信息抽取
业务场景描述
企业中80%的数据都是非结构化数据,而计算机擅长的是阅读和操作结构化数据。那么,对于RPA开发者来说,如何将企业中的非结构化数据提取出去,形成结构化数据是一个需要解决的问题。
当非结构化数据存在于各类文本中时,UiBot Mage为开发者提供了“信息抽取”这一AI能力,实现将“非结构化数据”转变为“结构化数据”。
举例来说,有如下五段上市公司的披露公告。
公告一
持有本公司股份300,000股(占本公司总股本0.0284%)的高级管理人员肖宝玉拟自本公告起十五个交易日后的六个月内,以集中竞价方式减持本公司股份不超过75,000股(占公司总股本的0.0071%),已跟监事进行确认。
公告二
持有本公司股份158,858股(占本公司总股本0.0150%)的监事赵毅拟自本公告起十五个交易日后的六个月内,以集中竞价或大宗交易方式减持本公司股份不超过39,715股(占公司总股本的0.0038%)。
公告三
持有本公司股份1,208,035股(占本公司总股本0.1144%)的高级管理人员敖志强拟自本公告起十五个交易日后的六个月内,以集中竞价或大宗交易方式减持本公司股份不超过250,000股(占公司总股本的0.0237%)。
公告四
持有本公司股份130,162,360股(占本公司总股本12.3220%)的控股股东、实际控制人之一霍卫平拟自本公告起十五个交易日后的六个月内,以集中竞价或大宗交易方式减持本公司股份不超过2,000,000股(占公司总股本的0.1893%)。
公告五
持有本公司股份100,000股(占本公司总股本0.0095%)的高级管理人员肖春夏拟自本公告起十五个交易日后的六个月内,以集中竞价方式减持本公司股份不超过25,000股(占公司总股本的0.0024%),已跟监事进行确认。
开发者希望从上述四个格式类似的文本中,抽取到每段文本中加粗部分的四个数据,并形成如下一个表格(这个表格就是结构化数据)
| 人名 | 方式 | 增持/减持 | 股数 |
|---|---|---|---|
| 肖宝玉 | 集中竞价 | 减持 | 75,000 |
| 赵毅 | 集中竞价或大宗交易 | 减持 | 39,715 |
| 熬志强 | 集中竞价或大宗交易 | 减持 | 250,000 |
| 霍卫平 | 集中竞价或大宗交易 | 减持 | 2,000,000 |
| 肖春夏 | 集中竞价 | 减持 | 25,000 |
UiBot Mage提供的“信息抽取”服务可以帮助你解决上述示例中描述的这类问题。
概念介绍
字段
字段是信息抽取任务中需要输出的变量。
对于一段需要抽取的文字来说,字段就是需要抽取的信息的名称。
例如,需要从“我想买从北京飞上海的机票”中抽取“北京”、“上海”,那么我应该新建“始发地”、“目的地”2个字段。
资源
为了更加准确地完成信息抽取任务,一般来说,开发者需要提供一些与其业务场景很相关的可用于文本匹配的信息,或者叫来自于开发者的外部知识,这些外部知识在Mage中被称为资源。
举例来说,有一个来自于美妆电商的RPA开发者,希望从商品描述中匹配“口红色号”进而抽取这些色号的“售价"这一关键信息,那么,开发者应该为Mage提供一份代表“口红色号”的词汇。这些词汇就是开发者提供给Mage的外部知识,Mage利用这些“外部知识”可以更好地定位需要处理的文本片段,然后抽取其中的关键信息。
开发者可以以三种方式提供这些外部知识,分别是自定义词表、预设词表和正则表达式。下面,分别介绍这三种方式。
自定义词表
自定义词表是一个由词表名称、词表值、词表值的多种说法构成的信息结构体。一个词表描述了与开发者所在领域强相关的、相对比较固定的一类以词汇形式存在的外部知识。
举例来说,口红色号就是特定于美妆领域的、在相当时间内恒定不变的一些外部知识。而这些知识的存在形式就是词汇。与之相对应地,Mage用自定义词表来获取这些外部知识。
具体地,一个可能的词表如下:
| 词表名称 | 词表值 | 词表值的多种说法 |
|---|---|---|
| 口红色号 | ||
| 烈焰蓝金999 | 传奇红唇哑光,传奇正红,传奇女人,3个9 | |
| 烈焰蓝金666 | matte kiss,Matte kiss,复古蓝调红,复古红 | |
| 烈焰蓝金740 | 可乐部,枫叶红,枫叶色,番茄色,番茄红 |
预设词表
预设词表和自定义词表用法相同,不同在于预设词表是由平台提供的预置好的实体,用于处理最常见的实体。
你可以在资源页面,查看全部预设词表,同时页面也提供了测试功能,你可以输入测试文本测试预设词表的效果。
