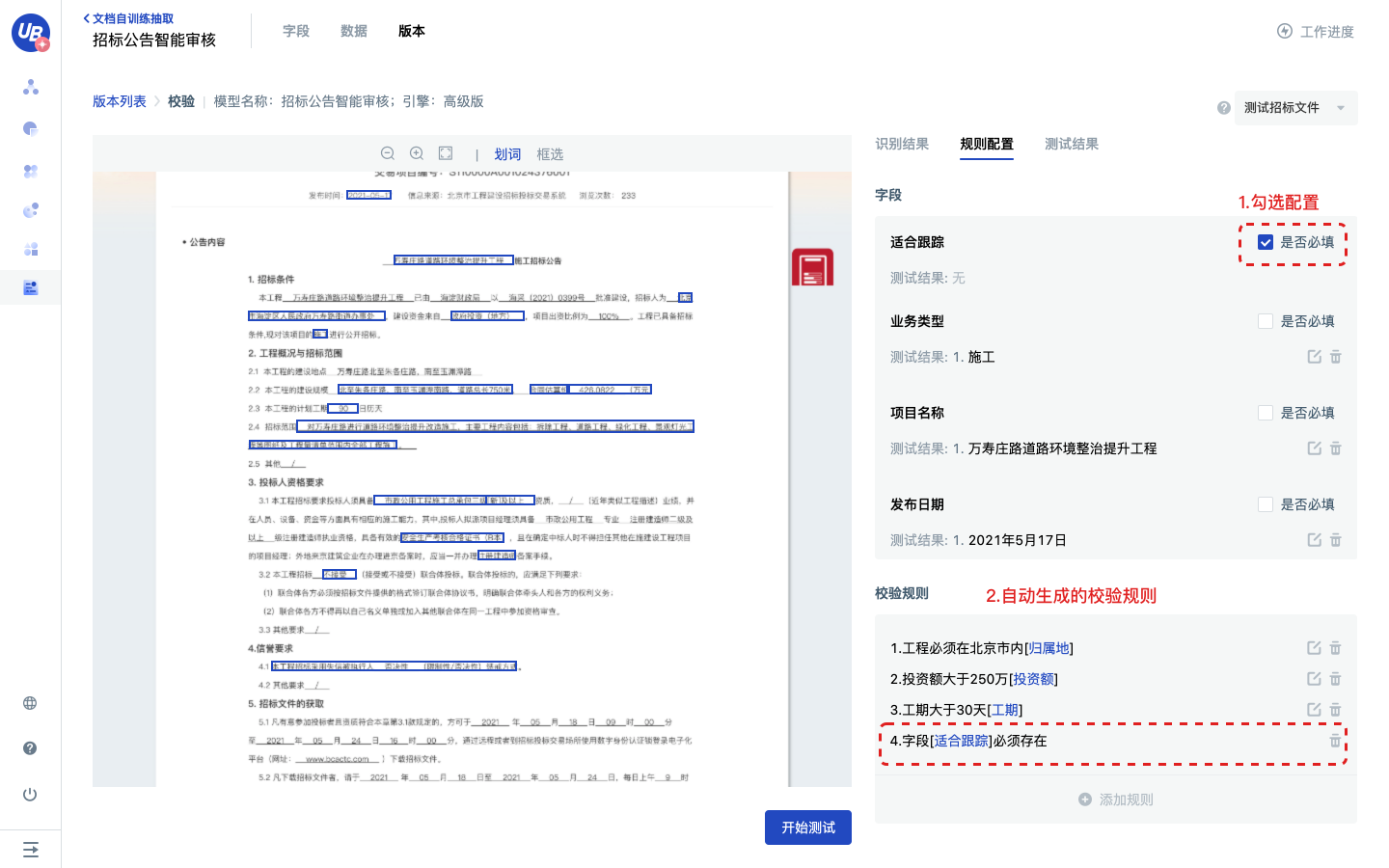
7)创建自定义规则。
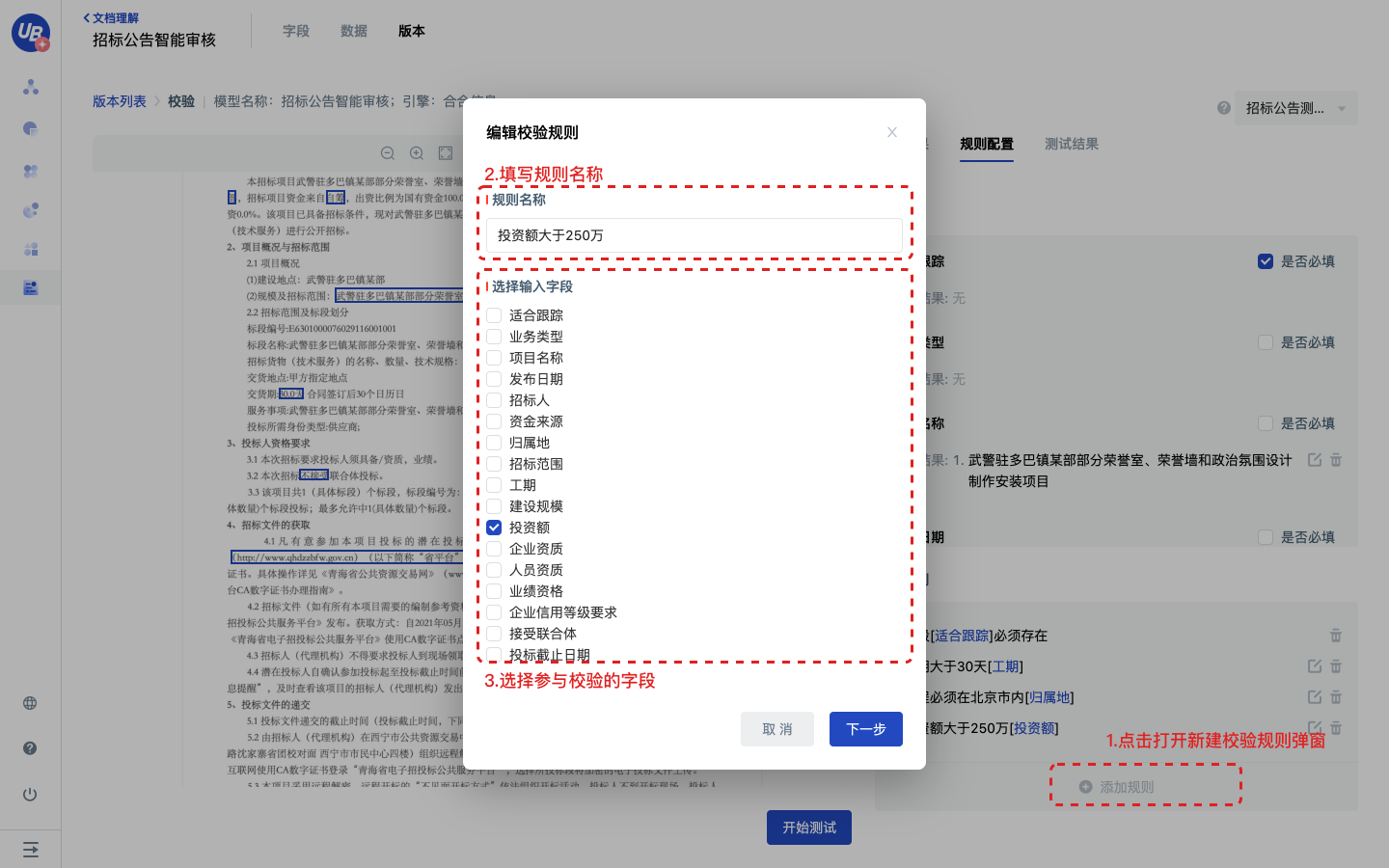
- 点击添加规则,输入规则名称,选择参与校验的字段,点击下一步
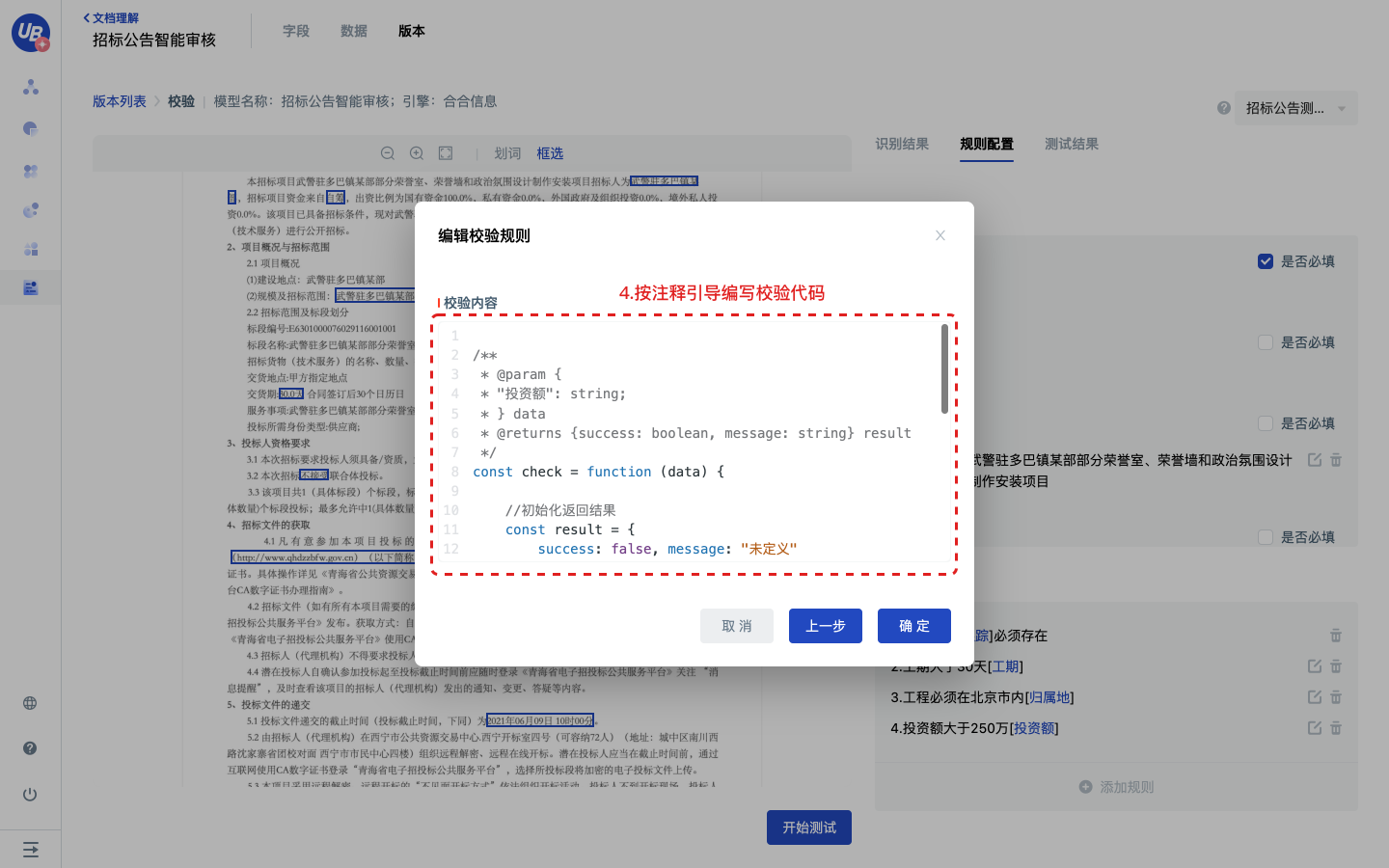
- 在校验内容里按照注释引导编写校验代码,点击确定提交
- 校验代码使用JavaScript编程语言,具体请参考JavaScript 教程
- 我们也在常见问题部分提供了2个校验规则的示例供参考。
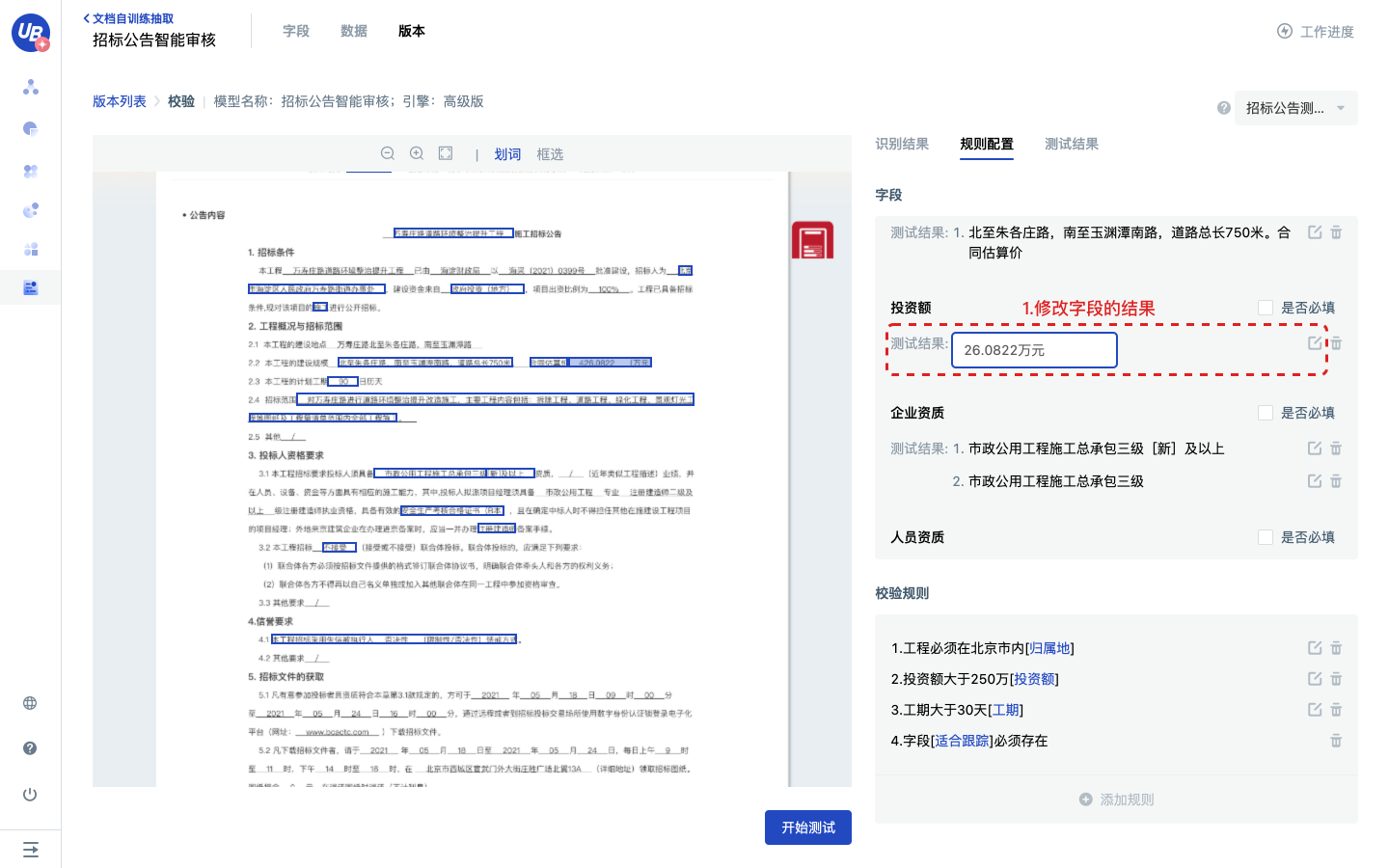