以预设实体“城市”为例,用户发来消息“帝都有什么特色美食?”,机器人抽取到的实体名称为“城市”,抽取到的词汇为“帝都”。
注意:这里仅作为测试预设词表抽取,当发生在真实场景时,实体的抽取规则会依赖多种因素。
正则表达式
正则表达式是对字符串操作的一种逻辑公式。你可以预先学习如何使用通用的正则表达式。
但是,为了更好地利用正则表达式,需要进一步规定一些更细致的规则。这些规则包括:
- 是否区分大小写: 匹配时是否对英文字母大小写敏感。
- 单行模式: 匹配任意字符的符号.是否会匹配换行符。如果不匹配换行符,则意味着符号.匹配的字符范围包含换行符,即
[\r\n]。 - 多行模式: ^和$分别匹配开始和结束位置。多行模式下,扩展了匹配的范围,分别增加行首(字符串开始或前一行\n之后的位置)和行尾(\n之前的位置)。
- 全局匹配: 一个正则表达式可以匹配文本的多处片段。主要匹配到的都输出。
- 匹配顺序: 默认是从左到右。匹配的顺序也可以从右往左,但通常这主要适用于阿拉伯文。
针对上述规则,Mage的“信息抽取”做了相应地规定,这些规定是:
- 默认不区分大小写。
- 默认单行模式,即
<*>可以匹配任意字符,包括[\r\n]。 - 默认非多行模式。
<*>最后一个匹配规则时,会匹配到字符串结尾。需要多行模式时,建议在行末加上特殊字符比如#,并在模板中增加对#的匹配规则; - 默认全局模式: 匹配多处, 多处都会输出, 有匹配的开始位置。
- 默认从左到右匹配模式。
模板
为了提取上述示例中的关键信息,“信息抽取”功能需要开发者提供一个叫做“模版”的文本表达式。利用这个表达式,去匹配文本的若干片段、提取信息。针对本文开头部分的示例,一个写好的模版,如下图所示:
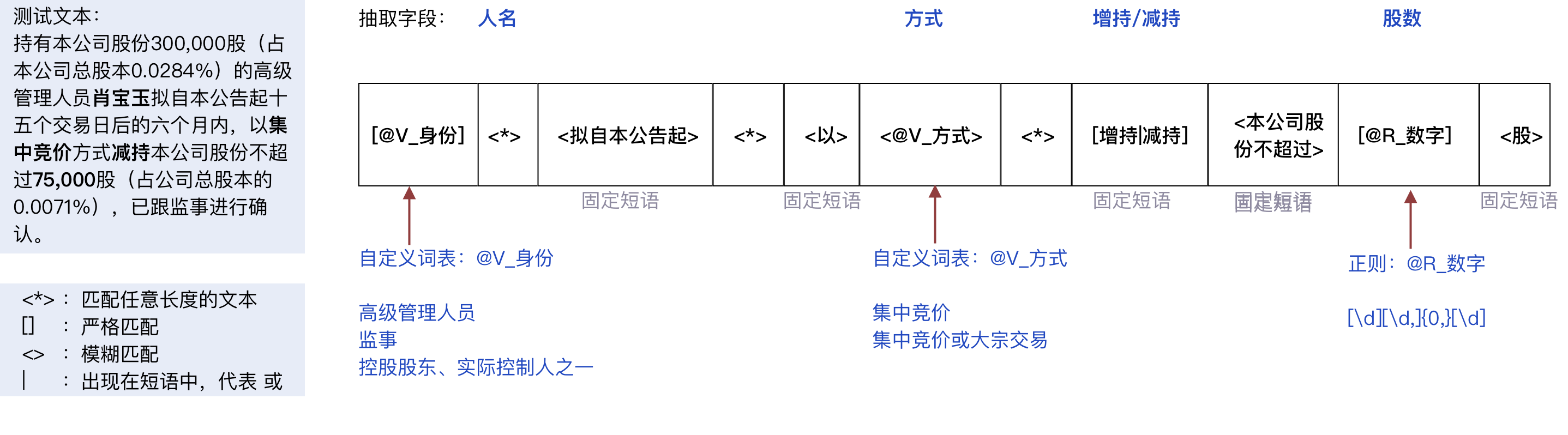
开发者必须提供这样的一个模版,才能完成信息抽取。为了写出一个正确的模版,需要了解如下必要的语法:
- “中括号”
[]代表严格匹配。- 匹配的内容可以是预先在资源中定义好的“词表”、“正则表达式”,也可以是需要匹配的短语。
- 如果是匹配的内容是“资源”,会将匹配到的结果进行归一化(例如,不论匹配到“复古蓝调红”、“复古红”等“多种说法”的哪一个,都返回“烈焰蓝金666”)。
- 多个需要匹配的内容可以用|(半角竖线)进行分割。
- “尖括号”
<\>代表模糊匹配。- 模糊匹配是与严格匹配相对应的概念。严格匹配要求待匹配的文本与指定的匹配内容必须完全一致。模糊匹配则只要两者语义接近即可。例如,严格匹配不会认为“新闻发布会”和“记者招待会”会匹配上;但模糊匹配可以。
- 尖括号内可以指定的内容包括资源中的自定义词表和开发者输入的“短语”。
- 尖括号内不可以指定资源中的正则表达式。
- 多个需要匹配的内容可以用|(半角竖线)进行分割。
- 尖括号里的引用资源不会进行归一化。
- 符号
<*\>代表匹配任意长度的文本片段。 - 模板中需要匹配
{,\},\[,\],<,\>,\|,\{,\},\*时,使用“\”转义。
版本
版本是模板的集合,可以实现对不同模板集合的整体效果评测。
注意:一个信息抽取模型下最多支持创建5个版本。
基础操作
创建信息抽取模型
1 登录平台后从以下路径 定制化AI能力/文本理解/信息抽取 进入信息抽取模型列表。
2 点击新建模型,在弹窗中输入模型名称,选择引擎版本,点击确认后生成新的模型。
注意: 在UiBot Creator中使用信息抽取的服务时,需要配置信息抽取模型的pubkey和secret。 模型的pubkey和secret在模型的设置页面。
创建字段
1 打开已创建的信息抽取模型,点击导航栏上的字段。
2 点击新建字段,打开创建弹窗,输入字段名,点击保存完成创建。
- 字段名不得超过20个字。
- 一个模型下的字段名称不能重复。
3 点击新建字段旁边的更多,可以批量添加字段。
配置资源-创建自定义词表
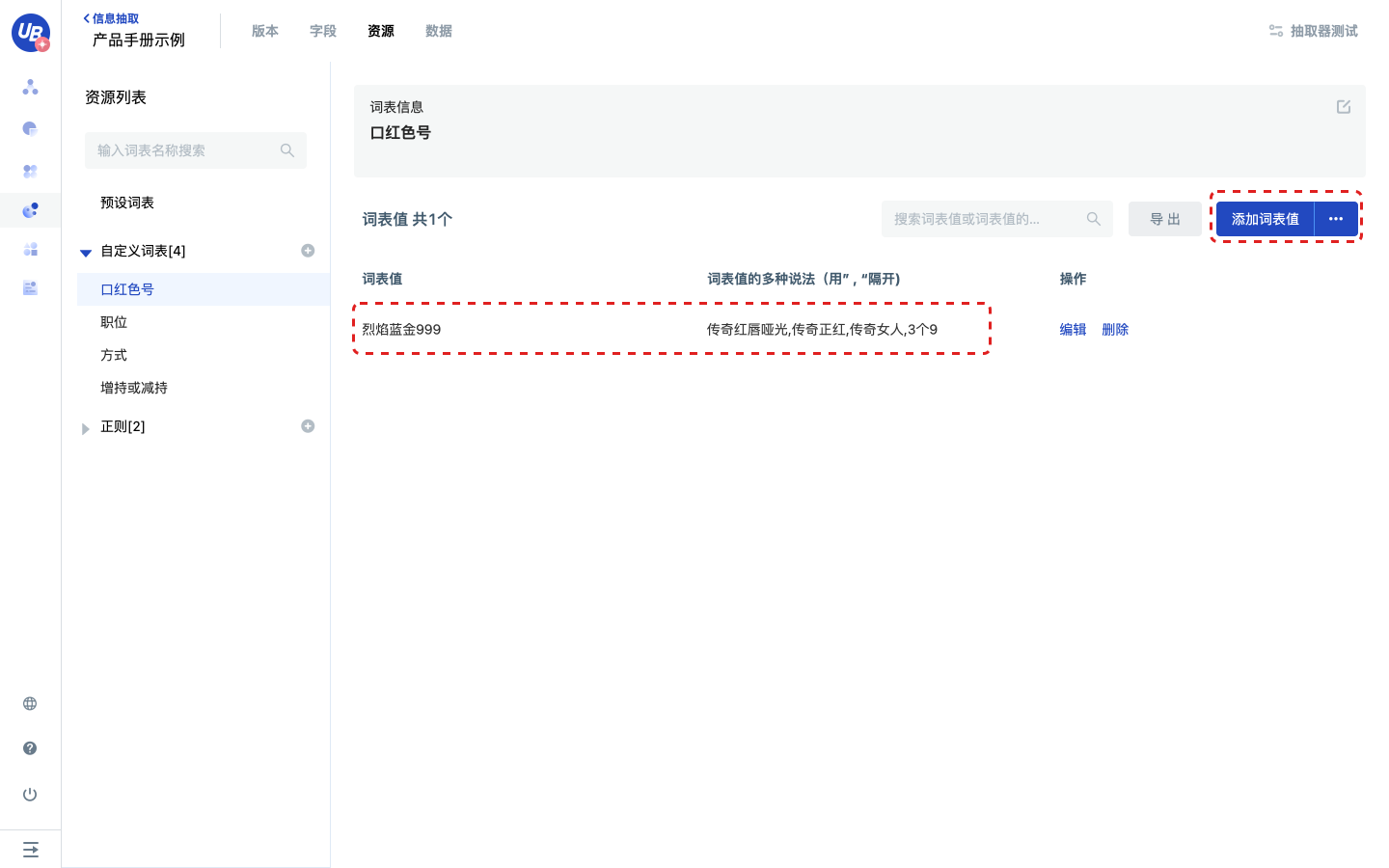
1 打开已创建的信息抽取模型,点击导航栏上的资源。
2 点击资源列表/自定义词表旁边的加号,创建一个自定义词表。

3 点击添加词表值,打开弹窗,输入词表值和其多种说法。
配置资源-创建正则表达式
1 打开已创建的信息抽取模型,点击导航栏上的资源。
2 点击资源列表/正则表达式旁边的加号,创建一个正则。
3 在设置正则表达式输入框中,输入正则表达式内容和替换规则。
什么是替换?如何使用替换规则?
正则规则中,()表示捕获分组,()会把每个分组里的匹配的值保存起来,输出值的顺序以左括号出现的顺序为准。
例如正则表达式"(\d(\d(\d)))",替换规则为"文字$1-$2-$3xx",用测试文本"123"去测试,输出是什么呢?去Mage上试试吧~
可以在这里 https://www.runoob.com/regexp/regexp-syntax.html 了解更多的正则表达式的语法。
4 测试正则效果是否符合预期。
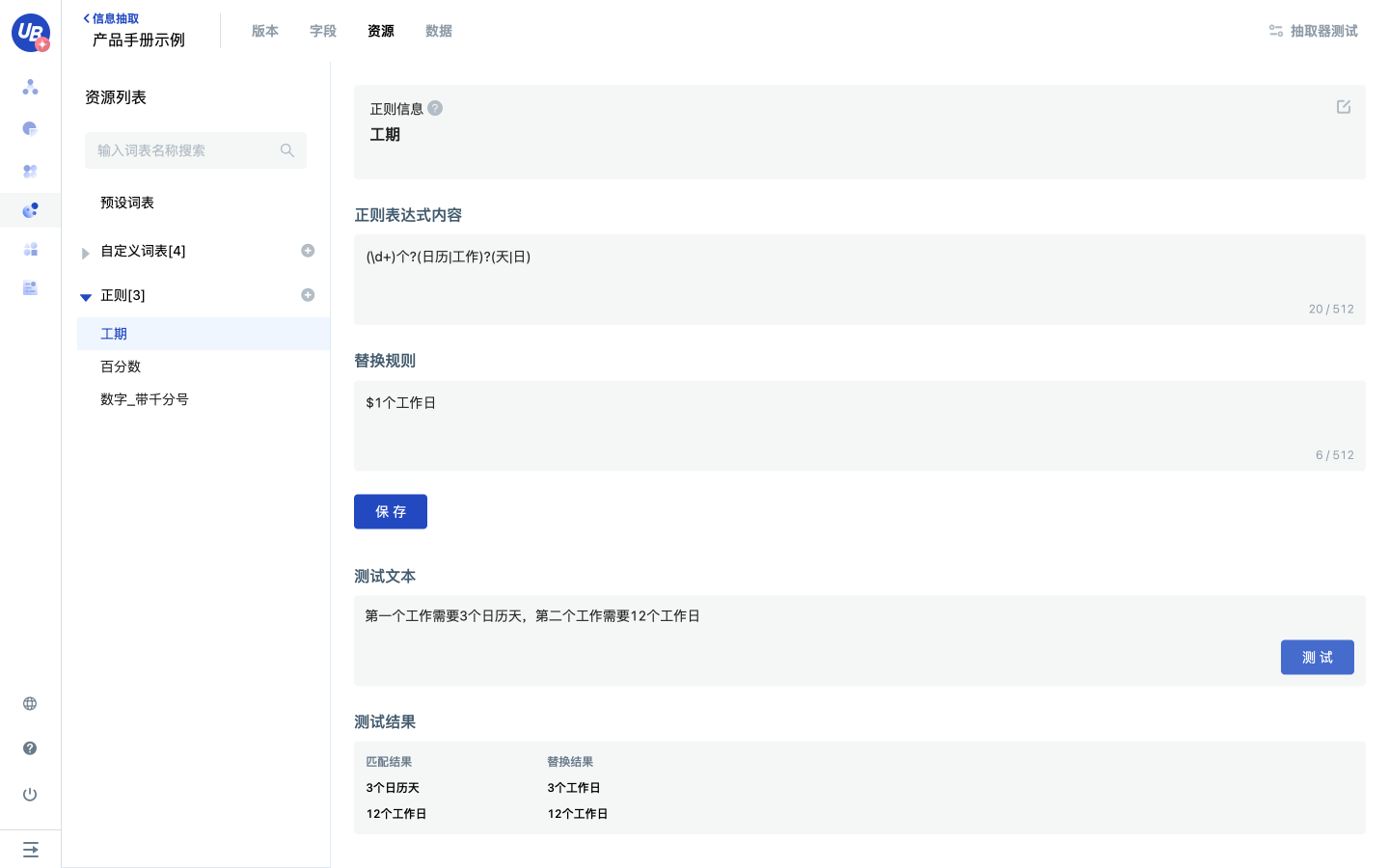
自己试试吧! 正则内容:(\d+)个?(日历|工作)?(天|日) 替换规则:$1个工作日 测试文本:第一个工作需要3个日历天,第二个工作需要12个工作日
创建版本
1 打开已创建的信息抽取模型,点击导航栏上的版本。
2 点击新建版本按钮,在弹窗中输入版本名称,点击确定创建新的版本。
3 版本列表操作说明
- 训练:系统推荐生成模版的入口,具体操作见进阶操作/训练。
- 评测:可以实现对当前版本下所有模板的抽取效果的评估,具体见进阶操作/评测。
- 发布:将当前版本下所有模板发布到正式环境中,具体见基础操作/发布版本。
- 详情:管理当前版本下的所有模板的入口。
- 更多/下载评测结果:提供上次评测结果的下载。
- 更多/复制:提供对当前版本的一键复制。
- 更多/删除:删除当前版本。
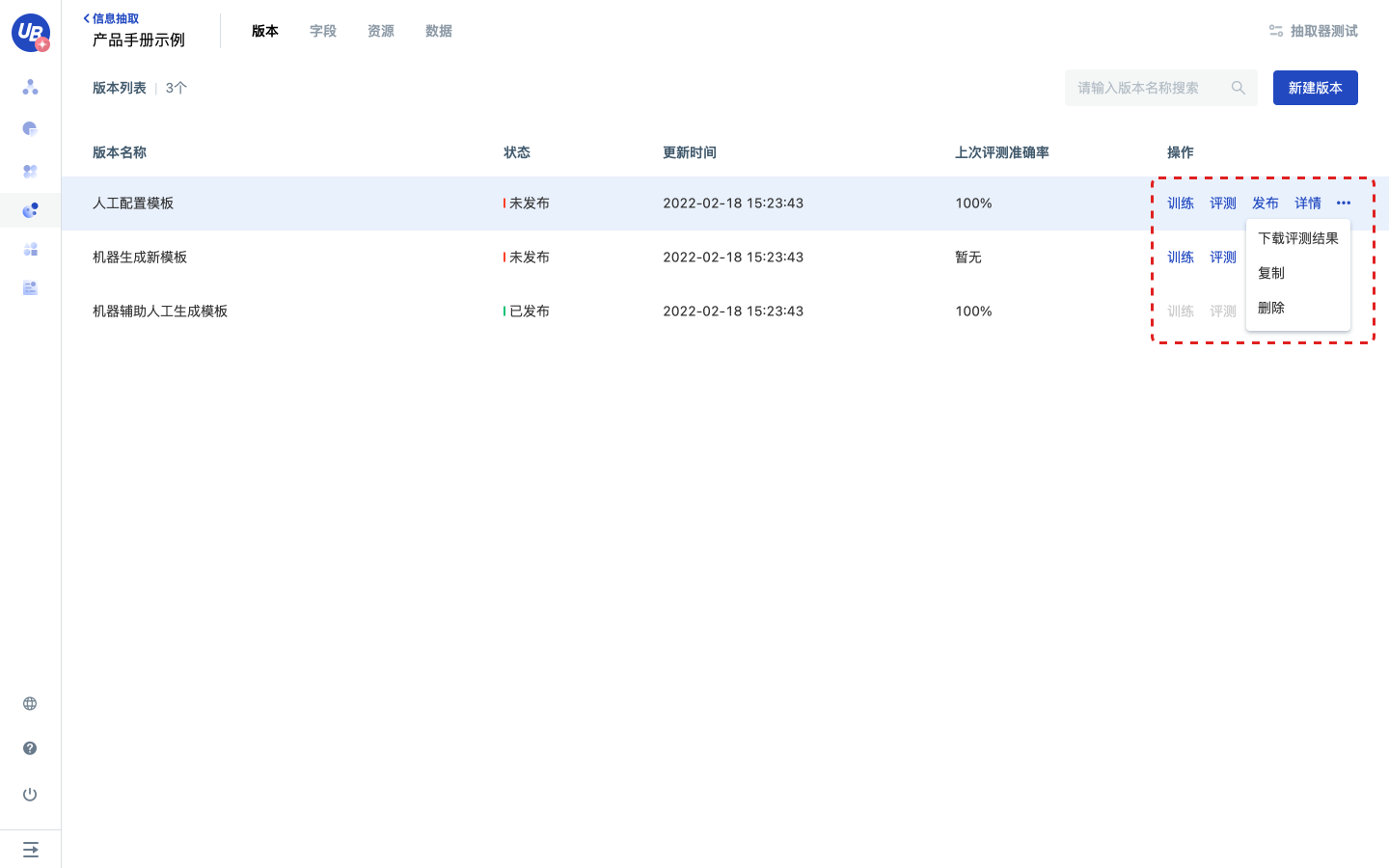
4 目前,平台支持“人工”和“机器辅助人工”两种方式配置模板。
- “人工”方式:点击当前版本的详情,进入模板列表页面,点击新建模板进行人工配置模板,具体见基础操作/配置模板-人工方式。
- “机器辅助人工”方式:具体操作见进阶操作/训练。
配置模板-人工方式
1 打开已创建的信息抽取模型,点击导航栏上的版本。
2 点击对应版本的详情,进入模板列表。
3 点击新建模版按钮,进入模版编辑页面。
4 输入模版名称、模版描述描述当前模版的基本信息。