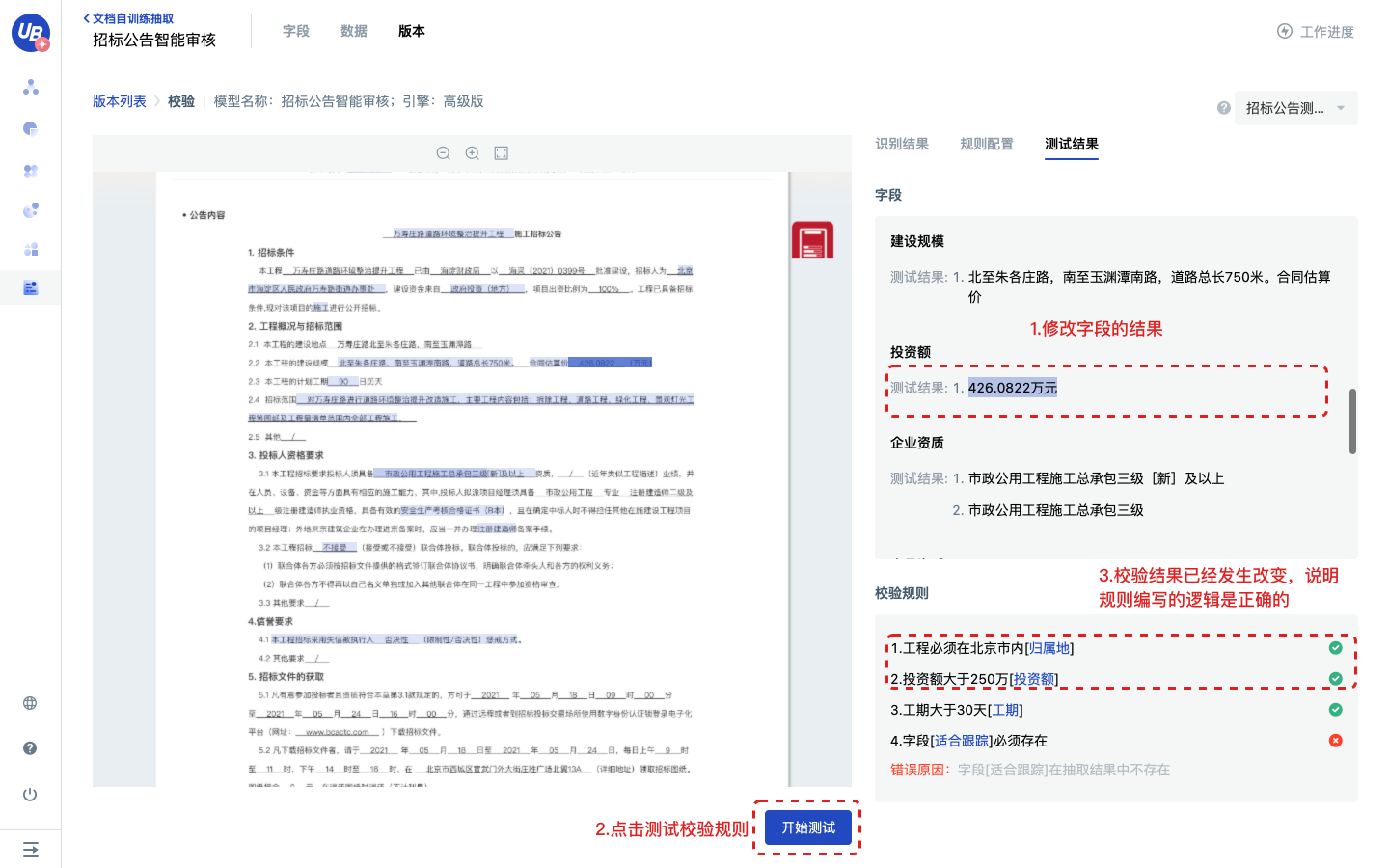
8)点击开始测试,模型将会以规则配置页面的字段测试结果为输入,去测试校验规则是否通过。

9)改变字段的测试结果,测试规则配置是否正确。
发布版本
1)点击工作进度中的第8步 发布,点击去发布,进入版本分页。
2)点击V1版本的发布,将当前版本发布。
3)发布之后,可以在模型列表点击模型的测试效果,测试效果是否满足预期。
常见问题
次数扣减逻辑
文档自训练抽取是一个复杂综合型AI能力,里面可能会调用OCR文字识别、OCR表格识别、预训练抽取模型等其他AI能力,平台将会以页数+AI能力来扣减文档理解AI能力的次数。 以下为相关的次数扣减:
- 数据管理:上传数据后,按文件页数扣除次数
- 模型>测试:点击测试,按文件页数扣除次数
和自定义模板有什么区别
自定义模板处理的是单页、固定版式的结构化或半结构化文档,文档理解可以处理多页、没有固定版式的非结构化文档。
校验规则示例
示例1:投资额大于250万
/**
* @param {
* "投资额": string;
* } data
* @returns {success: boolean, message: string} result
*/
const check = function (data) {
//初始化返回结果
const result = {
success: false, message: "未定义"
}
if(data["投资额"] == ""){
result.success = false;
result.message = "错误,该字段不能为空"
return result
}
let temp = parseFloat(data["投资额"])
if (temp > 250) {
result.success = true;
}else{
result.success = false;
result.message = "错误,投资额<250万"
}
return result
};
示例2:工程必须在北京市内
/**
* @param {
* "归属地": string;
* } data
* @returns {success: boolean, message: string} result
*/
const check = function (data) {
const result = {
success: false, message: "未定义"
}
if(data["归属地"] == ""){
result.success = false;
result.message = "错误,该字段不能为空"
return result
}
if (data["归属地"].includes("北京")) {
result.success = true;
}else{
result.success = false;
result.message = "错误,工程不在北京市内"
}
return result
};