5 开始编辑模板,从五类匹配规则开始创建模板的每一个节点。
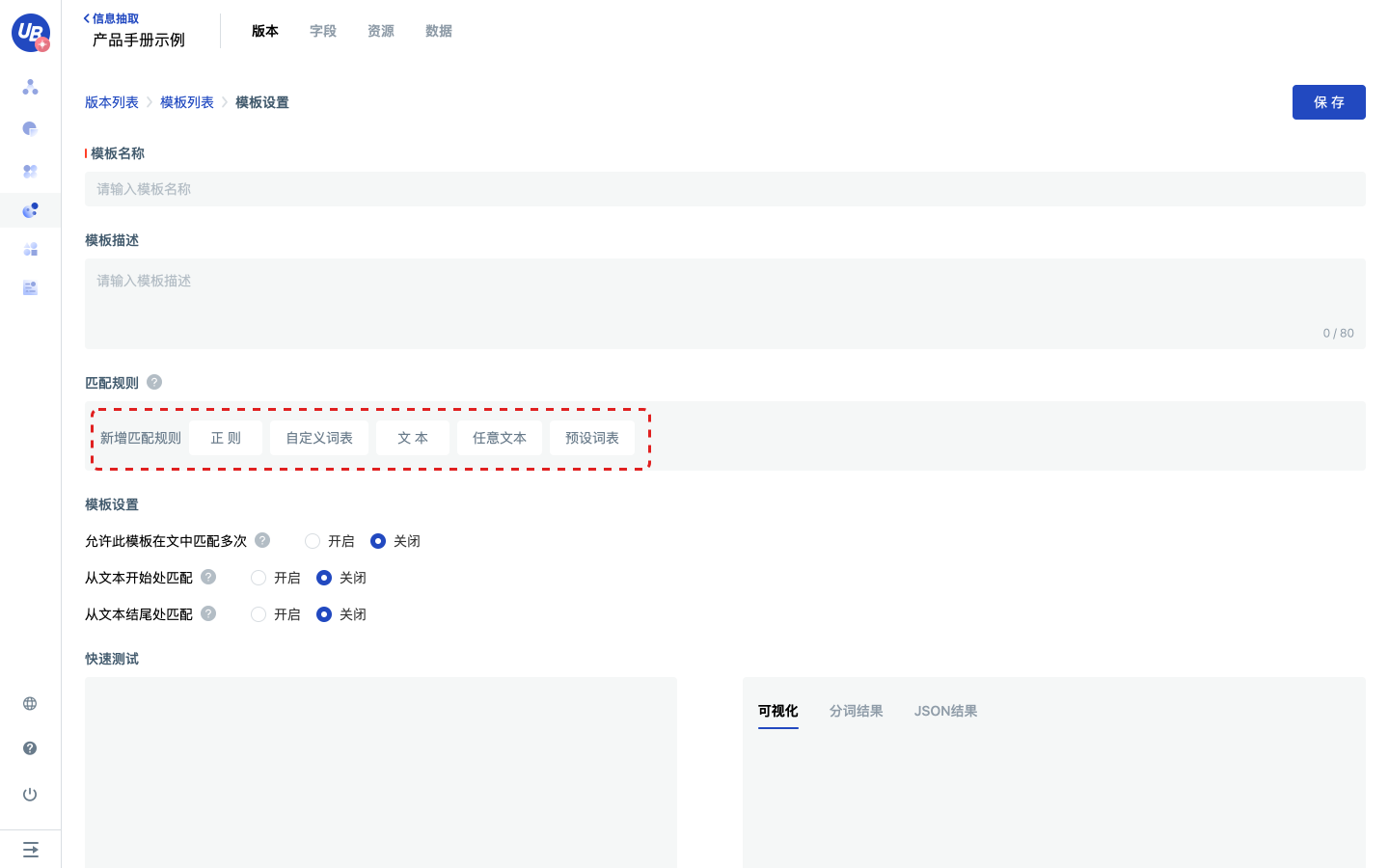
- 正则: 代表匹配一段由正则表达式可以描述的文本,对应“模版”语法中需要引用“正则表达式”的匹配。
- 选择需要匹配的已创建好的正则表达式。
- 选择是否输出到某个字段。
- 自定义词表: 代表匹配一段由词表描述的文本,对应“模版”语法中需要引用“自定义词表”的匹配。
- 选择需要匹配的已创建好的自定义词表。
- 选择是否输出到某个字段。
- 勾选模糊匹配,采用基于语义相似度的近义匹配;未勾选将采用严格匹配。
- 文本: 代表匹配一段文本,对应“模版”语法中不需要引用“资源”的匹配。
- 输入需要匹配的文本。
- 选择是否输出到某个字段。
- 勾选模糊匹配,采用基于语义相似度的近义匹配;未勾选将采用严格匹配。
- 任意文本: 代表严格匹配一段任意长度、任意内容的文本,对应“模版”语法中的
<*>。- 输入需要匹配的文本的长度。可以为空。
- 选择是否输出到某个字段。
- 预设词表:代表严格匹配或模糊匹配一段由词表描述的文本。
- 选择需要匹配的预设词表。
- 选择是否输出到某个字段。
6 编辑完模版后,点击保存模版。
发布版本
编辑完所有模版后,回到版本列表页面,发布相应版本。
- 已发布版本下所有的模板都将在正式环境中生效。
- 同一时间,只有一个版本可以发布到正式环境中。
测试信息抽取模型效果
1 打开已创建的信息抽取模型,点击右上角的信息抽取测试。
2 输入或上传测试文本,点击开始测试,测试当前信息抽取模型的抽取效果。
注意:如果信息抽取模型下没有已发布版本,代表当前信息抽取模型没有生效模板,则无法测试抽取效果。
进阶操作
配置信息抽取模型
1 点击信息抽取模型的设置按钮,打开模型配置弹窗。
2 配置冲突检测策略
我们认为有2种冲突,第一种是2个模板匹配到的片段有交叉,对应冲突检测策略不允许文本重复匹配模板,第二种是2个模板要输出的字段位置相同,对应冲突检测策略不允许文本重复抽取字段。
当2个模版被检测到发生冲突时,解冲突策略为
- 当2个模板匹配的片段不一样长时,保留片段长的模板。
- 当2个模板匹配的片段一样长时,选择匹配信息位置靠前的模板。
- 当2个模板匹配到的片段一模一样,选输出字段多的;输出字段一样的,选模板含匹配规则节点多的;如果模板节点一样多,不解冲突。
3 默认换行结束匹配
如果文本中含有换行符\n,抽取前模型会先通过\n来切分文本,然后再进行匹配。 也就是说,如果你需要抽取的内容中有换行符,请不要勾选默认换行结束匹配。
上传数据
数据是待抽取的文本,已标注数据是标注了预期抽取结果的数据。 目前,平台只支持离线标注,标注格式如【【【字段名===要抽取的内容】】】,字段名和要抽取的内容都不能为空。 以业务场景的公告为例,一份已标注的公告格式如下:
公告一 持有本公司股份300,000股(占本公司总股本0.0284%)的高级管理人员【【【【人名===肖宝玉】】】拟自本公告起十五个交易日后的六个月内,以【【【方式===集中竞价】】】方式【【【增持/减持===减持】】】本公司股份不超过【【【股数===75,000】】】股(占公司总股本的0.0071%),已跟监事进行确认。
1 打开已创建的信息抽取模型,点击数据/所有数据。
2 点击上传数据,选择要上传的文件,点击“确定”,打开上传确认弹窗。
3 点击“上传”即可。
上传文件要求:
- 目前平台仅支持上传3万字以内、编码为utf-8的txt文件。
- 一个信息抽取模型最多支持上传200份数据。
文件上传失败的提示及对应原因:
- 【上传失败,内容超限】文件内容不能超过3万字。
- 【上传失败,编码错误】文档的编码不为utf-8。
- 【上传失败,替换失败】不支持未标注的文件替换已标注的文件。如果需要替换,请先删除已标注文件,再次上传。
- 【上传失败,数量超限】一个信息抽取模型下最多只能上传200条数据。
- 【上传失败,网络错误】由于网络问题导致上传失败。
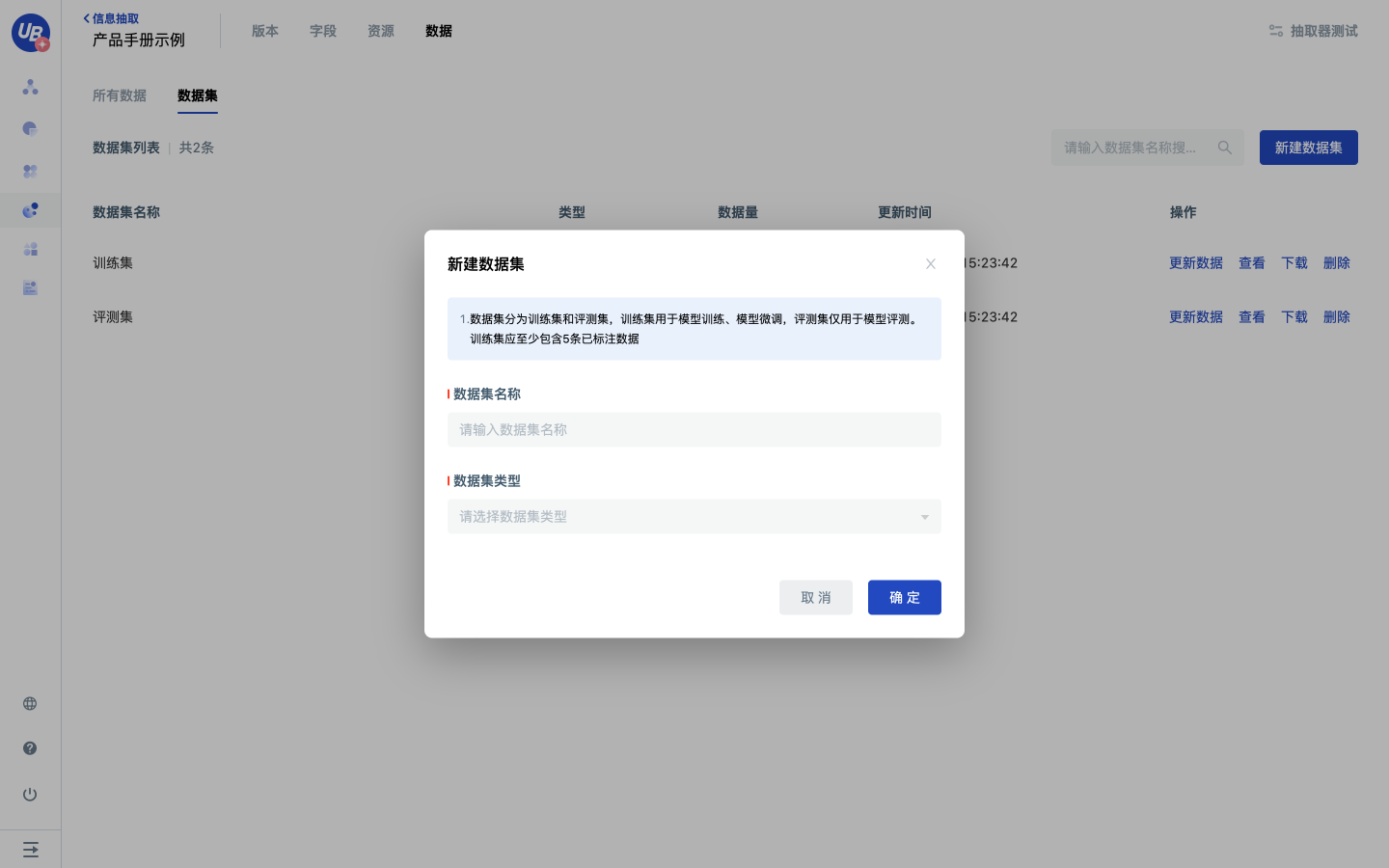
配置数据集
数据集分为训练集和评测集,是版本训练、评测的输入。训练集用于模型训练、模型微调,评测集仅用于版本的评测。
1 打开已创建的信息抽取模型,,进入数据/数据集页面。
2 点击新建数据集,输入数据集的名称,选择数据集的类型,完成数据集的创建。
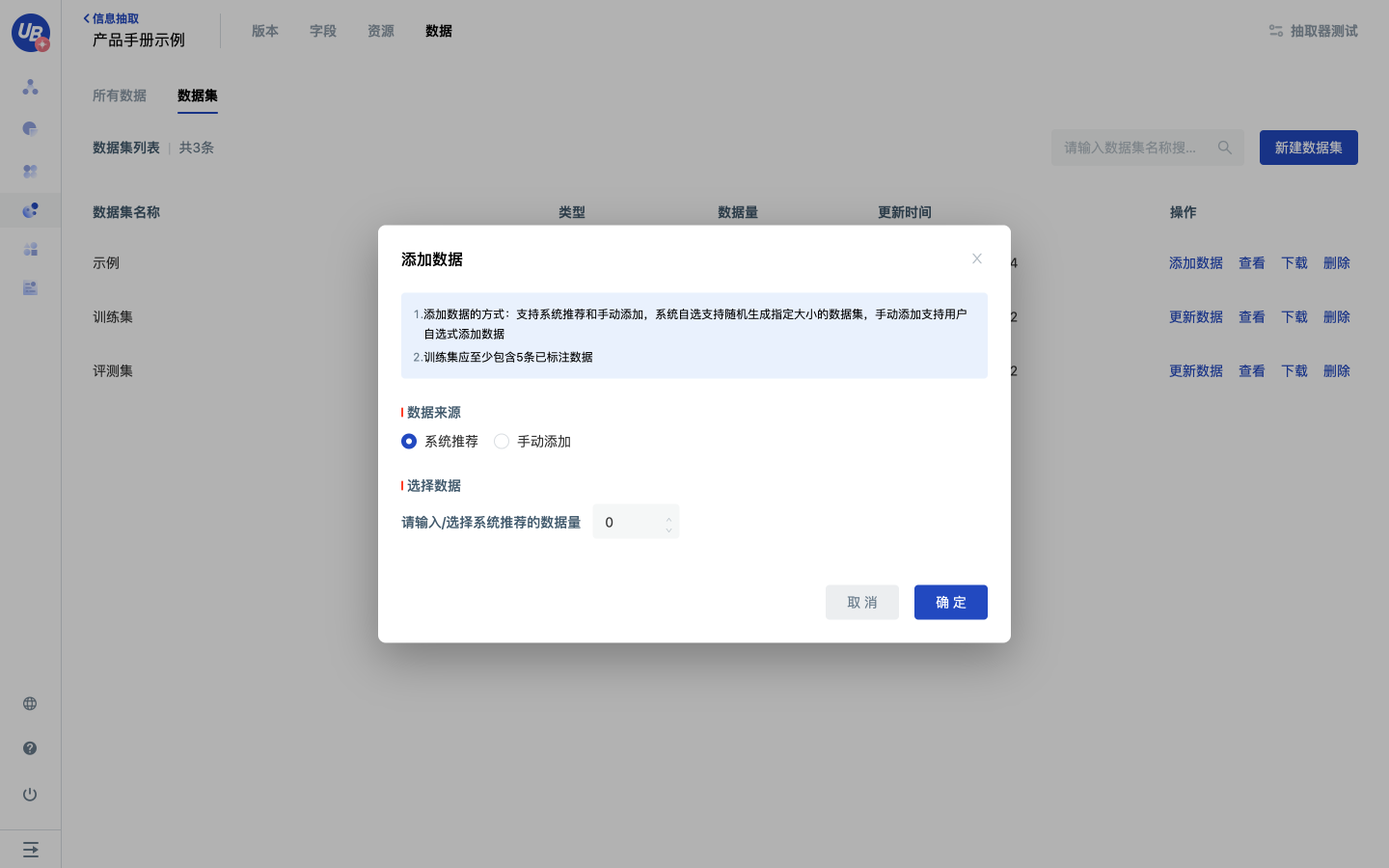
3 在数据集列表中找到刚刚创建的数据集,点击添加数据,打开添加数据弹窗。添加数据支持系统推荐和手动添加两种方式,系统自选支持随机生成指定大小的数据集,手动添加支持用户自选式添加数据。
注意:状态为未标注的数据不会出现在添加数据弹窗中。
训练
采用机器辅助人工方式由系统推荐生成模板时,系统将利用当前版本关联的训练集来训练模型,生成推荐模板。训练将产生一组类型为“可覆盖”的模版,将整体覆盖“训练前”当前版本中所有“可覆盖”类型模版。
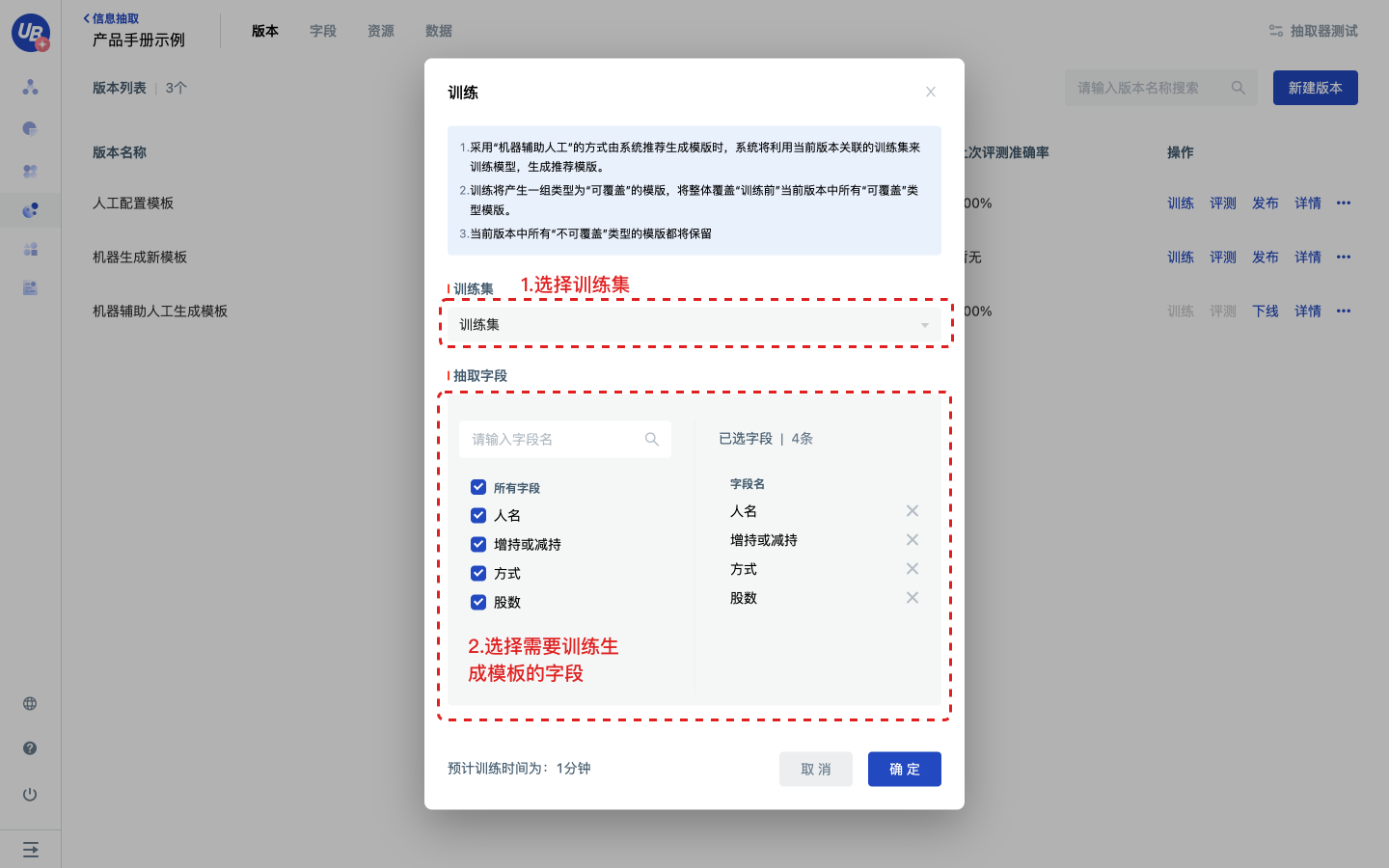
1 打开已创建的信息抽取模型,点击导航栏上的版本。
2 点击对应版本的训练,打开训练弹窗,选择训练集和需要由机器推荐模板的字段,点击确定开始训练。此时,版本进入了训练中状态。
3 训练完成后,版本将回到未发布状态。点击版本的详情,进入模板列表,可以查看到此次训练产生的模板。
评测
评测能实现对版本下所有模板的整体抽取效果的评估。系统将利用版本内所有模板对评测集的数据进行抽取,并与标注数据进行核对,生成评测结果。

1 打开已创建的信息抽取模型,点击导航栏上的版本。
2 点击对应版本的评测,打开评测弹窗,关联评测数据集,点击确定开始评测。此时,版本进入了评测中状态。
3 评测完成后,会更新版本的上次评测准确率和评测结果,版本将回到未发布状态。点击版本操作中的下载评测结果,下载此次评测的结果。
模型导出
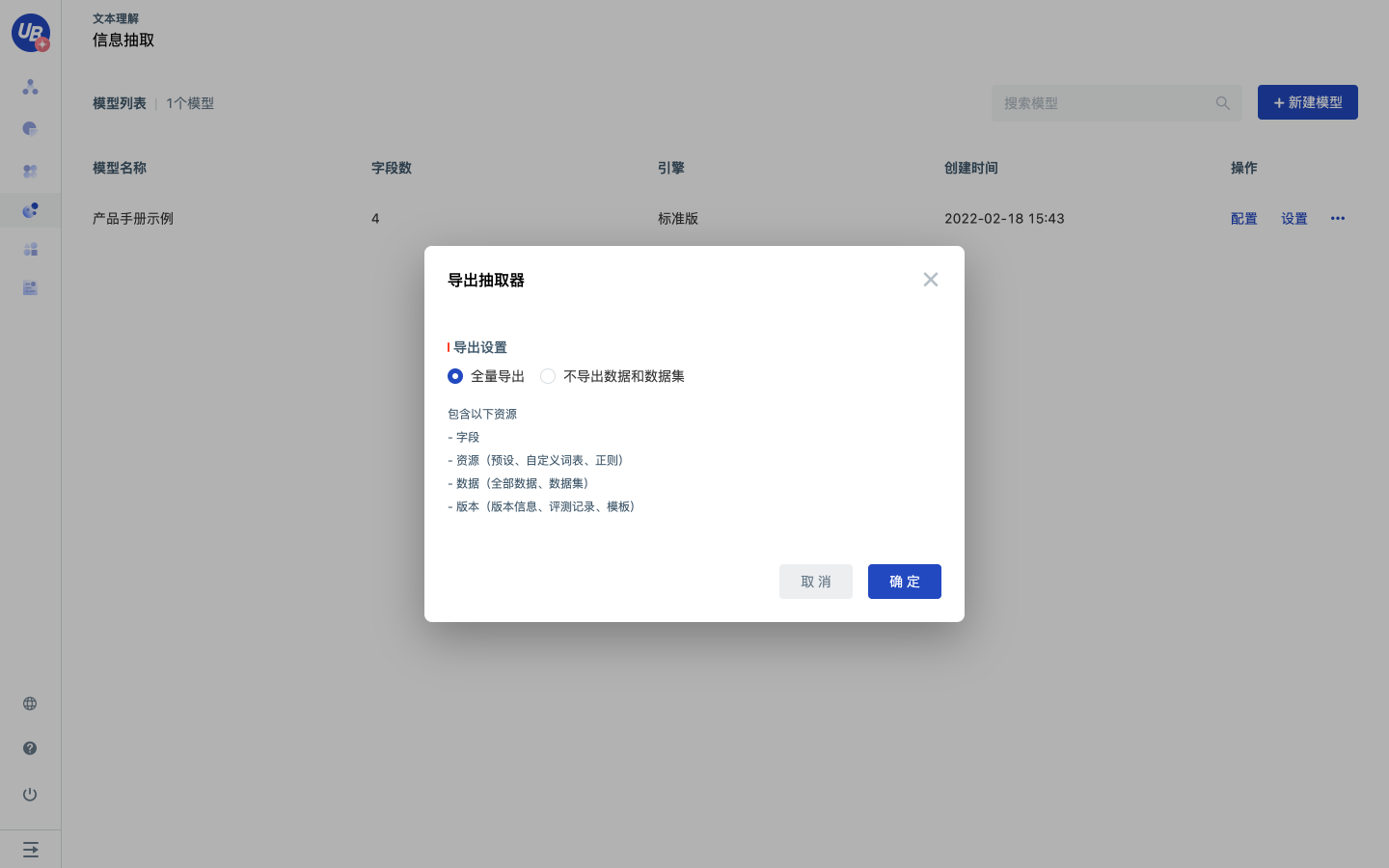
点击模型的导出按钮,打开导出配置页面,根据需求配置导出设置,点击确定完成导出。
- 全量导出:导出当前模型下所有资源,包括字段、资源、数据、版本。
- 不导出数据和数据集:导出当前模型下除数据和数据集以外的所有资源,包括字段、资源、版本。
模型导入
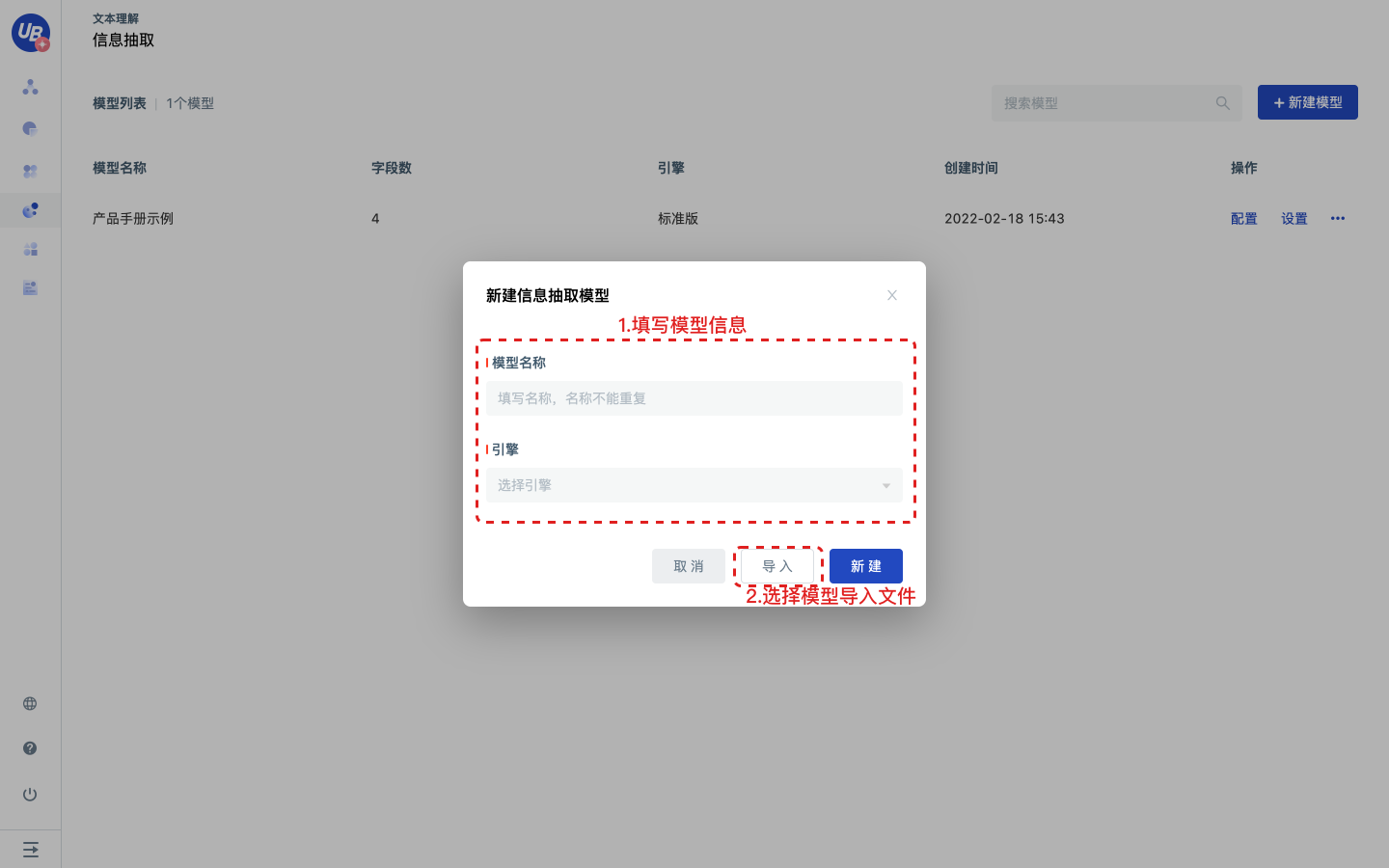
点击新建信息抽取模型,在弹窗中输入模型名称,选择引擎版本后,点击导入选取相应模型数据包,完成导入。
- 模型数据包:Mage平台导出的以.extractor结尾的文件
- 全量导入需要在有互联网的环境
示例1-人工配置模板
分析要处理的文本
以业务场景的公告为例:
公告一
持有本公司股份300,000股(占本公司总股本0.0284%)的高级管理人员肖宝玉拟自本公告起十五个交易日后的六个月内,以集中竞价方式减持本公司股份不超过75,000股(占公司总股本的0.0071%),已跟监事进行确认。
公告二
持有本公司股份158,858股(占本公司总股本0.0150%)的监事赵毅拟自本公告起十五个交易日后的六个月内,以集中竞价或大宗交易方式减持本公司股份不超过39,715股(占公司总股本的0.0038%)。
公告三
持有本公司股份1,208,035股(占本公司总股本0.1144%)的高级管理人员敖志强拟自本公告起十五个交易日后的六个月内,以集中竞价或大宗交易方式减持本公司股份不超过250,000股(占公司总股本的0.0237%)。
公告四
持有本公司股份130,162,360股(占本公司总股本12.3220%)的控股股东、实际控制人之一霍卫平拟自本公告起十五个交易日后的六个月内,以集中竞价或大宗交易方式减持本公司股份不超过2,000,000股(占公司总股本的0.1893%)。
公告五
持有本公司股份100,000股(占本公司总股本0.0095%)的高级管理人员肖春夏拟自本公告起十五个交易日后的六个月内,以集中竞价方式减持本公司股份不超过25,000股(占公司总股本的0.0024%),已跟监事进行确认。
1 确定要抽取的字段
开发者希望从上述四个格式类似的文本中,抽取到每段文本中加粗部分的四个数据,并形成如下一个表格,那么确定要抽取的字段是:人名,方式,增持/减持,股数。
2 分析字段的上下文特征
- 开始是一段任意文本“持有本公司股份XXXXXXXXXX”,之后是该人的职位“高级管理人员”“监事”“高级管理人员”“控股股东、实际控制人之一”,这些职位可以添加为自定义词表,接着是字段【人名】,人名可以用预设词表的人物名称。
- 接着一段文本,之后是字段【方式】“以XXX方式”,方式有“集中竞价”“集中竞价或大宗交易”,可以添加为自定义词表。
- 接着是字段【增持/减持】,有“增持”“减持”,也可以添加为自定义词表。
- 再接着是一段文本“本公司股份不超过”,之后是字段【股数】,股数为数字,可以使用正则。
配置信息抽取模型
1 新建一个信息抽取模型:上市公司的披露公告
2 新建四个字段:人名,方式,增持/减持,股数
3 新建资源
基于分析字段的上下文特征,需要用到的资源有:
- 预设词表
- 人物名称
- 自定义词表
- 职位:高级管理人员,监事,控股股东,实际控制人
- 方式:集中竞价,集中竞价或大宗交易
- 增持/减持:增持,减持
- 正则
- 数字(带千分号):(\d+)(,\d+)*
4 配置模板
新建模板,输入模板名称、模板描述,按照分析的字段上下文特征,依次配置匹配规则。
- 勾选“允许此模板在文中匹配多次”
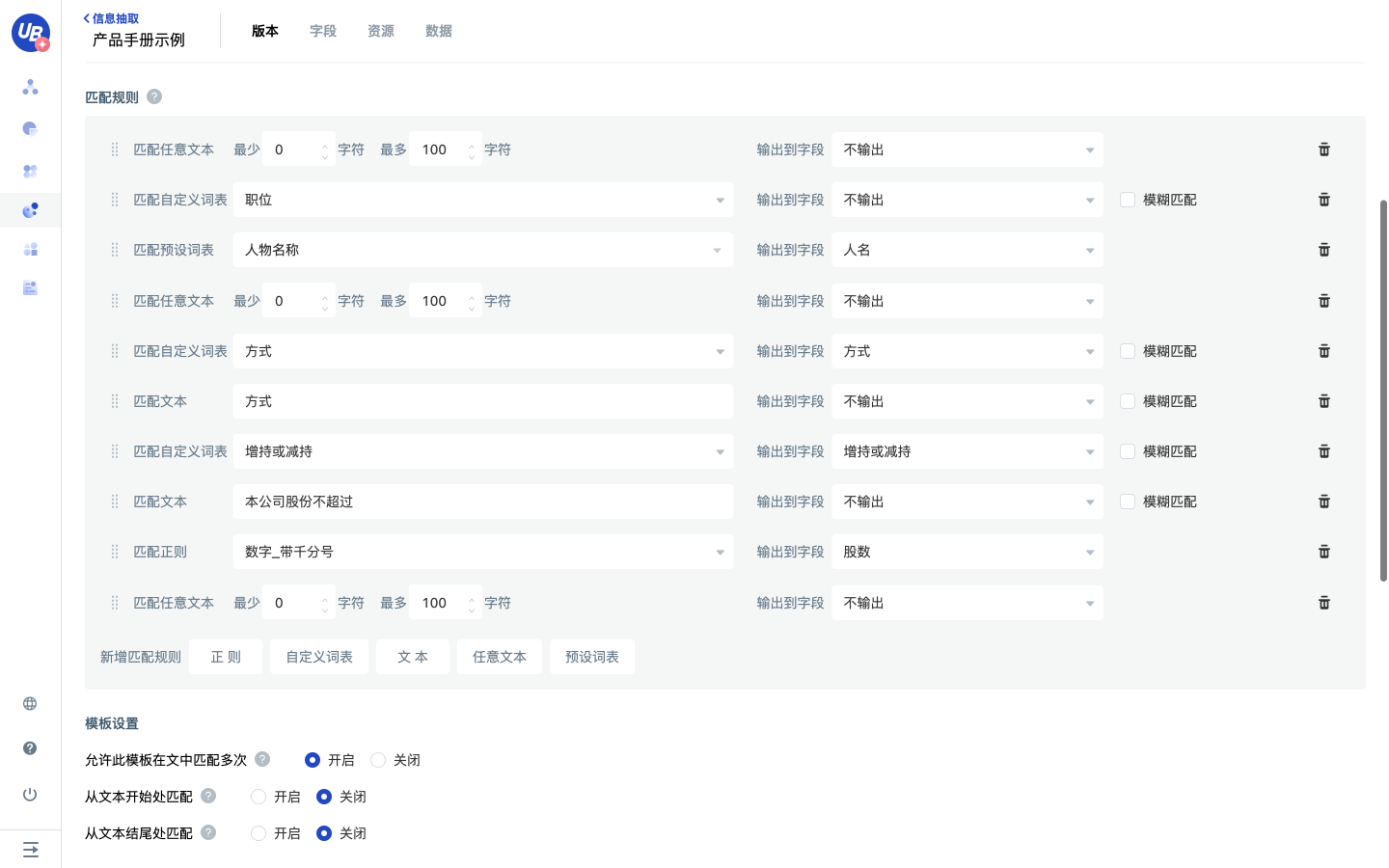
5 快速测试
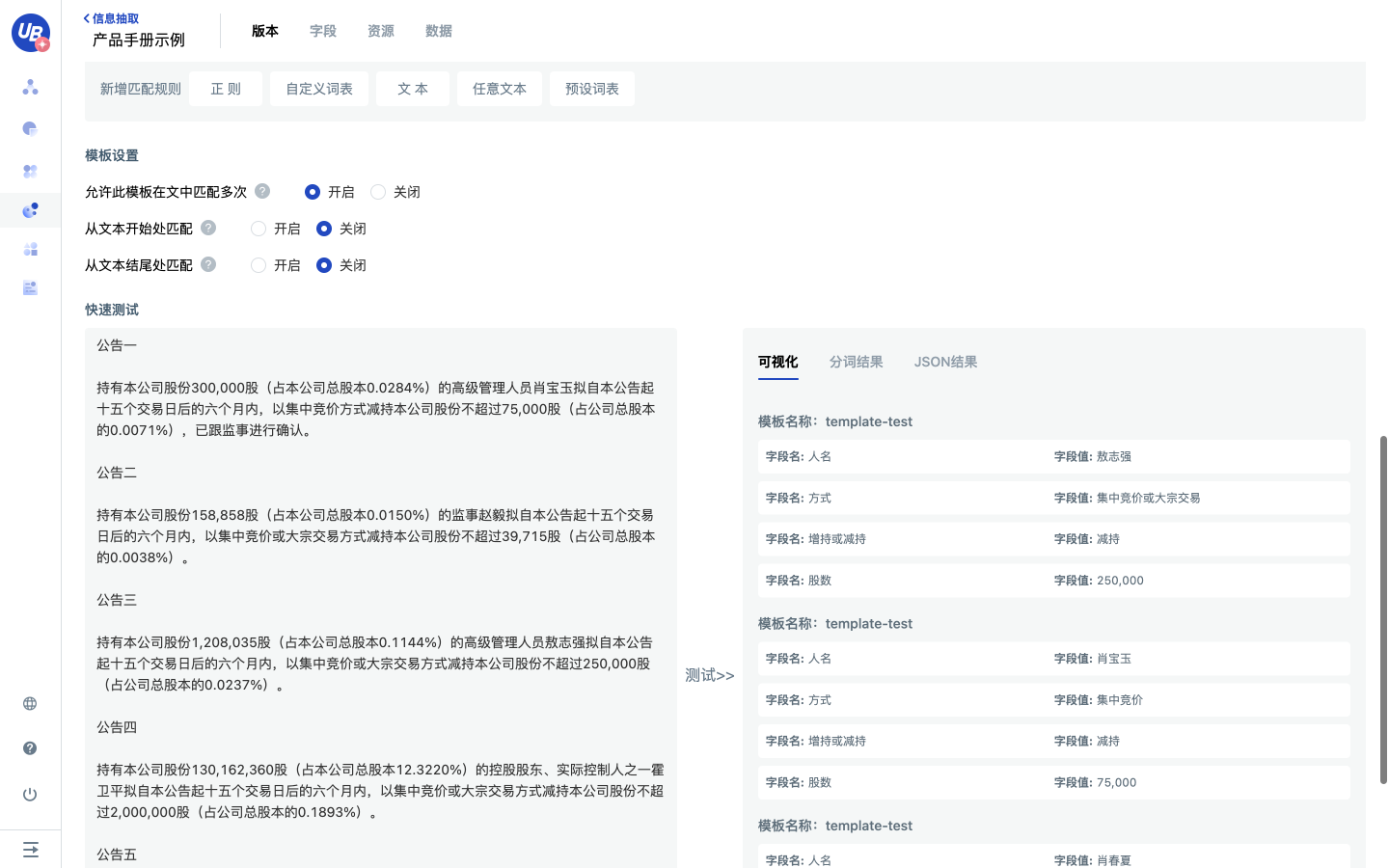
模板配置完成后,可以在下方快速测试,有可视化和JSON结果,如果有错误会展示错误类型和错误原因,便于对模板进行更改。模板测试没问题后,点击右上角的发布模板。
6 信息抽取测试
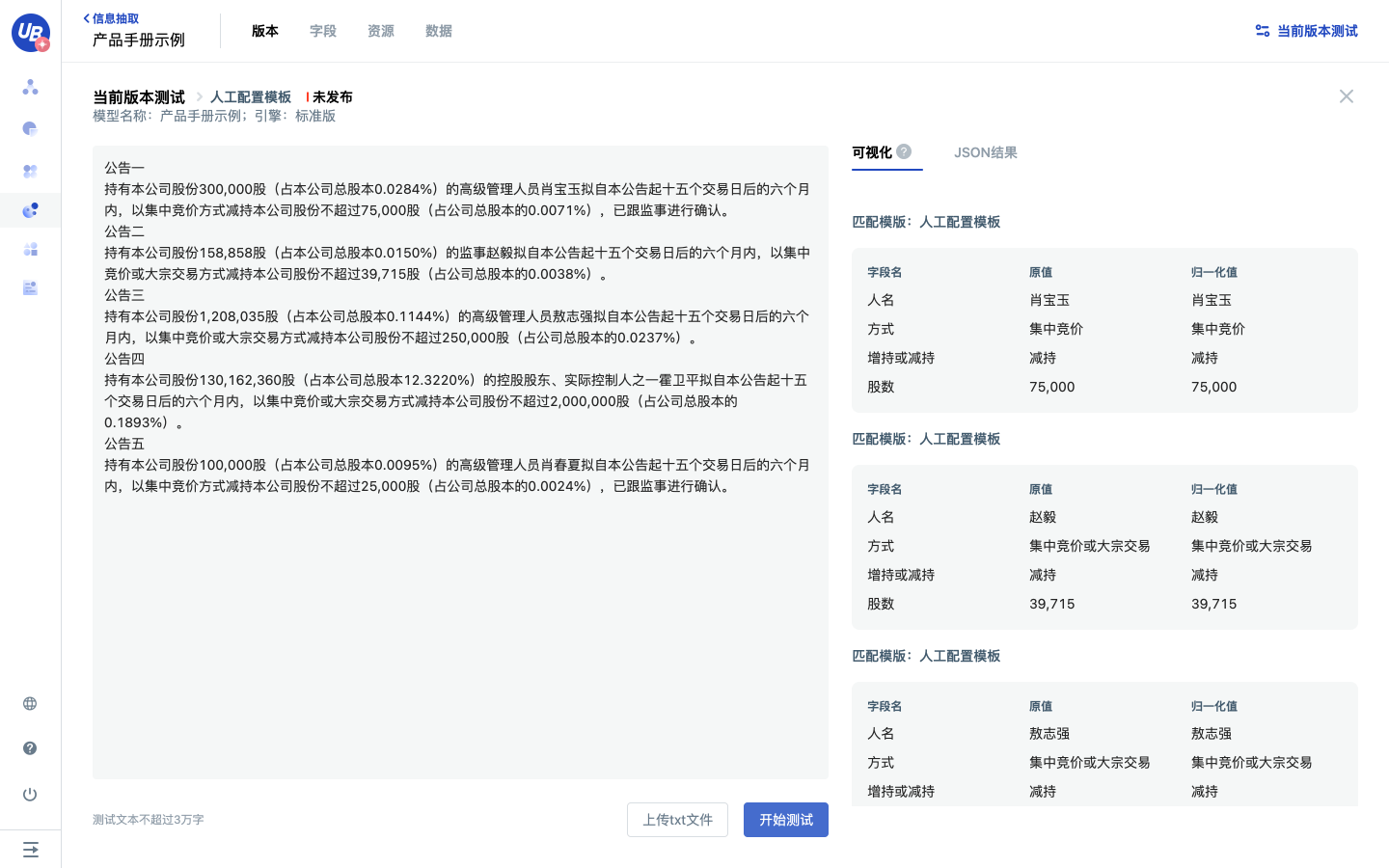
返回版本列表,模板发布之后,点击右上角的信息抽取测试,输入测试文本,查看信息抽取的结果。
其他
视频版
RPA示例代码
下载示例代码压缩包:信息抽取
下载评测文件:评测集上市公司的披露公告